视频剪辑方法和视频剪辑装置与流程
本发明总体说来涉及通信领域,更具体地讲,涉及一种视频剪辑方法和视频剪辑装置。
背景技术
连续的图像变化每秒超过24帧画面以上时,根据视觉暂留原理,人眼无法辨别单幅的静态画面,看上去是平滑连续的视觉效果,这样连续的画面叫做视频。目前,视频剪辑技术的应用越来越广泛,剪辑人员通常采用专业的剪辑软件对视频进行剪辑处理,以得到用户期望的视频内容。
然而,现有的视频剪辑技术主要采用人工手动的方式,从原始视频(即,已有的视频)中截取需要的视频片段,然后再进行拼接处理,这会造成在操作上耗费大量的时间,并且视频剪辑工作非常繁琐,导致视频剪辑的速度变慢,进而降低了剪辑视频的效率。
技术实现要素:
本发明的目的在于提供一种视频剪辑方法和视频剪辑装置,可以显著提高剪辑视频的效率,快速方便地得到用户感兴趣的视频内容。
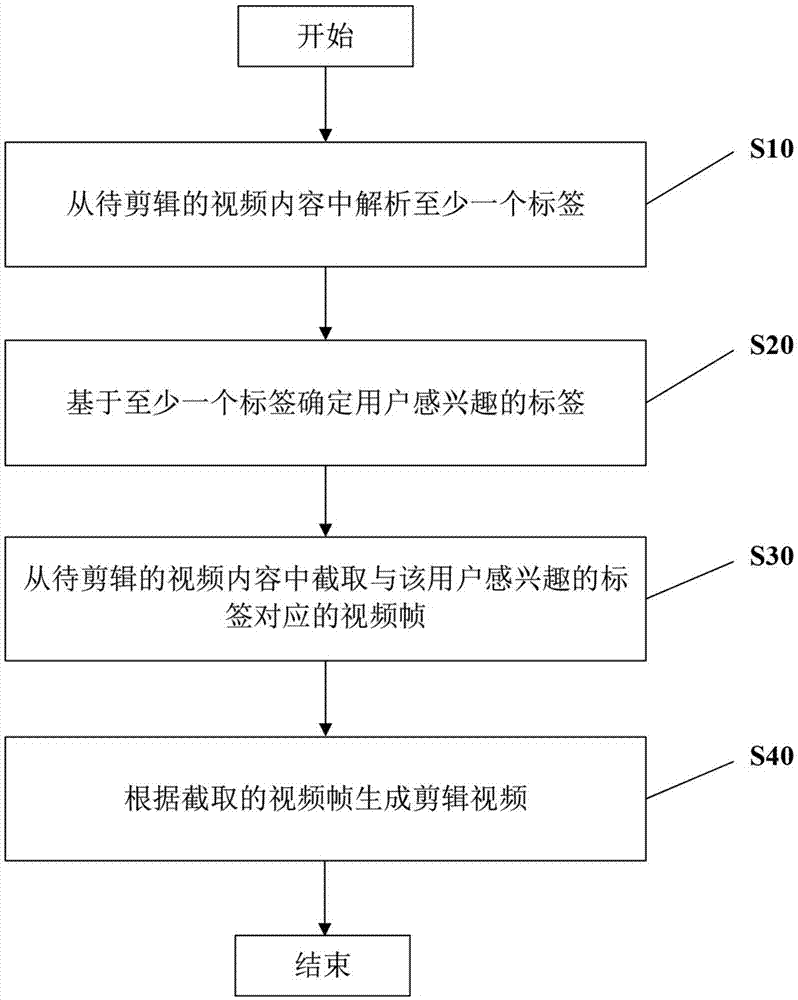
本发明的一方面提供一种视频剪辑方法,包括:(a)从待剪辑的视频内容中解析至少一个标签;(b)基于所述至少一个标签确定用户感兴趣的标签;(c)从待剪辑的视频内容中截取与所述用户感兴趣的标签对应的视频帧;(d)根据截取的视频帧生成剪辑视频。
可选地,所述至少一个标签包括:人物标签、物体标签和动作标签。
可选地,步骤(a)包括:识别待剪辑的视频内容中的人脸;将识别出的相同的人脸映射到同一个人物标签;输出映射得到的人物标签,和/或,步骤(a)包括:识别待剪辑的视频内容中的物体;输出用于指示识别出的物体的物体标签,和/或,步骤(a)包括:识别待剪辑的视频内容中的动作;输出用于指示识别出的动作的动作标签。
可选地,步骤(d)包括:对截取的视频帧进行编码以得到编码的视频文件;生成与编码的视频文件对应的字幕文件;生成与所述字幕文件对应的音频文件;对编码的视频文件、所述字幕文件和所述音频文件进行合成,以生成所述剪辑视频。
可选地,步骤(d)还包括:同步编码的视频文件和所述音频文件的时间戳。
可选地,所述视频剪辑方法还包括:接收用于生成剪辑视频的预定参数,其中,对编码的视频文件、所述字幕文件和所述音频文件进行合成的步骤包括:根据所述预定参数对编码的视频文件、所述字幕文件和所述音频文件进行合成。
可选地,所述预定参数包括:视频的格式和/或每秒传输帧数。
可选地,步骤(b)包括:响应于用户对所述至少一个标签的选择而将选择的标签确定为所述用户感兴趣的标签。
可选地,步骤(b)包括:基于用户的历史观看习惯从所述至少一个标签中确定所述用户感兴趣的标签,其中,所述历史观看习惯为从所述用户的互联网数据分析得到的反映所述用户观看视频的习惯的规律信息。
本发明的另一方面还提供一种视频剪辑装置,包括:解析单元,被配置为:从待剪辑的视频内容中解析至少一个标签;确定单元,被配置为:基于所述至少一个标签确定用户感兴趣的标签;截取单元,被配置为:从待剪辑的视频内容中截取与所述用户感兴趣的标签对应的视频帧;生成单元,被配置为:根据截取的视频帧生成剪辑视频。
可选地,所述至少一个标签包括:人物标签、物体标签和动作标签。
可选地,解析单元还被配置为:识别待剪辑的视频内容中的人脸,并将识别出的相同的人脸映射到同一个人物标签,输出映射得到的人物标签,和/或,解析单元还被配置为:识别待剪辑的视频内容中的物体,并输出用于指示识别出的物体的物体标签,和/或,解析单元还被配置为:识别待剪辑的视频内容中的动作,并输出用于指示识别出的动作的动作标签。
可选地,生成单元还被配置为:对截取的视频帧进行编码以得到编码的视频文件;生成与编码的视频文件对应的字幕文件;生成与所述字幕文件对应的音频文件;对编码的视频文件、所述字幕文件和所述音频文件进行合成,以生成所述剪辑视频。
可选地,生成单元还被配置为:同步编码的视频文件和所述音频文件的时间戳。
可选地,所述视频剪辑装置还包括:接收单元,被配置为:接收用于生成剪辑视频的预定参数,其中,生成单元还被配置为:根据所述预定参数对编码的视频文件、所述字幕文件和所述音频文件进行合成。
可选地,所述预定参数包括:视频的格式和/或每秒传输帧数。
可选地,确定单元还被配置为:响应于用户对所述至少一个标签的选择而将选择的标签确定为所述用户感兴趣的标签。
可选地,确定单元还被配置为:基于用户的历史观看习惯从所述至少一个标签中确定所述用户感兴趣的标签,其中,所述历史观看习惯为从所述用户的互联网数据分析得到的反映所述用户观看视频的习惯的规律信息。
本发明的另一方面还提供一种存储有计算机程序的计算机可读存储介质,其特征在于,当所述计算机程序被处理器执行时实现如上所述的视频剪辑方法。
本发明的另一方面还提供一种计算装置,其特征在于,包括:处理器;存储器,用于存储当被处理器执行使得处理器执行如上所述的视频剪辑方法的计算机程序。
本发明的视频剪辑方法和视频剪辑装置,通过用户感兴趣的标签对待剪辑的视频内容进行视频剪辑处理,可以显著提高剪辑视频的效率,快速方便地得到用户感兴趣的视频内容,极大地提升了用户体验。
附图说明
通过下面结合附图进行的详细描述,本发明的上述和其它目的、特点和优点将会变得更加清楚,其中:
图1示出根据本发明的实施例的视频剪辑方法的流程图;
图2示出根据本发明的实施例的生成剪辑视频的步骤的流程图;
图3示出根据本发明的实施例的视频剪辑装置的框图。
具体实施方式
现在,将参照附图更充分地描述不同的示例实施例,其中,一些示例性实施例在附图中示出。
下面参照图1至图3描述根据本发明的实施例的视频剪辑方法和视频剪辑装置。
图1示出根据本发明的实施例的视频剪辑方法的流程图。
在步骤s10,从待剪辑的视频内容中解析至少一个标签。
作为示例,至少一个标签可包括:人物标签、物体标签和动作标签等。
例如,人物标签可包括指示张三的标签和指示李四的标签等,物体标签可包括指示骆驼的标签、指示沙漠的标签和指示足球的标签等,动作标签可包括指示骑骆驼的标签、指示流水的标签、指示走路的标签和指示踢足球的标签等。
在一个实施例中,识别待剪辑的视频内容中的人脸;将识别出的相同的人脸映射到同一个人物标签;输出映射得到的人物标签。
应当理解,可通过各种能够从待剪辑的视频内容中识别出人脸的方法进行人脸识别,本发明对此不作限定。作为示例,可通过人脸识别技术识别待剪辑的视频内容中的人脸。
在另一实施例中,识别待剪辑的视频内容中的物体;输出用于指示识别出的物体的物体标签。
应当理解,可通过各种能够从待剪辑的视频内容中识别出物体的方法进行物体识别,本发明对此不作限定。作为示例,可通过使用卷积神经网络vgg16来识别待剪辑的视频内容中的物体。
在又一实施例中,识别待剪辑的视频内容中的动作;输出用于指示识别出的动作的动作标签。
应当理解,可通过各种能够从待剪辑的视频内容中识别出动作的方法进行动作识别,本发明对此不作限定。作为示例,可通过使用卷积神经网络cnn和长短时记忆网络lstm来识别待剪辑的视频内容中的动作。
在步骤s20,基于至少一个标签确定用户感兴趣的标签。
在一个实施例中,响应于用户对至少一个标签的选择而将选择的标签确定为该用户感兴趣的标签。
也就是说,接收用户从至少一个标签之中选择的标签,并将接收到的选择的标签作为该用户感兴趣的标签。
例如,当标签包括指示张三的标签、指示李四的标签、指示骆驼的标签、指示沙漠的标签、指示骑骆驼的标签和指示走路的标签时,将用户选择的指示李四的标签和指示走路的标签作为该用户感兴趣的标签。
在另一实施例中,基于用户的历史观看习惯从至少一个标签中确定该用户感兴趣的标签。
历史观看习惯可为从用户的互联网数据分析得到的反映该用户观看视频的习惯的规律信息。
例如,可从用户在社交网络中的好友印象、自我介绍、用户习惯等数据,分析出该用户的历史观看习惯,从而根据该历史观看习惯确定该用户感兴趣的标签。
在步骤s30,从待剪辑的视频内容中截取与用户感兴趣的标签对应的视频帧。
应当理解,可通过各种能够截取视频帧的方法从待剪辑的视频内容中截取与用户感兴趣的标签对应的视频帧,本发明对此不作限定。
作为示例,可从待剪辑的视频内容中截取与“指示李四的标签”对应的视频帧和与“指示走路的标签”对应的视频帧。
在步骤s40,根据截取的视频帧生成剪辑视频。
也就是说,基于截取的视频帧生成用户感兴趣的视频内容,从而显著提高剪辑视频的效率,快速方便地得到用户感兴趣的视频内容。
下面结合图2详细描述生成剪辑视频的步骤。
图2示出根据本发明的实施例的生成剪辑视频的步骤的流程图。
参照图2,在步骤s410,对截取的视频帧进行编码以得到编码的视频文件。
作为示例,对与“指示李四的标签”对应的视频帧和与“指示走路的标签”对应的视频帧进行编码,以得到显示“李四正在走路”编码的视频文件。
优选地,可将截取的视频帧编码成图像互换格式(gif)的视频文件或无字幕和音频的视频文件。
作为示例,可通过开源计算机程序(例如,ffmpeg)对截取的视频帧进行编码以得到编码的视频文件。
在步骤s420,生成与编码的视频文件对应的字幕文件。
应当理解,可通过各种能够生成与编码的视频文件对应的字幕文件的方法来进行字幕文件的生成,本发明对此不作限定。作为示例,可使用卷积神经网络cnn和长短时记忆网络lstm来生成该字幕文件。
在一个实施例中,可采用参数共享和增加标签属性来对用户感兴趣的标签进行细分,从而解决语法多义性的问题。
作为示例,如果编码的视频文件显示“李四正在走路”,可能会生成字幕文件:“李四正在走路”、“李四正在跑步”和“李四正在散步”等。可通过对用户感兴趣的标签进行细分,准确生成字幕文件“李四正在走路”。
在步骤s430,生成与该字幕文件对应的音频文件。
应当理解,可通过各种能够生成与字幕文件对应的音频文件的方法来进行音频文件的生成,本发明对此不作限定。作为示例,可使用文字语音合成技术(tts)来生成该音频文件。
作为示例,可生成“李四正在走路”的配音。
在步骤s440,对编码的视频文件、该字幕文件和该音频文件进行合成,以生成该剪辑视频。
作为示例,对显示“李四正在走路”的编码的视频文件、“李四正在走路”的字幕文件和“李四正在走路”的配音进行合成,生成用户感兴趣的剪辑视频。
应当理解,可通过各种能够合成视频文件、字幕文件和音频文件的方法来生成剪辑视频,本发明对此不作限定。
优选地,步骤s440还包括:同步编码的视频文件和该音频文件的时间戳。
也就是说,使编码的视频文件和该音频文件的时间戳保持一致。
例如,在编码的视频文件中,第一帧到第100帧对应的画面是李四正在走路,如果每秒传输帧数(fps)为50,则对应的时长为2秒,那么,“李四正在走路”的配音的时间戳为0秒至2秒。
此外,所述视频剪辑方法还包括:接收用于生成剪辑视频的预定参数。
作为示例,预定参数可包括:视频的格式和/或每秒传输帧数等。
在此情况下,步骤s440可根据该预定参数对编码的视频文件、该字幕文件和该音频文件进行合成。
作为一个示例,可根据接收的视频的格式对编码的视频文件、该字幕文件和该音频文件进行合成,以得到该格式的剪辑视频。
作为又一示例,可根据接收的每秒传输帧数对编码的视频文件、该字幕文件和该音频文件进行合成,以得到具有该每秒传输帧数的剪辑视频。
下面结合具体示例来详细描述根据本发明的实施例的视频剪辑方法。
从待剪辑的视频内容中解析出指示张三的标签、指示李四的标签、指示骆驼的标签、指示沙漠的标签、指示骑骆驼的标签和指示流水的标签,然后将用户选择的“指示张三的标签”和“指示骑骆驼的标签”作为该用户感兴趣的标签。接着,从待剪辑的视频内容中截取与“指示张三的标签”对应的视频帧和与“指示骑骆驼的标签”对应的视频帧,并将截取的视频帧编码成显示“张三正在骑骆驼”的视频文件。然后,生成“张三正在骑骆驼”的字幕文件和配音文件,最后合成该视频文件、该字幕文件和该配音文件,并同步该视频文件和该配音文件的时间戳,得到用户感兴趣的剪辑视频。
下面结合图3来详细描述本发明的实施例的视频剪辑装置。
图3示出根据本发明的实施例的视频剪辑装置的框图。
参照图3,根据本发明的实施例的视频剪辑装置包括:解析单元100、确定单元200、截取单元300和生成单元400。
解析单元100从待剪辑的视频内容中解析至少一个标签。
作为示例,至少一个标签可包括:人物标签、物体标签和动作标签等。
例如,人物标签可包括指示张三的标签和指示李四的标签等,物体标签可包括指示骆驼的标签、指示沙漠的标签和指示足球的标签等,动作标签可包括指示骑骆驼的标签、指示流水的标签、指示走路的标签和指示踢足球的标签等。
在一个实施例中,解析单元100识别待剪辑的视频内容中的人脸,并将识别出的相同的人脸映射到同一个人物标签,输出映射得到的人物标签。
应当理解,解析单元100可通过各种能够从待剪辑的视频内容中识别出人脸的方法进行人脸识别,本发明对此不作限定。作为示例,解析单元100可通过人脸识别技术识别待剪辑的视频内容中的人脸。
在另一实施例中,解析单元100识别待剪辑的视频内容中的物体,并输出用于指示识别出的物体的物体标签。
应当理解,解析单元100可通过各种能够从待剪辑的视频内容中识别出物体的方法进行物体识别,本发明对此不作限定。作为示例,解析单元100可通过使用卷积神经网络vgg16来识别待剪辑的视频内容中的物体。
在又一实施例中,解析单元100识别待剪辑的视频内容中的动作,并输出用于指示识别出的动作的动作标签。
应当理解,解析单元100可通过各种能够从待剪辑的视频内容中识别出动作的方法进行动作识别,本发明对此不作限定。作为示例,解析单元100可通过使用卷积神经网络cnn和长短时记忆网络lstm来识别待剪辑的视频内容中的动作。
确定单元200基于至少一个标签确定用户感兴趣的标签。
在一个实施例中,确定单元200响应于用户对所述至少一个标签的选择而将选择的标签确定为该用户感兴趣的标签。
也就是说,确定单元200接收用户从至少一个标签之中选择的标签,并将接收到的选择的标签作为该用户感兴趣的标签。
例如,当标签包括指示张三的标签、指示李四的标签、指示骆驼的标签、指示沙漠的标签、指示骑骆驼的标签和指示走路的标签时,确定单元200将用户选择的指示李四的标签和指示走路的标签确定为该用户感兴趣的标签。
在另一实施例中,确定单元200基于用户的历史观看习惯从至少一个标签中确定该用户感兴趣的标签。
历史观看习惯为从用户的互联网数据分析得到的反映该用户观看视频的习惯的规律信息。
例如,确定单元200可从用户在社交网络中的好友印象、自我介绍、用户习惯等数据,分析出该用户的历史观看习惯,从而根据该历史观看习惯确定该用户感兴趣的标签。
截取单元300从待剪辑的视频内容中截取与该用户感兴趣的标签对应的视频帧。
作为示例,截取单元300可从待剪辑的视频内容中截取与“指示李四的标签”对应的视频帧和与“指示走路的标签”对应的视频帧。
生成单元400根据截取的视频帧生成剪辑视频。
也就是说,生成单元400基于截取的视频帧生成用户感兴趣的视频内容。
在一个实施例中,生成单元400对截取的视频帧进行编码以得到编码的视频文件,生成与编码的视频文件对应的字幕文件,生成与该字幕文件对应的音频文件,对编码的视频文件、该字幕文件和该音频文件进行合成,以生成剪辑视频。
作为示例,生成单元400对与“指示李四的标签”对应的视频帧和与“指示走路的标签”对应的视频帧进行编码,以得到显示“李四正在走路”编码的视频文件,生成字幕文件“李四正在走路”,并生成“李四正在走路”的配音,然后,对显示“李四正在走路”的编码的视频文件、“李四正在走路”的字幕文件和“李四正在走路”的配音进行合成,生成用户感兴趣的剪辑视频。
此外,生成单元400还同步编码的视频文件和该音频文件的时间戳。
优选地,生成单元400可将截取的视频帧编码成图像互换格式(gif)的视频文件或无字幕和音频的视频文件。
作为示例,生成单元400可使用开源计算机程序(例如,ffmpeg)对截取的视频帧进行编码以得到编码的视频文件。
优选地,生成单元400可使用卷积神经网络cnn和长短时记忆网络lstm来生成字幕文件。
优选地,生成单元400可使用文字语音合成技术来生成音频文件。
此外,所述视频剪辑装置还包括:接收单元(未示出)。
接收单元接收用于生成剪辑视频的预定参数。
作为示例,预定参数可包括:视频的格式和/或每秒传输帧数。
在此情况下,生成单元400可根据该预定参数对编码的视频文件、该字幕文件和该音频文件进行合成。
作为一个示例,生成单元400可根据接收的视频的格式对编码的视频文件、该字幕文件和该音频文件进行合成,以得到该格式的剪辑视频。
作为又一示例,生成单元400可根据接收的每秒传输帧数对编码的视频文件、该字幕文件和该音频文件进行合成,以得到具有该每秒传输帧数的剪辑视频。
此外,本发明的实施例的视频剪辑方法和视频剪辑装置,通过用户感兴趣的标签对待剪辑的视频内容进行视频剪辑处理,可以显著提高剪辑视频的效率,快速方便地得到用户感兴趣的视频内容,极大地提升了用户体验。
根据本发明的实施例还提供一种存储有计算机程序的计算机可读存储介质,当所述计算机程序被处理器执行时实现如上所述的视频剪辑方法。
根据本发明的实施例还提供一种计算装置。该计算装置包括处理器和存储器。存储器用于存储当被处理器执行使得处理器执行如上所述的视频剪辑方法的计算机程序。
此外,应该理解,根据本发明示例性实施例的视频剪辑装置中的各个单元可被实现硬件组件和/或软件组件。本领域技术人员根据限定的各个单元所执行的处理,可以例如使用现场可编程门阵列(fpga)或专用集成电路(asic)来实现各个单元。
尽管已经参照其示例性实施例具体显示和描述了本发明,但是本领域的技术人员应该理解,在不脱离权利要求所限定的本发明的精神和范围的情况下,可以对其进行形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!