人工耳蜗汉语声调编码策略的评估系统的制作方法
本发明涉及人工视听觉技术领域,具体是一种人工耳蜗汉语声调编码策略的评估系统。
背景技术:
无论先天或后天形成的听力障碍会对患者的正常生活造成极大的困扰,甚至可能影响患者的语言功能。截至2013年止,世界卫生组织统计显示全球约有3.6亿听力语言障碍的残疾人,其中我国有2780万,是世界上听力残疾最多的国家。听觉障碍可以大致分为传导性耳聋、感音神经性耳聋及混合性耳聋三类。感音神经性耳聋和混合性耳聋起患者可以通过佩戴人工耳蜗(cochlearimplants,ci)的方式获取部分听力,与他人进行交流,提高生活的质量。
人工耳蜗通过特定的编码方式将声音信号转化为耳蜗内电刺激信号帮助重症听力患者恢复部分听觉功能,主要包括语音处理器、无线传输装置、接收线圈和耳蜗电极4个部分。语音处理器中的语音编码策略决定了人工耳蜗保留语音的质量,为了获得更好的听觉效果,需要尽可能有效地提取语音信号的特征,并完善语音编码策略。
传统商用语音编码策略按照信号提取的程度大致可以分为包络特征方案与精细特征方案两类。传统的是f0/f2(f0代表语音信号的基频和f2代表第二共振峰)语音编码方案应用在澳大利亚cochlear公司生产的wsp语音处理器。cis(continuousinterleavedsampler)方案利用间隔的脉冲刺激策略改进了传统压缩模拟(ca)方案中由于电极同时刺激所引起的电场干扰问题,同时为了更好的表达时域信息,cis策略还采用了更高的刺激速率。众多实验结果表明,cis编码方案在语音识别率上比ca方案有明显的提高。该编码方案也被成功运用在美国ab公司的clarion系列人工耳蜗与奥地利medel公司的耳蜗产品上。ace(advancedconfinedencoding)方案是目前在澳大利亚cochlear公司的人工耳蜗产品中运用比较广泛的一种波形编码方案。ace主要改进了cis编码方案中频率分辨率不足的问题,将语音信号划分为带宽更窄的子带,然后动态的选择刺激通道;同时利用高速率的脉冲刺激,获得了良好的语音识别率。包络特征方案,主要传递声音信号的谱包络信息而忽略精细结构信息。由于包络信息在语言理解方面有重要作用,而精细结构与声调和音乐感知更为相关,因此这些方案不能够很好的感知声调与音乐信息。
然而,由于汉语与英语语言特征的不同,当目标言语为汉语普通话时,根据英语设计的语音编码策略更容易出现能量掩蔽和信息掩蔽,导致语音感知能力差、语音声调识别能力差、无法较好地感知音乐等问题。
针对这个问题,近年来许多能的新的编码策略来保留更多语音信息。2012-2013年,美国华盛顿大学聂开宝等人提出了谐波单边带编码方案(harmonicsinglesidebandencoder,hsse),该策略首先提取出语音信号中的基频信息,然后在各个频率通道内选出最强的谐波成分,最后再利用移频处理技术将高次谐波移动到基频范围内进行刺激,从而将语音信号中丰富的声调信息编码到刺激信号中。通过了神经数字仿真和心理物理学测试表明,hsse方案可以比cis方案更好地传达时间声调线索,增强人工耳蜗植入的语音感知。又如力声特公司采用的c-tone编码系统,通过提高语音信号的时域振幅包络与f0轨迹的相关性,能够在复杂环境中减少噪音和提取f0,在词汇音调、单音节和双音节的识别上显著改善,词汇声调中,第三声调识别率改善幅度最大,第四声调识别率改善幅度最小,双音节识别率比单音节的改善幅度大。med-elc40+采用精细结构编码策略(finestructureprocessing,fsp),持续使用6周后,受试者声调识别成绩较更换前有显著提高,差异具有统计学意义;普通话噪声下言语测试成绩与更换前日常使用cis编码策略所得成绩接近,差异无统计学意义(t=1.475,p=0.173)。说明,在人工耳蜗言语提取方案中增加对时域精细结构线索的提取,有利于改善耳蜗植入者对声调的感知能力和对言语整体性的理解,进而有助于提高人工耳蜗植入者的生活质量。
同时,新型语音编码主要是通过临床试验才能应用到人工耳蜗产品上。然而,当前语音库内容多,范围广,逐一检测费时费力。而且,涉及到植入假体的语音编码算法审查严格,临床试验价格昂贵,受试者也存在对新策略测试的抗拒。而多数科研院所与高校采用听觉神经数字仿真模型评估新型语音编码策略,该系统速度快,价格便宜。但是,由于目前听觉神经通路数学模型主要模拟外周听觉通路的功能,缺乏中枢水平的听觉神经通路的功能模拟,降低了数字模拟的价值。
上述的问题,都限制了汉语新型语音编码算法的发展。
技术实现要素:
本发明的目的是解决现有技术中存在的问题。
为实现本发明目的而采用的技术方案如下所述,人工耳蜗汉语声调语音编码策略的评估系统,主要包括语音信号采集模块、信号预处理模块、频率通道划分模块、基频检测模块、谐波选择模块、移频处理模块、滤波模块、语音合成模块和语音播放模块。
所述语音信号采集模块采集外部语音信号s(t),并发送至基频检测模块和信号预处理模块。
所述语音信号采集模块为人工耳蜗的麦克风。
所述外部语音信号s(t)为汉语语音,包括林氏六音搭配四个汉语声调而形成的24个音节。
所述信号预处理模块对语音信号s(t)进行预加重、数据分帧和加窗处理,并将预处理后的语音信号s(t)发送至频率通道划分模块。
进一步,对语音信号s(t)进行预加重的步骤为:将语音信号s(t)输入到一阶巴特沃斯高通滤波器中,输出预加重后的语音信号s(t)。
一阶巴特沃斯高通滤波器的传递函数h(z)如下所示:
h(z)=1-k*z-1。(3)
式中,k为滤波系数。z表示待处理的语音信号。
所述频率通道划分模块利用带通滤波器将预处理后的一路语音信号s(t)划分为若干子路语音信号,并发送至谐波选择模块。
所述频率通道划分模块模拟人耳感应位置分布。
所述基频检测模块利用最小二乘谐波算法获得语音信号s(t)中的基频值f0,并将基频值f0发送至移频处理模块。
进一步,将预处理后的一路语音信号s(t)划分为若干子路语音信号的步骤为:将一路语音信号s(t)输入到greenwood耳蜗频率—位置函数中。greenwood耳蜗频率—位置函数对语音信号进行频段划分,从而输出若干子路语音信号。
greenwood耳蜗频率—位置函数如下所示:
f=a(10αx-k)。(4)
式中,f表示耳蜗上对应的频率点,a和k为常数,x为耳蜗基底膜上距顶部的位置,α是与位置x相关的常系数。
所述谐波选择模块分别选出每路语音信号中幅值最大的谐波分量hk(t),并发送至移频处理模块。
进一步,选出每路语音信号中幅值最大的谐波分量的步骤如下:
1)谐波选择模块对每路语音信号进行fft变换。
2)基于每路语音信号的基频值f0,在频谱上找出所有谐波分量对应的幅值。
3)选取幅值最大的谐波分量hk(t)。
所述移频处理模块对选取的谐波分量hk(t)进行降频处理,并发送滤波模块。
进一步,对选取的谐波分量hk(t)进行降频处理的主要步骤如下:
1)所述移频处理模块在语音信号s(t)上乘以exp(-j2π(k-1)f0t),使语音信号s(t)的谐波分量hk(t)的频谱从kf0转换为f0。
2)将输入信号s(t)输入到复滤波器中,与滤波器的脉冲响应函数
3)以复滤波器输出的信号实部为调制信号
所述滤波模块对降频后的谐波分量进行低通滤波,发送到幅度调制语音信号合成模块。包络信号是降频后的低通滤波的谐波信号。载波信号是高频正弦波。进行幅度调制信号合成,输出该信号。
所述滤波模块该信号发送至语音合成模块。
所述语音合成模块对谐波分量进行编码,并发送至播放模块。
所述播放模块播放编码后的信号。
基频检测模块、信号预处理模块、频率通道划分模块、谐波选择模块、移频处理模块、滤波模块、语音合成模块和播放模块集成在这套语音评估系统中。
需要说明的是,本发明采用的基本语音材料为林氏六音,搭配四种汉语声调,分别为一声(阴平),二声(阳平),三声(上声),四声(去声),得到24个声调音节。利用待测试的新型汉语语音编码策略处理这24个声调音节,播放给受试者,完成声调识别的听力任务,统计声调识别的正确率,来评估待测试的汉语语音编码策略的优劣。
本发明的技术效果是毋庸置疑的。针对现代语音编码算法语音库评估测试的内容多、时间长导致的检测效率相对低、成本高的问题,本发明提出将林氏六音与汉语声调语音编码算法结合起来评估汉语声调语音编码策略,实现对汉语声调语音编码的简单高效检验,并用到听力言语康复训练中。
本专利关键是避开将新型语音编码策略下载固化到人工耳蜗产品中,而是利用听健志愿者来模拟测试人工耳蜗新型语音编码的效果。本专利不仅可以对汉语语音编码算法进行检验,也能辅助测试人工耳蜗听障儿童的声调语音感知能力。而且,本专利测试的内容少,时间短,相对的检测效率高,成本低,可以提高患者治疗体验,可以对汉语语音编码算法进行检验,并训练听障儿童的声调语音感知能力。本专利提取出与语音声调相关的基频及其谐波进行调制,并且通过移频处理方式进行包络信息提取,增加相位信息改善了时域的波形,因而能够体现出复合波形的存在,包含了更丰富的精细结构。由于林氏六音覆盖大部分口语的常用频率范围,本专利能够快速而有效地检查儿童能否察觉到言语频率范围内的声音,具有简单高效,可行性高等优点。
附图说明
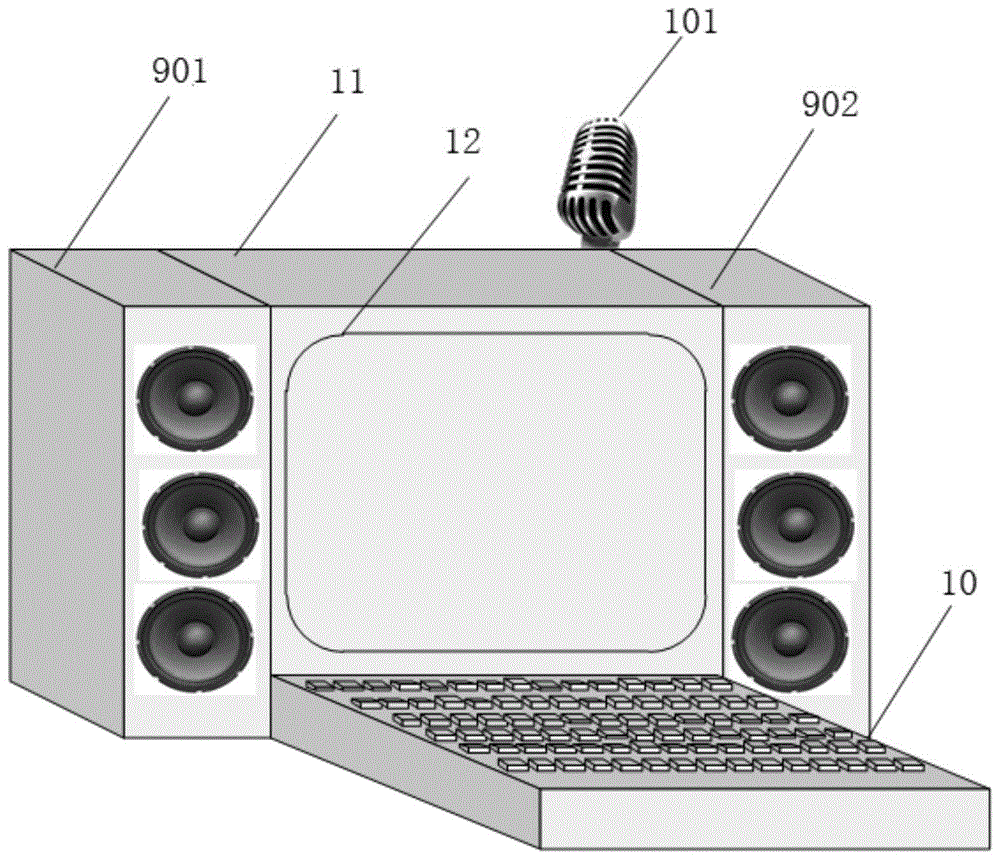
图1为人工耳蜗声调语音编码策略评估系统硬件示意图;
图2为汉语编码评估系统结构框图;
图3为汉语编码评估系统工作示意图;
图4为评估系统的声调识别率实验流程;
图中,语音信号采集模块1、基频检测模块2、信号预处理模块3、频率通道划分模块4、谐波选择模块5、移频处理模块6、滤波模块7、语音合成模块8、语音播放模块9、输入控制器10、评估系统主机11、显示器12、麦克风101、左侧扬声器901和右侧扬声器902。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1至图4,人工耳蜗汉语语音编码策略的评估系统,主要包括语音信号采集模块1、基频检测模块2、信号预处理模块3、频率通道划分模块4、谐波选择模块5、移频处理模块6、滤波模块7、语音合成模块8、语音播放模块9和用于对其它模块进行控制的输入控制器10。
参见图3,人工耳蜗汉语语音编码策略的评估系统集成为评估系统的主机。
所述语音信号采集模块1采集外部语音信号s(t),并发送至基频检测模块2和信号预处理模块3。
所述语音信号采集模块1具有麦克风101。
所述外部语音信号s(t)为汉语语音,包括林氏六音搭配四个汉语声调而形成的24个音节。
所述信号预处理模块3对语音信号s(t)进行预加重、数据分帧和加窗处理,并将预处理后的语音信号s(t)发送至频率通道划分模块4。
进一步,对语音信号s(t)进行预加重的步骤为:将语音信号s(t)输入到一阶巴特沃斯高通滤波器中,输出预加重后的语音信号s(t)。
一阶巴特沃斯高通滤波器的传递函数h(z)如下所示:
h(z)=1-k*z-1。(5)
式中,k为滤波系数。z表示待处理的语音信号。k取1或接近1。
所述加窗处理所用的窗函数包括矩形窗,汉宁窗,海明窗等。
所述频率通道划分模块利用带通滤波器将预处理后的一路语音信号s(t)划分为若干子路语音信号,并发送至谐波选择模块5。
所述频率通道划分模块模拟人耳感应位置分布。
所述基频检测模块2利用最小二乘谐波算法获得语音信号s(t)中的基频值f0,并将基频值f0发送至移频处理模块6。
进一步,将预处理后的一路语音信号s(t)划分为若干子路语音信号的步骤为:将一路语音信号s(t)输入到greenwood耳蜗频率—位置函数中。greenwood耳蜗频率—位置函数对语音信号进行频段划分,从而输出若干子路语音信号。
greenwood耳蜗频率—位置函数如下所示:
f=a(10αx-k)。(6)
式中,f表示耳蜗上对应的频率点,a和k为常数,x为耳蜗基底膜上距顶部的位置,α是与位置x相关的常系数。
所述谐波选择模块5分别选出每路语音信号中幅值最大的谐波分量hk(t),并发送至移频处理模块6。
选出每路语音信号中幅值最大的谐波分量的步骤如下:
1)谐波选择模块5对每路语音信号进行fft变换。
2)基于每路语音信号的基频值f0,在频谱上找出所有谐波分量对应的幅值。
3)选取幅值最大的谐波分量hk(t)。
所述移频处理模块6对选取的谐波分量hk(t)进行降频处理,并发送滤波模块7。
对选取的谐波分量hk(t)进行降频处理的主要步骤如下:
1)所述移频处理模块6在语音信号s(t)上乘以exp(-j2π(k-1)f0t),使语音信号s(t)的谐波分量hk(t)的频谱从kf0转换为f0。j为虚数。
2)将输入信号s(t)输入到复滤波器中,与滤波器的脉冲响应函数
3)以复滤波器输出的信号实部为调制信号
所述滤波模块7对降频后的谐波分量进行低通滤波,发送到幅度调制语音语音合成模块8。包络信号是降频后的低通滤波的谐波信号。载波信号是高频正弦波。进行幅度调制信号合成,输出该信号。
所述滤波模块该信号发送至语音合成模块8。
所述语音合成模块对谐波分量进行编码,并发送至语音播放模块9。
所述语音播放模块9播放编码后的信号。
语音播放模块9的扬声器输出为分别设置在评估系统主机11两侧的左侧扬声器901和右侧扬声器902。
基频检测模块2、信号预处理模块3、频率通道划分模块4、谐波选择模块5、移频处理模块6、滤波模块7、语音合成模块8和语音播放模块9集成在这套语音评估系统中。评估系统包括集成有各模块的评估系统主机11和显示器12。
使用者可以通过输入控制器10对人工耳蜗汉语语音编码策略的评估系统中各模块的参数进行设置。
实施例2:
参见图2,人工耳蜗汉语语音编码策略的评估系统,主要包括语音信号采集模块1、基频检测模块2、信号预处理模块3、频率通道划分模块4、谐波选择模块5、移频处理模块6、滤波模块7、语音合成模块8和语音播放模块9。
验证人工耳蜗汉语语音编码策略的评估系统的实验,主要步骤如下:
1)所述频率通道划分模块4中常规语音信号预处理与频率通道划分如下:
一般地,语音信号的大部分能力集中于低频端,高频端的信噪比会比较低。采用截止频率为1300hz的一阶巴特沃斯高通滤波器完成对高频段的补偿:
h(z)=1-k*z-1(k=1)(7)
语音信号是不平稳的信号,一般认为,语音信号在短时间内(10~30ms)具有准平稳的特性,所以采用平稳信号的求解系统来分析语音信号。通常在语音信号中,选用语音分帧来截取准稳态信号。
将分帧后的语音信号乘以一定加权的有限长度的窗函数,得到分帧信号。优选地,采用在相同的过渡带下,能够获得更好的阻带衰减的海明窗,能够较好的反映出短时信号的频谱特性。
正常耳蜗中,在处理声音时具有位置编码的功能。根据正常耳蜗感音机理的经典学说,从耳蜗的顶回到底回,不同频率的语音信号会刺激基底膜中的相应位置,基底膜靠近蜗底处响应高频信号,靠近蜗尖的位置响应低频信号。人工耳蜗语音编码策略模拟人耳感应位置分布来划分频率通道,将采集的声音信号通过一组带通滤波器,每一段的中心频率与刺激电极在耳蜗基底膜上的频率位置相对应。
2)所述基频检测模块2中基频信息提取方式如下:
采用最小二乘谐波模型,提取基频f0和谐波。语音信号表示为s(t),h(t)为谐波成分,n(t)为噪声成分,然后可以将信号s(t)表示为s(t)=h(t)+n(t)(8)
f0为基频,k是给定采样率下的谐波总数,每个特定谐波hk(t)都有自己的幅度调制ak(t)、频率kf0和相位函数
则原始信号与谐波成分之间的均方误差(mse)可以表示为公式(3),均方误差接近于零时,此时的信号可以近似用谐波成分进行表示,而该谐波信号频率值就可以表示成信号的基频或倍频。
3)所述谐波选择模块5中谐波信号选取方式如下:
优选地,不能将通道内所有谐波都提取出来进行处理,这就需要在子带通道内对谐波分量进行合适的选择。由于听觉掩蔽效应,通道内能量最强的谐波通常在声音感知过程中占主导作用,而低能分量被掩蔽。
4)所述移频处理模块6中移频方式如下:
除了基频以外,多数通道内选取的谐波信号属于高频信号,在电刺激感知阈值的限制下,并不能直接作用于调制信号,需要进行降频处理谐波模型(4)被转换为以下分析形式:
其中“re”表示取复杂信号和符号j=sqet(-1)的实部
首先将输入信号s(t)乘以exp(-j2π(k-1)f0t),这样hk(t)的频谱将从其原始位置kf0转换为f0,然后将s(t)通过一个过滤器,即与滤波器的脉冲响应函数
比较方程式(4)和(6),可以看出
实施例3:
一种验证人工耳蜗汉语语音编码策略的评估系统的声调识别正确率的实验,主要如下:
分别联系听健受试者和听障受试者进行声调识别正确率统计测试。整个测试在安静的隔音室中进行,每位受试者单独进行测试。利用声码器合成待检测汉语语音策略编码的声音,即选用一组正弦信号作为调制信号,以每个通道的中心频率fc作为调制频率,将调制后的各通道信号进行累加,输出信号y(t)即为声码合成后的编码信号。通过听健被试的声学模拟来检测使用的汉语语音编码策略的效果。
令原始林氏六音搭配四个声调的语音,得到原始的24个声调音节,并将每个原始声调音节重复十次,共计二百四十个音节随机播放,并让受试者识别出所听声音内容与声调,统计每个受试者识别每个原始声调音节的正确率。然后将原始的24个声调音节,采用传统语音编码后,并将每个传统编码声调音节重复十次,共计二百四十个音节随机播放,并让受试者识别出所听声音内容与声调,统计每个受试者识别每个传统声调音节的正确率。将上述原始的24个声调音节,采用新型语音编码后,并将每个新型编码声调音节重复十次,共计二百四十个音节随机播放,并让受试者识别出所听声音内容与声调,统计每个受试者识别每个新型编码声调音节的正确率。
然后利用
针对每一音节,计算每一受试者识别正确率与该受试者所在小组平均识别正确率偏差值δxi,并与该组三倍算数平均值标准偏差
异常数据剔除完毕后,分别计算听健组和听障组每个被试识别每一种声调音节正确率的算术平均值和方差。
听健志愿者的结果中,原始声调音节的识别率作为一种对照,新型编码声调音节的识别率与传统编码声调音节的识别率比较,来判断新型编码是否比某种传统编码在语音声调识别方面有改善,以及声调识别改善的程度。
听障志愿者的结果中,原始声调音节的识别率作为一种对照,新型编码声调音节的识别率与传统编码声调音节的识别率比较,来判断新型编码是否比某种传统编码在语音声调识别方面有改善,以及声调识别改善的程度。
- 还没有人留言评论。精彩留言会获得点赞!