一种药代动力学参数简化分析方法及系统与流程
[0001]
本发明涉及药物代谢动力学技术领域,尤其涉及一种药代动力学参数简化分析方法及系统。
背景技术:
[0002]
药物临床试验的药代动力学分析主要是对各受试者在每个采血时间点的血药浓度进行分析并提取药代动力学参数。在众多药代动力学参数中,cmax和tmax都属于最重要的参数之一。cmax代表各受试者的峰值血药浓度,tmax代表受试者血药浓度达到峰值cmax时的采血时间点。
[0003]
在统计师拿到受试者的血药浓度数据时,有些血药浓度会被标记为“bql”,代表这个血药浓度数据低于测量方法的定量下限,无法被测量。在对血药浓度数据进行分析之前,统计师通常需要对数据中的这种“bql”数值建立bql转换规则。
[0004]
对于血药浓度的描述性统计分析,最重要的数值之一为试验组中各个剂量组在各计划采血时间点的血药浓度平均值,而统计师在对血药浓度进行描述性分析之前,也需要将所有“bql”值进行转换。
[0005]
统计师通常使用phoenix winnonlin软件对血药浓度数据进行分析,提取药代动力学参数,再将计算结果进行整合,而后将整合后的数据代入到sas软件中进行各剂量组间差异的分析。当使用phoenix winnonlin软件时,统计师需要先确定数据集文件格式符合winnonlin软件要求,若不符合可能还需要先使用sas软件进行格式转换。数据集导入到winnonlin软件后,需要在软件中先建立“bql”值转换规则,并将规则应用至导入的数据集,而后统计师需要在winnonlin软件中建立非房室模型分析模块以及描述性分析模块来分别提取药代动力学参数和对血药浓度的描述性分析。将“bql”值转换后的数据集文件分别导入到各个模块之后系统会分别生成对应的结果数据集。而血药浓度数据集中所含的一些其他重要变量需要统计师在winnonlin软件中进行选择才可以保留至结果数据集,统计师可能需要再将各个结果数据集分别导入到sas软件中进行合并,以便进行后续的分析。有些含中文字符的数据在winnonlin软件中会以问号来显示,在重新导回至sas时可能会造成数据丢失。
[0006]
winnonlin软件可以帮助统计师提取各种药代动力学参数,但对于只想得到cmax、tmax以及试验组中各剂量组在各计划采血时间点的平均血药浓度的统计师来说操作起来会比较麻烦且耗费时间,而且可能需要花费额外的时间来合并结果数据集或在winnonlin和sas之间进行数据导入。winnonlin对于受试者治疗组的识别也相对比较麻烦,统计师可能需要在将数据集导入到winnonlin软件之前先提取子数据集或在winnonlin软件中设置weight变量。
[0007]
现有技术至少存在以下不足:
[0008]
1.对于只想分析cmax、tmax和各剂量组在各采血点的平均血药浓度的情况,数据处理比较麻烦,耗时长。
[0009]
2.winnonlin涉及数据集格式转换、治疗组识别、“bql”逻辑建立、分析流程建立、结果与原数据集的合并、“na”值与“nd”值的生成,以及数据导回到sas等一系列操作
[0010]
3.winnonlin价格昂贵,实验分析成本高。
技术实现要素:
[0011]
为解决现有技术中存在的技术问题,本发明提供了一种药代动力学参数简化分析方法及系统,该方法在对药物临床试验单次给药试验的药代动力学进行分析时,数据集中低于测量方法测量下限的值可以自定义字符表示,比如“bql”值,并可以对“bql”值进行自定义的转换,并得到cmax、tmax、试验组中各个剂量组在各计划采血时间点的血药浓度平均值等重要参数结果,运算的结果将在不对原数据集的格式以及数据集中其他变量数据有任何影响与改变的情况下合并至原数据集,生成新的数据集或直接覆盖原数据集。统计师可以在sas软件中简单地使用此pkbql macro程序快速地得到所需运算结果,并可直接开展后续的分析研究工作,不需要花费大量时间在不同软件之间进行数据集导入、合并或整理。
[0012]
本发明对数据集中的血药浓度的低于测量方法测量下限的值(为说明更清楚简洁,此处以第四字符定义为“bql”,第二字符定义为“nd”为例进行说明)“bql”进行转化,达到cmax之前的“bql”转化为0,达到cmax之后的“bql”值转化为第二字符,比如“nd”,若受试者所有血药浓度数据均为“bql”则全部转化为“nd”。本发明还对受试者所在治疗组进行分组指示,用于指示受试者所属采血时间点和剂量组,分析cmax、tmax、以及试验组各剂量组在各计划采血时间点的平均血药浓度,并直接与原数据集的数据进行合并,生成新的数据集或直接覆盖原数据集。若受试者所有血药浓度数据为“nd”,则生成的cmax与tmax也标记为“nd”,试验组各剂量组在各计划采血时间点的平均血药浓度会将全部“bql”值转换为0后进行计算,对照组各剂量组在各计划采血时间点的平均血药浓度,因为没有参考意义所以会以“na”进行标注,以上对bql值的转换符合一般药代动力学分析的标准。
[0013]
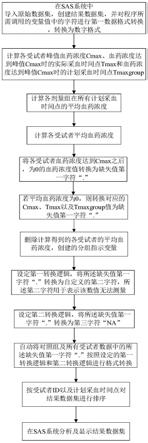
本发明提供了一种药代动力学参数简化分析方法,包括以下步骤:
[0014]
s100:导入原始数据集,创建结果数据集,并对程序所需调用的变量值中的字符进行第一数据格式转换,转换为数字格式;
[0015]
s200:计算各受试者峰值血药浓度cmax、血药浓度达到峰值cmax时的实际采血时间点tmax和血药浓度达到峰值cmax时的计划采血时间点tmaxgroup;
[0016]
s300:计算各剂量组在所有计划采血时间点的平均血药浓度;
[0017]
s400:计算各受试者平均血药浓度;
[0018]
s500:第二数据格式转换步骤,根据步骤s200中计算的cmax及步骤,将各受试者血药浓度达到cmax之后数据为0的血药浓度值进行格式转换,并对平均血药浓度为0的受试者,对应的cmax、tmax以及tmaxgroup值进行格式转换;
[0019]
s600:设定转换逻辑步骤,具体包括以下步骤:
[0020]
s601:设定第一转换逻辑,将所述缺失值第一字符“.”转换为自定义的第二字符,所述第二字符用于表示该数值无法测量;
[0021]
s602:设定第二转换逻辑,将所述缺失值第一字符“.”转换为第三字符“na”;
[0022]
s700:第三格式转换及排序步骤,
[0023]
自动将对照组及所有受试者数据中的所述缺失值第一字符“.”按照设定的第一转
换逻辑和第二转换逻辑进行格式转换;
[0024]
按受试者id以及计划采血时间点对结果数据集进行排序;
[0025]
s800:在sas系统执行步骤s100-步骤s700,并在步骤s700执行之后,将结果数据集在sas系统进行分析及显示。
[0026]
优选地,步骤s100具体包括如下步骤:
[0027]
s101:导入原始数据集,提取原始数据集中的全部信息创建结果数据集;
[0028]
s102:在结果数据集中提取运算所需的变量并重新命名;
[0029]
s103:将从结果数据集中提取的变量中第四字符转换为缺失值第一字符“.”,所述第四字符为原始数据集中自定义字符,用于代表该血药浓度数据低于测量方法的定量下限,无法测量;
[0030]
s104:将结果数据集中所有缺失值第一字符“.”转换为“0”;
[0031]
s105:创建分组指示变量,用于指示结果数据集中每一行数据所属采血时间点和剂量组,并将步骤s102重命名的变量以及创建的分组指示变量添加到结果数据集。
[0032]
优选地,步骤s200具体包括如下步骤:
[0033]
s201:计算各受试者峰值血药浓度cmax;
[0034]
s202:根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达到cmax时的计划采血时间点tmaxgroup;
[0035]
s203:将各受试者的cmax、tmax和tmaxgroup添加到结果数据集。
[0036]
优选地,步骤s300具体包括如下步骤:
[0037]
s301:根据步骤s105创建的分组指示变量来识别剂量组与计划采血时间点的组合;
[0038]
s302:根据结果数据集中各剂量组中的血药浓度数据,计算各剂量组在所有计划采血时间点的平均血药浓度;
[0039]
s303:将计算得到的各剂量组在所有计划采血点的平均血药浓度,保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;
[0040]
s304:将所述第一内部数据集合并到结果数据集,合并后,删除所述第一内部数据集。优选地,步骤s500具体包括如下步骤:具体包括以下步骤:
[0041]
s501:将各受试者血药浓度达到cmax之后,为0的血药浓度值转换为缺失值第一字符“.”;
[0042]
s502:根据步骤s400中计算的各受试者的平均血药浓度,对cmax、tmax以及tmaxgroup值进行如下调整:
[0043]
若平均血药浓度为0,则转换对应的cmax、tmax以及tmaxgroup值为缺失值第一字符“.”;
[0044]
s503:删除步骤s400中计算得到的各受试者的平均血药浓度,及步骤s105中创建的分组指示变量。
[0045]
优选地,步骤s400具体包括如下步骤:
[0046]
s401:计算各受试者平均血药浓度;
[0047]
s402:将计算得到的各受试者平均血药浓度,保存为第二内部数据集,所述第二数
据集包括受试者id和平均血药浓度;
[0048]
s403:将第二内部数据集合并到结果数据集,合并后,删除第二内部数据集。
[0049]
优选地,步骤s700具体包括如下步骤:
[0050]
s701:将对照组中受试者在各计划采血时间点的平均血药浓度转换为缺失值第一字符“.”;
[0051]
s702:按第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0052]
s703:按第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0053]
s704:按第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0054]
s705:将结果数据集按受试者id以及计划采血时间点进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0055]
本发明提供了一种使用上述药代动力学参数简化分析方法的药代动力学参数简化分析系统,包括:
[0056]
原始数据整理模块、cmax与tmax提取模块、各剂量组血药浓度均值提取模块、各受试者血药浓度均值提取模块;
[0057]
原始数据整理模块执行如下操作:
[0058]
导入原始数据集,提取原始数据集中的全部信息,保存为新的结果数据集;
[0059]
将结果数据集中的第四字符转换为缺失值第一字符“.”;
[0060]
创建采血时间点和剂量组的分组指示变量,并合并到结果数据集;
[0061]
cmax与tmax提取模块执行如下操作:
[0062]
根据各受试者的血药浓度计算出峰值血药浓度cmax的值;
[0063]
根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达到cmax时的计划采血时间点tmaxgroup;
[0064]
将各受试者的cmax、tmax和tmaxgroup添加到结果数据集;
[0065]
各剂量组血药浓度均值提取模块执行如下操作:
[0066]
根据分组指示变量,识别剂量组与计划采血时间点的组合,根据血药浓度数据计算各剂量组在所有计划采血点的平均血药浓度;
[0067]
将计算得到的各剂量组平均血药浓度保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;将所述第一内部数据集合并到结果数据集,并删除第一内部数据集;
[0068]
各受试者血药浓度均值提取模块执行如下操作:
[0069]
计算各受试者的平均血药浓度;
[0070]
将计算得到的各受试者的平均血药浓度保存为第二内部数据集,所述第二内部数据集包括受试者id和平均血药浓度,将所述第二内部数据集合并到结果数据集。
[0071]
优选地,还包括:
[0072]
分析结果预处理模块、转换逻辑设定模块、转换逻辑应用与结果整理模块;
[0073]
分析结果预处理模块执行如下操作:
[0074]
将各受试者血药浓度达到cmax之后为0的血药浓度值转换为缺失值第一字符“.”;
[0075]
根据计算得到的各受试者的平均血药浓度对cmax、tmax以及tmaxgroup值进行调整:
[0076]
若平均血药浓度为0,则将cmax、tmax以及tmaxgroup值转换为缺失值第一字符“.”;
[0077]
转换逻辑设定模块,
[0078]
设定第一转换逻辑,将缺失值第一字符“.”转换为第二字符,所述第二字符用于表示该数值无法测量;
[0079]
设定第二转换逻辑,将缺失值第一字符“.”转换为“na”;
[0080]
转换逻辑应用与结果整理模块,
[0081]
将对照组受试者的各剂量组平均血药浓度数值转换成缺失值第一字符“.”;
[0082]
应用第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0083]
应用第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0084]
应用第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0085]
按受试者id以及计划采血时间点对结果数据集进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0086]
优选地,还包括:
[0087]
由sas系统直接调用所述药代动力学参数简化分析系统,并在sas系统中进行结果分析和显示。
[0088]
与现有技术相对比,本发明的有益效果如下:
[0089]
1.本发明对原始数据集中的血药浓度低于测量方法的测量下限的值进行转化,方便处理,达到cmax之前的第四字符比如“bql”转化为0,达到cmax之后的“bql”值转化为“nd”,若受试者所有血药浓度数据均为“bql”则全部转化为“nd”。若受试者所有血药浓度数据为“nd”则生成的cmax与tmax也标记为“nd”,试验组各剂量组在各计划采血时间点的平均血药浓度会将全部“bql”值转换为0后进行计算,对照组各剂量组在各计划采血时间点的平均血药浓度,以“na”进行标注,本发明中的bql值转换符合一般药代动力学分析的标准。
[0090]
2.本发明对于第四字符和第二字符的形式,以及结果数据集的名称可以由使用者自定义,更方便。
[0091]
3.本发明方法的程序可以直接由sas系统调用,生成的结果数据集可以直接在sas系统进行分析和处理,不再需要进行格式转换,是分析人员操作更便捷、快速。
[0092]
4.本发明对于仅需要分析cmax、tmax和各剂量组在各采血点的平均血药浓度的情况,可以直接快速得到结果,操作少,不需要数据格式转换,更便捷,无需winnonlin软件分析中涉及的数据集格式转换、治疗组识别、“bql”逻辑建立、分析流程建立、结果与原数据集的合并、“na”值与“nd”值的生成,以及数据导回到sas等一系列操作。
[0093]
5.本发明无需winnonlin软件,即可分析cmax、tmax和各剂量组在各采血点的平均
血药浓度,省去了售价昂贵的winnonlin软件,对于只拥有sas而没有购入winnonlin的研究者来说,本发明是一个非常好的帮手。
附图说明
[0094]
图1是本发明的药代动力学参数简化分析方法一个实施例的流程图;
[0095]
图2是本发明的药代动力学参数简化分析系统一个实施例的示例框图;
[0096]
图3是本发明实施例3中对原始数据集通过本发明方法分析的结果;
[0097]
图4是本发明实施例3中对原始数据集phoenix winnonlin试验组中各个剂量组在各采血时间点的血药浓度平均值分析结果;
[0098]
图5是本发明实施例3中对原始数据集参考phoenix winnonlin受试者cmax与tmax分析结果。
具体实施方式
[0099]
下面结合附图1-5,对本发明的具体实施方式作详细的说明。
[0100]
本发明提供了一种药代动力学参数简化分析方法,包括以下步骤:
[0101]
s100:导入原始数据集,创建结果数据集,并对程序所需调用的变量值中的字符进行第一数据格式转换,转换为数字格式;
[0102]
s200:计算各受试者峰值血药浓度cmax、血药浓度达到峰值cmax时的实际采血时间点tmax和血药浓度达到峰值cmax时的计划采血时间点tmaxgroup;
[0103]
s300:计算各剂量组在所有计划采血时间点的平均血药浓度;
[0104]
s400:计算各受试者平均血药浓度;
[0105]
s500:第二数据格式转换步骤,根据步骤s200中计算的cmax及步骤,将各受试者血药浓度达到cmax之后数据为0的血药浓度值进行格式转换,并对平均血药浓度为0的受试者,对应的cmax、tmax以及tmaxgroup值进行格式转换;
[0106]
s600:设定转换逻辑步骤,具体包括以下步骤:
[0107]
s601:设定第一转换逻辑,将所述缺失值第一字符“.”转换为自定义的第二字符,所述第二字符用于表示该数值无法测量;
[0108]
s602:设定第二转换逻辑,将所述缺失值第一字符“.”转换为第三字符“na”;
[0109]
s700:第三格式转换及排序步骤,
[0110]
自动将对照组及所有受试者数据中的所述缺失值第一字符“.”按照设定的第一转换逻辑和第二转换逻辑进行格式转换;
[0111]
按受试者id以及计划采血时间点对结果数据集进行排序;
[0112]
s800:在sas系统执行步骤s100-步骤s700,并在步骤s700执行之后,将结果数据集在sas系统进行分析及显示。
[0113]
作为优选实施方式,步骤s100具体包括如下步骤:
[0114]
s101:导入原始数据集,提取原始数据集中的全部信息创建结果数据集;
[0115]
步骤s101所创建的结果数据集相当于原始数据集的拷贝,后续所有的运算都将针对结果数据集,而且计算结果也会合并到结果数据集,原始数据集在整个操作后不会受到任何影响(除非将结果数据集的名称与原始数据集设定为一样的时候,原始数据集会被结
果数据集覆盖)。在结果数据集中,每一列为一个变量,每一行为各个变量的观测值。一个数据集记录了很多变量的信息,比如受试者id,血药浓度,身高体重性别等等,本发明的目的就是把计算得到的新变量的信息也加入到结果数据集,让使用者可以从一个数据集得到全部原来数据信息和新变量的(如cmax、tmax等)信息。
[0116]
s102:在结果数据集中提取运算所需的变量并重新命名;
[0117]
此处对运算所需的变量进行重命名,是因为,使用本发明对不同数据集进行运算时,需要根据数据集内的变量的信息进行计算,比如受试者id、血药浓度、剂量组、实际采血时间点、计划采血时间点、治疗组等,但是不同数据集中这些变量的名字很可能不一样。比如血药浓度这个变量,有些数据集中它可能叫concentration,有些数据集中可能叫conc,所以,在使用本发明的方法的时候,会要求使用者填写各个变量在原始数据集中的名字,然后程序会识别出这次运算它所需要的每个变量都叫什么,比如conc代表血药浓度,然后在内部进行运算的时候重命名为concentration,具体实施方法和解释如实施例2中所述,所有运算需要用到的变量都会被识别,然后在程序运算过程中会被统一重命名,如data、id、concentration、dose、time、timegroup、treatmentgroup等,名字的不同对最终生成的结果没有任何影响。
[0118]
s103:将从结果数据集中提取的变量中第四字符转换为缺失值第一字符“.”,所述第四字符为原始数据集中自定义字符,用于代表该血药浓度数据低于测量方法的定量下限,无法测量;
[0119]
s104:将结果数据集中所有缺失值第一字符“.”转换为“0”;
[0120]
s105:创建分组指示变量,用于指示结果数据集中每一行数据所属采血时间点和剂量组,并将步骤s102重命名的变量以及创建的分组指示变量添加到结果数据集。
[0121]
剂量组是受试者被给药的剂量,比如一组受试者接受1mg的药物,另一组接受2mg的药物。治疗组代表受试者所在的组是对照组还是试验组。
[0122]
一般地,临床试验设计是这样:先分出各个剂量组,然后每个剂量组都有对照组和试验组,对照组的人不会被给予真正的药物,只有试验组的人会被真正给药,所以按理来说对照组的受试者,在整个研究中,他的血药浓度都应该为0(没有药物)。
[0123]
分组指示变量是一个新的变量,用于指示结果数据集中每一行数据所属采血时间点和剂量组,相当于把剂量组和采血时间点这两个变量合为了一个变量,方便后续运算,但在后面使用完后会被程序自行删除掉,所以在最终生成的结果数据集中并不会显示这个变量。作为优选实施方式,步骤s200具体包括如下步骤:
[0124]
s201:计算各受试者峰值血药浓度cmax;
[0125]
s202:根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达到cmax时的计划采血时间点tmaxgroup;
[0126]
s203:将各受试者的cmax、tmax和tmaxgroup添加到结果数据集。
[0127]
将cmax、tmax和tmaxgroup添加到结果数据集,就相当于在结果数据集中新增加三个变量,分别为cmax、tmax和tmaxgroup。在一开始这三个变量的数值均为“.”,然后针对受试者id,去比较受试者的每一个血药浓度数据,如果一个血药浓度大于前一个血药浓度数据,则cmax等于较大的那个血药浓度,一直比较到最后一个血药浓度数据来找出最大的血药浓度,然后cmax所在的实际采血时间点和计划采血时间点则分别为tmax与tmaxgroup。
[0128]
作为优选实施方式,步骤s300具体包括如下步骤:
[0129]
s301:根据步骤s105创建的分组指示变量来识别剂量组与计划采血时间点的组合;
[0130]
s302:根据结果数据集中各剂量组中的血药浓度数据,计算各剂量组在所有计划采血时间点的平均血药浓度;
[0131]
s303:将计算得到的各剂量组在所有计划采血点的平均血药浓度,保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;
[0132]
s304:将所述第一内部数据集合并到结果数据集,合并后,删除所述第一内部数据集。
[0133]
第一内部数据集以指示变量来索引,第一内部数据集可以只包含临床试验每个剂量组在每个采血时间点的平均血药浓度信息的数据集,指示变量说明了每个平均血药浓度数据是针对哪一个剂量组和哪一个时间点(例如1_2代表剂量组1,计划采血时间点2h)。第一内部数据集和结果数据集也会以指示变量来进行合并。
[0134]
作为优选实施方式,步骤s500具体包括如下步骤:具体包括以下步骤:
[0135]
s501:将各受试者血药浓度达到cmax之后,为0的血药浓度值转换为缺失值第一字符“.”;
[0136]
s502:根据步骤s400中计算的各受试者的平均血药浓度,对cmax、tmax以及tmaxgroup值进行如下调整:
[0137]
若平均血药浓度为0,则转换对应的cmax、tmax以及tmaxgroup值为缺失值第一字符“.”;
[0138]
s503:删除步骤s400中计算得到的各受试者的平均血药浓度,及步骤s105中创建的分组指示变量。
[0139]
作为优选实施方式,步骤s400具体包括如下步骤:
[0140]
s401:计算各受试者平均血药浓度;
[0141]
s402:将计算得到的各受试者平均血药浓度,保存为第二内部数据集,所述第二数据集包括受试者id和平均血药浓度;
[0142]
s403:将第二内部数据集合并到结果数据集,合并后,删除第二内部数据集。
[0143]
结果数据集就是原始数据集的所有变量加上新生成的变量,第二内部数据集可以只包含受试者id和受试者平均血药浓度这两个变量,以受试者id为索引与结果数据集合并,合并后,相当于结果数据集又增加了受试者平均血药浓度的这一个变量,受试者平均血药浓度只为识别受试者血药浓度是否一直为0,方便后续运算,没有实际临床意义,所以在使用完后也会被自动删除,在最终的结果数据集中将不显示这个变量。
[0144]
作为优选实施方式,步骤s700具体包括如下步骤:
[0145]
s701:将对照组中受试者在各计划采血时间点的平均血药浓度转换为缺失值第一字符“.”;
[0146]
s702:按第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0147]
s703:按第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度
中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0148]
s704:按第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0149]
s705:将结果数据集按受试者id以及计划采血时间点进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0150]
缺失值第一字符“.”是sas中对于缺失数据统一的表达方法,只要是缺失数据,sas系统就默认把它显示成“.”。“na”代表“not available”,也就是“不适用”,一般类似的缺失数值都以“na”来表示。第二字符可以自定义为“nd”,表示“not determined”,相当于“无法定量”。“na”和“nd”的最大区别就是,“na”代表没有这个数据,或者不需要计算或测量这个数据,“nd”代表测了这个数据,但是没测出来具体数值。
[0151]
比如,如果生成的变量conc_mean(受试者所在剂量组在某一个采血时间点的平均血药浓度)中若有一个数据显示为“na”,则代表该值为某一位对照组受试者所在剂量组在某一个采血时间点的平均血药浓度,没有参考意义,不需要计算,所以显示为“na”。但是血药浓度变量中的“nd”则代表测了这个血药浓度,但是没测出来具体数值。
[0152]
第四字符可以自定义为“bql”,代表“below quantitation limit”也就是“低于定量下限”,也就是说比如这个血药浓度低于检测仪器最小能探测到的浓度(有很多人也会叫它“blq”),所以本发明中对于低于定量下限的值,可以自定义显示形式。
[0153]
对于一个标注为第四字符(比如“bql”)的值,我们不知道它到底代表血中没有药(血药浓度为0)还是血药浓度实在太低无法定量(可以定义为“nd”)。在血药浓度达到峰值cmax之前的“bql”值很可能是因为血中没有药物造成的(比如给药前测的血药浓度)所以把它转换成0,但是血药浓度达到峰值cmax后的“bql”值,就代表血药浓度太低(因为血药浓度达到峰值后,血药浓度逐渐降低),所以用无法定量(可以定义为“nd”)来显示(此处设定了让使用者自定义“nd”的形式)。若受试者所有时间点的血药浓度数据均为“bql”的话则全部转换为“nd”。
[0154]
本发明提供了一种使用上述药代动力学参数简化分析方法的药代动力学参数简化分析系统,包括:
[0155]
原始数据整理模块、cmax与tmax提取模块、各剂量组血药浓度均值提取模块、各受试者血药浓度均值提取模块;
[0156]
原始数据整理模块执行如下操作:
[0157]
导入原始数据集,提取原始数据集中的全部信息,保存为新的结果数据集;
[0158]
将结果数据集中的第四字符转换为缺失值第一字符“.”;
[0159]
创建采血时间点和剂量组的分组指示变量,并合并到结果数据集;
[0160]
cmax与tmax提取模块执行如下操作:
[0161]
根据各受试者的血药浓度计算出峰值血药浓度cmax的值;
[0162]
根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达到cmax时的计划采血时间点tmaxgroup;
[0163]
将各受试者的cmax、tmax和tmaxgroup添加到结果数据集;
[0164]
各剂量组血药浓度均值提取模块执行如下操作:
[0165]
根据分组指示变量,识别剂量组与计划采血时间点的组合,根据血药浓度数据计
算各剂量组在所有计划采血点的平均血药浓度;
[0166]
将计算得到的各剂量组平均血药浓度保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;将所述第一内部数据集合并到结果数据集,并删除第一内部数据集;
[0167]
各受试者血药浓度均值提取模块执行如下操作:
[0168]
计算各受试者的平均血药浓度;
[0169]
将计算得到的各受试者的平均血药浓度保存为第二内部数据集,所述第二内部数据集包括受试者id和平均血药浓度,将所述第二内部数据集合并到结果数据集。
[0170]
作为优选实施方式,该药代动力学参数简化分析系统,还包括:
[0171]
分析结果预处理模块、转换逻辑设定模块、转换逻辑应用与结果整理模块;
[0172]
分析结果预处理模块执行如下操作:
[0173]
将各受试者血药浓度达到cmax之后为0的血药浓度值转换为缺失值第一字符“.”;
[0174]
根据计算得到的各受试者的平均血药浓度对cmax、tmax以及tmaxgroup值进行调整:
[0175]
若平均血药浓度为0,则将cmax、tmax以及tmaxgroup值转换为缺失值第一字符“.”;
[0176]
转换逻辑设定模块,
[0177]
设定第一转换逻辑,将缺失值第一字符“.”转换为第二字符,所述第二字符用于表示该数值无法测量;
[0178]
设定第二转换逻辑,将缺失值第一字符“.”转换为“na”;
[0179]
转换逻辑应用与结果整理模块,
[0180]
将对照组受试者的各剂量组平均血药浓度数值转换成缺失值第一字符“.”;
[0181]
应用第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0182]
应用第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0183]
应用第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0184]
按受试者id以及计划采血时间点对结果数据集进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0185]
作为优选实施方式,该药代动力学参数简化分析系统,还包括:
[0186]
由sas系统直接调用所述药代动力学参数简化分析系统,并在sas系统中进行结果分析和显示。
[0187]
实施例1
[0188]
参照附图1-5,根据本发明的一个具体实施方案,对本发明提供的药代动力学参数简化分析方法进行详细说明。
[0189]
本发明提供了一种药代动力学参数简化分析方法,包括以下步骤:
[0190]
s100:导入原始数据集,创建结果数据集,并对程序所需调用的变量值中的字符进
行第一数据格式转换,转换为数字格式;
[0191]
步骤s100具体包括如下步骤:
[0192]
s101:导入原始数据集,提取原始数据集中的全部信息创建结果数据集;
[0193]
s102:在结果数据集中提取运算所需的变量并重新命名;
[0194]
s103:将从结果数据集中提取的变量中第四字符转换为缺失值第一字符“.”,所述第四字符为原始数据集中自定义字符,用于代表该血药浓度数据低于测量方法的定量下限,无法测量;
[0195]
s104:将结果数据集中所有缺失值第一字符“.”转换为“0”;
[0196]
s105:创建分组指示变量,用于指示结果数据集中每一行数据所属采血时间点和剂量组,并将步骤s102重命名的变量以及创建的分组指示变量添加到结果数据集。
[0197]
s200:计算各受试者峰值血药浓度cmax、血药浓度达到峰值cmax时的实际采血时间点tmax和血药浓度达到峰值cmax时的计划采血时间点tmaxgroup;
[0198]
步骤s200具体包括如下步骤:
[0199]
s201:计算各受试者峰值血药浓度cmax;
[0200]
s202:根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达到cmax时的计划采血时间点tmaxgroup;
[0201]
s203:将各受试者的cmax、tmax和tmaxgroup添加到结果数据集。
[0202]
s300:计算各剂量组在所有计划采血时间点的平均血药浓度;
[0203]
步骤s300具体包括如下步骤:
[0204]
s301:根据步骤s105创建的分组指示变量来识别剂量组与计划采血时间点的组合;
[0205]
s302:根据结果数据集中各剂量组中的血药浓度数据,计算各剂量组在所有计划采血时间点的平均血药浓度;
[0206]
s303:将计算得到的各剂量组在所有计划采血点的平均血药浓度,保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;
[0207]
s304:将所述第一内部数据集合并到结果数据集,合并后,删除所述第一内部数据集。
[0208]
s400:计算各受试者平均血药浓度;
[0209]
步骤s400具体包括如下步骤:
[0210]
s401:计算各受试者平均血药浓度;
[0211]
s402:将计算得到的各受试者平均血药浓度,保存为第二内部数据集,所述第二数据集包括受试者id和平均血药浓度;
[0212]
s403:将第二内部数据集合并到结果数据集,合并后,删除第二内部数据集。
[0213]
s500:第二数据格式转换步骤,根据步骤s200中计算的cmax及步骤,将各受试者血药浓度达到cmax之后数据为0的血药浓度值进行格式转换,并对平均血药浓度为0的受试者,对应的cmax、tmax以及tmaxgroup值进行格式转换;
[0214]
步骤s500具体包括如下步骤:具体包括以下步骤:
[0215]
s501:将各受试者血药浓度达到cmax之后,为0的血药浓度值转换为缺失值第一字
符“.”;
[0216]
s502:根据步骤s400中计算的各受试者的平均血药浓度,对cmax、tmax以及tmaxgroup值进行如下调整:
[0217]
若平均血药浓度为0,则转换对应的cmax、tmax以及tmaxgroup值为缺失值第一字符“.”;
[0218]
s503:删除步骤s400中计算得到的各受试者的平均血药浓度,及步骤s105中创建的分组指示变量。
[0219]
s600:设定转换逻辑步骤,具体包括以下步骤:
[0220]
s601:设定第一转换逻辑,将所述缺失值第一字符“.”转换为自定义的第二字符,所述第二字符用于表示该数值无法测量;
[0221]
s602:设定第二转换逻辑,将所述缺失值第一字符“.”转换为第三字符“na”;
[0222]
s700:第三格式转换及排序步骤,
[0223]
自动将对照组及所有受试者数据中的所述缺失值第一字符“.”按照设定的第一转换逻辑和第二转换逻辑进行格式转换;
[0224]
按受试者id以及计划采血时间点对结果数据集进行排序;
[0225]
步骤s700具体包括如下步骤:
[0226]
s701:将对照组中受试者在各计划采血时间点的平均血药浓度转换为缺失值第一字符“.”;
[0227]
s702:按第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0228]
s703:按第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0229]
s704:按第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0230]
s705:将结果数据集按受试者id以及计划采血时间点进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0231]
s800:在sas系统执行步骤s100-步骤s700,并在步骤s700执行之后,将结果数据集在sas系统进行分析及显示。
[0232]
本发明提供了一种使用上述药代动力学参数简化分析方法的药代动力学参数简化分析系统,包括:
[0233]
原始数据整理模块、cmax与tmax提取模块、各剂量组血药浓度均值提取模块、各受试者血药浓度均值提取模块;
[0234]
原始数据整理模块执行如下操作:
[0235]
导入原始数据集,提取原始数据集中的全部信息,保存为新的结果数据集;
[0236]
将结果数据集中的第四字符转换为缺失值第一字符“.”;
[0237]
创建采血时间点和剂量组的分组指示变量,并合并到结果数据集;
[0238]
cmax与tmax提取模块执行如下操作:
[0239]
根据各受试者的血药浓度计算出峰值血药浓度cmax的值;
[0240]
根据计算得到的各受试者的cmax,得到达到cmax时的实际采血时间点tmax,和达
到cmax时的计划采血时间点tmaxgroup;
[0241]
将各受试者的cmax、tmax和tmaxgroup添加到结果数据集;
[0242]
各剂量组血药浓度均值提取模块执行如下操作:
[0243]
根据分组指示变量,识别剂量组与计划采血时间点的组合,根据血药浓度数据计算各剂量组在所有计划采血点的平均血药浓度;
[0244]
将计算得到的各剂量组平均血药浓度保存为第一内部数据集,所述第一内部数据集包括分组指示变量以及剂量组血药浓度均值,所述剂量组血药浓度均值为各剂量组在所有计划采血时间点的血药浓度均值;将所述第一内部数据集合并到结果数据集,并删除第一内部数据集;
[0245]
各受试者血药浓度均值提取模块执行如下操作:
[0246]
计算各受试者的平均血药浓度;
[0247]
将计算得到的各受试者的平均血药浓度保存为第二内部数据集,所述第二内部数据集包括受试者id和平均血药浓度,将所述第二内部数据集合并到结果数据集。
[0248]
该药代动力学参数简化分析系统还包括:
[0249]
分析结果预处理模块、转换逻辑设定模块、转换逻辑应用与结果整理模块;
[0250]
分析结果预处理模块执行如下操作:
[0251]
将各受试者血药浓度达到cmax之后为0的血药浓度值转换为缺失值第一字符“.”;
[0252]
根据计算得到的各受试者的平均血药浓度对cmax、tmax以及tmaxgroup值进行调整:
[0253]
若平均血药浓度为0,则将cmax、tmax以及tmaxgroup值转换为缺失值第一字符“.”;
[0254]
转换逻辑设定模块,
[0255]
设定第一转换逻辑,将缺失值第一字符“.”转换为第二字符,所述第二字符用于表示该数值无法测量;
[0256]
设定第二转换逻辑,将缺失值第一字符“.”转换为“na”;
[0257]
转换逻辑应用与结果整理模块,
[0258]
将对照组受试者的各剂量组平均血药浓度数值转换成缺失值第一字符“.”;
[0259]
应用第一转换逻辑,将对照组中受试者在各计划采血时间点的cmax、tmax以及tmaxgroup值中,标注为缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0260]
应用第二转换逻辑,将对照组中受试者在各计划采血时间点的平均血药浓度中,标注为缺失值第一字符“.”的数据转换为所述第三字符“na”进行显示;
[0261]
应用第一转换逻辑,将将各受试者血药浓度达到cmax之后,血药浓度值中的缺失值第一字符“.”的数据转换为所述第二字符进行显示;
[0262]
按受试者id以及计划采血时间点对结果数据集进行排序,并保存为新的数据集或直接覆盖原始数据集。
[0263]
还包括:由sas系统直接调用所述药代动力学参数简化分析系统,并在sas系统中进行结果分析和显示。
[0264]
实施例2
[0265]
根据本发明的一个具体实施方案,本发明的方法实现程序运行过程中,定义变量
的具体示例包括:
[0266]
1.data:是所要使用程序进行分析的数据集文件名,使用者在data=后面填写需要被程序进行分析的数据集名称后,程序会根据所填写的名称自动调用血药浓度数据集。
[0267]
2.bql:是“bql”值在原数据集中被标注的形式,一般血药浓度数据集中的“bql”值会被直接标注为“bql”,若使用者想进行分析的数据集中“bql”被标注为了其他形式,使用者可以将其他形式填写到此处让程序进行识别,注意“bql”被标注的形式要像上面的参考代码中显式的一样使用单引号或双引号括住。
[0268]
3.nd:是达到cmax之后的“bql”需要被转化成的形式,一般对于血药浓度达到cmax值之后的“bql”值需要被标注为“nd”,代表无法测量,使用者也可自定义将“bql”值标注为“nd”以外的其他形式,注意“nd”的形式要像上面的参考代码中显式的一样使用单引号或双引号括住。
[0269]
4.id:是受试者的编号,使用者在id=后面填写数据集中代表受试者编号的变量的名称来让程序识别每一位受试者。
[0270]
5.concentration:是受试者的血药浓度,使用者在concentration=后面填写数据集中代表受试者血药浓度的变量的名称来让程序识别受试者的血药浓度数据。
[0271]
6.dose:是受试者所在剂量组,使用者在dose=后面填写数据集中代表受试者剂量组的变量的名称来让程序识别每一位受试者所在的剂量组。
[0272]
7.time:是实际采血时间点,使用者在time=后面填写数据集中代表受试者血药浓度的实际采血时间点的变量的名称来让程序识别实际采血时间点,此时间点为血药浓度分析时间与开始给药时间的差值。
[0273]
8.timegroup:是计划采血时间点,使用者在timegroup=后面填写数据集中代表受试者血药浓度的计划采血时间点的变量的名称来让程序识别计划采血时间点,此时间点为试验设计时所计划的采血时间点。
[0274]
9.treatmentgroup:是受试者所在治疗组的指示变量(0代表对照组,1代表试验组),使用者在treatmentgroup=后面填写数据集中代表受试者所在治疗组的指示变量的名称来让程序识别每个受试者是属于试验组还是对照组。
[0275]
10.outputname:是运算后生成数据集的名字,使用者在outputname后填写程序运算后新生成的数据集的名字,若与原数据集名字相同则可直接覆盖原数据集。
[0276]
结果数据集中的新变量含义:
[0277]
1.cmax:是受试者峰值血药浓度,若数据集中受试者每一个采血时间点的血药浓度均被转换为使用者所定义的“nd”的形式时,该名受试者的cmax值也会被标注为使用者所定义的“nd”的形式。
[0278]
2.tmax:是受试者血药浓度达到cmax时的实际采血时间点,若数据集中受试者每一个采血时间点的血药浓度均被转换为使用者所定义的“nd”的形式时,该名受试者的tmax值也会被标注为使用者所定义的“nd”的形式。
[0279]
3.tmaxgroup:是受试者血药浓度达到cmax时的计划采血时间点,若数据集中受试者每一个采血时间点的血药浓度均被转换为使用者所定义的“nd”的形式时,该名受试者的tmaxgroup值也会被标注为使用者所定义的“nd”的形式。
[0280]
4.conc_mean:是受试者所在剂量组在各计划采血时间点的平均血药浓度,试验组
各剂量组在各计划采血时间点的平均血药浓度会将全部“bql”值转换为0后进行计算。若某受试者在某一计划采血时间点的conc_mean结果被标注“na”为则代表此受试者来自对照组,该受试者所在剂量组在各计划采血时间点的平均血药浓度没有参考意义。
[0281]
实施例3
[0282]
根据本发明的一个具体实施方案,以表1中的数据为例,给出采用本发明方法处理前及数据模拟了单次给药的药物临床试验受试者在各采血时间点的血药浓度信息。数据中subj_id代表受试者编号,conc代表血药浓度,real_time代表实际采血时间点,time代表计划采血时间点,dose_group代表受试者剂量组,treatment_group代表受试者所在治疗组,其中1代表试验组,0代表对照组。
[0283]
表1原始数据集
[0284]
[0285]
[0286]
[0287][0288]
以下是本发明方法在sas系统调用的代码示例,本发明方法的实施程序命名为“pkbql macro程序”:
[0289]
[0290][0291]
通过本发明方法pkbql macro程序分析的结果,参见附图3,从结果可以看出pkbql macro程序分析出的参数很好的与原数据集进行了合并,并且没有对原数据集的数据存储格式或其他变量产生任何的影响或改变。试验组101号受试者与102号受试者血药浓度达峰前的“bql”值均被转换为了0,对照组103号受试者因为每个采血时间点的血药浓度均为“bql”因此他的所有“bql”值均被转换成了“nd”,同时因为他处于对照组,所以该受试者所在剂量组在各计划采血时间点的平均血药浓度没有参考意义,进而被标注为“na”。
[0292]
参考phoenix winnonlin试验组中各个剂量组在各采血时间点的血药浓度平均值分析结果,参见附图4。从结果可以看出phoenix winnonlin对于试验组中各个剂量组在各采血时间点的血药浓度平均值的分析结果与pkbql macro一致,例如试验组中剂量组1在计划时间点1的平均血药浓度均为49.668,试验组中剂量组1在计划时间点2的平均血药浓度均为40.668。但原先数据集中的其他变量却不能简单的在winnonlin的运算结果中保留,也不能体现出对照组各个剂量组在各采血时间点的血药浓度平均值的“na”值,需要对结果数据集进行额外操作。
[0293]
参考phoenix winnonlin受试者cmax与tmax分析结果,参见附图5。从结果可以看出phoenix winnonlin对于受试者cmax与tmax的分析结果与pkbql macro一致,例如受试者101的cmax均为50.123,tmax均为0.9998,受试者102的cmax均为49.213,tmax均为1,但是winnonlin结果中cmax与tmax的“nd”值无法直接体现出来,需要对结果数据集进行额外操作。
[0294]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1