一种超密集网络中基于密度与最小距离的基站分簇方法与流程
本发明属于无线通信技术领域,应用于超密集网络中微小区基站的管理,具体涉及一种超密集网络中基于密度与最小距离的基站分簇方法。
背景技术:
随着移动通信技术的飞速发展,接入到网络中的通信设备呈爆炸式增长,使得原本就庞大的网络结构变得更加复杂。同时,用户对数据流量的需求也急剧增长,无线网络将面临巨大的压力和挑战。在超密集网络中,通过将微小区基站密集部署在小区内,可以大幅度的提高无线网络的系统容量。然而由于大量基站的密集部署,网络中的干扰问题也日趋严重,资源分配不合理的问题亟待解决。在超密集网络中,首先通过分簇技术将整个网络分成多个子网络,然后在每个子网络内进行干扰管理和资源分配可以有效地简化网络拓扑结构,便于对基站进行管理,从而有效地进行干扰管理、合理分配资源。其中,采用k-means算法可以根据微小区基站的位置快速的对基站进行有效的分簇。但是传统k-means算法需要对分簇的个数进行人为设置,这样就导致该算法不能自适应网络拓扑结构的变化。此外,该算法由于是随机选择初始簇中心,容易使最终分簇结果陷入局部最优解。
因此,需要寻找一个能够适应不断变化的网络拓扑结构,以及更好地对网络进行分簇的分簇方法,以便能够在超密集网络中进行实际应用。
技术实现要素:
本发明的目的在于提供一种超密集网络中基于密度与最小距离的基站分簇方法,该方法可以根据网络拓扑的变化对海量基站进行动态分簇,通过筛选簇中心点避免陷入局部最优解的情况,提高了分簇的准确度,同时也加快了分簇的收敛速度,解决了传统方案中分簇结果不均匀的问题,适用于超密集网络中的基站高效管理,具体技术方案如下:
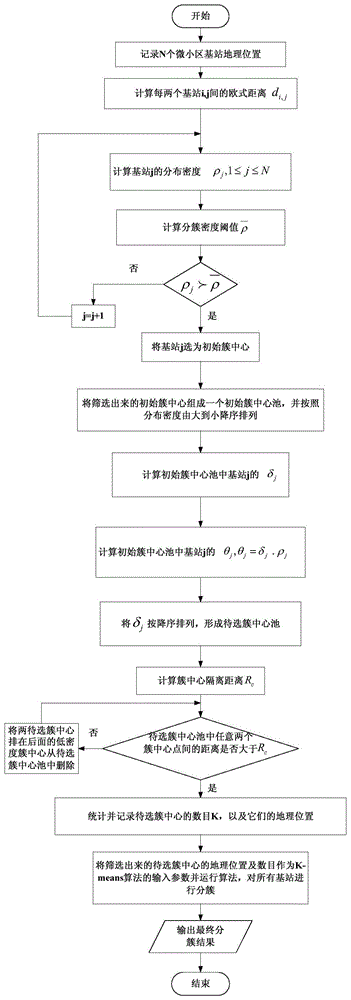
一种超密集网络中基于密度与最小距离的基站分簇方法,所述方法包括步骤:
s1、记录超密集网络中n个微小区基站的地理位置,并计算任意两个微小区基站之间的欧式距离;
s2、计算超密集网络中每个微小区基站的分布密度和分簇密度阈值,比较各微小区基站的分布密度与分簇密度阈值的大小,并将分布密度大于分簇密度阈值的微小区基站作为初始簇中心;
s3、将所有所述初始簇中心组成初始簇中心池,计算所述初始簇中心池中每个微小区基站与较其分布密度高的微小区基站之间距离的最小值;
s4、计算所述初始簇中心池中各微小区基站的分布密度与较其分布密度高的微小区基站之间距离最小值的乘积,记为加权分布密度θj,并将微小区基站对应所述加权分布密度θj从大到小降序排列形成待选簇中心池;
s5、计算簇中心隔离距离,并按照所述加权分布密度θj的大小在所述待选簇中心池中进行降序排列,依次将待选簇中心池中两两之间距离大于所述簇中心隔离距离的两个簇中心中加权分布密度值较小的簇中心从待选簇中心池中移除;
s6、统计并记录最终获得的所述待选簇中心池中簇中心的数目k及每一簇中心的地理位置,作为参数输入传统k-means算法中,执行k-means算法得到超密集网络中所有微小区基站的分簇结果。
进一步的,步骤s2中,所述分布密度定义为:
所述分簇密度阈值定义为:
进一步的,步骤s3中,所述最小值越大,说明所述初始簇中心中微小区微基站分布越均匀,且所述初始簇中心中分布密度最大的微小区基站的距离最小值为与其距离最远的微小区基站之间的距离;
所述初始簇中心池中所有所述初始簇中心按照对应微小区基站的分布密度的大小降序排列。
进一步的,步骤s4中,所述加权分布密度θj越大,说明与所述加权分布密度θj对应的微小区基站的分布密度越大,且与所述加权分布密度θj对应微小区基站距其他微小区基站的距离越远。
进一步的,步骤s5中,所述簇中心隔离距离定义为:
进一步的,步骤s5中,将超密集网络中任意微小区基站i与任意微小区基站j之间的欧式距离di,j与所述簇中心隔离距离rc比较,若di,j>rc,则将微小区基站j从所述待选簇中心池中移除,直至所述待选簇中心池中任意两个微小区基站的距离di,j均大于所述簇中心隔离距离rc。
本发明的超密集网络中基于密度与最小距离的基站分簇方法,首先计算得到超密集网络中微小区基站的分布密度和分簇密度阈值,将分布密度大于分簇密度阈值的微小区基站构建初始簇中心池,并计算初始簇中心池任意两个微小区基站之间的距离;然后,计算初始簇中心池中的每个微小区基站的加权分布密度为实际分布密度与距离高密度基站的最小距离的乘积,按加权分布密度对池中基站进行降序排列,形成待选簇中心池;并计算待选池的簇中心隔离距离;比较初始簇中心池任意两个微小区基站的距离与簇中心隔离距离的大小,将小于簇中心隔离距离的微小区基站从待选簇中心池移除;最后,统计并记录待选簇中心池中微小区基站的数目和地理位置,将数目和地理位置作为传统k-means的参数输入并执行k-means算法,得到超密集网络中微小区基站的分簇结果;与现有技术相比,本发明可以根据网络中基站的位置变化自适应的设置分簇的个数,从而更好地实现超密集网络的分簇;通过计算基站的分布密度与最小距离来联合筛选初始簇中心,可以避免陷入局部最优解的情况,从而获得准确度更高的分簇结果。
附图说明
图1为本发明实施例中所述超密集网络中基于密度与最小距离的基站分簇方法的流程框图示意。
图2为本发明实施例的微小区基站分布位置模拟图。
图3为本发明实施例的分簇结果图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
在本发明实施例中,提供了一种超密集网络中基于密度与最小距离的基站分簇方法;具体的,本发明以300m*300m的区域进行微小区基站的分布位置模拟来对本发明方法进行说明,区域内的所有微小区基站的位置分布满足独立泊松点分布过程;参阅图1,假设区域内微小区基站的数目为n=50,则方法的具体过程包括步骤:
步骤一、记录超密集网络中n个微小区基站的地理位置,即n=50,参阅图2,图示为本实施例中微小区基站的分布位置模拟图,从中可知超密集网络中各微小区基站的实际位置分布情况,从而可以得到每一微小区基站的地理位置;然后计算任意两个微小区基站之间的欧式距离;超密集网络中基站i与基站j均为2维向量,则基站i与基站j之间的欧式距离计算为:
步骤二、计算超密集网络中每个微小区基站的分布密度和分簇密度阈值,其中,分布密度定义为:
步骤三、将所有初始簇中心组成初始簇中心池,计算初始簇中心池中每个微小区基站与较其分布密度高的微小区基站之间距离的最小值;在实施例中,初始簇中心池中所有初始簇中心按照对应微小区基站的分布密度的大小降序排列;指定微小区基站对应最小值越大,说明初始簇中心中微小区微基站分布越均匀,且初始簇中心中分布密度最大的微小区基站的距离最小值为与其距离最远的微小区基站之间的距离。
步骤四、计算初始簇中心池中各微小区基站的分布密度与较其分布密度高的微小区基站之间距离最小值的乘积,记为加权分布密度θj,并将微小区基站对应加权分布密度θj从大到小降序排列形成待选簇中心池;具体的,将微小区基站j到比起分布密度大的基站(即高密度基站)的距离中的最小值定义为δj,则加权密度θj可定位为:θj=δj·ρj;在具体实施例中,加权分布密度θj越大,说明与加权分布密度θj对应的微小区基站的分布密度越大,且与加权分布密度θj对应微小区基站距其他微小区基站的距离越远。
步骤五、计算待选簇中心池的簇中心隔离距离,并按照簇中心在待选簇中心池中的前后排列顺序,依次将待选簇中心池中两两之间距离大于簇中心隔离距离的两个簇中心中加权分布密度值较小的簇中心从待选簇中心池中移除;本发明实施例中,簇中心隔离距离定义为:
在得到待选簇中心池中簇中心隔离距离rc后,将超密集网络中任意微小区基站i与任意微小区基站j之间的欧式距离di,j与簇中心隔离距离rc比较,若di,j>rc,则将微小区基站j从待选簇中心池中移除,直至待选簇中心池中任意两个微小区基站的距离di,j均大于簇中心隔离距离rc。
步骤六、统计并记录待选簇中心池中簇中心的数目k及每一簇中心对应微小区基站的地理位置,作为参数输入传统k-means执行k-means算法,得到超密集网络中所有微小区基站的分簇结果;参阅图3,通过本发明方法对含有50个微小区基站的超密集网络进行分簇后,从分簇效果图来看,可以明显看出本发明方案的分簇结果更加均匀;其中,50个基站一共被分为5个簇,每个簇的基站数基本相同,分簇效果理想。
本发明的超密集网络中基于密度与最小距离的基站分簇方法,首先计算得到超密集网络中微小区基站的分布密度和分簇密度阈值,将分布密度大于分簇密度阈值的微小区基站构建初始簇中心池,并计算初始簇中心池任意两个微小区基站之间的距离;然后,计算初始簇中心池中的每个微小区基站的加权分布密度为实际分布密度与距离高密度基站的最小距离的乘积,按加权分布密度对池中基站进行降序排列,形成待选簇中心池;并计算待选池的簇中心隔离距离;比较初始簇中心池任意两个微小区基站的距离与簇中心隔离距离的大小,将小于簇中心隔离距离的微小区基站从待选簇中心池移除;最后,统计并记录待选簇中心池中微小区基站的数目和地理位置,将数目和地理位置作为传统k-means的参数输入并执行k-means算法,得到超密集网络中微小区基站的分簇结果;与现有技术相比,本发明可以根据网络中基站的位置变化自适应的设置分簇的个数,从而更好地实现超密集网络的分簇;通过计算基站的分布密度与最小距离来联合筛选初始簇中心,可以避免陷入局部最优解的情况,从而获得准确度更高的分簇结果。
以上仅为本发明的较佳实施例,但并不限制本发明的专利范围,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员而言,其依然可以对前述各具体实施方式所记载的技术方案进行修改,或者对其中部分技术特征进行等效替换。凡是利用本发明说明书及附图内容所做的等效结构,直接或间接运用在其他相关的技术领域,均同理在本发明专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!