自演进的网络自适应爬虫方法及系统与流程
本发明涉及互联网技术领域,尤其涉及一种自演进的网络自适应爬虫方法及系统。
背景技术:
互联网的信息每天海量增长,大量的信息中潜在着巨大的商业价值,网络爬虫为采集互联网中的海量信息而存在。由于互联网的信息过于巨大,这对网络爬虫的采集能力、经济性都是巨大的考验;同时,网络信息瞬息万变,及时采集这些信息也显得非常重要。
目前,网站为提供大流量处理能力的同时提供系统的可靠性,一般同时存在多个ip地址提供同等web服务。现有的爬虫主要包括2种采集方法,一种通过dns(domainnamesystem,域名系统)查询ip再访问,由于dnscache(缓存服务)原因,导致每次查到的ip是同样的,使爬虫不能充分利用多个服务端;另一种预先保存域名与ip地址对应关系,通过替换url中的域名为ip地址的方法实现负荷分担,这使爬虫对很多网站不能访问,因为很多目标网站限制只能使用域名访问,例如新浪微博等。
此外,互联网中不同的目标网站对采集系统有不同的限制策略,这使得网络爬虫不得不为各种目标网站增加各种配置项,开发人员不得不花费很多时间调试目标网站的参数,才能使爬虫系统正常工作,但是很多因素需要运行一段时间才会触发,因此每过一段时间需要检查其工作状态是否正常,分析大量日志,修改爬虫配置参数,再使其正常工作,整个过程中需要持续消耗研发人力。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种自演进的网络自适应爬虫方法及系统,以使提高爬虫的采集能力同时能够使爬虫自动适应目标网站的配置项。
为了解决上述技术问题,本发明实施例提出了一种自演进的网络自适应爬虫方法,包括:
步骤1:接收采集任务以及目标网站的ip地址或域名,当接收的为ip地址时直接进入步骤4,当接收的为域名时则根据域名查询对应的域名ip列表是否存在于自建的dns系统的记录中,记录若存在,则查询记录是否超时,若未超时,则进入步骤4;若记录不存在或记录超时,则进入步骤2;
步骤2:查询目标网站的域名对外提供服务的所有ip地址;
步骤3:探测查询到的ip地址是否有效,将有效的ip地址生成与目标网站对应的域名ip列表,并更新至自建的dns系统;
步骤4:探测并保存与目标网站对应的ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并基于域名ip列表结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;
步骤5:根据机器学习的规则知识库预测对应的采集模型,并根据采集模型设置爬虫的参数值,采集目标网站的数据。
相应地,本发明实施例还提供了一种自演进的网络自适应爬虫系统,包括:
采集模块:接收采集任务以及目标网站的ip地址或域名,当接收的为ip地址时,探测ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;当接收的为域名时则根据域名查询对应的域名ip列表是否存在于自建的dns系统的记录中,记录若存在,则查询记录是否超时,若未超时,则探测对应的域名ip列表内ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并基于域名ip列表结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;若记录不存在或记录超时,则查询目标网站的域名对外提供服务的所有ip地址,并探测查询到的ip地址是否有效,将有效的ip地址生成与目标网站对应的域名ip列表,并更新至自建的dns系统,再探测对应的域名ip列表内各ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,基于域名ip列表并结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;根据机器学习的规则知识库预测对应的采集模型,并根据采集模型设置爬虫的参数值,采集目标网站的数据。
本发明实施例通过提出一种自演进的网络自适应爬虫方法及系统,所述爬虫方法包括步骤1~步骤5,通过获取自建的dns系统中目标网站对外提供服务的所有ip地址列表并结合网络能力探测结果来生成负荷分担任务,以及通过机器学习的规则知识库预测最高成功率的采集模型,解决了爬虫采集能力差及需经常修改爬虫配置参数的问题,进而达到了提高爬虫的采集能力同时能够使爬虫自动适应目标网站的配置项的技术效果。
附图说明
图1是本发明实施例的自演进的网络自适应爬虫方法的流程示意图。
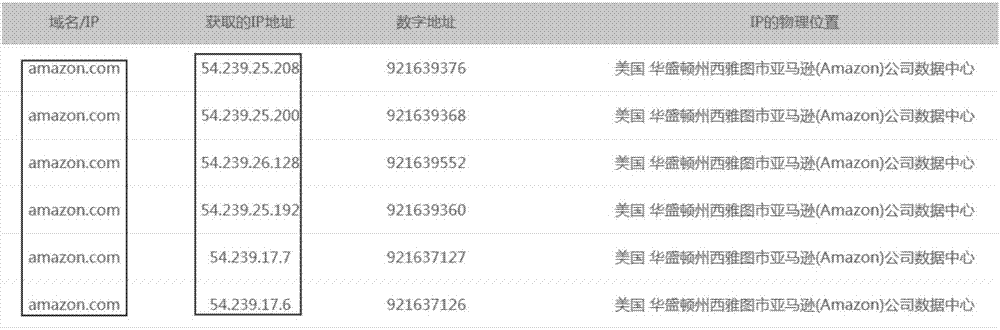
图2是本发明一种实施例的域名对应的ip地址的示意图。
图3是本发明实施例的请求头域参数的示意图。
图4是本发明实施例的自演进的网络自适应爬虫系统的结构示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
本发明实施例中若有方向性指示(诸如上、下、左、右、前、后……)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
另外,在本发明中若涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。
请参照图1,本发明实施例的自演进的网络自适应爬虫方法,包括:
步骤1:接收采集任务以及目标网站的ip地址或域名,当接收的为ip地址时直接进入步骤4,当接收的为域名时则根据域名查询对应的域名ip列表是否存在于自建的dns系统的记录中,记录若存在,则查询记录是否超时,若未超时,则进入步骤4;若记录不存在或记录超时,则进入步骤2。
步骤2:查询目标网站的域名对外提供服务的所有ip地址。查域名对应的所有ip地址的方法包括dns轮询、dig命令查询以及通过第3方网站查询(例如:http://centralops.net/co/或http://ip.chinaz.com/等)等。
步骤3:探测查询到的ip地址是否有效,将有效的ip地址生成与目标网站对应的域名ip列表,并更新至自建的dns系统。
步骤4:探测并保存与目标网站对应有效的ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并基于域名ip列表结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务。首次访问目标网站的ip地址时,探测ip地址的网络环境并保存网络探测结果,在预设期限内再次访问该ip地址时,则可以直接引用之前探测的网络探测结果;超过预设期限后再次访问该ip地址时,需重新探测探测ip地址的网络环境并保存网络探测结果。本发明实施例结合网络探测结果分配爬虫任务,网络探测结果包括对应ip地址服务器的网络能力等,例如,多个爬虫(节点、进程、线程)的爬取网页能力不同,爬取能力强的(例如网络带宽很大)就多分配任务,爬取能力弱的就少分配任务;比较空闲的爬虫(节点、进程、线程)就多取任务,比较忙的就少取任务,或者等任务处理完成后再取任务。例如,如图2所示,亚马逊(美国)对外提供服务,虽然域名都是amazon.com,但是其dns负载均衡的ip地址有多个,且每个ip地址都有完整、独立的服务提供能力;如果通过域名直接采集,在同一个区域通过dns获取到ip地址只有1个,其它服务器的能力将得不到利用。本发明实施例获取并保存所有ip地址,并结合网络探测结果,进行ip地址负荷分担,从而增大了并发请求数,提高了爬虫采集能力。
本发明实施例的网络环境探测内容包括:目标ip地址的服务可用性;目标网站网络带宽;目标网站ip并发连接数;目标网站对单个ip地址在不同速率下访问的可持续时长;网络时延;ip丢包率;目标操作系统类型;目标web服务程序名称、版本;防火墙类型探测;模拟pc(windows/linux/mac)请求,模拟mobile(android/ios)请求,比较响应消息的差异等;以上内容如果没有探测到,则反馈为空。本发明实施例的探测的结果还用于设置对应的爬虫参数值。
步骤5:根据机器学习的规则知识库预测对应的采集模型,并根据采集模型设置爬虫的参数值,采集目标网站的数据。预测的采集模型的基本参数包括:基于sourceip并发连接数阀值;基于sourceip的请求时延参数值;系统当前总体并发连接数阀值;请求头域参数,如图3所示;下载器选择(chrome/firefox/ie/safari/../自开发的downloader)等。本发明实施例的模型参数用于设置爬虫对应的参数值。
作为一种实施方式,步骤1之前还包括构建dns系统步骤:记录多个预设的域名ip列表,构建dns系统并保存于本地数据库中,所述域名ip列表包括预设网站的域名及与域名对应的多个ip地址。
作为一种实施方式,步骤2之前还包括定时更新步骤:定时触发更新任务,获取domain/ip数据库中的hot域名列表,domain/ip数据库存储有域名与ip列表直接的对应关系。domain/ip是一个内部存储着域名与ip列表直接的对应关系以及数据的更新时间信息的数据库。自建的dns系统在一段时间内,每次查询domain得到的ip地址是相同的,导致不能充分利用目标网站的多个ip地址系统的能力,因此,本发明实施例采用domain/ip本地缓存domain/iplist信息,替换dns系统功能。domain/ip数据库的更新触发机制包括定时触发及爬虫触发两种。定时触发即设置每间隔一定的时间(间隔时间也可以是一定时间范围内的随机值),触发更新domain/ip数据库内的域名与ip关系内容(查询的方式可以是自研dns轮询功能、dig命令、查询第三方网站都可以);爬虫触发即当收到爬虫的请求时,查询domain/ip数据库,domain的记录不存在时,立即去查询更新数据库内容,查询到内容后再反馈给dns系统。
作为一种实施方式,步骤5之前还包括机器学习步骤:根据预设的参数采用预设的机器学习算法构建规则模型并构建对应的规则知识库。优选地,预设的机器学习算法为tensorflow算法。本发明实施例实现的功能包括:
1.从成功的请求参数中抽取特性维度,并对维度进行rank打分;
2.从失败的请求参数中抽取特性维度,并对维度进行rank打分;
3.参数模型中,推荐成功率高的参数(例如多次请求之间的间隔时间为离散随机值),去除失败率高的独特参数(例如使用ie浏览器下载失败率过高,后续降低ie的使用频率);
4.从大量请求/响应参数中提取新的特征维度(例如:增加某种httpheader头域),再继续进行维度rank打分;提取的新特征维度从机器系统中输入到特征维度数据库,并在后续请求中逐渐增加特征维度的请求尝试;
5.系统自学演进记录到数据库中,供人工介入分析,并改进学习算法模型。
作为一种实施方式,步骤5之后还包括训练模型步骤:记录爬虫采集成功或失败的结果并提取对应采集结果的参数;将结果及参数反馈至机器学习引擎训练机器学习的规则模型,训练完成后保存至规则知识库。本发明实施例提取爬虫采集成功/识别的因子,并根据概率提供最高成功率的采集模型,首次访问目标网站时则采用预设的模型。本发明实施例采集的参数包括:下载器类型:chrome/firefox/ie/safari/../自开发的downloader;请求消息头域(header);响应消息头域(header);当前针对目标ip(destinationip)的并发连接数;当前源ip地址(sourceip)针对目标ip的并发连接数;当前源ip地址(sourceip)针对目标域名系统的并发连接数;(针对云防火墙场景)sourceip与destinationip间持续访问时长;响应消息的响应码、错误原因(http错误原因、tcp错误原因)等;以上内容如果没有探测到,则反馈为空。本发明实施例的反馈的参数用于机器学习引擎的输入。本发明实施例通过采集反馈的参数,经过机器学习引擎,自动改进后续请求下载模型参数,进而使爬虫能够自动适应目标网站的配置项。
请参照图4,本发明实施例的自演进的网络自适应爬虫系统,包括:
采集模块:接收采集任务以及目标网站的ip地址或域名,当接收的为ip地址时,探测ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;当接收的为域名时则根据域名查询对应的域名ip列表是否存在于自建的dns系统的记录中,记录若存在,则查询记录是否超时,若未超时,则探测对应的域名ip列表内ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,并基于域名ip列表结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;若记录不存在或记录超时,则查询目标网站的域名对外提供服务的所有ip地址,并探测查询到的ip地址是否有效,将有效的ip地址生成与目标网站对应的域名ip列表,并更新至自建的dns系统,再探测对应的域名ip列表内各ip地址的网络环境或引用在预设期限内的之前任务所探测对应的网络探测结果,基于域名ip列表并结合ip地址的网络探测结果进行负荷分担,分配爬虫的采集任务;根据机器学习的规则知识库预测对应的采集模型,并根据采集模型设置爬虫的参数值,采集目标网站的数据。
作为一种实施方式,自演进的网络自适应爬虫系统还包括构建dns系统模块:记录多个预设的域名ip列表,构建dns系统并保存于本地数据库中,所述域名ip列表包括预设网站的域名及与域名对应的多个ip地址。
作为一种实施方式,自演进的网络自适应爬虫系统还包括定时更新模块:定时触发更新任务,获取domain/ip数据库中的hot域名列表,domain/ip数据库存储有域名与ip列表直接的对应关系。
作为一种实施方式,自演进的网络自适应爬虫系统还包括机器学习模块:根据预设的参数采用预设的机器学习算法构建规则模型并构建对应的规则知识库。
作为一种实施方式,自演进的网络自适应爬虫系统还包括训练模型模块:记录爬虫采集成功或失败的结果并提取对应采集结果的参数;将结果及参数反馈至机器学习引擎训练机器学习的规则模型,训练完成后保存至规则知识库。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同范围限定。
- 还没有人留言评论。精彩留言会获得点赞!