基于并行GS迭代的大规模MIMO检测算法及硬件架构的制作方法
本发明属于计算机通信和数字电路领域,涉及一种大规模MIMO系统上行链路信号线性检测方法及其硬件架构。
背景技术:
大规模多输入多输出(MIMO)被认为是第5代(5G)无线系统的关键技术之一。通过装备大量天线(例如,在基站处安装数百个并且用户端安装数十个),该技术可以提供更高的频谱效率,更快的峰值数据速率以及比小规模MIMO系统上的更好的能量效率。然而,在大规模MIMO上行链路中,随着天线数目的显着增加,诸如最大似然(ML)检测和最大后验(MAP)检测的最佳检测方法在计算复杂度方面变得难以承受。因此研究人员将目光转向近似MAP算法(例如消息传递检测器)和近似ML检测算法(例如多分支和可能性上升搜索(LAS)检测器)。同时,线性检测方法,如迫零(ZF)和最小均方误差(MMSE),在大规模MIMO系统中因其次优性能和低复杂性特性备受关注。
虽然大规模MIMO有着优越的性能,但是天线量级的巨大增幅带来了计算复杂度的指数上升。目前已有多篇文章提出了大规模MIMO上行链路信号检测的算法及架构,其主要的计算复杂度在于一个高阶矩阵的求逆,假设M为用户数。若采用精确的矩阵求逆方法,如Cholesky分解法,则计算复杂度为O(M3)。那么当M的数量极大时,这样的求逆方案将带来巨大的计算和硬件消耗。
近几年,Linglong Dai等研究人员提出了基于Gauss-Seidel(GS)方法的软输出检测算法,该算法主要采用GS迭代方法求解线性方程组,从而避免了复杂度较高的矩阵精确求逆,但由于GS迭代方法固有的数据依赖特性,每轮迭代中的元素必须按顺序更新,不能并行计算,这使得该算法不利于高吞吐率的硬件实现。
技术实现要素:
发明目的:针对现有技术的不足,本发明提出了一种基于并行GS迭代的大规模MIMO检测算法(MMSE-PGS)及相应的硬件架构。通过略微改变原有GS迭代方法中元素的更新顺序,使得所提出的MMSE-PGS算法能够被并行实现,从而进一步提高硬件的吞吐率。根据数值模拟结果,本发明所提出的MMSE-PGS算法在复杂性和性能方面优于常规的基于NSE的方法,当迭代次数足够大时,所提出的MMSE-PGS算法能够达到和传统GS迭代检测算法一样的误码率性能。
技术方案:本发明提供了一种基于并行GS迭代方法的大规模MIMO线性检测算法,包括以下步骤:
步骤1:将信道矩阵H和接收信号y经过匹配滤波和矩阵运算,得到匹配滤波器输出yMF=HHy和规则化Gram矩阵W=G+NOIM,其中Gram矩阵G=HHH,NO为噪声方差,IM为M维单位矩阵,(.)H为共轭转置操作,M为矩阵W的维度,即发射天线数;
步骤2:计算系数矩阵A=D-1W和常数向量b=D-1yMF,使得系数矩阵对角线元素为1,其中D为W的对角阵;
步骤3:设置迭代初始解为x0=0和辅助向量初始化s=b,目标迭代次数K;
步骤4:开始迭代过程,每轮迭代中对矩阵和向量的每列进行并行运算,当行号和列号相同时,令xi=si,si=bi,否则令si=si-Aijxj,i和j分别为系数矩阵的行号和列号,K轮迭代后,xK即为待检测信号的估计结果。
一种实现上述的基于并行GS迭代的大规模MIMO线性检测算法的硬件架构,包括Gram矩阵&匹配滤波模块、预处理模块和并行GS迭代模块;
所述Gram矩阵&匹配滤波模块包括:由复数乘法累加器(MAC)组成的匹配滤波计算单元,用于计算yMF=HHy,以及规则化Gram矩阵计算单元,用于计算W=G+NOIM;
所述预处理模块包括:求倒数单元,用于计算W对角元素的倒数D-1,以及乘法器阵列,用于计算A=D-1W和b=D-1yMF;
所述并行GS迭代模块包括一个控制器和一系列结构相同的处理单元(PE),每个处理单元并行计算,实现xi=si,si=bi运算或si=si-Aijxj运算。
进一步地,每个处理单元(PE)包括:一个乘法器,用于计算Aijxj;一个加法器,用于计算si-Aijxj;一个寄存器,用于保存si的当前值;两个交换电路,用于切换PE工作模式,在模式1中PE执行si=si-Aijxj运算,在模式2中PE执行xi=si,si=bi运算。
进一步地,所述并行GS迭代模块中共有M个PE与控制器相连,控制器负责向PE输入Aij和bi,并与PE交换xi和xj;同时,控制器提供控制信号,负责切换PE的工作模式,经过K轮迭代后,控制器输出检测结果。
工作原理:考虑到大规模MIMO系统上行链路MMSE检测中滤波矩阵W为Hermitian正定阵且主对角线占优,本发明采用的并行GS迭代方法在多次迭代后一定收敛,有效避免了复杂度高的矩阵求逆过程,从而得到近似线性MMSE检测效果。另一方面,由于本发明采用的并行GS迭代方法打破了传统GS迭代方法的元素更新次序,因此在初始的几轮迭代内,性能略低于传统GS迭代方法,但随着迭代次数的增大,本发明采用的并行GS迭代方法最终功能能够达到和传统GS迭代方法一致的误码率效果。
有益效果:与现有技术相比,本发明重点考虑了计算复杂度和算法性能,有效避免了复杂度高的高阶矩阵求逆过程,且能够达到和传统GS迭代算法一致的检测效果(接近线性MMSE检测效果);由于并行化了传统的GS迭代方法,本发明采用的并行GS迭代方法减少了每轮迭代的硬件延时,有利于提高硬件吞吐率。另一方面,本发明为迭代算法,在软件编程方面可以节省内存消耗,在硬件实现方面具有节省面积的优点。
附图说明
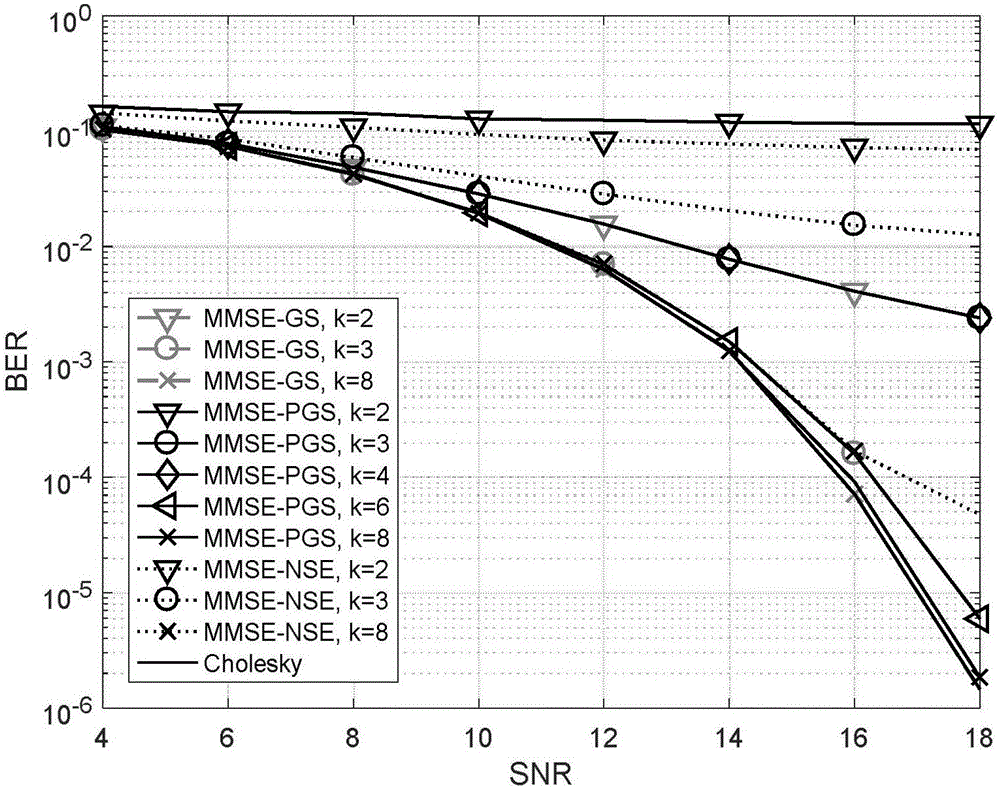
图1为发射天线(用户)数为16,接收天线数为64时,采用本发明信号检测算法和其他传统检测算法的误码率对比图;
图2为发射天线(用户)数为16,接收天线数为128时,采用本发明信号检测算法和其他传统检测算法的误码率对比图;
图3为本发明提供的基于并行GS迭代的大规模MIMO检测算法的硬件架构示意图;
图4为并行GS迭代模块硬件架构图及内部处理单元(PE)结构图;
图5为并行GS迭代模块时序调度示意图。
具体实施方式
本实施例中建立一个大规模MIMO上行链路系统进行模拟操作。在大规模MIMO上行链路中,一般有Nr》Nt(基站天线数Nr远大于发射天线数,即用户数Nt)。首先Nt个不同用户产生的并行传输比特流分别通过信道编码进行编码,然后映射到星座符号,并采取星座图集合能量归一化。让x=[x1,x2,x3,…,xNt]T表示信号向量,x中包含了分别从Nt个用户产生的传输符号,采用64-QAM方式映射。H表示维度是Nr×Nt信道矩阵,故上行链路基站端的接收信号向量y可以表示为
y=Hx+n
其中y的维度为Nr×1,n为Nt×1维的加性白噪声向量,其元素服从零均值方差为No的高斯分布。上行链路多用户信号检测任务就是从接收机接收向量y=[y1,y2,y3,…,yNr]T估计传输信号符号x。假设H已知(平坦Rayleigh衰落信道),其元素服从均值为0方差为1的独立同分布,采用最小均方误差(MMSE)线性检测理论,对传输信号向量的估计表示为
该估计过程等效为求解线性方程组
基于上述模型,本发明实施例公开的基于并行GS迭代方法的大规模MIMO线性检测算法,包括如下步骤:
步骤1:将信道矩阵H和接收信号y经过匹配滤波和矩阵运算,得到匹配滤波器输出yMF=HHy和规则化Gram矩阵W=HHH+NOIM;M为矩阵W的维度即发射天线(用户)数Nt;
步骤2:预处理,计算A=D-1W和b=D-1yMF,使得系数矩阵对角线元素为1;
步骤3:设置迭代初始解为x0=0和辅助向量初始化s=b,目标迭代次数K;
步骤4:开始迭代过程(M路并行操作),算法伪代码如下
在进行步骤4中的K轮迭代之后,xK即为待检测信号的估计结果。
上述检测算法的所需的复数乘法次数为(K+1)M2-(K-2)M,因此算法复杂度为
对于天线配置(Nr×Nt)为64×16和128×16的大规模MIMO系统,采用64-QAM映射,所述收敛速率可调的大规模MIMO迭代检测算法的仿真结果见图1、图2。可以看出,在迭代次数较大时(在具体应用时,可以根据仿真结果设置合理的迭代次数,通常10次以内,算法即有较好的性能),本发明提出的MMSE-PGS检测算法和传统的GS迭代检测算法(MMSE-GS)性能一致,且误码率性能均优于传统的Neumann级数检测算法(MMSE-NSE)。这说明,本发明不仅提高了GS迭代算法的并行性,使其更加适合硬件实现,而且并不牺牲原始GS算法的性能表现。
硬件架构方面,本实施例中采用的基于并行GS迭代的大规模MIMO检测器硬件架构顶层示意图如图3所示,其中计算模块包括了Gram矩阵&匹配滤波模块、预处理模块、并行GS迭代模块(SINR计算模块、LLR计算模块为软输出检测器所需要添加的模块,可参考本专利发明人2016年在IEEE上发表的基于GS迭代方法的大规模MIMO系统软输出检测算法的高效硬件架构)。
具体来说,在Gram矩阵&匹配滤波模块中,包含:
1)匹配滤波计算单元(MF):由Nt个复数乘法累加器(MAC)组成的线性脉动阵列,用于计算yMF=HHy;
2)规则化Gram矩阵计算单元:由(1+Nt)Nt/2个MAC组成的下三角脉动阵列,用于计算W=HHH+NOINt。
在预处理模块中,包含:
1)求倒数单元:由查找表(LUT)生成,用于计算对角元素的倒数D-1;
2)乘法器阵列:用于计算A=D-1W和b=D-1yMF。
在并行GS迭代模块中,包含:
1)控制器:将元素Aij,bi按MMSE-PGS算法中的顺序传递给处理单元(PE),并负责在每个时钟周期更新最新的迭代结果xi,xj;
2)处理单元(PE):共有Nt个PE,每个PE均能工作于模式1或者模式2,如图4所示。每个PE包括:一个乘法器,用于计算Aijxj;一个加法器,用于计算si-Aijxj;一个寄存器,用于保存si的当前值;两个交换电路,用于切换PE工作模式,在模式1中PE执行si=si-Aijxj运算,在模式2中PE执行xi=si,si=bi运算。Nt个PE与控制器相连,控制器负责向PE输入Aij和bi,并与PE交换xi和xj。同时,控制器提供控制信号,负责切换PE的工作模式。经过K轮外部迭代后,控制器输出检测结果。
在实际运行过程中,并行GS迭代模块的时序调度方式如图5所示:每轮并行GS迭代需要消耗Nt个时钟周期,其中第i个PE在第i个时钟工作于模式2(深色方块),其余时间工作于模式1(浅色方块),因此对于K次迭代,该模块共需要消耗KNt个时钟周期。这说明,本发明提出的并行GS迭代硬件架构在每轮迭代中的处理延时仅为传统GS迭代硬件架构延迟的一半,大大提高了硬件吞吐率。另一方面,由于引入的预处理和辅助变量,并行GS迭代模块中的每个PE采用的乘法器所需字长明显减少,进一步减少了整体硬件消耗。
- 还没有人留言评论。精彩留言会获得点赞!