一种基于多轮语音聊天模型构建方法与流程
本发明涉及人机对话系统,尤其涉及一种基于多轮对话模型构建方法。属于智能软件技术领域。
背景技术:
1、国外技术现状
(1)基于人工模板的对话系统
基于人工模板的技术通过人工设定对话场景,并对每个场景写一些针对性的对话模板,模板描述了用户可能的问题以及对应的答案模板。
weizenbaum等人(1966)开发出最早的聊天机器人eliza,eliza根据对话中可能出现的语言情况,去预先设计对应的语言模板,文本生成器会根据用户的输入将输入中的重要信息嵌入到模板中,最终得到回复。
他们都将聊天限制到特定场景或者特定的话题,并且使用一组模板规则来生成响应。
(2)基于检索的对话系统
基于检索技术的聊天机器人则使用是类似搜索引擎的方法,事先存储好对话库并建立索引,根据用户问句,在对话库中进行模糊匹配找到最合适的应答内容。
shaikh等人(2010)构建了一个虚拟聊天机器人(vca),可以在聊天室中与人们进行初步的社交,他们使用一种新颖的方法来利用正在进行的对话主题来进行网络搜索,并找到可以插入对话中的相关主题来改变其流程,可以看作是基于检索和以及模板方法的融合。
(3)基于深度学习的对话生成模型
深度学习技术在对话生成中的应用主要是面向开放域聊天机器人,因为大规模通用语料的获取较为容易,最常用的借鉴机器翻译的sequencetosequence模型,将对话生成的由问题到回复的整个过程视为机器翻译中从源语言到目标语言的翻译过程。
ritter等人(2011)使用了从twitter中获取的对话语料,利用seq2seq模型使得效果超过了基于检索系统的对话模型。
sordoni等人(2015)提出一个对话生成系统,该系统考虑到了对话中的上下文信息,从而在回复一致性上取得提升。
serban等人(2016)提出了hierarchicalnerualnetwork模型,旨在对对话中上下文的语义和交互进行建模,从而构建一个多轮的对话系统。
jiweili等人(2016)致力于解决传统seq2seq模型生成通用回复的问题,引入了互信息作为目标函数,提高了生成回复的多样性。同时jiweili(2016)使用改进的seq2seq模型对用户风格进行了建模,在解码端引入了用户embedding作为先验,从而提高了对话系统的一致性和相关性。
louisshao等人(2017)改进了seq2seq模型的训练方法和decode端,并且加入了beam-search,从而提高模型生成的回复长度以及一致性和相关性。
2、国内技术现状
国内因为起步较晚,在对话系统方面的研究也主要是基于深度学习的方法,lihang等人(2015)提出了neuralrespondingmachine,使用改进的seq2seq模型,加入attention机制并使用多个模型进行融合从而在短文本对话系统上取得了不错的结果。
moulili(2016)着眼于解决传统seq2seq模型生成通用回复的问题,提出先seq2bf模型,通过使用互信息先预测关键词,再基于关键词进行回复句子的生成。
同时zongchengji(2014)则使用基于检索的方法,使用最先进的信息检索技术,依靠庞大的对话语料库,创建了一个相对智能的对话系统。
3、国内外文献综述的简析
目前国内外对于开放域对话生成系统的研究主要包括基于模板的方法,基于检索的方法以及基于深度学习的方法。早期时的基于模板的方法没有进行真正的语言处理,生成的语言僵硬,形式化,往往存在语义和流畅度方面的问题,相对于开放域对话系统,该方法更适合任务型聊天机器人。
基于检索的方法是在已有的人人对话语料库中通过排序学习技术和深度匹配技术找到适合当前输入的最佳回复。这种方法的局限是仅能以固定的语言模式进行回复,无法实现词语的多样性组合。
目前最流行的方法是基于深度学习的方法,使用来自机器翻译任务的seq2seq模型,一般是encoder-decoder结构,配合较大规模的对话语料,用于实现端到端的训练,从而获得一个对话系统。该方法能够突破之前的方法对于句式词语的限制,主要是对用户输入的问题进行建模,然后根据中间结果进行逐字的生成,可以创造性地生成回复,目前绝大多数研究都是基于该模型的拓展或者改进。
但是基于深度学习的方法依赖于大规模语料,seq2seq模型训练速度受到语料规模的影响,并且由于对话生成的回复不唯一性,seq2seq模型总是倾向于生成通用,无意义的回复,例如“你好”,“我也不知道”,“哈哈”等等。
再者目前大多数对话系统都致力于优化单轮对话即一问一答过程的质量,聊天是一个有特定背景的连续交互过程,一句话的意义有时要结合对话上下文或者相关的背景才能确定。对于上下文建模依然是有待深入研究的问题。
技术实现要素:
本发明的目的在于,针对上述问题,提出一种基于多轮对话模型构建方法,以实现人机多轮对话的目的。
为实现上述目的,本发明采用的技术方案是:
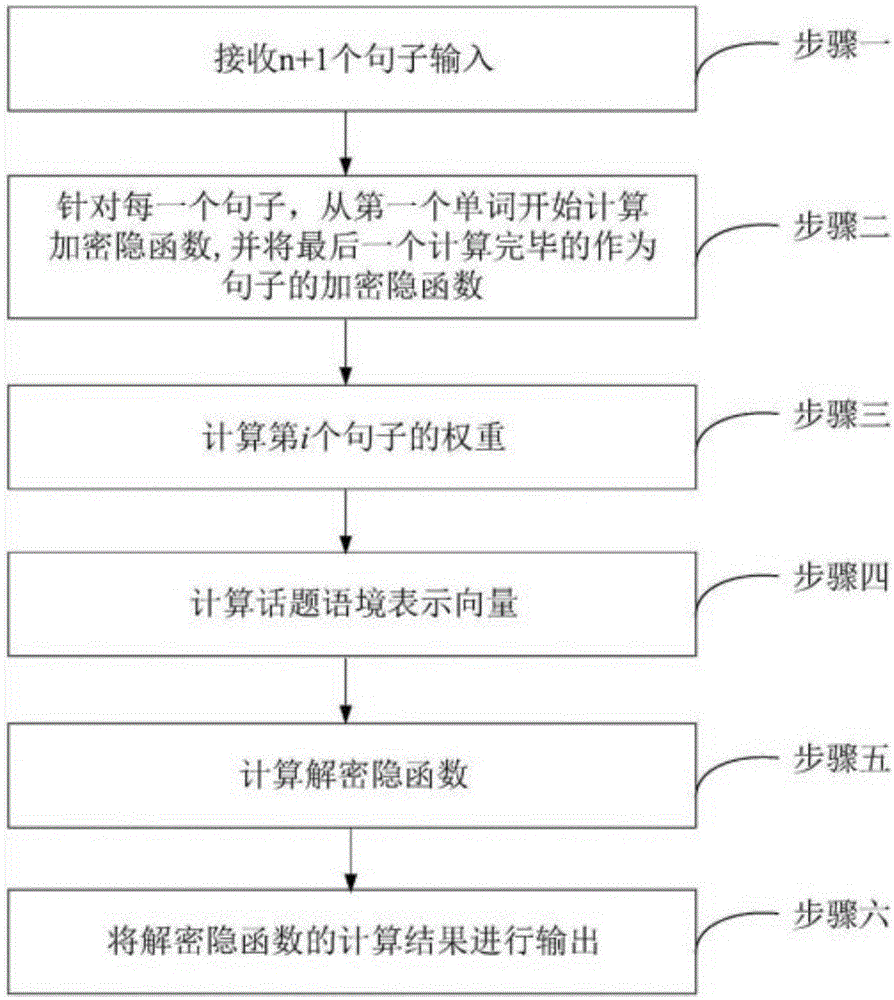
步骤一、接收n+1个句子输入;
步骤二、针对每一个句子ci,从第一个单词开始计算加密隐函数hi,t=f(xi,t,hi,t-1),其中其中xi,t代表ci第t个单词;其中hi,0记为预设参数;并将最后一个计算完毕的hi,t记为句子ci的加密隐函数hi;
步骤三、计算第i个句子的attention权重其中ei=vttanh(whi+uhn);v、w、u均为attention机制中的预设参数;tanh为激活函数;
步骤四、计算话题语境表示向量t=∑αihi;
步骤五、计算解密隐函数st=f(yt-1,st-1,t),yt-1表示t-1时刻的迭代输入量,y0为预设值;s0=hn;
步骤六、将s1,s2,……st……sn的值作为结果进行输出。
本发明还提供另一种基于多轮对话模型的构建方法,包括:
步骤一、接收n+1个句子输入;
步骤二、针对每一个句子ci,从第一个单词开始计算加密隐函数hi,t=f(xi,t,hi,t-1),其中其中xi,t代表ci第t个单词;其中hi,0记为预设参数;并将最后一个计算完毕的hi,t记为句子ci的加密隐函数hi;
步骤三、计算第i个句子中第t个单词的attention权重其中eit=vttanh(whi+ust-1);v、w、u均为attention机制中的预设参数;st-1为t-1时刻的隐层状态;
步骤四、计算动态表示向量dt=αithi;
步骤五、计算解密隐函数st=f(yt-1,st-1,t),yt-1表示t-1时刻的迭代输入量,y0为预设值;s0=hn;
步骤六、将s1,s2,……st……sn的值作为结果进行输出。
进一步地,本发明的有益效果为:
1、不依赖于大规模语料,训练速度不受到语料规模的影响,不会倾向于生成通用、无意义的回复;
2、本发明在opensubtitles数据集和ubuntu数据集上进行了测试。
在opensubtitles数据集上,本发明的embeddingaverage最高可达到0.565647,明显高于现有技术的0.557139;本发明的greedymatching最高可达到0.523235,明显高于现有技术的0.503273;本发明的extrema最高可达到0.393724,高于现有技术的0.393189。
在ubuntu数据集上,本发明的embeddingaverage最高可达到0.612089,明显高于现有技术的0.577022,本发明的greedymatching最高可达到0.429328,明显高于现有技术的0.416948,本发明的extrema最高可达到0.397543,高于现有技术的0.391392。
附图说明
图1为本发明的基于多轮对话模型构建方法的流程图;
图2为本发明具体实施方式一步骤二中计算加密隐函数过程的示意图;其中context指的是句子输入co,c1,…cn组成的上下文;
图3为本发明具体实施方式一步骤三至步骤五的示意图;其中topicnet表示计算话题语境表示向量t的计算模块,topicvector表示话题语境表示向量;解码器用于计算解密隐函数;由hn指向解码器的箭头表示解密隐函数的计算需要用到hn的值。
具体实施方式
以下结合实施例对本发明进一步说明:
具体实施方式一:
本发明提供一种基于层次化注意力机制的多轮对话模型构建方法,如图1所示,包括:
步骤一、接收n+1个句子输入。
步骤二、针对每一个句子ci,从第一个单词开始计算加密隐函数hi,t=f(xi,t,hi,t-1),其中其中xi,t代表ci第t个单词;其中hi,0记为预设参数;并将最后一个计算完毕的hi,t记为句子ci的加密隐函数hi。
步骤三、计算第i个句子的attention权重其中ei=vttanh(whi+uhn);v、w、u均为attention机制中的预设参数。
步骤四、计算话题语境表示向量t=∑αihi。
步骤五、计算解密隐函数st=f(yt-1,st-1,t),yt-1表示t-1时刻的迭代输入量,0为预设值;s0=hn;当步骤一中接收的句子输入为训练数据时,yt-1为预设的标准答案单词,当步骤一中接收的句子输入为实测数据时,yt-1的值等同于st-1。
步骤六、将st的值作为结果进行输出。
具体而言,本发明的方式是基于机器翻译任务的seq2seq模型,并且采用的是encoder-decoder结构,这种模型和结构的特点是,对于一个句子ci,将其中包含的每个单词xi,t顺序输入模型,模型对于每一个xi,t根据公式计算相应的加密隐函数(如图2所示),其计算结果用于计算下一个加密隐函数,以此类推,最后一个加密隐函数输出的值作为整个句子的加密隐函数hi,由于一共输入了n+1个句子,因此也会得到n+1个加密隐函数。然后根据这些加密隐函数计算attention权重,attention机制也是常用的机制,本发明对其公式形式进行了修改,对公式的改进主要是在计算每一句的权重时,考虑到了当前句子的加密隐函数和所有句子中最后一句的隐函数(即公式ei=vttanh(whi+uhn)中的hi表示当前句子的加密隐函数,hn表示最后一句的加密隐函数),然后再根据权重计算话题语境表示向量t,该向量包含了加密端的必要信息,最后解密端对这个向量进行解密(用于解密的函数即st=f(yt-1,st-1,t))得到结果,如图3所示。实际处理数据时,yt-1是输出的结果,st就是yt,即t时刻输出的单词,而在训练过程中,为了保证训练的效果,st是实际的输出,而yt-1是预设好的单词,即标准答案中的单词。
可以看出本发明的方法不仅基于当前问题进行回复,也会考虑到当前语境及上下文信息,可以将这个过程视为记忆过程,人们从记忆中读取信息,结合当前问题,从而给出回复。本项工作使用记忆网络(memorynetwork)对整个上下文进行处理,端到端的记忆网络可以被用于qa任务或者阅读理解,通过建模来获取文档的表示以此完成不同的任务。
本项工作将上下文中最后一句视为key(即即公式ei=vttanh(whi+uhn)中的hn),其余句子视为memory,以此计算整个上下文的表示,该部分作为seq2seq模型的加密端,结果输入到解密端,用于解码出回复。同时可以考虑到memory中句子的时序信息,赋予各个句子不同的权重,以此来获得更好的上下文表示。
具体实施方式二:
本发明还提供另一种基于层次化注意力机制的多轮对话模型构建方法,包括:
步骤一、接收n+1个句子输入co,c1,…cn。
步骤二、针对每一个句子ci,从第一个单词开始计算加密隐函数hi,t=f(xi,t,hi,t-1),其中其中xi,t代表ci第t个单词;其中hi,0记为预设参数;并将最后一个计算完毕的hi,t记为句子ci的加密隐函数hi。
步骤三、计算第i个句子中第t个单词的attention权重其中eit=vttanh(whi+ust-1);v、w、u均为attention机制中的预设参数;st-1为t-1时刻的隐层状态。
步骤四、计算动态表示向量dt=αithi。
步骤五、计算解密隐函数st=f(yt-1,st-1,dt),yt-1表示t-1时刻的迭代输入量,y0为预设值;s0=hn。
步骤六、将st的值作为结果进行输出。
本实施方式与具体实施方式的不同之处在于,步骤三中计算attention权重的方式不同,本实施方式是针对每一句的每一个单词都计算权重,而具体实施方式一是仅针对整句计算一个权重。另一处区别是权重具体计算时不再使用最后一句的加密隐函数hn,而是使用上一时刻的隐层状态st-1。具体实施方式一和具体实施方式二都是基于“考虑整篇上下文,并选用key值计算权重”这一发明思路的,只不过选取的key值一个是选最后一句的加密隐函数,另一个是选解密端的隐层状态。
在本发明中,使用了深度学习的方法对上下文信息的进行建模,从而优化对话质量,提高生成回复的相关性和一致性。本项专利使用的主要模型是seq2seq模型,结构为encoder-decoder结构(加密端-解密端结构),因为最终目标是解码生成一个语义流畅,一致性相关性较好的回复,decoder(解密端)必须是一个较好的语言模型,所以decoder都是基于rnn的实现。
传统seq2seq模型只是考虑单轮对话的问题和回复,但人们进行对话时不仅会考对话当前所说的话,也会考虑到当前语境及上下文信息,不过在多轮对话中,当前句也就是时间上距离当前回复最近的句子被视为最重要的句子,因为生成回复是对于该句子的直接回复。为了获取整个上下文的信息,从而对语境话题建模,本项工作使用rnn对上下文的所有语句进行建模,从而得到多个表示,然后参考机器翻译中的注意力机制,对上下文进行层次化的注意力计算,得出上下文的attented表示,并以此作为话题语境的表示,加入到解码端用于辅助解码,从而生成一致性相关性更好的回复。
下面具体说明本发明的有益效果:
目前对开放域环境下的聊天机器人评价的方法主流有两种思路,客观指标评价与主观人工评分。本项工作使用的客观指标部分的主要是以embeddingaverage,greedymatching,vectorextrema为代表的基于词向量的评价矩阵。
上述客观指标的基本原理都是计算生成的候选回复和参考答案的目标回复之间的相似度,以此作为回复质量的评分,基本方法是通过了解每一个词的意思来判断回复的相关性,词向量是实现这种评价方法的基础。依据语义分布,给每一个词分配一个向量用于表示这个词,再通过各种方法可以分别得到候选回复与目标回复的句向量,再通过余弦距离进行比较,就可以得到二者的相似度。
opensubtitles是一个国际知名字幕网站,提供各国语言的字幕下载,可以从中获得由电影对白组成的英文对话数据集;ubuntu数据集是ubuntu论坛上讨论贴上的聊天记录组成的英文对话数据集。本专利工作获取了100000个opensubtitles对话场景,处理成了800000个多轮对话session,在此基础上使用word2vec预训练词向量,得到了30000+的词表;ubuntu数据集上则得到了约450000个多轮对话session,使用word2vec预训练词向量得到了30000+的词表。
目前topicmodel(具体实施方式一的方法)和dynamicmodel(具体实施方式二的方法)在opensubtitles数据集和ubuntu数据集上进行了实验,通过处理原对话语料context后,处理成对话session的形式,进行实验测试。
本项专利工作和lstm、hred模型、vhred模型三个baseline模型在embeddingaveragegreedymatching以及vectorextrema指标上进行了比较ubtitles数据集namicmodel也在baseline结果,
表2:ubuntu数据集上的结果,lstm,hred,vhred为baseline结果,topicmodel,dynamicmodel为申请专利的方法
通过以下4组测试实例可以更直观地看出本发明的效果。
其中topicmode表示具体实施方式一的方法,dynamodel表示具体实施方式二的方法,hredmodel,vhredmodel和lstmmodel是已有的模型。
例1:
上文:
现在我要尝试使用ppa的开发版本,看看它是否会再次崩溃。
你在看电脑的cpu温度吗?
不,我还没有遇到温度方面的问题....我在哪里可以看到它的温度?
topicmodel:你可以尝试删除您的配置文件,然后再试一次
dynamodel:尝试从终端运行lspci,那里有个列表
hredmodel:系统->;首选项->;电源管理
vhredmodel:我不明白你的意思
lstmmodel:我不明白
例2:
上文:
请进。
谢谢。
别客气,就当是在自己家
蒂拉小姐等会会出门。
好的
玩的开心
topicmodel:我相信自己会玩的开心
dynamodel:谢谢你
hredmodel:来吧
vhredmodel:好的,我们走
lstmmodel:我会小心的
例3:
上文:
按照链接中的方法,在内核中加入nomodeset参数到启动项中
除此之外呢?谢谢。
topicmodel:你还可以使用nomodeset选项在/etc/default/grub下编辑配置文件
dynamodel:指令与上次更新的最后一个条目相同
hredmodel:不客气
vhredmodel:不客气
lstmmodel:我不明白
例4:
上文:
另一个问题谁知道。有没有办法让pidgin显示消息菜单?
请检查下是否你真的使用nvidia的驱动程序。或者重装一下驱动确保没有问题
topicmodel:我有一个nvidia显卡,和一个radeonmobility7000显卡。
dynamodel:我有一个75英尺的最好的显示器。
hredmodel:我该怎么做?
vhredmodel:我知道
lstmmodel:我不知道
从上述4个例子可以看出,vhredmodel和lstmmodel更倾向于生成通用的回复,很难针对复杂的上下文生成符合语境的回复。hredmodel有时会生成通用的回复,有时会生成符合语境的回复,但总的来说,不符合语境的情况更多。而本发明的topicmodel和dynamodel总能生成符合语境的回复内容。
本发明的具体实施方式一、二可以直接应用于开放域的聊天机器人系统中。本专利技术的应用载体是哈尔滨工业大学社会计算与信息检索研究中心开发的聊天机器人“笨笨”。
本发明提供的多轮对话功能可以作为整个聊天机器人系统的一个模块:该模块接受来自中控模块的启动信号,独立负责一次多轮对话的进行,多轮对话结束时,将控制流程交还给中控模块。
从部署方式上来讲,该项技术可以独立作为一个计算节点,部署于阿里云或者美团云等云计算平台上,与其它模块之间的通讯可以通过绑定ip地址和端口号的方式进行。
该技术的具体实现上,因为使用了深度学习相关技术,所以需要使用相应的深度学习框架:tensorflow以及pytorch都可作为备选框架。无论使用什么深度学习框架,都不会影响该技术模块的对外接口。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!