一种基于区域自适应模型的深度视频码率控制方法与流程
本发明涉及3D视频编码领域,尤其涉及一种基于区域自适应模型的深度视频码率控制方法。
背景技术:
码率控制在通过信道传输高质量3D视频的过程中扮演着重要角色。码率控制的基本原理是按照一定的编码策略动态地调整编码器的编码参数,通过各个层次上的码率优化分配,最终调节编码器在单位时间内输出的比特数,使得实际输出码率与目标码率一致。针对码率控制已经有较多的研究,各个视频编码标准均制定了相应的码率控制算法模型,针对不同的应用及标准,对应使用不同的码率控制算法与模型。除了集成在视频编码标准中的方法,研究者还提出了许多其他的码率控制模型,主要可以分成三类:在码率R和量化参数Q之间建立联系的Q-domain码率控制技术、在码率R和量化后的零系数的比例ρ之间建立联系的ρ-domain码率控制技术、以及在码率R和拉格朗日乘子λ之间建立关系的λ-domain码率控制技术。Ma等[1]针对H.264/AVC提出了一种线性的R-Q(Rate-Quantitation)模型,并且利用该模型提出了一种使部分编码块编码两次的码率控制算法。Kamaci等[2]提出了一种基于柯西分布的统计的R-Q模型,并且针对H.264/AVC提出了一种新的比特分配方案。Lee等[3]提出了将不同编码单元(Coding Unit,CU)分成纹理区域和非纹理区域,用拉普拉斯模型分别对纹理区和非纹理区建立R-Q的模型。这些算法都是建立在R-Q模型的基础上,R-Q模型本身存在蛋鸡悖论,并且随着编码复杂度的增加,R和Q之间不存在一一对应的关系。He等[4]针对H.264/AVC提出了一种ρ域的码率控制方法,此方法只适用于固定CU块。Gao等[5]研究了码率和量化后的非零系数之间的线性关系,并且针对HEVC提出了一种新的帧级比特分配方案。Li等[6]将人的面部区域进行分层,为每一层提供不同的权重,实现了一种加权的λ域码率控制方法。Guo等[7]将基于R-λ模型的码率控制方法运用到屏幕内容编码中,并依据屏幕内容编码的特性改进了算法的比特分配阶段。
然而,现有的码率控制模型大多是针对彩色视频构建的。随着3D显示技术、场景重现和视点合成技术的发展,深度视频在3D视频中的重要作用逐渐被人们发掘。在3D视频中,深度视频是对象在3D场景中的几何表示。不同于彩色图像,深度图是由大量的平滑区域和尖锐的边界所构成,若直接将传统的彩色视频码率控制算法直接应用到深度视频上,必然会造成深度视频编码效率的下降,因此需要对深度视频编码的比特分配及码率控制技术进行研究。
技术实现要素:
本发明针对现有的码率控制模型大多是针对彩色视频构建的现状,提出针对深度视频的基于区域自适应模型的深度视频码率控制方法,以提高深度视频的编码效率,详见下文描述:
一种基于区域自适应模型的深度视频码率控制方法,所述控制方法包括以下步骤:
将深度视频的区域划分为对绘制虚拟视点影响较大的区域IBV,其余的区域为对绘制虚拟视点影响较小的区域NIBV;其中,区域IBV为:物体的边界和剧烈运动的区域,
建立基于区域IBV和区域NIBV的R-λ模型;计算R-λ模型的初始参数;
基于区域R-λ模型的码率控制方法确定区域IBV和区域NIBV最优的比特分配,并求解最优比特分配。
所述基于区域IBV和区域NIBV的R-λ模型具体为:
其中,j∈{IBV,NIBV},aj和bj是模型参数,Rj是j的平均比特,λj是j的拉格朗日乘子。
所述基于区域R-λ模型的码率控制方法确定区域IBV和区域NIBV最优的比特分配的步骤具体为:
通过拉格朗日乘数法将限制条件下求极值的问题映射到等价的无约束条件的求极值问题,可得:
min J=A·exp(βIBVRIBV)+B·exp(βNIBVRNIBV)+C
+λ·(RIBV·NIBV+RNIBV·NNIBV-RT)
其中,J为目标函数;λ为拉格朗日乘子;RT为一帧图片的目标比特;A、B、C、βIBV和βNIBV是模型参数,NIBV和NNIBV表示一帧中IBV和NIBV的8×8块的数目,RIBV和RNIBV表示IBV和NIBV的比特率。
所述求解最优比特分配具体为:
λw=γ·λR+(1-γ)·λo
其中,δ为一个LCU中IBV所占的比重;λo为通过传统R-λ模型计算得到的拉格朗日乘子;γ为参数;λw为加权的拉格朗日乘子;λR为LCU拉格朗日乘子。
本发明提供的技术方案的有益效果是:本发明将深度图的区域特性结合到码率控制算法中,建立了深度视频区域间最优的比特分配方案、以及区域自适应R-λ码率控制模型,提高了深度视频码率控制的准确性以及绘制虚拟视点的主观质量和客观质量,提升了深度视频的编码效率。
附图说明
图1为"Ballet"视频序列区域划分结果的示意图;
(a)为原始深度视频的非关键帧;(b)为非关键帧的划分结果;(c)为原始深度中关键帧;(d)为关键帧的划分结果。
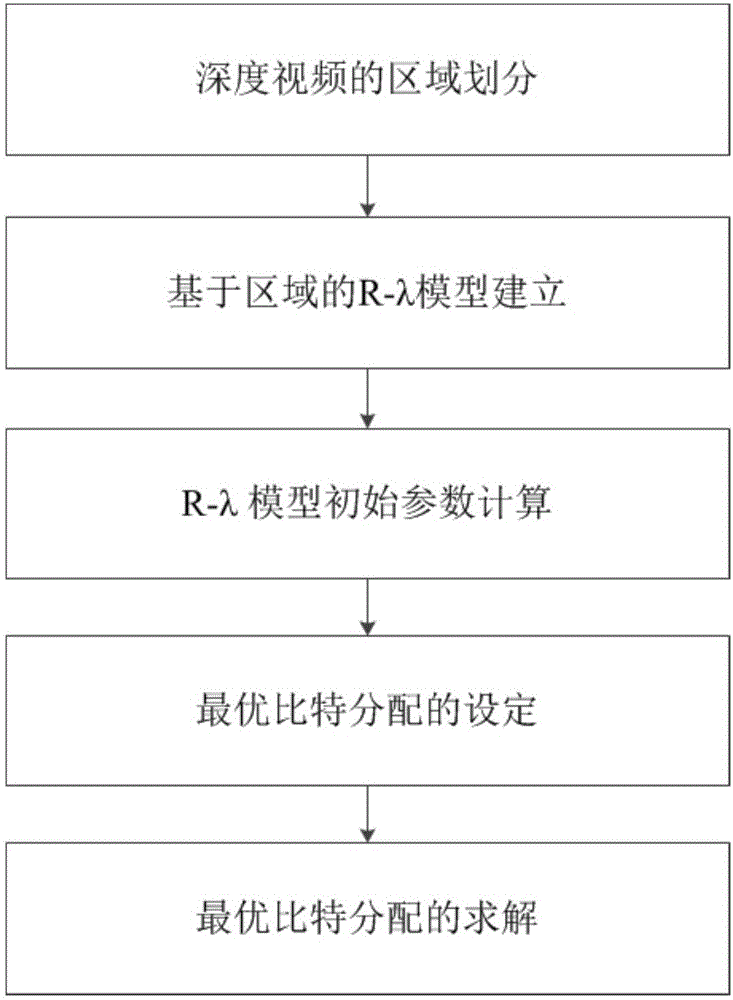
图2为一种基于区域自适应模型的深度视频码率控制方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
为了克服现有技术的不足,准确的实现深度视频的码率控制算法,提高绘制的虚拟视点的质量,本发明实施例提出了基于区域自适应模型的深度视频码率控制方法,具体的技术方案分为下列步骤:
101:将深度视频的区域划分为对绘制虚拟视点影响较大的区域IBV,其余的区域为对绘制虚拟视点影响较小的区域NIBV;其中,区域IBV为:物体的边界和剧烈运动的区域,
102:建立基于区域IBV和区域NIBV的R-λ模型;计算R-λ模型的初始参数;
103:基于区域R-λ模型的码率控制方法确定区域IBV和区域NIBV最优的比特分配,并求解最优比特分配。
其中,步骤102中的基于区域IBV和区域NIBV的R-λ模型具体为:
其中,j∈{IBV,NIBV},aj和bj是模型参数,Rj是j的平均比特,λj是j的拉格朗日乘子。
其中,步骤103中的基于区域R-λ模型的码率控制方法确定区域IBV和区域NIBV最优的比特分配的步骤具体为:
通过拉格朗日乘数法将限制条件下求极值的问题映射到等价的无约束条件的求极值问题,可得:
min J=A·exp(βIBVRIBV)+B·exp(βNIBVRNIBV)+C
+λ·(RIBV·NIBV+RNIBV·NNIBV-RT)
其中,J为目标函数;λ为拉格朗日乘子;RT为一帧图片的目标比特;A、B、C、βIBV和βNIBV是模型参数,NIBV和NNIBV表示一帧中IBV和NIBV的8×8块的数目,RIBV和RNIBV表示IBV和NIBV的比特率。
其中,步骤103中的求解最优比特分配具体为:
λw=γ·λR+(1-γ)·λo
其中,δ为一个LCU中IBV所占的比重;λo为通过传统R-λ模型计算得到的拉格朗日乘子;γ为参数;λw为加权的拉格朗日乘子;λR为LCU拉格朗日乘子。
综上所述,本发明实施例通过上述步骤101-步骤103建立了深度视频区域间最优的比特分配方案和区域自适应R-λ码率控制模型,提高了深度视频码率控制的准确性以及绘制虚拟视点的主观质量和客观质量,提升了深度视频的编码效率。
实施例2
下面结合具体的计算公式、实例对实施例1中的方案进行详细介绍,详见下文描述:
201:深度视频的区域划分;
深度图中物体的边界和剧烈运动的区域对绘制虚拟视点的质量影响很大。为了提高绘制虚拟视点的质量,本发明实施例将输入的深度图基于8×8大小的块分成对于绘制虚拟视点影响较大的区域(Interested Blocks for Virtual view rending,IBV)和对绘制虚拟视点影响较小的区域(Not Interested Blocks for Virtual view rending,NIBV)两种区域。具体来说,IBV包含两个部分:物体的边界和剧烈运动的区域,其余的部分为NIBV。
物体的边界由canny算子检测,当一个8×8大小的块内的边界像素的数目大于一个阈值Th(Th按照经验值设置为5),该块被标记为IBV。剧烈运动区域的检测分成以下两种情况:
1)对于非关键帧,运动矢量可以反映一个CU的运动情况。每个CU的MV(运动矢量,Motion Vector)都从已编码的彩色视频中获取,表示为(xp,yp)。MV的泛数(Norm of MV,NM)可由计算。如果NM大于一个阈值(根据经验值设置为32),MV对应的CU在输入的深度图上被标记为IBV。
2)由于关键帧使用帧内预测编码工具,关键帧中不存在MV。本方法根据CU的编码结构,将最小的CU标记为IBV来表示关键帧的运动情况。在编码当前CU之前,最小的CU也是未知的,用位于同一TL(时域层,Temporal Level)的已编码的参考帧中对应LCU(编码树单元,Largest Coding Unit)中最小CU来标记当前编码的LCU。
202:基于区域的R-λ模型建立;
HEVC(高效视频编码-)采用的R-λ模型符合双曲线函数。IBV和NIBV是一帧的一部分,双曲线R-λ模型也同样适用于只有IBV或者只有NIBV的区域。因此,IBV和NIBV的R-λ模型可以描述为:
其中,j∈{IBV,NIBV},aj和bj是模型参数,通过线性回归的方法求得;Rj是j的平均比特,λj是j的拉格朗日乘子。
203:R-λ模型初始参数计算;
其中,HEVC中的R-λ模型的初始参数不适用于深度视频的码率控制模型。深度视频整体消耗的比特数比彩色视频要少。同时,更新R-λ模型正确参数的过程会花费很长的时间,这个过程会造成大量的比特失真。因此,深度视频编码需要准确的R-λ模型的初始参数。R-λ模型中的α和β的初始值是由不同视频序列的模型拟合得到的。本发明实施例中,通过实验来统计适合深度视频模型的初始参数。
利用每个视频序列的QP的值从20到42间隔2变化一次的实验结果进行R-λ模型的拟合。深度视频编码中的R-λ模型的α和β的初始值设置为0.05和-1.728。在编码完一个LCU或者一帧的图片后,用实际消耗的bpp和实际编码中的λ来更新α和β。
204:最优比特分配的设定;
其中,基于区域R-λ模型的码率控制方法首先需要确定IBV和NIBV最优的比特分配。在给定一帧的目标比特RT的限定下,一帧内IBV和NIBV的比特分配问题可以转化为一个绘制虚拟视点失真最小化问题。此最小化的问题表示为:
min DV(RIBV,RNIBV)
s.t. RIBV·NIBV+RNIBV·NNIBV≤RT
其中,DV表示绘制虚拟视点的失真,NIBV和NNIBV表示一帧中IBV和NIBV的8×8块的数目,RIBV和RNIBV表示IBV和NIBV的比特率。为了对上述最优化的问题进行求解,虚拟视点的失真DV可以用IBV的比特率RIBV和NIBV的比特率RNIBV表示:
DV=A·exp(βIBVRIBV)+B·exp(βNIBVRNIBV)+C
其中,A、B、C、βIBV和βNIBV是模型参数。
为了使上述公式获取更加准确的参数,将深度视频在标准测试条件下进行预编码。将编码完的深度视频与原始彩色视频一起绘制虚拟视点,统计绘制虚拟视点的失真DV,IBV的比特率RIBV和NIBV的比特率RNIBV,以拟合上述公式得到准确的参数。因此,有限定条件的优化问题可以表示为如下公式:
min A·exp(βIBVRIBV)+B·exp(βNIBVRNIBV)+C
s.t. RIBV·NIBV+RNIBV·NNIBV≤RT
通过拉格朗日乘数法将限制条件下求极值的问题映射到等价的无约束条件的求极值问题,可得:
min J=A·exp(βIBVRIBV)+B·exp(βNIBVRNIBV)+C
+λ·(RIBV·NIBV+RNIBV·NNIBV-RT)
其中,J为目标函数;λ为拉格朗日乘子。
205:最优比特分配的求解。
计算J对RIBV、RNIBV和λ的偏导,并令其偏导为0:
求解方程的解便得到RIBV和RNIBV为:
代入步骤202中的公式,可以得到用于LCU级的码率控制的最优λIBV和λNIBV,得到LCU拉格朗日乘子:
其中,λR为LCU的拉格朗日乘子;δ为一个LCU中IBV所占的比重。
但是,若直接将λR用于编码当前的LCU,将造成LCU之间的质量差异过大,产生块效应,从而大大降低深度视频的质量。为了避免块效应,平滑深度图的质量,提出加权的拉格朗日乘子λw,其由λR和λo的平均得到。λo是由HEVC中的R-λ模型计算得到。λw表示为
λw=γ·λR+(1-γ)·λo
其中,λo为通过传统R-λ模型计算得到的拉格朗日乘子;γ设置为0.5。
综上所述,本发明实施例通过上述步骤201-步骤205建立了深度视频区域间最优的比特分配方案和区域自适应R-λ码率控制模型,提高了深度视频码率控制的准确性以及绘制虚拟视点的主观质量和客观质量,提升了深度视频的编码效率。
参考文献
[1]Ma S,Gao W,Lu Y.Rate-distortion analysis for H.264/AVC video coding and its application to rate control[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,15(12):1533-1544.
[2]Kamaci N,Altunbasak Y,Mersereau R M.Frame bit allocation for the H.264/AVC video coder via Cauchy-density-based rate and distortion models[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,15(8):994-1006.
[3]Lee B,Kim M,Nguyen T Q.A Frame-Level Rate Control Scheme Based on Texture and Nontexture Rate Models for High Efficiency Video Coding[J].IEEE Transactions onCircuits and Systems for Video Technology,2014,24(3):465-479.
[4]He Z,Mitra S K.Optimum bit allocation and accurate rate control for video coding viaρ-domain source modeling[J].IEEE Transactions on Circuits and Systems for Video Technology,2002,12(10):840-849.
[5]Gao W,Kwong S,Yuan H,et al.DCT Coefficient Distribution Modeling and Quality Dependency Analysis Based Frame-Level Bit Allocation for HEVC[J].IEEE Transactions on Circuits and Systems for Video Technology,2016,26(1):139-153.
[6]Li S,Xu M,Deng X,et al.Weight-based R-λ,rate control for perceptual HEVC coding on conversational videos[J].Signal ProcessingImage Communication,2015,38(C):127-140.
[7]Guo Y,LiB,Sun S,et al.Rate control for screen content coding in HEVC[J].IEEE International Symposium on Circuits and Systems.2015:1118-1121.
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!