针对排序和有效消耗的ICD代码相关性的自动上下文确定的制作方法
下文总体涉及医学领域、医学数据库领域、医学成像领域以及相关领域。
背景技术
一些电子医学记录(emr)系统(在本领域中还已知诸如电子健康记录ehr系统的类似命名)的特征在于:提供包含以国际疾病分类10(icd-10)代码形式的患者的历史和当前信息的emr问题列表(pl)。该信息对于正在阅读患者的成像检查的放射科医师是有价值的。所述成像检查例如可以是计算机断层摄影(ct)成像检查、磁共振(mr)成像检查、正电子发射断层摄影(pet)成像检查、计算机放射学(cr)成像检查等。然而,因为大多数代码对于图像解读而言可能是不相关的,针对患者的pl会是冗长且繁琐的。实际上,放射科医师可能在执行医学成像检查阅读时未咨询针对患者的pl。
下文提供了克服前述问题和其他问题的新的并且经改进的设备和方法。
技术实现要素:
根据一个方面,一种放射学工作站,包括:至少一个显示部件;至少一个用户输入设备;以及至少一个微处理器,其被编程为生成针对经由所述至少一个用户输入设备接收到的上下文(contextual)的临床代码的上下文排序并且在所述放射学工作站的所述显示部件上显示关于所述上下文排序的信息。所述上下文排序是由所述微处理器根据以下项来计算的:(i)被包含在放射学报告数据库中并且满足所述上下文的放射学报告中的所述临床代码的出现的统计结果,以及(ii)被包含在问题列表数据库中并且满足所述上下文的问题列表中的所述临床代码的统计结果。
根据另一方面,提供了一种非瞬态计算机可读介质,其承载用于控制至少一个处理器以执行图像采集方法的软件。所述方法包括:生成针对经由放射学工作站的至少一个用户输入设备接收到的上下文的临床代码的上下文排序;并且在所述放射学工作站的显示部件上显示关于所述上下文排序的信息。所述上下文排序是根据以下项来生成的:(i)被包含在放射学报告数据库中并且满足所述上下文的放射学报告中的所述临床代码的出现的统计结果,以及(ii)被包含在问题列表数据库中并且满足所述上下文的问题列表中的所述临床代码的统计结果。
根据另一方面,一种放射学工作站包括至少一个显示部件和至少一个用户输入设备。至少一个微处理器被编程为:生成针对经由所述至少一个用户输入设备接收到的上下文的临床代码的上下文排序并且在所述放射学工作站的所述显示部件上显示关于所述上下文排序的信息;并且通过执行自然语言处理以标识表示对应于临床代码c的一个或多个临床概念的短语而从放射学报告中提取代码c,来生成放射学报告中的所述临床代码的出现的统计结果。所述上下文排序是由所述微处理器根据以下项来计算的:(i)被包含在放射学报告数据库中并且满足所述上下文的放射学报告中的所述临床代码的出现的统计结果,以及(ii)被包含在问题列表数据库中并且满足所述上下文的问题列表中的所述临床代码的统计结果。
附图说明
本发明可以采取各种部件和部件布置以及各种步骤和步骤安排的形式。附图仅仅用于图示优选实施例的目的而不应当被解释为对本发明的限制。
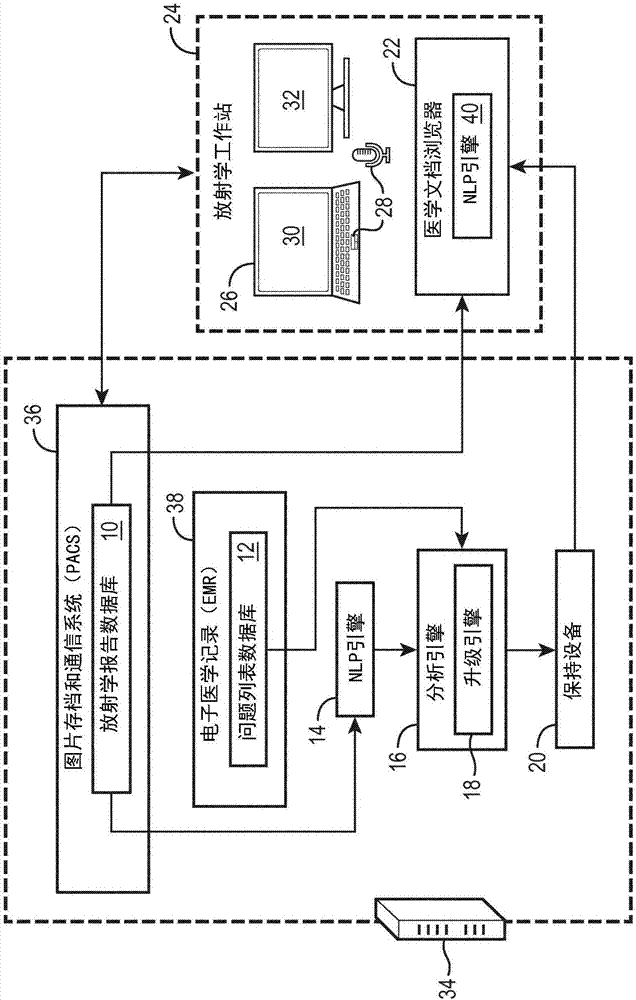
图1图解性地图示了包含所公开的临床代码上下文相关性排序的实施例的放射学工作站;并且
图2-8呈现了如在本文中所描述的实验数据。
具体实施方式
用于使pl的内容对于放射科医师更有用的一种可能方法是通过与一般的医学成像检查阅读的相关性或者更具体地通过与正在执行的具体成像检查(例如,ct、mr、pet,…)的相关性对icd代码进行排序。一种方法是提供:(1)确定icd代码特定相关性的基于规则的方法,和/或(2)让用户提供反馈的用户接口设备,其被用于创建和校准规则。例如,对于(1),可以假定某人已经输入了指示“赘生物”类别中的所有代码具有相关性0.8的规则。关于选项(2),一种可能的场景是:一个或多个用户已经在“良性赘生物”类别中的所有代码与其包含的类别“赘生物”不太相关的工作流中提供了反馈。这两个场景要求手动输入。
在本文中所公开的例示性方法中,在没有人类交互的情况下,针对icd代码导出了相关性得分。同样在没有人类介入的情况下,能够在各种颗粒度水平上使相关性方案上下文相关。所公开的方法基于以下认识:在数学上,确定相关性的问题能够被定义为条件概率:
prob(代码c是相关的|代码c在问题列表p中)(1)通过定义,这等价于:
prob(代码c是相关的&代码c在问题列表p中)/
prob(代码c在问题列表p中)(2)
假定所有相关代码被包含在问题列表中,等式(2)的分子等于:
prob(代码c是相关的)(3)用于通过相关性对pl中的代码进行排序的所公开的方法基于以下认识:分子和分母两者能够通过对回顾性数据的分析来估计。概率prob(代码c是相关的)能够被估计为(能够从其中提取c的放射学报告的临床历史部分的#)/(报告的#)。该估计利用放射科医师在临床历史部分中包括对于解读有关的临床信息的典型实践。概率prob(代码c在问题列表p中)被估计为(包含代码c的问题列表的#)/(问题列表的#)。
在本文中公开了用于根据回顾性数据来估计以上两个参数并且用于处理在任何临床历史和/或问题列表中未发现或很少发现的代码的各种方法。
参考图1,一些例示性实施例包括以下部件:
●放射学报告数据库10-利用独有的患者标识符和上下文参数而索引的放射学报告的数据库,所述上下文参数诸如是被成像的解剖学部分(例如,腹部/神经/胸部/血管/乳腺)和成像模态(例如,cr/mr/ct/nm)。
●问题列表(pl)数据库12-利用独有的患者标识符而索引的问题列表的数据库。
●自然语言处理引擎14-从叙述性语言的特定片段提取代码的自然语言处理(nlp)引擎。所述代码是来自背景本体(ontology)的受控的语义实体,诸如icd。
●分析引擎16-将相关计数制表并且将其合计在代码特定相关性得分中的统计学引擎。
●升级引擎18-基于背景本体中的祖先代码的相关性来确定代码的相关性的层次推理引擎(例如,“良性赘生物”具有其祖先之中的“赘生物”)。
●保持设备20–保持自动地导出的相关性得分并且使其暴露于人类和/或自动化代理方的方法。
还可以提供医学文档浏览器22,其用作例如可以具有针对上下文放射学相关性的“热图功能”的医学文档的浏览器。
在例示性图1中,操作性地结合向放射科医师或其他医学专家提供用于执行放射学检查(例如,ct、mr、pet、cr等)并且记录其读取结果的工具的放射学工作站24示出了临床代码上下文相关性排序。例示性放射学工作站24包括计算机26(具有微处理器,未示出)、用户输入设备28(例如,例示性键盘、跟踪板、听写麦克风;可以提供额外的或其他用户输入设备,诸如鼠标和/或触敏显示器)。例示性放射学工作站24还包括一个或多个(例示性为两个)显示设备或部件30、32,例如lcd显示器。优选地,这些显示部件30、32中的至少一个是用于显示医学图像的高分辨率显示器。放射学工作站24运行适合的程序设计或软件以使得用户能够:从图片存档和通信系统(pacs)36(在本领域中也已知诸如放射学信息系统ris的类似命名)检索医学图像;在优选具有执行各种图像操纵(放大/缩小、浏览图像切片堆栈中的图像切片、产生三维绘制、在图像上标记位置并且测量标记之间的距离等)的能力的显示部件30、32上显示图像;准备基于文本的放射学报告(例如,通过键入和/或听写,任选地利用与医学图像和/或插入的图像缩略图或者减小分辨率的嵌入式图像等的链接)。例示性医学文档浏览器22由在放射学工作站24上运行的适合的程序设计来运行以显示并且允许对这样的放射学报告的编辑(或者,任选更一般地,呈现其他类型的医学报告)。
继续参考图1,接下来描述了例示性临床代码上下文相关性排序的部件的一些例示性实施例。这些部件(除了在放射学工作站24上实施的例示性医学文档浏览器22之外)在由根据在本文中所公开的实施例的适合的软件编程为执行所公开的处理的服务器计算机34或其他计算系统(例如,服务器集群、云计算资源等,再次地,这些中的每个固有地包括一个或多个微处理器)上适合地实施。在其他实施例中,如果放射学工作站24具有足够的计算能力,那么包括例示性临床代码上下文相关性排序的部件的所有部件都可以在放射学工作站24上本地实施。还预期一个、两个或更多个计算机之中的各种处理的其他划分。
放射学报告数据库10包括优选使用标准(例如,关系)数据库技术存储的放射学报告的数据库。所述数据库能够通过查询针对放射学报告和相关元数据的现有数据库(诸如图片存档和通信系统(pacs)36)来获得。
问题列表数据库12包括优选使用标准(例如,关系)数据库技术存储的问题列表的数据库。问题列表数据库12能够通过查询针对问题列表的现有数据库(诸如电子医学记录(emr)38)来获得。在问题列表数据库12中所使用的患者标识符应当与在放射学报告数据库10中所使用的标识符一致(例如,与其相同或者能够与之交叉引用)。这通常是诸如在其中emr38和pacs36中的患者标识符应当内部一致的医院的典型设置中的情况。
自然语言处理(nlp)引擎14操作用于通过对来自放射学报告数据库10的放射学报告的自然语言处理来提取对应于临床代码(例如,icd-10代码)的概念。在一个例示性范例中,这是通过以下操作来完成的:(1)检测并且标准化放射学报告中的部分的标头,并且(2)从诸如临床历史部分的一个或多个片段提取概念。步骤(1)能够基于字符串匹配或统计学技术使用句子边界检测来实施。步骤(2)能够使用概念提取引擎(诸如metamap,其被优化用于提取snomed概念)来实施。作为任选步骤,从icd之外的另一本体提取的概念能够使用预定映射表格被映射至icd上—例如,用于snomed至icd的映射表格是公开可用的。因此,nlp引擎14检测表示在snomed概念数据库中标识并且从而由snomed代码索引的临床概念的短语,并且snomed代码然后使用snomed至icd-10映射表格被转换为icd-10代码。通过组合由步骤(1)和(2)所提供的信息,能够针对驻留在其临床历史部分中的icd代码来查询给定的一个或多个报告。
应当注意,尽管国际统计学疾病分类和相关健康问题(icd)代码在本文中被用作临床代码本体,但是更一般地,所述方法能够与任何临床代码本体一起使用。类似地,尽管在本文中使用icd-10,但是icd修正可以不同于第10th版修正。
接下来描述了分析引擎16的实施方案的例示性范例。针对给定的icd代码c,基于查询放射学报告数据库10、问题列表数据库12和nlp引擎14,分析引擎16对以下参数进行制表:
●由自然语言处理引擎14从其中提取c的临床历史部分的#
●所检查的临床历史部分的#,即,放射学报告数据库10中的#报告
●包含c的问题列表的#
●所检查的问题列表的#,即,问题列表数据库12中的#问题列表针对任意icd代码c,然后使用相关性得分公式来计算相关性:
prob(代码c是相关的)=(能够从其中提取c的放射学报告的临床历史部分的#)/(报告的#)(4)
以及
prob(代码c在问题列表p中)=(包含代码c的问题列表的#)/(问题列表的#)(5)
代码c的相关性然后根据等式(4)和(5)的结果被计算为:
prob(代码c是相关的|代码c在问题列表p中)=prob(代码c是相关的)/prob(代码c在问题列表p中)(6)其中,等式(6)遵循参考图(1)-(3)所描述的认识。
使用针对每个放射学报告而存储的元数据,能够计算上下文相关得分。例如,如果期望检索针对腹部研究的相关性得分,则分析引擎16导出以下计数:
●来自由nlp引擎14从其中提取c的腹部报告的临床历史部分的#
●从腹部报告检查的临床历史部分的#,即,放射学报告数据库10中的腹部报告#
●具有包含c的新近腹部研究(<1yr)的患者的问题列表的#
●具有检查的新近腹部研究(<1yr)的患者的问题列表的#,即,具有问题列表数据库12中的新近腹部研究(<1yr)的患者的问题列表#
这些值然后用作对等式(4)-(6)的输入以计算针对腹部研究的上下文的上下文相关性得分。以相同的方式,能够促进额外的或其他任选更颗粒化的上下文相关性得分,诸如“腹部mr”研究或者“由dr.doe读取的胸部cr”,只要放射学报告数据库10中的报告被适当地索引,使得适当的放射学报告能够被标识。
参考图2,针对icd10代码i10(高血压)呈现了工作的范例。如所期望的,所述代码具有心脏领域中的最高相关性得分。在图2的范例中,并且参考图3-8所描述的那些,采用以下数据和分析。等式(4)-(6)的代码相关性度量被用于对在放射学报告的历史部分中更频繁的有序icd10代码进行排序(因此,假定由在pl的集合中的频率标准化的相关性)。为了确定代码频率,metamap检测243374份报告的去标识的语料库中的代码出现;20148位患者的pl被用于频率标准化。相关性度量通过过滤神经报告和具有神经检查的患者的相关pl被文字化以用于神经成像检查。类似的过程被用于腹部、肌骨的、心脏和胸部检查。
接下来描述了升级引擎18的例示性实施例。用于包括该任选部件的基本原理如下。由分析引擎16合计的计数基于所观测到的频率。针对一些icd代码,在两个观测到的概率prob(代码c是相关的)并且prob(代码c在问题列表中)的置信度区间太宽的意义上,这些观测到的频率对于有意义的分析可能太小。例如,考虑以下参数:
●包含代码c的问题列表的#=1
●所检查的问题列表的#=1000
●prob(代码c在问题列表中)=0.001
在该事件中,prob(代码c在问题列表中)的95%置信度区间的范围从0.000025到0.006。如果prob(代码c是相关的)=0.0005,那么置信度区间分析指示相关性得分的范围将从1(=min{0.0005/0.000025,1})到0.083(0.0005/0.006)范围。
如果统计学分析的结果指示相关性得分不是可信的,则升级引擎18执行针对给定代码的统计学分析并且采取适当的动作。可信度是如下确定的:基于上文给出的自变量类型,或者在备选实施例中,通过针对预定阈值来检查计数,诸如例如:
包含代码c的问题列表的#>tmin(7)其中,tmin是某个阈值,例如,在一些预期的实施例中tmin=10。如果统计学分析指示相关性得分不是可信的,则升级引擎18迭代地寻找比当前代码更一般的代码的相关性得分,直到获得了可信值。在该分析中,祖先节点的计数相对于其儿子和孙子的计数累积。这将导致更高的计数、更高的概率、相对地较小的置信度区间以及更可信的相关性得分。升级引擎18可以利用icd代码的分层树形结构。在图3中图示了该升级策略。
这仅仅是一个例示性升级方法。能够实施不同的升级策略。例如,能够针对不满足可信度检查的代码返回默认相关性得分,在这种情况下,有效地不存在层次升级。在其他实施方案中,每个代码总是被升级直到足够的一般代码水平。
接下来描述了保持设备20的一些适合的实施例。保持设备20使相关性得分暴露于用户或者诸如例示性医学文档浏览器22的应用,例如作为将个体icd代码映射至相关性得分的表格文件,或者作为用于由问题列表排序方法消耗的数字对象。
参考图4-8,给出了另外的范例。在图4中(在标签“按年代”下方)示出了样本问题列表(pl)。在该表中,所述代码被以相反的年月日次序(“最新至最旧”)排序。在图5、6、7和8中分别示出了用于腹部、心脏、胸部和神经的文字化的排序。这些图4-8图示了一种可能的用户接口方法,其中,图4-8的表格中的一个表格在放射学工作站24的显示器30、32上显示(参见图1),其中用户能够从上方图形用户接口(gui)菜单50选择以下中的任一项:引出图4的表格的“按年代”的标签;引出图5的表格的“腹部”标签;引出图6的表格的“心脏”标签;引出图7的表格的“胸部”标签;或者引出图8的表格的“神经”标签。以这种方式,放射科医师能够通过使用例示性跟踪板或者某个其他指点设备28(例如,鼠标、轨迹球、触敏屏幕)点击上方菜单50中的上下文标签来快速地标识最相关的icd代码(或者在图4-8中,以自然语言文本编写的其等价相关临床意义)。
在预期的各种实施例中,放射学报告数据库10和问题列表数据库12被配置为使得针对先前的数据库中的每个放射学报告,保留当前问题列表的图像。以这种方式,将能够获得针对放射学解读的每个时间点的患者的问题列表。当以这种方式进行配置时,能够使用时间历史适当的问题列表应用临床代码排序,如已经描述的。
在另一预期变型中,考虑icd代码的“延迟”,被定义为代码被录入的时间点与放射学解读的时间点(或者“现在”)跨越的区间的持续时间。从报告的临床历史部分提取的每个icd代码能够与当前问题列表匹配并且能够获得代码的延迟。针对每个代码,能够创建时间相关性曲线,这指示代码的相关性如何随时间恶化。以这种方式,能够确定如果在两年内有报告,但是不超过那个,则发烧是相关的。类似地,能够确定恶性赘生物的相关性曲线是稳定的,这指示其相关性不受时间影响。
接下来描述了用于利用放射学工作站24的上下文中的临床代码排序的一些另外的方法。
当医学文档浏览器22启动以打开患者的新的放射学检查时,浏览器22从一个或多个医学仓库(例如,emr38或pacs36)检索一个或多个医学文档并且将nlp引擎40应用于所述文档以提取句子并且提取icd代码。针对每个概念,计算相关性得分,如已经描述的。从其中提取具有高相关性的代码的句子或短语能够在被显示在放射学工作站24的显示部件30、32上的报告中突出显示,或者能够分离地呈现。另一方面,在仅低相关性得分的情况下从其中提取代码的句子能够以灰色显示或者以其他方式去强调格式示出,或者可以使用省略号(“…”)作为占位符来呈现,其中“隐藏”文本任选被选择用于通过用户使用指点设备点击(或者悬停,或者以其他方式选择)来显示。医学文档浏览器22还能够被配置为仅突出显示/分离来自部分的选择集合的句子(例如,印象和临床历史)。这些仅仅是例示性范例。
还将意识到,所公开的处理可以任选被实施为存储由计算机(例如,例示性服务器34和/或图1的放射学工作站24的计算机26)可读并且可执行以执行所公开的临床代码相关性排序和呈现操作的指令(例如,计算机程序)的非瞬态存储介质。所述非瞬态存储介质例如可以包括硬盘或者其他磁性存储介质、光盘或其他光学存储介质、固态磁盘驱动器或其他电子存储介质、其各种组合等。
已经参考优选实施例描述了本发明。在阅读并且理解了前述详细描述之后可以想到修改和变更。本发明旨在被理解为包括所有这样的修改和变型,只要其落入权利要求书或者其等价方案的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!