一种区域单病种监管系统的制作方法
本发明涉及医疗信息技术领域,尤其涉及一种区域单病种监管系统。
背景技术:
国内学术、媒体、政策文件对于疾病监管与互联网技术结合研究的甚少,已有的评审体系重视科研、论文、重视经济效益等存在弊端,但在不断努力完善中。单个媒体,专科医生等很关注单病种监管,但仍严重缺乏科技的支撑。
技术实现要素:
本发明针对现有方式的缺点,提出一种区域单病种监管系统,用以解决现有技术存在的上述问题。
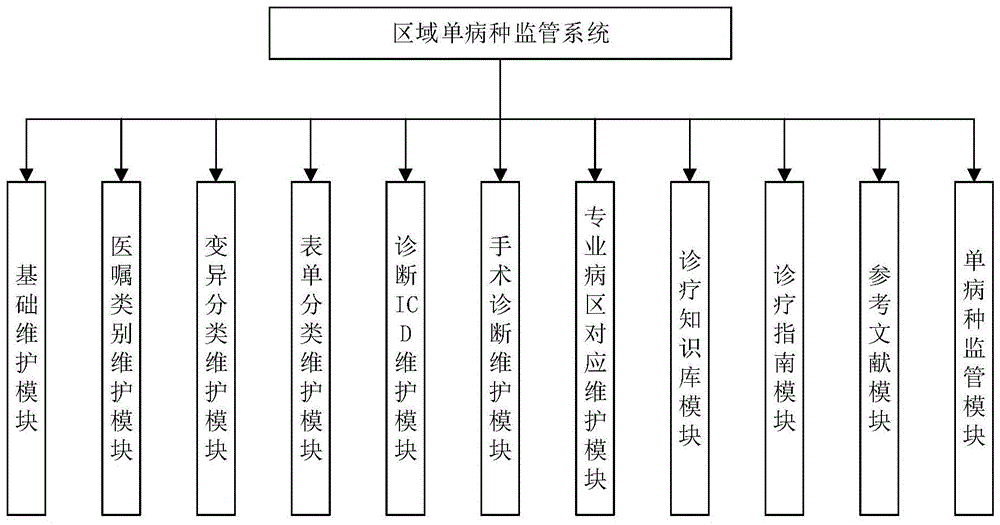
根据本发明的第一个方面,提供了一种区域单病种监管系统,包括基础维护模块、医嘱类别维护模块、变异分类维护模块、表单分类维护模块、诊断icd维护模块、手术诊断维护模块、专业病区对应维护模块、诊疗知识库模块、诊疗指南模块、参考文献模块、单病种监管模块,其中:单病种监管模块又包括路径维护单元及路径查询单元;
所述基础维护模块,用于录入和维护日常业务所需的基础资料信息,所述基础资料信息包括诊疗过程阶段信息、医嘱类别信息、变异分类信息、表单分类信息、诊断icd信息、手术诊断信息、专业病区对应信息、诊疗知识库信息、诊断指南信息及参考文献信息;
所述医嘱类别维护模块,用于医嘱类别的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
所述变异分类维护模块,用于维护临床路径的表单分类,供维护路径明细时使用,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
所述表单分类维护模块,用于维护临床路径的表单分类,供维护路径明细时使用,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
所述诊断icd维护模块,用于诊断icd的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
所述手术诊断维护模块,用于手术诊断的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
所述专业病区对应维护模块,用于维护科室与专业的对应,作为医生为科室病人选择临床路径的一个依据,预防医生选择错误的临床路径,用户可以根据具体情况或业务需要,进行相应的增加、删除;
所述诊疗知识库模块,用于预存临床疾病诊疗知识,用户可以根据具体情况或业务需要,进行相应的查看与维护;
所述诊疗指南模块,用于预存临床疾病诊断知识,用户可以根据具体情况或业务需要,进行相应的查看与维护;
所述参考文献模块,用于存储与分享工作方面的文献;
所述单病种监管模块,用于存储日常业务所需的路径信息,以满足临床路径信息管理需要;
所述路径维护单元,用于维护路径基本信息,所述路径基本信息包括路径名称、适用对象、活动时间、诊断依据、治疗方案、入径标准、排除条件、出院评估、变异、并发症、内容维护、医嘱维护、展示、模板管理;
所述路径查询单元,用于查看维护的路径信息。
进一步地,所述参考文献模块还包括,预先设置部分或全部被预设权限的用户查看、修改和/或删除。
进一步地,还包括,通过所述路径查询单元中的路径编码、路径名称、发布状态、标准、专业、注销状态,进行单一或组合条件的筛选查看信息。
进一步地,所述基础资料信息包括分类知识图谱以对其包括的信息进行分类。
进一步地,还包括,分类知识图谱的预先构建:
抽取基础资料信息,通过专家对其中的信息进行归纳,形成各类信息的实体和关系引用规则库;
通过大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型;
使用已经训练好的大数据机器模型,对未标注的信息进行预先标注,形成分类知识图谱。
进一步地,所述大数据神经网络分词方法,是指:融合了大数据分析方法、词典数据库的分词规则、神经网络聚类和分类的一种方法。
进一步地,所述大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,包括:
接收信息;
基于词典数据库的分词规则分词;
专家标注;
大数据分析;
神经网络机器学习;
神经网络聚类;
神经网络分类;
输出分类结果。
进一步地,所述大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,还包括:
合并信息中的冗余节点,删除无用节点。
进一步地,所述大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,还包括:
合并信息中的冗余字、词,删除无用字、词。
进一步地,所述机器学习规则设于crf模型、bilstm模型、或bert模型中。
与现有技术相比,本发明的有益效果是:
本发明不仅实现了信息资源共享、数据交换、统计分析,降低了监管成本。
本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为本发明实施例一中的一种区域单病种监管系统的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
在本发明的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分例,实施而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。
实施例一
如图1所示,提供了本发明一个实施例的一种区域单病种监管系统,包括基础维护模块、医嘱类别维护模块、变异分类维护模块、表单分类维护模块、诊断icd维护模块、手术诊断维护模块、专业病区对应维护模块、诊疗知识库模块、诊疗指南模块、参考文献模块、单病种监管模块,其中:单病种监管模块又包括路径维护单元及路径查询单元;
基础维护模块,用于录入和维护日常业务所需的基础资料信息,基础资料信息包括诊疗过程阶段信息、医嘱类别信息、变异分类信息、表单分类信息、诊断icd信息、手术诊断信息、专业病区对应信息、诊疗知识库信息、诊断指南信息及参考文献信息;
基础维护模块,主要用于维护住院诊疗过程的主要环节,即诊疗过程阶段,以及每个诊疗过程阶段包含的诊疗活动。用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作。基础维护模块设计特点:数据相对稳定,不经常变化。
基础维护模块中的内容及其说明具体如下:
编码:系统自动生成,默认两位,只能用数字0-9表示,不能为空。
名称:最长50个字符,可为汉字、数字或英文字母;不能为空;不能重复。
助记码:根据名称自动生成。
注销:某诊疗过程阶段不想使用,不想删除或删除不掉,可将其注销。
所有信息输入好后,点击“保存(s)”,或按“ctrl+s”键,进行保存。
医嘱类别维护模块,用于医嘱类别的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
医嘱类别维护模块,主要用于医嘱类别的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作。数据相对稳定,不经常变化。
变异分类维护模块,用于维护临床路径的表单分类,供维护路径明细时使用,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
表单分类维护模块,用于维护临床路径的表单分类,供维护路径明细时使用,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
诊断icd维护模块,用于诊断icd的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
手术诊断维护模块,用于手术诊断的维护,用户可以根据具体情况或业务需要,进行相应的增加、修改、删除工作;
专业病区对应维护模块,用于维护科室与专业的对应,作为医生为科室病人选择临床路径的一个依据,预防医生选择错误的临床路径,用户可以根据具体情况或业务需要,进行相应的增加、删除;
诊疗知识库模块,用于预存临床疾病诊疗知识,用户可以根据具体情况或业务需要,进行相应的查看与维护;
诊疗指南模块,用于预存临床疾病诊断知识,用户可以根据具体情况或业务需要,进行相应的查看与维护;
参考文献模块,用于存储与分享工作方面的文献;
单病种监管模块,用于存储日常业务所需的路径信息,以满足临床路径信息管理需要;
单病种监管模块,在正式使用单病种监管系统进行日常业务处理前,首先要建立日常业务所需的路径信息,以满足临床路径信息管理需要。
路径维护单元,用于维护路径基本信息,路径基本信息包括路径名称、适用对象、活动时间、诊断依据、治疗方案、入径标准、排除条件、出院评估、变异、并发症、内容维护、医嘱维护、展示、模板管理;
路径名称:最长50个字符,可为汉字、数字或英文字母;不能为空;不能重复。
路径名称包括路径编码:默认10位,系统自动生成。前2位表示标准;4~7位是路径的专业编码;后3位是顺序码。
标准:标准分三种:卫生部发布的临床路径为“国标—gb”;卫生厅发布的临床路径为“省标—db”;医院自己发布的临床路径为“院标—qb”。不能为空。
路径查询单元,用于查看维护的路径信息。
还包括,通过路径查询单元中的路径编码、路径名称、发布状态、标准、专业、注销状态,进行单一或组合条件的筛选查看信息。
本发明还包括,分类知识图谱的预先构建:
抽取基础资料信息,通过专家对其中的信息进行归纳,形成各类信息的实体和关系引用规则库;
通过大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型;
大数据神经网络分词方法,是指:融合了大数据分析方法、词典数据库的分词规则、神经网络聚类和分类的一种方法。
大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,包括:
接收信息;
基于词典数据库的分词规则分词;
专家标注;
大数据分析;
神经网络机器学习;
神经网络聚类;
神经网络分类;
输出分类结果。
大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,还包括:
合并信息中的冗余节点,删除无用节点。
大数据神经网络分词方法,基于专家标注的规则以及机器学习规则训练大数据机器模型,还包括:
合并信息中的冗余字、词,删除无用字、词。
机器学习规则设于crf模型、bilstm模型、或bert模型中。
crf是马尔科夫随机场的特例,它假设马尔科夫随机场中只有x和y两种变量,x一般是给定的,而y一般是在给定x的条件下我们的输出。
x和y有相同的结构的crf就构成了线性链条件随机场。
crf的数学语言描述:设x与y是随机变量,p(y|x)是给定x时y的条件概率分布,若随机变量y构成的是一个马尔可夫随机场,则称条件概率分布p(y|x)是条件随机场。(判别式模型)
linear-crf的数学定义:设x=x1,x2,…,xn,y=y1,y2,…,yn均为线性链表示的随机变量序列,在给定随机变量序列x的情况下,随机变量y的条件概率分布p(y|x)构成条件随机场,即满足马尔可夫性:p(yi|x,y1,y2,…,yn)=p(yi|x,yi-1,…,yi+1),则称p(y|x)为线性链条件随机场。
lstm的全称是longshort-termmemory,它是rnn(recurrentneuralnetwork)的一种。lstm由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。bilstm是bi-directionallongshort-termmemory的缩写,是由前向lstm与后向lstm组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。
lstm模型是由t时刻的输入词xt,细胞状态ct,临时细胞状态
第一,是这个模型非常的深,12层,并不宽(wide),中间层只有1024,而之前的transformer模型中间层有2048。这似乎又印证了计算机图像处理的一个观点——深而窄比浅而宽的模型更好。
第二,mlm(maskedlanguagemodel),同时利用左侧和右侧的词语,这个模型的核心是聚焦机制,对于一个语句,可以同时启用多个聚焦点,而不必局限于从前往后的,或者从后往前的,序列串行处理。不仅要正确地选择模型的结构,而且还要正确地训练模型的参数,这样才能保障模型能够准确地理解语句的语义。bert用了两个步骤,试图去正确地训练模型的参数。第一个步骤是把一篇文章中,15%的词汇遮盖,让模型根据上下文全向地预测被遮盖的词。假如有1万篇文章,每篇文章平均有100个词汇,随机遮盖15%的词汇,模型的任务是正确地预测这15万个被遮盖的词汇。通过全向预测被遮盖住的词汇,来初步训练transformer模型的参数。
然后,用第二个步骤继续训练模型的参数。譬如从上述1万篇文章中,挑选20万对语句,总共40万条语句。挑选语句对的时候,其中210万对语句,是连续的两条上下文语句,另外210万对语句,不是连续的语句。然后让transformer模型来识别这20万对语句,哪些是连续的,哪些不连续。
这两步训练合在一起,称为预训练pre-training。训练结束后的transformer模型,包括它的参数,是遮蔽语言模型(maskedlanguagemodel,mlm)的通用的语言表征模型,来克服上文提到的单向性局限。
bert目前已经刷新的11项自然语言处理任务的最新记录包括:将glue基准推至80.4%(绝对改进7.6%),multinli准确度达到86.7%(绝对改进率5.6%),将squadv1.1问答测试f1得分纪录刷新为93.2分(绝对提升1.5分),超过人类表现2.0分。
使用已经训练好的大数据机器模型,对未标注的信息进行预先标注,形成分类知识图谱。
在本申请所提供的实施例中,应该理解到,所揭露的系统、装置、模块和/或单元,可以通过其它的方式实现。例如,以上所描述的方法实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!