终端喇叭的控制方法、设备及计算机可读存储介质与流程
本发明涉及终端技术领域,尤其涉及一种终端喇叭的控制方法、设备及计算机可读存储介质。
背景技术:
随着科学技术的发展,出现了屏幕发声电视。屏幕发声提升了电视的临场体验。但是目前的电视还是左边一个喇叭,右边一个喇叭,电视声音的控制主要是左右声道平衡控制,并不能做到电视输出声音的位置随着电视播放画面中声音源的移动而移动,如电视输出的声音是由人发出的,由于电视中喇叭的位置固定,该声音的输出位置并不能随着电视播放画面中人位置的变动而变动。
技术实现要素:
本发明的主要目的在于提供一种终端喇叭的控制方法、设备及计算机可读存储介质,旨在解决现有的终端输出声音的位置无法随着其播放画面中声音源的变化而变化的技术问题。
为实现上述目的,本发明提供一种终端喇叭的控制方法,所述终端的显示屏至少划分成两个显示区域,每个显示区域至少对应着一个喇叭,所述终端喇叭的控制方法包括步骤:
当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频;
若检测到所述待播放视频是经过人工智能学习后的视频,则获取所述待播放视频中的帧识别码;
若所述终端当前播放的帧画面为与所述帧识别码对应的目标帧画面,则根据所述目标帧画面对应的帧识别码确定目标声音源位置信息;
控制所述目标声音源位置信息对应显示区域的喇叭输出所述目标帧画面对应的声音。
优选地,所述控制所述目标声音源位置信息对应显示区域的喇叭输出所述目标帧画面对应的声音的步骤包括:
若检测到目标声音源位置信息对应两个显示区域,则确定所述目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域;
控制所述前显示区域对应喇叭的音量从大到小输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭的音量从小到大输出所述目标帧画面对应的声音。
优选地,所述若检测到目标声音源位置信息对应两个显示区域,则确定所述目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域的步骤之后,还包括:
控制所述前显示区域对应喇叭以第一音量输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭以第二音量输出所述目标帧画面对应的声音,其中,所述第一音量小于所述第二音量。
优选地,所述若检测到所述待播放视频是经过人工智能学习后的视频,则获取所述待播放视频中的帧识别码的步骤包括:
若检测到所述待播放视频是经过人工智能学习后的视频,则从所述待播放视频的头文件中获取帧识别码。
优选地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤之后,还包括:
若检测到所述待播放视频是未经过人工智能学习后的视频,则采用预设的人工智能学习算法识别出所述待播放视频中存在声音的帧画面对应的声音源位置信息;
为存在声音的帧画面添加帧识别码,并将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频。
优选地,所述将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频的步骤包括:
按照预设的编码规则将各个帧识别码和与各个帧识别码对应的声音源位置信息编码成字符串;
在所述字符串的末尾添加结束标识,将携带所述结束标识的字符串编写至所述待播放视频的头文件中,得到经过人工智能学习的待播放视频。
优选地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤之后,还包括:
若检测到所述待播放视频是未经过人工智能学习后的视频,则确定所述终端中已启动的喇叭;
控制所述已启动的喇叭输出所述待播放视频中的声音。
优选地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤包括:
当接收到服务器发送的待播放视频后,检测所述待播放视频中是否存在人工智能学习的特征码;
若所述待播放视频中存在所述特征码,则确定所述待播放视频是经过人工智能学习后的视频。
此外,为实现上述目的,本发明还提供终端喇叭的控制设备,所述终端喇叭的控制设备包括存储器、处理器和存储在所述存储器上并可在所述处理器上运行的终端喇叭的控制程序,所述终端喇叭的控制程序被所述处理器执行时实现如上所述的终端喇叭的控制方法的步骤。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有终端喇叭的控制程序,所述终端喇叭的控制程序被处理器执行时实现如上所述的终端喇叭的控制方法的步骤。
本发明通过在终端接收到经过人工智能学习后的待播放视频时,获取待播放视频中的帧识别码;若终端当前播放的帧画面为与帧识别码对应的目标帧画面,则根据目标帧画面对应的帧识别码确定目标声音源位置信息,并控制目标声音源位置信息对应显示区域的喇叭输出目标帧画面对应的声音,实现了终端输出声音的位置随着播放画面中声音源的变化而变化。
附图说明
图1是本发明实施例方案涉及的硬件运行环境的结构示意图;
图2是本发明终端喇叭的控制方法第一实施例的流程示意图;
图3是本发明实施例中终端显示屏坐标的一种示意图;
图4是本发明实施例中终端控制目标声音源位置信息对应显示区域的喇叭输出目标帧画面对应的声音的一种示意图;
图5是本发明终端喇叭的控制方法第三实施例的流程示意图;
图6是本发明实施例中帧识别码、声音源位置信息和特征码对应字符串的一种示意图;
图7是本发明实施例中帧识别码、声音源位置信息和特征码对应字符串的另一种示意图;
图8是本发明终端喇叭的控制方法第四实施例的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
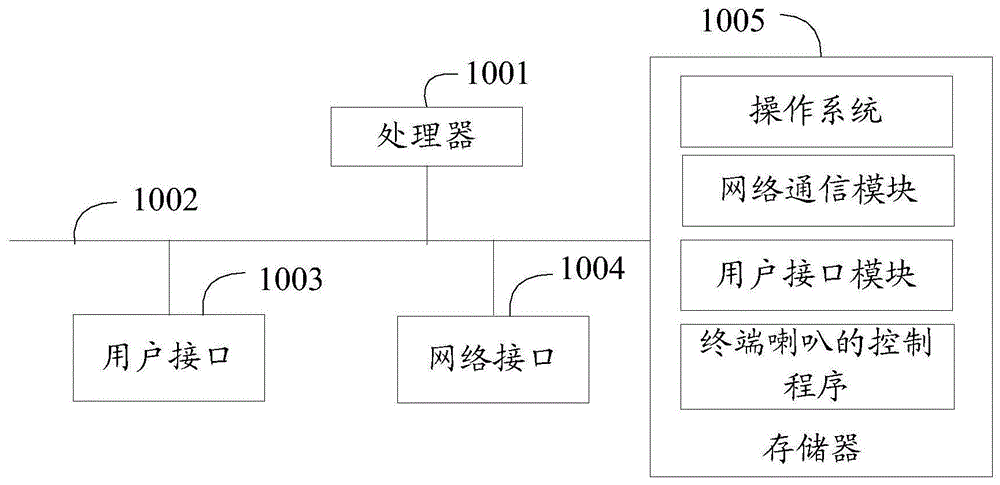
如图1所示,图1是本发明实施例方案涉及的硬件运行环境的结构示意图。
需要说明的是,图1即可为终端喇叭的控制设备的硬件运行环境的结构示意图。本发明实施例终端喇叭的控制设备可以是pc,便携计算机等终端设备。
如图1所示,该终端喇叭的控制设备可以包括:处理器1001,例如cpu,用户接口1003,网络接口1004,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的终端喇叭的控制设备结构并不构成对终端喇叭的控制设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及终端喇叭的控制程序。其中,操作系统是管理和控制终端喇叭的控制设备硬件和软件资源的程序,支持终端喇叭的控制程序以及其它软件或程序的运行。
在图1所示的终端喇叭的控制设备中,用户接口1003主要用于连接服务器,与服务器进行数据通信;网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;可以理解的是,该终端喇叭的控制设备可为喇叭所在终端。所述终端的显示屏至少划分成两个显示区域,每个显示区域至少对应着一个喇叭,而处理器1001可以用于调用存储器1005中存储的终端喇叭的控制程序,并执行以下操作:
当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频;
若检测到所述待播放视频是经过人工智能学习后的视频,则获取所述待播放视频中的帧识别码;
若所述终端当前播放的帧画面为与所述帧识别码对应的目标帧画面,则根据所述目标帧画面对应的帧识别码确定目标声音源位置信息;
控制所述目标声音源位置信息对应显示区域的喇叭输出所述目标帧画面对应的声音。
进一步地,所述控制所述目标声音源位置信息对应显示区域的喇叭输出所述目标帧画面对应的声音的步骤包括:
若检测到目标声音源位置信息对应两个显示区域,则确定所述目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域;
控制所述前显示区域对应喇叭的音量从大到小输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭的音量从小到大输出所述目标帧画面对应的声音。
进一步地,所述若检测到目标声音源位置信息对应两个显示区域,则确定所述目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的终端喇叭的控制程序,并执行以下步骤:
控制所述前显示区域对应喇叭以第一音量输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭以第二音量输出所述目标帧画面对应的声音,其中,所述第一音量小于所述第二音量。
进一步地,所述若检测到所述待播放视频是经过人工智能学习后的视频,则获取所述待播放视频中的帧识别码的步骤包括:
若检测到所述待播放视频是经过人工智能学习后的视频,则从所述待播放视频的头文件中获取帧识别码。
进一步地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的终端喇叭的控制程序,并执行以下步骤:
若检测到所述待播放视频是未经过人工智能学习后的视频,则采用预设的人工智能学习算法识别出所述待播放视频中存在声音的帧画面对应的声音源位置信息;
为存在声音的帧画面添加帧识别码,并将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频。
进一步地,所述将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频的步骤包括:
按照预设的编码规则将各个帧识别码和与各个帧识别码对应的声音源位置信息编码成字符串;
在所述字符串的末尾添加结束标识,将携带所述结束标识的字符串编写至所述待播放视频的头文件中,得到经过人工智能学习的待播放视频。
进一步地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的终端喇叭的控制程序,并执行以下步骤:
若检测到所述待播放视频是未经过人工智能学习后的视频,则确定所述终端中已启动的喇叭;
控制所述已启动的喇叭输出所述待播放视频中的声音。
进一步地,所述当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频的步骤包括:
当接收到服务器发送的待播放视频后,检测所述待播放视频中是否存在人工智能学习的特征码;
若所述待播放视频中存在所述特征码,则确定所述待播放视频是经过人工智能学习后的视频。
本发明终端喇叭的控制设备具体实施方式与下述终端喇叭的控制方法各实施例基本相同,在此不再赘述。
基于上述的结构,提出终端喇叭的控制方法的各个实施例。
参照图2,图2为本发明终端喇叭的控制方法第一实施例的流程示意图。
本发明实施例提供了终端喇叭的控制方法的实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
终端喇叭的控制方法包括:
步骤s10,当接收到服务器发送的待播放视频后,检测所述待播放视频是否是经过人工智能学习后的视频。
在本发明实施例中,终端包括但不限于电视和个人计算机等具有视频播放功能的设备。终端的显示屏至少划分成两个显示区域,每个显示区域至少对应着一个喇叭。当终端接收到服务器发送的待播放视频后,终端检测待播放视频是否为经过人工智能(ai,artificialintelligence)学习后的视频。具体地,服务器可预先和终端协商好,对哪些待播放视频进行人工智能学习,如服务器可预先和终端协商好对视频播放时长大于预设时长的视频进行人工智能学习,或者对特定类型的待播放视频进行人工智能学习,如对电视剧视频或者音乐视频进行人工智能学习,此时,终端在接收到服务器发送的待播放视频后,只要对应检测待播放视频的播放时长,或者确定待播放视频的类型即可知道待播放视频是否为经过人工智能学习后的视频。
需要说明的是,若待播放视频经过人工智能学习,则该视频中包含了视频声音源位置信息和对应的帧识别码,即经过人工智能学习,可知道待播放视频中哪一帧画面存在声音,且该声音对应声音源在该帧画面中的位置;帧识别码用于表示存在声音的帧画面,声音源位置信息用于表示对应帧画面中声音源的位置。
进一步地,步骤s10包括:
步骤a,当接收到服务器发送的待播放视频后,检测所述待播放视频中是否存在人工智能学习的特征码。
步骤b,若所述待播放视频中存在所述特征码,则确定所述待播放视频是经过人工智能学习后的视频。
进一步地,服务器可根据具体情况对待播放视频进行人工智能学习,当服务器对某个待播放视频进行人工智能学习后,服务器会为该经过人工智能学习的待播放视频添加一个特征码,以根据该特征码告知终端该待播放视频已经过人工智能学习。其中,在本发明实施例中,不限制特征码的表现形式,特征码可用数字、字母或者数字与字母的结合形式表示。
当终端接收到服务器发送的待播放视频后,检测待播放视频中是否存在人工智能学习的特征码。若检测到待播放视频中存在该特征码,终端则确定待播放视频为经过人工智能学习后的视频;若检测到待播放视频中未存在该特征码,终端则确定待播放视频是未经过人工智能学习后的视频。其中,为了提高终端检测待播放视频是否为经过人工智能学习后的视频的检测效率,服务器可将特征码编写在待播放视频的头文件中。可以理解的是,服务器也可将特征码编写在待播放视频的尾部,本实施例可不对特征码在待播放视频中的位置做具体限制。
步骤s20,若检测到所述待播放视频是经过人工智能学习后的视频,则获取所述待播放视频中的帧识别码。
若终端检测到待播放视频是经过人工智能学习后的视频,终端则获取待播放视频中的帧识别码。其中,通过该帧识别码可确定待播放视频中存在声音的帧画面。具体地,服务器可只对存在声音的帧画面设置帧识别码,此时,每一帧识别码都存在对应的声音源位置信息;若服务器为待播放视频的每一帧画面都设置帧识别码,则只有存在声音的帧画面对应的帧识别码才会存在对应的声音源位置信息,不存在声音的帧画面的帧识别码不存在对应的声音源位置信息。为了便于描述,以下内容以只对存在声音的帧画面设置帧识别码为例进行说明。在本发明实施例中,不对帧识别码的表现形式做具体限制,通过帧识别码可以识别出是待播放视频中的第几帧画面存在声音。
进一步地,步骤s20包括:
步骤c,若检测到所述待播放视频是经过人工智能学习后的视频,则从所述待播放视频的头文件中获取帧识别码。
进一步地,为了提高终端获取帧识别码的获取效率,服务器在通过人工智能学习识别出待播放视频中存在声音的帧画面后,为存在声音的帧画面设置对应的帧识别码,并将该帧识别码编写至待播放视频的头文件中。因此,当终端检测到待播放视频是经过人工智能学习后的视频时,终端从待播放视频的头文件中获取帧识别码。进一步地,服务器也可将帧识别码和特征码编写至待播放视频对应音频文件的头文件中。
步骤s30,若所述终端当前播放的帧画面为与所述帧识别码对应的目标帧画面,则根据所述目标帧画面对应的帧识别码确定目标声音源位置信息。
在终端播放待播放视频过程中,终端检测其当前播放的帧画面是否为与帧识别码对应的帧画面,在本发明实施例中,将终端当前播放的与帧识别码对应的帧画面记为目标帧画面。若终端检测到其当前播放的帧画面为目标帧画面,终端则根据目标帧画面对应的帧识别码确定声音源位置信息,并将目标帧画面的帧识别码对应的声音源位置信息记为目标声音源位置信息。需要说明的是,本发明实施例中的一帧画面的大小可根据具体需要而设置。具体地,声音源位置信息可用坐标来表示,此时,可将终端的显示屏的左下角作为原点,原点往右边为横轴的正方向(x轴),原点往上为纵轴(y轴)的正方向,具体地,如图3所示。需要说明的是,也可以采用终端显示屏的中间位置作为原点,即本实施例不限制坐标的建立形式。
进一步地,若终端检测到其当前播放的帧画面不是目标帧画面,终端则继续播放待播放视频,并继续检测其当前播放的帧画面是否为目标帧画面。可以理解的是,在终端播放待播放视频过程中,会对待播放视频进行图像处理和音频处理,以正常播放待播放视频。
步骤s40,控制所述目标声音源位置信息对应显示区域的喇叭输出所述目标帧画面对应的声音。
当终端根据目标帧画面对应的帧识别码确定目标声音源位置信息后,终端控制目标声音源位置信息对应显示区域的喇叭输出目标帧画面对应的声音。其中,目标声音源位置信息可对应一个坐标,也可对应多个坐标,因此,目标声音源位置信息对应的显示区域可为一个,也可为多个。可以理解的是,若帧画面中的声音源为人发出的,则在人工智能学习过程中,是通过智能学习人的嘴型变化来确定该人是否有发出声音,若该人发出声音,则声音源位置信息应该对应人嘴巴所在位置,此时,目标声音源位置信息可对应多个坐标,即目标声音源位置信息对应着一个坐标群。
具体地,参照图3,在图3中,将终端的显示屏划分成4个面积相等的显示区域,分别为a显示区域,b显示区域,c显示区域和d显示区域,每个显示区域设置了一个喇叭,若该显示屏的分辨率为3840×2160,则可用根据像素建立坐标系,通过像素代表声音所对应的坐标点,此时,这个4个显示区域的分辨率分别为1920×1080。若将喇叭都设在各个显示区域的中心位置,则这4个喇叭的坐标分别是a,b,c和d,其中a的坐标为(960,540),b的坐标为(2880,1620),c的坐标为(2880,540),d的坐标为(960,1620)。当终端检测到目标声音源位置信息为坐标(960,540)时,终端控制a显示区域的喇叭输出待播放视频的声音;当终端检测到目标声音源位置信息为坐标(2000,900)时,终端控制c显示区域的喇叭输出待播放视频的声音;当终端检测到目标声音源位置信息为坐标(1910,1000)和(1925,995)时,终端控制a显示区域和c显示区域的喇叭共同输出待播放视频的声音。
本实施例通过在终端接收到经过人工智能学习后的待播放视频时,获取待播放视频中的帧识别码;若终端当前播放的帧画面为与帧识别码对应的目标帧画面,则根据目标帧画面对应的帧识别码确定目标声音源位置信息,并控制目标声音源位置信息对应显示区域的喇叭输出目标帧画面对应的声音,实现了终端输出声音的位置随着播放画面中声音源的变化而变化,提高了终端播放视频过程中的临场体验效果。
进一步地,提出本发明终端喇叭的控制方法第二实施例。
所述终端喇叭的控制方法第二实施例与所述终端喇叭的控制方法第一实施例的区别在于,步骤s40包括:
步骤d,若检测到目标声音源位置信息对应两个显示区域,则确定所述目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域。
在终端控制目标声音源位置信息对应显示区域的喇叭输出目标帧画面对应的声音过程中,终端可检测目标声音源位置信息是否对应两个显示区域。若终端检测到目标声音源位置信息对应着两个显示区域,终端则获取与目标帧画面关联的前后帧画面。需要说明的是,终端可获取目标帧画面的前一帧画面和后一帧画面,也可获取目标帧画面的前两帧画面和后一帧画面,或者获取目标帧画面的前三帧画面和后三帧画面等。具体地,终端通过目标声音源位置信息中的坐标即可确定目标声音源位置信息是否对应两个显示区域。
当终端获取到与目标帧画面关联的前后帧画面时,终端根据该前后帧画面即可确定目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域。其中,前显示区域为该帧画面中先出现的区域,后显示区域为该帧画面中后出现的区域,即发出声音的物体是从前显示区域往后显示区域移动。
进一步地,若终端检测到目标声音源位置对应着一个显示区域,终端则控制该显示区域对应喇叭输出该目标帧画面的声音。具体地,可参照图4,若将终端的显示屏划分成a、b、c、d、e和f这6个显示区域,若待播放视频中的小鸟在飞行过程都在鸣叫,当小鸟在a显示区域飞行时,终端控制a显示区域对应喇叭输出小鸟的鸣叫声;当小鸟在b显示区域飞行时,终端控制b显示区域对应喇叭输出小鸟的鸣叫声;当小鸟在c显示区域飞行时,终端控制c显示区域对应喇叭输出小鸟的鸣叫声。
步骤e,控制所述前显示区域对应喇叭的音量从大到小输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭的音量从小到大输出所述目标帧画面对应的声音。
当终端确定目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域后,终端控制前显示区域对应喇叭的音量从大到小输出目标帧画面对应的声音,以及控制后显示区域对应喇叭的音量从小到大输出目标帧画面对应的声音。
进一步地,所述终端喇叭的控制方法还包括:
步骤f,控制所述前显示区域对应喇叭以第一音量输出所述目标帧画面对应的声音,以及控制所述后显示区域对应喇叭以第二音量输出所述目标帧画面对应的声音,其中,所述第一音量小于所述第二音量。
进一步地,终端在确定前显示区域和后显示区域后,终端控制前显示区域对应喇叭以第一音量输出目标帧画面对应的声音,并控制后显示区域对应喇叭以第二音量输出目标帧画面对应的声音,其中,第一音量小于第二音量,第一音量和第二音量的大小可根据具体需要而设置,在本实施例对第一音量和第二音量的大小不做具体限制。
进一步地,终端在检测到目标声音源位置信息对应两个显示区域时,终端可确定声音源对应发声物体在两个显示区域中的面积,将面积大的记为第一显示区域,将面积小的记为第二显示区域,并控制第一显示区域对应喇叭以第三音量输出帧画面对应的声音,以及控制第二显示区域对应喇叭以第四音量输出帧画面对应的声音,其中,第三音量大于第四音量,在本实施例中对第三音量和第四音量的大小不做具体限制。此时,发声物体可为人,动物等的嘴巴,或者乐器等。可以理解的是,终端也可以控制这两个显示区域对应喇叭以相同的音量输出帧画面对应的声音。
需要说明的是,当终端检测到目标声音源位置信息对应三个或者四个显示区域时,对应的喇叭控制规则目标声音源位置信息对应两个显示区域的控制规则类似,在此不再详细赘述。
本实施例通过在检测到目标声音源位置信息对应两个显示区域,则确定目标声音源位置信息对应两个显示区域中的前显示区域和后显示区域,控制前显示区域对应喇叭的音量从大到小输出目标帧画面对应的声音,以及控制后显示区域对应喇叭的音量从小到大输出目标帧画面对应的声音,或者控制面积大的第一显示区域对应喇叭以第三音量输出帧画面对应的声音,控制面积小的第二显示区域对应喇叭以第四音量输出帧画面对应的声音,其中,第三音量大于第四音量,提高了终端输出声音的位置随着播放画面中声音源的变化而变化的准确度,进一步地提高了终端输出声音的智能性。
进一步地,提出本发明终端喇叭的控制方法第三实施例。
所述终端喇叭的控制方法第三实施例与所述终端喇叭的控制方法第一或第二实施例的区别在于,参照图5,终端喇叭的控制方法还包括:
步骤s50,若检测到所述待播放视频是未经过人工智能学习后的视频,则采用预设的人工智能学习算法识别出所述待播放视频中存在声音的帧画面对应的声音源位置信息。
当终端检测到待播放视频是未经过人工智能学习后的视频时,终端采用预设的人工智能学习算法识别出待播放视频中存在声音的帧画面对应的声音源位置信息。人工智能学习算法包括但不限于机器学习算法和深度学习算法,机器学习算法包括但不限于支持向量机(svm,supportvectormachine)、朴素贝叶斯(nb,naivebayesian)、k最邻近分类算法(knn,k-nearestneighbor)、决策树(dt,decisiontree)和集成模型(rf(randomforest,随机森林)/gdbt(gradientboostingdecisiontree);深度学习算法包括但不限于卷积神经网络(cnn,convolutionalneuralnetwork)、循环神经网络(recurrentneuralnetworks)和递归神经网络(recursiveneuralnetworks)。可以理解的是,通过视频中人嘴巴的嘴型或者动物的嘴型可对应确定人或者动物是否有发出声音,从而将嘴型变动的位置标上坐标,输入到人工智能学习算法进行训练,以得到训练后的人工智能学习算法,然后将待播放视频输入到训练后的人工智能学习算法中,即可识别出待播放视频中存在声音的帧画面对应的声音源位置信息。
步骤s60,为存在声音的帧画面添加帧识别码,并将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频。
终端为待播放视频中存在声音的帧画面添加帧识别码,并各个帧识别码和对应的声音源位置信息关联编写至待播放视频中,以得到经过人工智能学习的待播放视频。
需要说明的是,服务器对待播放视频进行人工智能学习的过程与终端对待播放视频进行人工智能学习的过程一致,因此在本发明实施例中不再详细赘述服务器对待播放视频进行人工智能学习的过程。
本实施例通过终端在检测到待播放视频是未经过人工智能学习后的视频时,采用预设的人工智能学习算法识别出待播放视频中存在声音的帧画面对应的声音源位置信息,并为存在声音的帧画面添加帧识别码,并将各个帧识别码和对应的声音源位置信息关联编写至待播放视频中,以得到经过人工智能学习的待播放视频,提高了终端输出声音的位置随着播放画面中声音源的变化而变化的成功率。
进一步地,所述将各个帧识别码和对应的声音源位置信息关联编写至所述待播放视频中,以得到经过人工智能学习的待播放视频的步骤包括:
步骤h,按照预设的编码规则将各个帧识别码和与各个帧识别码对应的声音源位置信息编码成字符串。
进一步地,当终端为存在声音的帧画面添加帧识别码之后,终端按照预设的编码规则将各个帧识别码和与各个帧识别码对应的声音源位置信息编码至待播放视频的头文件中。编码规则可为将帧识别码与该帧识别码对应的声音源位置信息拼接成一个字符串,在该字符串中,可按照“帧识别码1-声音源坐标1-帧识别码2-声音源坐标2┄帧识别码n-声音源坐标n”的格式进行编码,具体地,可参照图6;也可将声音源位置信息编写在帧识别码前面。进一步地,编码规则也可将帧识别码和对应的声音源位置信息编码成一个表格。
步骤i,在所述字符串的末尾添加结束标识,将携带所述结束标识的字符串编写至所述待播放视频的头文件中,得到经过人工智能学习的待播放视频。
在得到字符串后,终端在字符串的末尾添加结束标识,然后将携带结束标识的字符串编写至待播放视频的头文件中,以得到经过人工智能学习的待播放视频。在本实施例中,结束标识可用特定的字符表示,如结束标识可用“end”表示,具体地如图6所示。进一步地,如图6所示,服务器可将特征码编写在字符串的首位。需要说明的是,若是终端自己对待播放视频进行人工智能学习,可不在字符串中添加特征码。
具体地,如图7所示,以0x10,0x11这两帧画面为例进行说明,其中特征码为0xb0,代表待播放视频是经过人工智能学习后的视频;帧识别码0x10,代表标志为0x10对应的帧画面有声音,并且0x10对应的声音源位置信息为声音源坐标1;帧识别码0x11,代表标志为0x11对应的帧画面有声音,并且0x10对应的声音源位置信息为声音源坐标2,即当播放到带有标志0x10的帧画面时,获取声音源坐标1,控制声音源坐标1对应显示区域的喇叭输出声音;当播放到带有标志0x11的帧画面时,获取声音源坐标2,控制声音源坐标2对应显示区域的喇叭输出声音。
本实施例通过在字符串的末尾添加结束标识,以根据该结束标识告知终端结束标识之前为与待播放视频无关的内容,结束标识之后为与待播放视频相关的内容,以避免终端在解码待播放视频过程中,将特征码、帧识别码和声音源位置信息和待播放视频相关内容混淆,导致待播放视频播放失败的情况出现,提高了待播放视频播放的成功率。
进一步地,提出本发明终端喇叭的控制方法第四实施例。
所述终端喇叭的控制方法第四实施例与所述终端喇叭的控制方法第一或第二实施例的区别在于,参照图8,终端喇叭的控制方法还包括:
步骤s70,若检测到所述待播放视频是未经过人工智能学习后的视频,则确定所述终端中已启动的喇叭。
步骤s80,控制所述已启动的喇叭输出所述待播放视频中的声音。
当终端检测到待播放视频是未经过人工智能学习后的视频时,终端确定其已启动的喇叭,并控制以启动的喇叭输出待播放视频中的声音。进一步地,当终端检测到待播放视频是未经过人工智能学习后的视频时,终端解密待播放视频,得到待播放视频中的音轨信息,根据该音轨信息控制喇叭输出待播放视频中的声音。其中,音轨是在音序器软件中看到的一条一条的平行“轨道”。每条音轨分别定义了该条音轨的属性,如音轨的音色,音色库,通道数,输入/输出端口和音量等。
本实施例通过在检测到待播放视频是未经过人工智能学习后的视频时,控制终端中已启动的喇叭输出待播放视频中的声音,以使未经过人工智能学习后的视频也能正常播放。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有终端喇叭的控制程序,所述终端喇叭的控制程序被处理器执行时实现如上所述的终端喇叭的控制方法的步骤。
本发明计算机可读存储介质具体实施方式与上述终端喇叭的控制方法各实施例基本相同,在此不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!