重组胶原的局部制剂的制作方法
重组胶原的局部制剂
交叉引用
1.本申请要求于2019年4月1日提交的美国临时专利申请号62/827,662的权益,该申请通过引用整体并入本文。
背景技术:
2.胶原和类似的蛋白质是生物圈中最丰富的蛋白质。胶原和结构化蛋白质可见于动物的皮肤、结缔组织和骨骼以及其他组织中。体内存在的胶原量是总蛋白质的大约三分之一,并且占皮肤干重的约四分之三。
3.天然胶原的结构可以是三股螺旋,其中三个多肽链一起形成螺旋卷曲。单个多肽链由被指定为gly-x-y的重复三联体氨基酸序列组成。x和y可以是任何氨基酸,并且第一个氨基酸是甘氨酸。胶原中氨基酸脯氨酸和羟脯氨酸的浓度较高。最常见的三联体是甘氨酸-脯氨酸-羟脯氨酸(gly-pro-hyp),占胶原中三联体的大约10.5%。
4.明胶是通过某种(例如天然)胶原部分水解而获得的产物。通常,明胶是通过酸水解、碱水解和酶水解,或是通过在水溶液中使胶原暴露于热(例如,煮沸动物的骨骼和皮肤、煮沸鱼鳞等)而产生的。
5.明胶在多种产品中使用,包括化妆品、食品、药品、医疗设备、胶卷、粘合剂、粘结剂,等等。明胶的物理和化学性质可以根据具体应用而调节。这些物理/化学性质包括凝胶强度、熔点温度、粘度、颜色、浊度、ph、等电点,等等。
技术实现要素:
6.在某些实施方案中,这里是各种多肽、包含此类多肽的组合物和使用此类多肽和/或其组合物的方法。在某些实施方案中,此类多肽包括非天然和/或重组多肽,例如包含相对于天然胶原,例如本文所述的天然胶原而言被截短的一个或多个氨基酸序列。在某些情况下,此类多肽在本文中被描述为“截短胶原”。在特定实施方案中,所述多肽包括天然人类胶原的一个或多个(例如,两个或更多个)截短氨基酸序列。在特定实施方案中,所述多肽包括天然海蜇胶原的一个或多个(例如,两个或更多个)截短氨基酸序列。在一个方面,提供了一种向皮肤(例如,个体如人类的皮肤)提供益处(例如,增加皮肤的紧致度、弹性、亮度、水合度、触觉质感或视觉质感)的方法。在一些实施方案中,所述方法包括向所述皮肤局部应用本文所述的多肽(例如,非天然存在的截短胶原,例如本文所述的)或制剂(例如,包含多肽,例如非天然存在的截短胶原)。
7.在特定的方面,提供了一种减少皮肤上存在的褶皱或皱纹或者减少皮肤的红疹的方法。在一些实施方案中,所述方法包括向所述皮肤局部应用本文所述的多肽(例如,非天然存在的截短胶原,例如本文所述的)或其制剂。在一些实施方案中,本文还提供了制剂,其包含本文所述的多肽,例如非天然存在的截短胶原。
8.在某些情况下,本文所述的多肽(例如,截短胶原)可用于增加皮肤的紧致度、弹性、亮度、水合度、触觉质感和/或视觉质感。在一些情况下,本文所述的多肽(例如,截短胶
原)可用于减少皮肤上存在的褶皱或皱纹或者减少皮肤的红疹。在特定实施方案中,所述多肽(例如,截短胶原)是或包括截短海蜇胶原(例如,天然存在的海蜇胶原的截短氨基酸序列)。在其他特定实施方案中,所述多肽(例如,截短胶原)是或包括截短人类胶原(例如,天然存在的人类胶原的截短氨基酸序列)。
9.在一些实施方案中,(例如,可用于本文公开的方法的)所述多肽(例如,截短胶原)是或包括相对于天然(例如,人类或海蜇(水螅虫))胶原而言的截短氨基酸序列。在一些情况下,此类多肽在本文中被称为非天然存在的胶原。在特定实施方案中,所述非天然存在的胶原是或包含seq id no:2、seq id no:4、seq id no:5、seq id no:7、seq id no:10、seq id no:12、seq id no:14、seq id no:16、seq id no:18、seq id no:20、seq id no:22、seq id no:24、seq id no:25、seq id no:27和/或seq id no:29,或其同系物(例如,与其具有至少85%、至少90%、至少95%或至少98%的序列同一性)的氨基酸序列。在更加特定的实施方案中,所述非天然存在的胶原是seq id no:2、seq id no:4、seq id no:5、seq id no:7、seq id no:10、seq id no:12、seq id no:14、seq id no:16、seq id no:18、seq id no:20、seq id no:22、seq id no:24、seq id no:25、seq id no:27或seq id no:29,或其同系物(例如,与其具有至少85%、至少90%、至少95%或至少98%的序列同一性)的氨基酸序列。
10.在某些实施方案中,本文提供了组合物。在一些实施方案中,此类组合物包含本文所述的多肽(例如,截短或非天然的胶原)。在一个方面,提供了组合物,其包含任何合适量,例如0.005%至30%w/w的本文提供的任何多肽(例如,截短或非天然存在的胶原)。所述组合物还可以包含至少一种另外的成分,该至少一种另外的成分包括赋形剂、局部载体或防腐剂。
11.在某些实施方案中,本文提供的组合物是局部组合物,例如被配制和/或适合用于局部施用或使用的组合物。在一个方面,本文提供了一种例如向个体的皮肤提供(例如,如本文所述的)益处的方法,所述方法包括向皮肤局部施用所述局部组合物。在特定实施方案中,所述局部组合物被用在用于减少皮肤损伤、促进受损皮肤修复或刺激皮肤细胞产生胶原的方法中。在某些实施方案中,所述局部组合物被用在用于增加、促进、刺激或其他方式增加皮肤中的弹性蛋白产生的方法中。
12.一个方面提供了向受试者的皮肤应用所述胶原或包含胶原的组合物的方法。
13.在一些实施方案中,如本文所讨论的,本文提供的多肽是或包括相对于天然(例如,人类或海蜇(水螅虫))胶原而言的截短氨基酸序列。在特定实施方案中,此类多肽是截短胶原(例如,包含相对于天然胶原而言的一个或多个截短氨基酸序列)。在一些实施方案中,所述截短胶原是海蜇胶原或人类胶原。在多个实施方案中,所述胶原(例如,相对于天然胶原)在c末端、n末端、内部或在c末端和n末端两者处被截短。在一个实施方案中,所述胶原(例如,相对于天然胶原)在c末端和n末端两者处被截短。在某些实施方案中,本文提供的多肽是或包括具有任何合适的截短的截短胶原,所述合适的截短例如包括c末端截短、n末端截短和/或一个或多个内部截短。在一些实施方案中,所述胶原的截短适合于实现有益结果(例如,相对于天然胶原而言改善的结果和/或相对于天然胶原而言有另外的益处)并且/或者缩短所述胶原的长度,同时保留胶原的一个或多个有益方面。在一些实施方案中,本文提供的多肽是或包括以例如保留胶原的一个或多个局部益处的方式截短的胶原。
14.在一些实施方案中,(例如,本文提供的多肽的)截短胶原(其氨基酸序列)在c末端处被截短任何适当数目的氨基酸残基,例如至多10、10至800、10至700、10至500、10至400、10至300、50至800、50至700、50至600、50至500、50至400个等。在某些实施方案中,(例如,本文提供的多肽的)截短胶原(其氨基酸序列)在n末端处被截短任何适当数目的氨基酸残基,例如至多10、10至900、10至800、10至700、10至500、10至400、10至300、50至800、50至700、50至600、50至500、50至400个等。在一些实施方案中,(例如,本文提供的多肽的)截短胶原(其氨基酸序列)在内部被截短任何适当数目的氨基酸残基,例如至多10、10至900、10至800、10至700、10至500、10至400、10至300、50至800、50至700、50至600、50至500、50至400个等。在特定实施方案中,(例如,本文提供的多肽的)截短胶原(其氨基酸序列)在c末端处被截短10至800个氨基酸并且/或者在n末端处被截短10至800个氨基酸。在另一实施方案中,(例如,本文提供的多肽的)截短胶原(其氨基酸序列)的长度为10至900个氨基酸、10至800个氨基酸、10至700个氨基酸、10至600个氨基酸、10至500个氨基酸、10至400个氨基酸、10至300个氨基酸、10至200个氨基酸、10至100个氨基酸、10至50个氨基酸、50至800个氨基酸、50至700个氨基酸、50至600个氨基酸、50至500个氨基酸、50至400个氨基酸、50至300个氨基酸、50至200个氨基酸,或50至100个氨基酸。
15.在某些实施方案中,本文提供了多肽,所述多肽是或包括人类(例如,人类21型)胶原的氨基酸序列。在特定实施方案中,所述截短人类胶原是截短的人类21型胶原。在多个实施方案中,截短是根据本文提供的任何公开内容。在特定实施方案中,所公开的截短的人类21型胶原是seq id no:16(或其同系物,例如与seq id no:16的氨基酸序列具有至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少98%序列同一性或本文提供的其他序列同一性)。在多个实施方案中,此类多肽被提供在本文提供的任何组合物、制剂或方法中。
16.在某些实施方案中,本文提供了多肽,所述多肽是或包括海蜇(水螅虫)胶原的氨基酸序列。在多个实施方案中,所述截短是根据本文提供的任何公开内容。在特定实施方案中,所公开的截短的海蜇胶原是seq id no:5(或其同系物,例如与seq id no:5的氨基酸序列具有至少80%序列同一性、至少85%序列同一性、至少90%序列同一性、至少95%序列同一性、至少98%序列同一性或本文提供的其他序列同一性)。在多个实施方案中,此类多肽被提供在本文提供的任何组合物、制剂或方法中。
17.在某些实施方案中,本文提供了一种方法,包括向个体的皮肤施用多肽(例如,是或包括本文所述的截短胶原),例如以便向所述个体或其皮肤提供益处。在一些情况下,向所述皮肤提供的益处是改善所述皮肤的紧致度,改善所述皮肤的弹性,改善所述皮肤的水合度,改善所述皮肤的质感,改善所述皮肤的亮度,减少所述皮肤的皱纹,减少所述皮肤的红疹,改善所述皮肤中的胶原产生,改善或增加所述皮肤中的弹性蛋白产生,对所述皮肤进行抗氧化保护,减少所述皮肤的发红或其他益处或例如本文所述的那些益处的组合。在多种情况下,由本文提供的方法所提供的皮肤特性改善或益处以任何合适的方式确定,例如通过使用仪器或通过由临床医生评价。在一个方面,提供了一种增加皮肤紧致度的方法,其中所述皮肤的紧致度增加至少5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、70%或75%。在一个实施方案中,使用皮肤弹性测试仪(cutometer)测量所述皮肤的紧致度。
18.另一个方面提供了一种增加皮肤弹性的方法,其中所述皮肤的弹性增加至少5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、70%或75%。在一个实施方案中,使用皮肤弹性测试仪测量所述皮肤的弹性。
19.在另一个方面,提供了一种增加皮肤水合度的方法,其中所述皮肤的水合度增加至少5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、70%或75%。在一个实施方案中,在皮肤水分测试仪(corneometer)上测量皮肤水合度。
20.在一个方面,提供了一种增加皮肤紧致度的方法,其中所述皮肤的紧致度得以增加。在一个实施方案中,由专业的临床评分员确定所述皮肤的紧致度。
21.在一个方面,提供了一种增加皮肤弹性的方法,其中所述皮肤的弹性得以增加。在一个实施方案中,由专业的临床评分员确定所述皮肤的弹性。
22.在一个方面,提供了一种增加皮肤亮度的方法,其中所述皮肤的亮度得以增加。在一个实施方案中,由专业的临床评分员确定所述皮肤的亮度。
23.在另一个方面,提供了一种增加皮肤触觉质感的方法,其中所述皮肤的触觉质感得以增加。在一个实施方案中,由专业的临床评分员确定所述皮肤的触觉质感。
24.在一个方面,提供了一种增加皮肤视觉质感的方法,其中所述皮肤的视觉得以质感增加。在一个实施方案中,由专业的临床评分员确定所述皮肤的视觉质感。
25.在一个方面,提供了一种减少皮肤上存在的褶皱或皱纹的方法,其中所述皮肤上存在的褶皱或皱纹得以减少。在一个实施方案中,由专业的临床评分员确定所述皮肤上存在的褶皱或皱纹的量。
26.在一个方面,提供了一种减少皮肤红疹的方法,其中所述皮肤的红疹得以减少。在一个实施方案中,由专业的临床评分员确定所述皮肤的红疹。
27.另一方面提供了刺激皮肤细胞中产生胶原的方法。在一个实施方案中,所述方法包括向所述皮肤应用非天然存在的截短胶原或包含非天然存在的截短胶原的制剂。在一个实施方案中,截短的海蜇胶原或截短的人类胶原刺激胶原产生。在特定实施方案中,所述截短的人类胶原是seq id no:16的截短的人类21型胶原。在另一特定实施方案中,所述截短的海蜇胶原是seq id no:5的截短海蜇胶原。
28.又一方面提供了一种刺激皮肤细胞中产生胶原的方法,其中皮肤中的胶原增加至少1%、至少2%、至少3%、至少4%、至少5%、至少6%、至少7%、至少8%、至少9%或至少10%。
29.公开了一种局部制剂,其包含截短胶原和一种或多种另外的成分,所述一种或多种另外的成分选自水、油、甘油聚醚-8酯(glycereth-8ester)、甘油、椰子烷烃、丙烯酸羟乙酯/丙烯酰二甲基牛磺酸钠共聚物、戊二醇、edta二钠、辛甘醇(caprylyl glycol)、氯苯甘醚和苯氧乙醇。在一个实施方案中,所述截短胶原是截短的海蜇胶原或截短的人类胶原。在另一个实施方案中,所述截短胶原是截短的人类21型胶原。本文公开的又一个实施方案是包含胶原并且还包含植物油的局部制剂。在一个实施方案中,所述植物油是橄榄油。
附图说明
30.本发明的新颖特征在所附权利要求中具体阐述。通过参考以下对其中利用到本发明原理的说明性实施方式加以阐述的详细描述和附图,将会获得对本发明的特征和优点的
更好理解,在这些附图中:
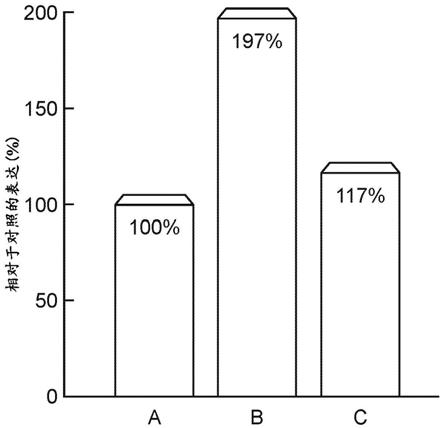
31.图1示出了本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)对成纤维细胞中的1型胶原蛋白分泌的影响。
32.图2a示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理的成纤维细胞中的1型胶原mrna的表达。
33.图2b示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理的成纤维细胞中的弹性蛋白mrna的表达。
34.图2c示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理的成纤维细胞中的纤连蛋白mrna的表达。
35.图3示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理的人类原代角质形成细胞中的il-1a的表达。
36.图4示出了本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)的抗氧化能力。
37.图5示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理的、经uvb照射的角质形成细胞的活力。
38.图6示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理后的皮肤弹性。
39.图7示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理后的皮肤胶原含量。
40.图8示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理后的皮肤发红的定量。
41.图9示出了经本文提供的示例性多肽(包含截短的人类胶原氨基酸序列)处理后的皮肤皱纹的定量。
42.图10示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理的人类皮肤组织模型的1型胶原蛋白分泌。
43.图11示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理的角质形成细胞中的uvb诱导的tt二聚体。
44.图12示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理的、uvb照射后的角质形成细胞的活力。
45.图13示出了经城市灰尘和本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理后的细胞活力。
46.图14示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理后,由uvb诱导的il-1a的相对表达。
47.图15示出了本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)的抗氧化能力。
48.图16示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理后的皮肤水合度。
49.图17示出了经本文提供的示例性多肽(包含截短的海蜇胶原氨基酸序列)处理后的皮肤弹性。
具体实施方式
50.在下面的描述中,阐述了某些具体细节以便提供对本公开的各种实施方案的透彻理解。然而,本领域技术人员将理解,可以在没有这些细节的情况下实践本公开。
51.如本文所用,术语“约”通常是指
±
10%。
52.术语“由...组成”是指“包括并限于”。通常,“包括”的公开包括“由...组成”的公开。
53.术语“基本上由...组成”是指所述组合物、方法或结构可以包括另外的成分、步骤和/或部分,但前提是所述另外的成分、步骤和/或部分不会实质性地改变所要求保护的组合物、方法或结构的基本和新颖特征。通常,“包括”的公开包括“基本上由...组成”的公开。
54.如本文所用,单数形式的“一个”、“一种”和“该”包括复数个指称物,除非上下文另外明确指出。例如,术语“一种化合物”或“至少一种化合物”可以包括多种化合物,包括其混合物。
55.在整个文档中,可以以范围格式来呈现本公开的各种实施方案。应当理解,范围格式的描述仅是为了方便和简洁,而不应被解释为对本公开范围的严格限制。因此,应该将范围的描述视为已具体公开了所有可能的子范围以及该范围内的各个数值。例如,对范围从1到6的描述应被视为已明确公开了诸如从1到3、从1到4、从1到5、从2到4、从2到6、从3到6等子范围,以及该范围内的各个数字,例如1、2、3、4、5和6。无论范围多宽,这都适用。
56.每当在本文中指示数值范围时,其意图包括在指示范围内的任何引用的数字(分数或整数)。词语“在”第一指示数字和第二指示数字“之间的范围”和词语“从”第一指示数字“到”第二指示数字的“范围”在本文中可互换使用,并且旨在包括第一指示数字和第二指示数字以及它们之间的所有分数和整数。
57.如本文所用,术语“胶原”或“胶原样”在一些情况下是指可以与一种或多种胶原或胶原样多肽缔合以形成四级结构的(例如,单体)多肽。胶原的非限制性示例包括人类21型α1胶原(例如,seq id no:31)、人类1型α2胶原(例如,seq id no:32)和海蜇(水螅虫)胶原(例如,seq id no:33)。在一些情况下,可用酸、碱或热处理胶原以制备明胶。天然胶原的四级结构是三螺旋,通常由三个多肽组成,但应注意,本文提供的“截短胶原”或包含“截短胶原”的多肽可能具有也可能不具有这种四级结构,因此不一定具有这样的四级结构。在一些情况下,形成天然胶原的三个多肽中,两个通常是相同的,并被称为α链。第三个多肽被称为β链。在某些情况下,典型的天然胶原可以被称为aab,其中胶原由两条α(“a”)链和一条β(“b”)链组成。在一些情况下,本文提供的包含“截短胶原”的多肽可以具有或可以不具有这样的结构元件。术语“胶原”或“胶原样”可以指α链多肽、β链多肽或α链多肽和β链多肽两者。如本文所用,术语“前胶原”通常是指由细胞产生的多肽,其可以被加工成天然存在的胶原。
58.如本文所用,术语“表达载体”或“载体”通常是指能够指导外源基因表达的核酸装配体。表达载体可包括与外源基因可操作连接的启动子、限制性核酸内切酶位点、编码一种或多种选择标记的核酸以及可用于重组技术实践的其他核酸。
59.如本文所用,术语“成纤维细胞”通常是指合成前胶原和其他结构蛋白的细胞。成纤维细胞广泛分布于体内,并存在于皮肤、结缔组织和其他组织中。
60.术语“荧光蛋白”通常是指可以在基因工程技术中用作外源多核苷酸表达的报道分子的蛋白质。该蛋白质在暴露于紫外线或蓝光下时发荧光并发出明亮的可见光。发出绿
光的蛋白质包括绿色荧光蛋白(gfp),发出红光的蛋白质包括红色荧光蛋白(rfp)。
61.如本文所用,术语“明胶”通常是指已经通过暴露于酸、碱或热而被进一步加工的胶原。在一些情况下,明胶溶液形成可逆凝胶,用于食品、化妆品、药品、工业产品、医疗产品、实验室培养生长培养基和许多其他应用。
62.如本文所用,术语“基因”通常是指编码特定蛋白质的多核苷酸,并且其可以单独指代编码区或可以包括在编码序列之前的调控序列(5'非编码序列)和之后的调控序列(3'非编码序列)。
63.术语“组氨酸标签”通常是指重组多肽上的2-30个连续的组氨酸残基系列。
64.术语“宿主细胞”通常是指经工程化以表达引入的外源多核苷酸的细胞。
65.术语“角质形成细胞”通常是指产生在皮肤的表皮层中存在的角蛋白的细胞。
66.如本文所用,术语“内酰胺酶”通常是指水解含有内酰胺(环酰胺)部分的抗生素的酶。“beta-内酰胺酶”或“β-内酰胺酶”是水解含有β-内酰胺部分的抗生素的酶。
67.如本文所用,术语“非天然存在的”是指通常在自然界中不存在的基因、多肽或蛋白质,例如胶原。非天然存在的胶原可以经重组制备。非天然存在的胶原可以是重组胶原。在一个实施方案中,非天然存在的胶原是截短胶原。其他非天然存在的胶原多肽包括嵌合胶原。嵌合胶原是其中胶原多肽的一部分与第二胶原多肽的一部分邻接的多肽。例如,包含邻接有人类胶原的一部分的海蜇胶原的一部分的胶原分子是嵌合胶原。在另一个实施方案中,非天然存在的胶原包括融合多肽,所述融合多肽包含另外的氨基酸,例如分泌标签、组氨酸标签、绿色荧光蛋白、蛋白酶切割位点、gek重复序列、gdk重复序列和/或β-内酰胺酶。
68.通常,本文提供的胶原或截短胶原(例如具有特定氨基酸序列)的公开包括具有或包含该精确氨基酸序列及其同系物的多肽。在一些情况下,本文提供的氨基酸序列的同系物可以具有更长或更短的序列,并且可以具有该氨基酸序列的一个或多个氨基酸残基的置换。这样的同系物与所述序列具有特定的序列同一性(例如以本文提供的序列同一性量)。序列同一性(例如出于评估百分比同一性的目的)可以通过任何合适的比对算法进行测量,包括但不限于needleman-wunsch算法(例如,参见www.ebi.ac.uk/tools/psa/emboss_needle/nucleotide.html上可用的emboss needle比对器,任选采用默认设置)、blast算法(例如,参见blast.ncbi.nlm.nih.gov/blast.cgi上可用的blast比对工具,任选采用默认设置),或者smith-waterman算法(例如,参见www.ebi.ac.uk/tools/psa/emboss_water/nucleotide.html上可用的emboss water比对器,任选采用默认设置)。可以使用所选算法的任何合适参数(包括默认参数)来评估最佳比对。在一些情况下,非天然存在的胶原可以与本文公开的序列具有至少60%、65%、70%、75%、80%、85%、90%、95%、97%、98%、99%或100%的序列同一性。
69.术语“蛋白酶切割位点”通常是指被特异性蛋白酶切割的氨基酸序列。
70.术语“分泌标签”或“信号肽”通常是指征募宿主细胞的细胞机制以将表达的蛋白质转运至宿主细胞的特定位置或细胞器的氨基酸序列。
71.术语“截短胶原”通常是指小于全长胶原的单体多肽,其中全长胶原的一个或多个部分不存在。胶原多肽在c末端被截短、在n末端被截短、通过去除全长胶原多肽的内部部分而被截短(例如内部截短),或者在c末端和n末端两处都被截短。在非限制性实施方案中,截短的人类胶原可包含根据seq id no:16的氨基酸序列或其同系物。在另一个非限制性示例
中,截短的海蜇胶原可包含根据seq id no:5的氨基酸序列或其同系物。通常,本文提供的截短胶原可以与天然或全长胶原具有相似或基本上相似的功能和/或提供相似或基本上相似的益处(例如,如本文提供的)。在一些情况下,与天然或全长胶原相比,本文提供的截短胶原可以具有改善或增加的功能和/或益处(例如,如本文提供的)。
72.当用于提及氨基酸位置时,“截短”包括所述氨基酸位置。例如,在全长蛋白质的氨基酸位置100处的n末端截短意味着从全长蛋白质的n末端截短了100个氨基酸(即,截短的蛋白质缺少全长蛋白质的1至100位氨基酸)。类似地,全长蛋白质(假设是具有1000个氨基酸的全长蛋白质)在氨基酸位置901处的c末端截短意味着从c末端截短了100个氨基酸(即,截短的蛋白质缺少全长蛋白质的901至1000位氨基酸)。类似地,在氨基酸位置101和200处的内部截短是指全长蛋白质的100个氨基酸的内部截短(即,截短的蛋白质缺少全长蛋白质的101至200位氨基酸)。
73.在一些实施方案中,细胞培养物可还包括以下一种或多种:氯化铵、硫酸铵、氯化钙、氨基酸、硫酸亚铁(ii)、硫酸镁、蛋白胨、磷酸钾、氯化钠、磷酸钠和酵母提取物。
74.宿主细菌细胞可以连续或不连续地培养;分批处理、加料分批处理或重复加料分批处理。
75.通常,信号序列可以是表达载体的组成部分,或者可以是插入载体中的外源基因的一部分。所选择的信号序列可以是被宿主细胞识别和处理(例如,被信号肽酶切割)的信号序列。对于不识别和处理外源基因的天然信号序列的细菌宿主细胞,该信号序列可以由任何通常已知的细菌信号序列代替。在一些实施方案中,可以使用dsba信号序列将重组产生的多肽靶向周质空间。dinh和bernhardt,j bacteriol,2011年9月,4984-4987。
76.在一方面,提供了由宿主细胞产生的非天然存在的胶原。非天然存在的胶原可以是海蜇胶原或人类胶原。非天然存在的胶原可以是截短胶原。所述截短可以是内部截短(例如,内部部分的截短)、在胶原的n-末端部分的截短、在胶原的c-末端部分的截短或在c-末端和n-末端两者处的截短。胶原可以被截短50个氨基酸至1000个氨基酸、50个氨基酸至950个氨基酸、50个氨基酸至900个氨基酸、50个氨基酸至850个氨基酸、50个氨基酸至800个氨基酸、50个氨基酸至850个氨基酸、50个氨基酸至800个氨基酸、50个氨基酸至750个氨基酸、50个氨基酸至700个氨基酸、50个氨基酸至650个氨基酸、50个氨基酸至600个氨基酸、50个氨基酸至550个氨基酸、50个氨基酸至500个氨基酸、50个氨基酸至450个氨基酸、50个氨基酸至400个氨基酸、50个氨基酸至350个氨基酸、50个氨基酸至300个氨基酸、50个氨基酸至250个氨基酸、50个氨基酸至200个氨基酸、50个氨基酸至150个氨基酸或50个氨基酸至100个氨基酸。在另一实施方案中,胶原可以被截短约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190、200、210、220、230、240、250、260、270、280、290、300、310、320、330、340、350、360、370、380、390、400、410、420、430、440、450、460、470、480、490、500、510、520、530、540、550、560、570、580、590、600、650、700、750、800、850、900、950或1000个氨基酸。非天然存在的胶原可以由多核苷酸序列的一部分或本文公开的整个多核苷酸序列编码。
77.本文公开的截短胶原可以包含相对于全长胶原的截短。在一些实施方案中,本文公开的截短胶原可以包含相对于全长人类21型α1胶原的截短。在一些实施方案中,本文公开的截短胶原可以包含相对于全长人类1型α2胶原的截短。在一些实施方案中,本文公开的截短胶原包括相对于全长海蜇(水螅虫)胶原的截短。全长胶原的非限制性示例提供在以下
表1中。表1.全长胶原的氨基酸序列
78.在一些情况下,如本文所述的截短胶原可以包含在seq id no:31的氨基酸位置1至548之间;氨基酸位置1至553之间;氨基酸位置1至558之间;氨基酸位置1至563之间;氨基酸位置1至568之间;或者氨基酸位置1至573之间的任何氨基酸位置的n末端截短。在一些情况下,如本文所述的截短胶原可以包含在seq id no:31的氨基酸位置726至957之间;氨基酸位置731至957之间;氨基酸位置736至957之间;氨基酸位置741至957之间;氨基酸位置746至957之间;氨基酸位置751至957之间;或者氨基酸位置756至957之间的任何氨基酸位置的c末端截短。在一些情况下,如本文所述的截短胶原可以包含n末端截短和c末端截短两
者。例如,如本文所述的截短胶原可以包含在seq id no:31的氨基酸位置1至548之间;氨基酸位置1至553之间;氨基酸位置1至558之间;氨基酸位置1至563之间;氨基酸位置1至568之间;或者氨基酸位置1至573之间的任何氨基酸位置的n末端截短;以及在氨基酸位置726至957之间;氨基酸位置731至957之间;氨基酸位置736至957之间;氨基酸位置741至957之间;氨基酸位置746至957之间;氨基酸位置751至957之间;或者氨基酸位置756至957之间的任何氨基酸位置的c末端截短。在特定实施方案中,本文公开的截短胶原可以包含在seq id no:31的氨基酸位置558的n末端截短;和在seq id no:31的氨基酸位置746的c末端截短。
79.在一些情况下,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置1至401之间;氨基酸位置1至406之间;氨基酸位置1至411之间;氨基酸位置1至416之间;氨基酸位置1至421之间;氨基酸位置1至426之间;或者氨基酸位置1至431之间的任何氨基酸位置的n末端截短。在一些情况下,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置585至1366之间;氨基酸位置590至1366之间;氨基酸位置595至1366之间;氨基酸位置600至1366之间;氨基酸位置605至1366之间;氨基酸位置610至1366之间;氨基酸位置615至1366之间;或者氨基酸位置620至1366之间的任何氨基酸位置的c末端截短。在一些情况下,如本文所述的截短胶原可以包含n末端截短和c末端截短两者。例如,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置1至401之间;氨基酸位置1至406之间;氨基酸位置1至411之间;氨基酸位置1至416之间;氨基酸位置1至421之间;氨基酸位置1至426之间;或者氨基酸位置1至431之间的任何氨基酸位置的n末端截短;以及在seq id no:32的氨基酸位置585至1366之间;氨基酸位置590至1366之间;氨基酸位置595至1366之间;氨基酸位置600至1366之间;氨基酸位置605至1366之间;氨基酸位置610至1366之间;氨基酸位置615至1366之间;或者氨基酸位置620至1366之间的任何氨基酸位置的c末端截短。在特定实施方案中,如本文提供的截短胶原可以包含在seq id no:32的氨基酸位置416的n末端截短;和在seq id no:32的氨基酸位置605的c末端截短。
80.在一些情况下,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置1至101之间;氨基酸位置1至106之间;氨基酸位置1至111之间;氨基酸位置1至116之间;氨基酸位置1至121之间;或者氨基酸位置1至126之间的任何氨基酸位置的n末端截短。在一些情况下,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置276至1366之间;氨基酸位置281至1366之间;氨基酸位置286至1366之间;氨基酸位置291至1366之间;氨基酸位置296至1366之间;氨基酸位置301至1366之间;或者氨基酸位置306至1366之间的任何氨基酸位置的c末端截短。在一些情况下,如本文所述的截短胶原可以包含n末端截短和c末端截短两者。例如,如本文所述的截短胶原可以包含在seq id no:32的氨基酸位置1至101之间;氨基酸位置1至106之间;氨基酸位置1至111之间;氨基酸位置1至116之间;氨基酸位置1至121之间;或者氨基酸位置1至126之间的任何氨基酸位置的n末端截短;以及在seq id no:32的氨基酸位置276至1366之间;氨基酸位置281至1366之间;氨基酸位置286至1366之间;氨基酸位置291至1366之间;氨基酸位置296至1366之间;氨基酸位置301至1366之间;或者氨基酸位置306至1366之间的任何氨基酸位置的c末端截短。在特定实施方案中,如本文提供的截短胶原可以包含在seq id no:32的氨基酸位置111的n末端截短;和在seq id no:32的氨基酸位置291的c末端截短。
81.在一些情况下,如本文所述的截短胶原可以包含在seq id no:33的氨基酸位置16
至240之间;氨基酸位置16至245之间;氨基酸位置16至250之间;氨基酸位置16至255之间;氨基酸位置16至260之间;氨基酸位置16至265之间;氨基酸位置6至255之间;氨基酸位置11至255之间;氨基酸位置21至255之间;氨基酸位置26至255之间;氨基酸位置31至255之间;氨基酸位置21至250之间;氨基酸位置21至245之间;氨基酸位置26至250之间;氨基酸位置26至245之间;氨基酸位置31至250之间;或者氨基酸位置31至245之间的任何氨基酸位置的内部截短。在特定实施方案中,如本文所述的截短胶原可以包含在seq id no:33的氨基酸位置16至255的内部截短。
82.在一些情况下,截短胶原可以包含以下表2中提供的任何氨基酸序列。在一些情况下,截短胶原可以由以下表2中提供的任何氨基酸序列组成。在一些情况下,截短胶原可以基本上由以下表2中提供的任何氨基酸序列组成。在特定实施方案中,非天然存在的胶原是或包含seq id no:2、seq id no:4、seq id no:5、seq id no:7、seq id no:10、seq id no:12、seq id no:14、seq id no:16、seq id no:18、seq id no:20、seq id no:22、seq id no:24、seq id no:25、seq id no:27和seq id no:29中任一个的氨基酸序列。在一些实施方案中,截短胶原包含的氨基酸序列与seq id no:2、seq id no:4、seq id no:5、seq id no:7、seq id no:10、seq id no:12、seq id no:14、seq id no:16、seq id no:18、seq id no:20、seq id no:22、seq id no:24、seq id no:25、seq id no:27和seq id no:29中的任一个具有至少85%、至少90%、至少95%或者至少98%的序列同一性。表2.截短胶原的非限制性示例
83.在一些情况下,截短胶原的长度可以在100至300个氨基酸之间、150至250个氨基
酸之间、160至250个氨基酸之间、160至220个氨基酸之间、170至200个氨基酸之间、180至190个氨基酸之间或者185至190个氨基酸之间。
84.在一些实施方案中,非天然存在的胶原可以还包括包含分泌标签的氨基酸序列。分泌标签可以将胶原引导至宿主细胞的周质空间。在具体实施方案中,信号肽衍生自dsba、pelb、ompa、tolb、male、lpp、tora、hy1a、degp或包含一个分泌标签的一部分与第二分泌标签的一部分融合的杂种分泌标签。在一方面,分泌标签可以附接于非天然存在的胶原。在另一方面,分泌标签可以从非天然存在的胶原上切割下来。
85.在一些实施方案中,非天然存在的胶原包含组氨酸(或多组氨酸)标签。在特定的实施方案中,组氨酸标签或多组氨酸标签是或包含附接至胶原的2至20个组氨酸残基的序列。在各种实施方案中,组氨酸标签包含2至20个组氨酸残基、5至15个组氨酸残基、5至18个组氨酸残基、5至16个组氨酸残基、5至15个组氨酸残基、5至14个组氨酸残基、5至13个组氨酸残基、5至12个组氨酸残基、5至11个组氨酸残基、5至10个组氨酸残基、6至12个组氨酸残基、6至11个组氨酸残基或7至10个组氨酸残基。组氨酸标签可用于通过采用基于镍的色谱介质的色谱方法进行蛋白质纯化。示例性的荧光蛋白包括绿色荧光蛋白(gfp)或红色荧光蛋白(rfp)。荧光蛋白是本领域众所周知的。在一个实施方案中,非天然存在的胶原包含gfp和/或rfp。在一个实施方案中,将超折叠gfp与非天然存在的胶原融合。超折叠gfp可以是即使与折叠不良的多肽融合也可以正确折叠的gfp。在一方面,组氨酸标签可以附接于非天然存在的胶原。在另一方面,组氨酸标签可以从非天然存在的胶原上切割下来。
86.在一些实施方案中,非天然存在的胶原还包含蛋白酶切割位点。蛋白酶切割位点可用于切割重组产生的胶原以去除多肽的一个或多个部分。可以去除的多肽部分包括分泌标签、组氨酸标签、荧光蛋白标签和/或β-内酰胺酶。蛋白酶可以包括内切蛋白酶、外切蛋白酶、丝氨酸蛋白酶、半胱氨酸蛋白酶、苏氨酸蛋白酶、天冬氨酸蛋白酶、谷氨酸蛋白酶和金属蛋白酶。示例性的蛋白酶切割位点包括被凝血酶、tev蛋白酶、因子xa、肠肽酶和鼻病毒3c蛋白酶切割的氨基酸。在一方面,切割标签附接于非天然存在的胶原。在另一方面,切割标签通过适当的蛋白酶被从非天然存在的胶原去除。
87.在一些实施方案中,非天然存在的胶原还包含作为β-内酰胺酶的酶。β-内酰胺酶可用作选择标记。在一方面,β-内酰胺酶附接于非天然存在的胶原。在另一方面,β-内酰胺酶被从非天然存在的胶原上切割下来。
88.本文某些实施方案中提供的是包含本文提供的一种或多种多肽的(例如局部的)组合物或制剂。在一些实施方案中,组合物例如以任何合适量(例如,当给予或施用于个体或细胞时适合提供益处的量)提供本文提供的任何合适量的多肽。在一些特定的实施方案中,组合物包含当(例如,局部地)施用于个体皮肤时适合于向个体皮肤提供有益作用的量。在特定实施方案中,组合物包含0.001%至30%w/w的例如本文提供的多肽(或非天然存在的胶原)。在更特定的实施方案中,组合物包含0.001%至20%w/w的例如本文提供的多肽(或非天然存在的胶原)、0.001%至10%w/w的例如本文提供的多肽(或非天然存在的胶原)、0.001%至5%w/w的例如本文提供的多肽(或非天然存在的胶原)、0.001%至2%w/w的例如本文提供的多肽(或非天然存在的胶原)、0.001%至1%w/w的例如本文提供的多肽(或非天然存在的胶原)、0.001%至0.5%w/w的例如本文提供的多肽(或非天然存在的胶原)以及0.001%至0.2%w/w的例如本文提供的多肽(或非天然存在的胶原)。
89.在一方面,包含非天然存在的胶原的组合物可以是个人护理产品(例如,化妆品)。在一些实施方案中,将组合物配制用于局部施用。组合物可以包含其他适合人类使用的化妆品成分。个人护理产品可用于预防或治疗紫外线辐射对人类皮肤或毛发的损害。个人护理产品可用于增加皮肤的紧致度、弹性、亮度、水合度、触觉质感或视觉质感,并且/或者刺激胶原产生。个人护理产品可用于减少皮肤发红。个人护理产品可以应用于皮肤或毛发。组合物包括例如面膜、皮肤清洁剂(如肥皂、清洁霜、清洁洗剂、洁面剂、清洁乳、清洁垫、洗面奶)、面部和身体乳霜和保湿剂、面部精华、面膜和身体膜、爽肤水和面部喷雾、眼霜和眼部护理剂、去角质配方、润唇膏和唇膏、洗发水、护发素和沐浴露、毛发和头皮精华、发雾和喷雾、眼影、遮瑕膏、睫毛膏和其他彩色化妆品。
90.包含非天然存在的胶原的组合物可以还包含至少一种另外的成分,包括局部载体或防腐剂。局部载体可以包括选自脂质体、可生物降解的微胶囊、洗剂、喷雾剂、气雾剂、粉化粉剂、可生物降解的聚合物、矿物油、甘油三酯油、硅油、甘油、单硬脂酸甘油酯、醇、乳化剂、液体石油、白凡士林、丙二醇、聚氧乙烯、聚氧丙烯、蜡、脱水山梨醇单硬脂酸酯、聚山梨酸酯、鲸蜡酯蜡、鲸蜡硬脂醇、2-辛基十二烷醇、苄醇、环甲硅油、环戊硅氧烷和水的局部载体。防腐剂可以包括选自生育酚、二碘甲基-对甲苯基砜、2-溴-2-硝基丙烷-1,3-二醇、1-(3-氯烯丙基)-3,5,7-三氮杂-1-氮鎓金刚烷氯化物顺式异构体、戊二醛、4,4-二甲基噁唑烷、7-乙基二环噁唑烷、苯氧基乙醇、丁二醇、1,2己二醇、对羟基苯甲酸甲酯、山梨酸、germaben ii、迷迭香提取物和edta的防腐剂。
91.在本文的某些实施方案中,还提供了减少皮肤损伤、促进受损皮肤的修复、保护皮肤免受紫外线损伤和/或保护皮肤细胞免受暴露于城市灰尘的影响的方法。在另一个实施方案中,提供了改善皮肤的紧致度、弹性、亮度、水合度、触觉质感或视觉质感和/或刺激胶原产生的方法。该方法可以包括将包含非天然存在的胶原的组合物应用于受试者的皮肤的步骤。不受特定理论或机制的束缚,组合物中的胶原可通过防止紫外线损伤来减少皮肤损伤。在一些情况下,组合物中的胶原可通过增加细胞活力来促进受损皮肤的修复。在一些情况下,当组合物中的胶原应用于皮肤时,可通过增加前胶原的合成和/或促进皮肤细胞的活力来减少皮肤损伤和/或促进细胞修复。在一些情况下,胶原减少了胸腺嘧啶-胸腺嘧啶(tt)二聚体的形成。
92.本文提供的方法包括使用组合物进行方法中指示的治疗(例如通过本文提供的步骤)。在实施方案中,本公开提供了本文提供的组合物(例如,截短胶原或包含截短胶原的制剂)在用于减少皮肤损伤、促进受损皮肤的修复、保护皮肤免受紫外线损伤和/或保护皮肤细胞免受暴露于城市灰尘的影响的方法中的用途(例如,通过向受试者的皮肤施用本文提供的组合物)。在实施方案中,本公开提供了本文提供的组合物(例如,截短胶原或包含截短胶原的制剂)在用于改善皮肤的紧致度、弹性、亮度、水合度、触觉质感或视觉质感和/或刺激胶原产生的方法中的用途。
93.在一些实施方案中,本文提供的截短胶原可以刺激成纤维细胞和/或角质形成细胞产生i型胶原(参见例如实施例4和实施例6)。在一些情况下,可以测量i型前胶原c-肽的水平(胶原产生的读数)。在一些情况下,可以使用体外mattek全厚度人类皮肤组织模型(参见例如实施例6)来评估i型前胶原c-肽水平。在一些情况下,i型胶原水平可以通过酶联免疫吸附测定(elisa)进行测量或确定。在一些情况下,与未处理的细胞、用视黄醇处理的细
胞和/或用维生素b3处理的细胞相比,本文提供的截短胶原可以以更高的水平刺激i型胶原的产生。
94.在一些实施方案中,本文提供的截短胶原可刺激细胞外基质基因的成纤维细胞过表达(参见例如实施例4)。在一些情况下,细胞外基质基因的水平可以通过rna测序来测量。在一些情况下,本文提供的截短胶原可刺激i型胶原基因(col1a)、弹性蛋白基因(eln)和纤连蛋白基因(fn1)中的一种或多种的成纤维细胞过表达。在一些情况下,通过用本文提供的截短胶原处理的成纤维细胞产生的细胞外基质基因的水平可以高于未处理的成纤维细胞或用视黄醇处理的成纤维细胞。在一些情况下,通过用本文提供的截短胶原处理的成纤维细胞产生的细胞外基质基因的水平可以类似于或高于用维生素c处理的成纤维细胞。
95.在一些实施方案中,本文提供的截短胶原可以减少经uvb光照射的角质形成细胞的炎症(参见例如实施例4和实施例6)。在一些情况下,可用uvb光照射角质形成细胞,然后用本文提供的截短胶原处理。在一些情况下,可以通过测量由经uvb照射的角质形成细胞产生的il-1α水平(例如,通过elisa)来测量炎症。在一些情况下,对于经uvb照射的角质形成细胞,当用本文提供的截短胶原处理时,与未处理的角质形成细胞相比,可产生较低水平的il-1α。
96.在一些实施方案中,本文提供的截短胶原可以增加经uvb光照射的角质形成细胞的活力(参见例如实施例4)。在一些情况下,可用本文提供的截短胶原对角质形成细胞进行预处理(在uvb照射之前)和后处理(在uvb照射之后)。在一些情况下,可以使用mtt代谢比色测定法测量细胞活力。在一些情况下,用本文提供的截短胶原处理的角质形成细胞与未处理的角质形成细胞相比,在uvb照射后可表现出更大的细胞活力。
97.在一些实施方案中,本文提供的截短胶原可以减少暴露于uvb光后角质形成细胞中的dna损伤(参见例如实施例6)。在一些情况下,可以通过测量胸腺嘧啶二聚体(tt-二聚体)的水平来评估dna损伤。在非限制性示例中,oxiselect uv诱导的dna损伤elisa试剂盒可用于测量tt-二聚体的水平。在一些情况下,与未处理的角质形成细胞相比,用本文提供的截短胶原处理的经uvb照射的角质形成细胞可以显示出更低的tt-二聚体水平。
98.在一些实施方案中,本文提供的截短胶原可以具有抗氧化能力(参见例如实施例4和实施例6)。在一些情况下,氧自由基吸收能力(orac)测定法可用于测量截短胶原的抗氧化能力。在非限制性示例中,呈0.1%溶液形式的截短胶原可具有至少10μm trolox(维生素e)当量(te)、至少50μm te、至少100μm te、至少150μm te、至少160μm te、至少170μm te、至少180μm te、至少190μm te或至少200μm te的抗氧化性质。
99.在一些实施方案中,与未处理的细胞相比,本文提供的截短胶原可以增加暴露于城市灰尘污染的角质形成细胞的细胞活力(参见例如实施例6)。在一些情况下,可以通过mtt代谢比色测定法测量细胞活力。
100.在一些实施方案中,向受试者的面部局部施用本文提供的截短胶原可导致在处理后的1周、2周、4周、8周或更长的时间,面部皮肤的弹性与基线相比增加(参见例如实施例5和实施例7)。在一些情况下,面部皮肤的弹性可以通过皮肤弹性测试仪来测量。
101.在一些实施方案中,向受试者的面部局部施用本文提供的截短胶原可导致在处理后的1周、2周、4周、8周或更长的时间,面部皮肤的胶原含量与基线相比增加(参见例如实施例5)。在一些情况下,可以通过siascope测量面部皮肤的胶原含量。
102.在一些实施方案中,局部施用本文提供的截短胶原可导致在处理后的1周、2周、4周、8周或更长的时间,面部皮肤的发红(红疹)与基线相比减少(例如参见实施例5)。在一些情况下,可以由不知情的临床评分员对面部皮肤的发红(红疹)进行评分(例如,使用表4中提供的5点顺序量表)。
103.在一些实施方案中,局部施用本文提供的截短胶原可导致在处理后的1周、2周、4周、8周或更长的时间,面部皱纹与基线相比减少(参见例如实施例5)。在一些情况下,可以由不知情的临床评分员对面部皱纹进行评分。
104.在一些实施方案中,局部施用本文提供的截短胶原可导致在处理后的1周、2周、4周、8周或更长的时间,面部皮肤的水分与基线相比增加(参见例如实施例7)。在一些情况下,与局部施用海洋胶原相比,局部施用提供本文提供的截短胶原可导致面部皮肤的水分增加。在一些情况下,可以通过皮肤水分测试仪测量皮肤的水合度。
105.本公开的一方面提供了编码非天然存在的胶原的多核苷酸。多核苷酸可以编码来自海蜇或人类的胶原。多核苷酸可以编码全长或截短的胶原。在各种实施方案中,多核苷酸可以包括根据seq id no:1、seq id no:3、seq id no:6、seq id no:8、seq id no:9、seq id no:11、seq id no:13、seq id no:15、seq id no:17、seq id no:19、seq id no:21、seq id no:23、seq id no:26、seq id no:28或seq id no:30或其同系物(例如,与其具有至少85%、至少90%、至少95%或至少98%的序列同一性)中的任一个的多核苷酸。在一些情况下,可以对多核苷酸进行密码子优化(例如,用于在宿主细胞中表达)。
106.在另一方面,本公开提供了编码胶原融合蛋白的多核苷酸。胶原融合蛋白可以包含分泌标签、组氨酸标签、荧光蛋白标签、蛋白酶切割位点、β-内酰胺酶和/或gek氨基酸三聚体重复序列和/或gdk氨基酸三聚体重复序列,以及胶原。
107.在一方面,包含编码胶原的多核苷酸的载体可以用于转化宿主细胞并表达多核苷酸。多核苷酸还可包含编码酶的核酸,该酶允许宿主生物体在选择剂的存在下生长。选择剂可包括某些糖,包括含半乳糖的糖,或抗生素,包括氨苄青霉素、潮霉素、g418等。可用于赋予选择剂抗性的酶包括β-半乳糖苷酶或β-内酰胺酶。
108.在一方面,提供了表达本发明的多核苷酸的宿主细胞。宿主细胞可以是任何宿主细胞,包括革兰氏阴性细菌细胞、革兰氏阳性细菌细胞、酵母细胞、昆虫细胞、哺乳动物细胞、植物细胞或用于表达外源多核苷酸的任何其他细胞。示例性的革兰氏阴性宿主细胞是大肠杆菌。
109.除碳、氮和无机磷酸盐源以外,还可以包含适当浓度的任何期望或必要的补充剂,其单独引入或作为与另一种补充剂或介质(诸如复合氮源)的混合物引入。在某些实施方案中,培养基还包含一种或多种选自以下的成分:氯化铵、硫酸铵、氯化钙、酪蛋白氨基酸、硫酸亚铁(ii)、硫酸镁、蛋白胨、磷酸钾、氯化钠、磷酸钠和酵母提取物。
110.β-内酰胺酶是赋予原核细胞中的内酰胺抗生素抗性的酶。典型地,当β-内酰胺酶在细菌宿主细胞中表达时,表达的β-内酰胺酶蛋白还包含将β-内酰胺酶蛋白导向周质空间的靶向序列(分泌标签)。β-内酰胺酶只有转运到周质空间才会起作用。提供了靶向周质空间的β-内酰胺酶,无需使用将酶靶向周质空间的独立分泌标签。通过创建其中将周质分泌标签添加到蛋白质(例如gfp、胶原或gfp/胶原嵌合体)的n末端的融合蛋白,可以使用缺少天然分泌标签的β-内酰胺酶的功能来选择n-末端融合蛋白的完全翻译和分泌。采用这种方
法,可以使用dsba-gfp-胶原-β-内酰胺酶融合物来选择靶胶原中有利于翻译和分泌的截短产物。
111.另一个实施方案提供了产生例如本文所提供的多肽(或非天然存在的胶原)的方法。在一些实施方案中,该方法包括以下步骤:用重组宿主细胞接种培养基,所述重组宿主细胞包含编码所述多肽或“胶原”的多核苷酸;培养所述宿主细胞;以及从所述宿主细胞分离所述多肽(或非天然存在的胶原)。
112.提供了发酵制备多肽(或蛋白质)的方法。该方法包括以下步骤:(a)在包含镁盐的培养基中培养重组革兰氏阴性细菌细胞,其中所述培养基中镁离子的浓度为至少约6mm,并且其中所述细菌细胞包含编码所述蛋白质的外源基因;和(b)从所述培养基中收获所述蛋白质。
113.细菌可以以任何合适的方式培养,例如连续培养(如例如wo 05/021772中所述)或以分批过程(分批培养)或以加料分批或重复加料分批过程的方式不连续培养,以用于产生目标蛋白。在一些实施方案中,蛋白质生产是大规模进行的。各种大规模发酵程序可用于生产重组蛋白。大规模发酵具有至少1,000升的容量,优选大约1,000至100,000升的容量。在一些情况下,发酵罐使用搅拌器叶轮分配氧气和养分,尤其是葡萄糖(优选的碳源/能源)。小规模发酵通常是指在发酵罐中发酵,发酵罐的容量不超过约20升。
114.为了积累目标蛋白,可以在足以积累目标蛋白的条件下培养宿主细胞。这样的条件包括例如温度、养分和允许细胞表达和积累蛋白质的细胞密度条件。此外,如本领域技术人员已知的,这样的条件可以是指在这些条件下细胞可以执行针对分泌蛋白的如下基本细胞功能:转录、翻译和蛋白质从一个细胞室到另一细胞室的传递。
115.在本文提供的方法中任选地使用任何合适的细菌细胞。细菌细胞可以在任何合适的温度下培养。在特定的实施方案中,细菌细胞是大肠杆菌细胞。对于大肠杆菌生长,例如,典型温度范围为约20℃至约39℃。在一个实施方案中,温度为约20℃至约37℃。在另一实施方案中,温度为约30℃。在一个实施方案中,可以在一个温度下在非切换状态或切换状态下培养宿主细胞,并切换至不同温度以诱导蛋白质产生。可以先在一个温度下培养宿主细胞以繁殖细胞,然后可以在较低温度下培养细胞以诱导蛋白质产生。第一温度可以是大约23℃、24℃、25℃、26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃、34℃、35℃、36℃或37℃。第二温度可以是大约20℃、21℃、22℃、23℃、24℃、25℃、26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃、34℃、35℃或36℃。在第二温度下的培养可以进行1小时至100小时、5小时至90小时、5小时至80小时、5小时至75小时、5小时至70小时、10小时至70小时、15小时至70小时、15小时至65小时、15小时至60小时、20小时至60小时、20小时至55小时、20小时至50小时、24小时至50小时、24小时至48小时、30小时至50小时、30小时至45小时或30小时至40小时。
116.培养基的ph可以是约5-9的任何ph,主要取决于宿主生物体。对于大肠杆菌,ph可以为约6.0至约7.4、约6.2至约7.2、约6.2至约7.0、约6.2至约6.8、约6.2至约6.6、约6.4或约6.5。
117.为了诱导基因表达,通常可以将细胞培养直至达到一定的光密度,例如,od 600为约1.1,在该点开始诱导(例如,通过添加诱导剂,通过耗尽阻抑剂、抑制剂或培养基组分等)以诱导编码目标蛋白的外源基因的表达。在一些实施方案中,外源基因的表达可以通过选自例如异丙基-β-d-1-硫代半乳糖吡喃糖苷、乳糖、阿拉伯糖、麦芽糖、四环素、脱水四环素、
vavlycin、木糖、铜、锌等的诱导剂来诱导。基因表达的诱导还可以通过降低发酵过程中的溶解氧水平来实现。细胞繁殖期间发酵的溶解氧水平可以在10%至30%之间。为了诱导基因表达,可将溶解氧水平降低至低于10%、9%、8%、7%、6%、5%、4%、3%、2%、1%或0%。在宿主细胞中,无论是处于生理状态还是处于转换状态,都可以通过降低如本文所公开的发酵温度来诱导蛋白质产生。实施例实施例1.截短胶原的产生
118.合成并表达了密码子优化的dna序列,该序列针对在大肠杆菌中的表达进行了优化并且编码具有240个内部氨基酸的截短(相对于全长海蜇胶原(seq id no:33))的海蜇胶原。该dna序列在以下的seq id no:1中示出。在seq id no:1中,dsba分泌标签由核苷酸1-72编码并且编码seq id no:2的氨基酸1-24。包含9个组氨酸残基的组氨酸标签由seq id no:1的核苷酸73-99编码并且编码seq id no:2的氨基酸25-33。连接子由seq id no:1的核苷酸100-111编码并编码seq id no:2的氨基酸34-37。凝血酶切割位点由seq id no:1的核苷酸112-135编码并且编码seq id no:2的氨基酸38-45。截短胶原由seq id no:1的核苷酸136-822编码并且编码seq id no:2的氨基酸46-274。
119.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatcaccatcaccaccaccaccatcaccactctggctcgagcctggtgccgcgcggcagccatatgggtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtgaaaaaggagaacagggacgtacaggtgcagcaggtaaacagggcagcccgggtgccgatggtgcccgtggcccgctgggtagcattggtcagcagggtgcaagaggcgaaccgggcgatccgggtagtccgggcctgcgtggtgatacgggtctggccggtgttaaaggcgttgcaggtccttcaggtcgtccaggtcaaccgggtgcaaatggtctgccgggtgttaatggtcgtggcggtctggaacgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgttaa(seq id no:1)
120.截短胶原约为全长海蜇胶原(seq id no:33)的54%,并在以下的seq id no:2中公开。
121.mkkiwlalaglvlafsasaaqyedhhhhhhhhhsgsslvprgshmgpqgvvgadgkdgtpgekgeqgrtgaagkqgspgadgargplgsigqqgargepgdpgspglrgdtglagvkgvagpsgrpgqpganglpgvngrgglerglagppgpdgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglr(seq id no:2)
122.在seq id no:3中公开了编码没有dsba分泌标签、组氨酸标签、连接子和凝血酶切割位点的截短海蜇胶原的多核苷酸。
123.gtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtgaaaaaggagaacagggacgtacaggtgcagcaggtaaacagggcagcccgggtgccgatggtgcccgtggcccgctgggtagcattggtcagcagggtgcaagaggcgaaccgggcgatccgggtagtccgggcctgcgtggtgatacgggtctggccggtgttaaaggcgttgcaggtccttcaggtcgtccaggtcaaccgggtgcaaatggtctgccgggtgttaatggtcgtggcggtctggaa
cgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgttaa(seq id no:3)
124.在seq id no:4中公开了没有dsba分泌标签、组氨酸标签、连接子和凝血酶切割位点的截短的海蜇胶原氨基酸序列。
125.gpqgvvgadgkdgtpgekgeqgrtgaagkqgspgadgargplgsigqqgargepgdpgspglrgdtglagvkgvagpsgrpgqpganglpgvngrgglerglagppgpdgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglr(seq id no:4)
126.将seq id no:1的多核苷酸进行密码子优化,并通过gen9dna(现在为ginkgo bioworks)内部合成来合成。将pet28载体与seq id no:1之间的重叠序列设计为30至40bp长,并使用pcr通过酶gxl聚合酶(www.clontech.com/us/products/pcr/gc_rich/primestar_gxl_dna_polymerase?sitex=10020:22372:us)来添加。然后使用sgi gibson(us.vwr.com/store/product/17613857/gibson-assembly-hifi-1-step-kit-synthetic-genomics-inc)将打开的pet28a载体和插入dna(seq id no:1)组装在一起成为最终质粒。然后通过eurofins genomics(www.eurofinsgenomics.com)的sanger测序验证质粒序列。
127.将转化的细胞在基本培养基中培养,并以50:50的细胞:甘油比冷冻在具有甘油的1.5ml等分试样中。将一小瓶这种冷冻培养物在50ml基本培养基中于37℃、200rpm下复苏过夜。将细胞转移到300ml基本培养基中,生长6-9小时,以达到od600为5-10。
128.用2.7l的基本培养基+葡萄糖制备生物反应器,并添加300ml od600为5-10的培养物以使起始体积达到3l。使细胞在28℃、ph 7下生长,其中使用包含搅拌、空气和氧气的级联将溶解氧保持在20%饱和度。用28%w/w的氢氧化铵溶液控制ph。一旦40g/l的初始食团在13小时左右耗尽,便会使用基于do-stat的加料算法以加料分批模式进行发酵。在初始生长24-26小时后,od600达到高于100。此时,添加300ml 500g/l蔗糖,并将温度降至25℃。使用1mm iptg诱导高密度培养以产生蛋白质。继续发酵另外20-24小时,并使用台式离心机在9000rcf、15℃下离心60分钟来收获细胞。将离心回收的细胞沉淀以2x缓冲液比1x细胞的重量比重悬于ph为8的含有0.5m nacl和0.1m kh2po4的缓冲液中。
129.将收获的细胞在匀浆器中以14,000psi的压力破碎2次。所得浆液包含胶原蛋白以及其他蛋白质。
130.在范围为25℃至28℃的不同温度下进行发酵。对于某些发酵,将发酵温度保持在恒定温度,并且在发酵完成时(od 600为5-10)立即将胶原纯化。对于其他发酵,将发酵温度维持期望的时间段,并且当od 600细胞密度达到5-10时,降低温度以诱导蛋白质产生。通常,将温度从28℃降低到25℃。在25℃下继续发酵40-60小时后,分离胶原。
131.通过对匀浆的细胞肉汤进行酸处理来纯化胶原。另外,在离心和重悬于上述缓冲
液中之后,还对从生物反应器回收的未匀浆的完整细胞进行了酸处理。使用6m盐酸将匀浆的浆液或重悬的完整细胞的ph降低至ph 3。将酸化的细胞浆液在混合下于4℃温育过夜,然后离心。在聚丙烯酰胺凝胶上测试了酸化浆液的上清液,发现与起始沉淀相比,所含胶原的丰度相对较高。如此获得的胶原浆液的盐分高。为了减少体积和盐分,使用emd millipore切向流过滤系统执行浓缩和渗滤步骤(各自使用0.1m2的超滤盒)。使用两个平行的盒的总过滤面积为0.2m2。在tff阶段,体积减少了5x,盐分减少了19x。使最终胶原浆液在sds-page凝胶上电泳,以确认胶原的存在。使用多托盘冻干机将该浆液干燥3天,以获得白色蓬松的胶原粉末。
132.在sds-page凝胶上分析获自匀浆的细胞肉汤或未匀浆的细胞的纯化截短胶原,并在预期的27千道尔顿的大小处观察到一条清晰的粗条带。还通过质谱法分析了纯化的胶原,证实了27千道尔顿的蛋白质是海蜇胶原。
133.下文提供了全长胶原和截短的胶原的可替选纯化方法。
134.将发酵肉汤与0.3-0.5%w/v的聚乙亚胺(pei)混合。在与pei温育15分钟后,将发酵肉汤在9000rcf下离心15分钟,以回收含有胶原蛋白的上清液。丢弃含有细胞的沉淀,并将经pei处理的含有胶原的上清液与钠膨润土(最终0.2%w/v)(wyoming膨润土)混合并离心。丢弃含有膨润土的沉淀,并回收上清液。
135.使用5kda的盒在切向流过滤系统(tff)(emd millipore)上将经膨润土处理的上清液浓缩3-6倍。在渗透液流几乎没有损失的情况下保留了胶原。为了去除盐,使用相同的tff装置对浓缩步骤中的渗余物进行渗滤。蛋白质溶液的最终电导率<10毫西门子。典型的电导率在400微西门子至1.5毫西门子之间。高浓度胶原溶液的较高电导率接近4毫西门子。本领域技术人员将理解,根据胶原的浓度,可以观察到高于10毫西门子的电导率。接着,使用w-l 9000 10
×
40粒状树脂(carbon activated corporation)用活性炭对脱盐的浓缩蛋白质进行处理。将5%w/v的碳树脂与含胶原的进料混合,并在45-50℃下温和搅拌混合。在存在或不存在助滤剂例如硅藻土(sigma aldrich)的情况下,使用衬有ertel压滤垫m-953(ertel alsop)的布氏漏斗过滤经碳处理的浆液。过滤后,将胶原溶液通过0.2微米过滤器过滤,然后用钠膨润土(最终0.2%w/v)(wyoming膨润土)处理一到数个小时,并在9000rcf下离心15-30分钟获得高纯度、透明且无颗粒的胶原溶液。当需要去除内毒素蛋白时,将该蛋白通过诸如sartobind-q(sartorius-stedim)之类的色谱过滤器来特异性去除内毒素蛋白。
136.在sds-page凝胶上分析纯化的胶原,并在30千道尔顿处观察到一条清晰的粗条带。大小上移是由于胶原分子的结构和高甘氨酸/脯氨酸氨基酸含量。还通过质谱法分析了纯化的胶原,并证实了30千道尔顿的蛋白质是截短胶原。
137.使用agilent 1100系列hplc通过hplc进一步分析截短胶原。柱为50mm agilent plrp-s反相色谱柱,其中内径为4.6mm,粒径为μm,孔径为1000埃。
138.通过在hplc级水中的0.04%叠氮化钠溶液中以1:1稀释来制备样品。稀释后,将所得混合物通过0.45μm过滤器过滤,以除去任何可能堵塞hplc柱的大颗粒。为了进行分析,将样品在约ph 4.5下用在hplc级水中的20mm醋酸铵缓冲液适当稀释。在混合样品后,将其转移至300μl微量瓶中,然后将其置于自动进样器中。使用操作hplc的软件chemstation,可以
更改分析参数,例如样品流速、柱温、流动相流速、流动相组成等。在一个示例性但非限制性的分析中,参数为:样品流速为1ml/min,柱温为80℃,柱压为60-70bar,流动相组成为97.9%水/1.9%乙腈和0.2%三氟乙酸;用于分析的uv波长为214.4nm,进样量为10μl,样品运行时间为10分钟。
139.在这些条件下,seq id no:5的截短的海蜇胶原具有约5.4分钟的洗脱时间。chemstation定量了洗脱峰的峰面积,并使用将峰面积与蛋白质浓度直接有关的校准曲线计算蛋白浓度。该校准曲线使用已知的胶原溶液生成,该已知的胶原溶液被连续稀释成包含0.06mg/ml至1.00mg/ml的胶原浓度。没有his标签-连接子-凝血酶切割位点的截短胶原
140.下面公开了没有his标签、连接子和凝血酶切割位点的截短的海蜇胶原。在seq id no:6中提供了编码该胶原的密码子优化的核苷酸序列。在seq id no:7中公开了氨基酸序列。dsba分泌标签由seq id no:6的核苷酸1-72编码,并且编码seq id no:7的氨基酸1-24。截短胶原序列由seq id no:6的核苷酸73-639编码,并且编码seq id no:7的氨基酸25-213。
141.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatggtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtaatgcaggtcagaaaggtccgtcaggtgaacctggcagccctggtaaagcaggtagtgccggtgagcagggtccgccgggcaaagatggtagtaatggtgagccgggtagccctggcaaagaaggtgaacgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgttaa(seq id no:6)
142.mkkiwlalaglvlafsasaaqyedgpqgvvgadgkdgtpgnagqkgpsgepgspgkagsageqgppgkdgsngepgspgkegerglagppgpdgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglr(seq id no:7)
143.编码没有his标签、连接子和凝血酶切割位点的截短海蜇胶原的多核苷酸在seq id no:8中公开。
144.ggtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtaatgcaggtcagaaaggtccgtcaggtgaacctggcagccctggtaaagcaggtagtgccggtgagcagggtccgccgggcaaagatggtagtaatggtgagccgggtagccctggcaaagaaggtgaacgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgttaa(seq id no:8)
145.没有his标签、连接子和凝血酶切割位点的截短海蜇胶原在seq id no:5中公开。
146.gpqgvvgadgkdgtpgnagqkgpsgepgspgkagsageqgppgkdgsngepgspgkegerglagppgp
dgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglr(seq id no:5)具有dsba分泌标签-his标签-连接子-凝血酶切割位点和gfpβ-内酰胺酶融合蛋白的截短胶原(版本1):
147.下面公开了具有dsba分泌标签-his标签-连接子-凝血酶切割位点和gfpβ-内酰胺酶融合蛋白的海蜇胶原。在seq id no:9中提供了编码该胶原的密码子优化的核苷酸序列。在seqid no:10中公开了氨基酸序列。dsba分泌标签由seq id no:9的核苷酸1-72编码,并且编码seq id no:10的氨基酸1-24。his标签由seq id no:9的核苷酸73-99编码,并且编码seq id no:10的氨基酸25-33的9组氨酸标签。连接子由seq id no:9的核苷酸100-111编码,并且编码seq id no:10的氨基酸34-37。凝血酶切割位点由seq id no:9的核苷酸112-135编码,并且编码seq id no:10的氨基酸38-45。具有连接子的绿色荧光蛋白(gfp)由seq id no:9的核苷酸136-873编码,并且编码seq id no:10的氨基酸46-291。截短胶原序列由seq id no:9的核苷酸874-1440编码,并且编码seq id no:10的氨基酸292-480。具有连接子的β-内酰胺酶由seq id no:9的核苷酸1441-2232编码,并且编码seq id no:10的氨基酸481-744。即使该多肽不具有独立的分泌标签,β-内酰胺酶也正确地靶向周质空间。dsba分泌标签将整个转录物(具有dsba分泌标签-his标签-连接子-凝血酶切割位点和gfpβ-内酰胺酶融合蛋白的截短胶原)引向周质空间,并且β-内酰胺酶正常起作用。
148.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatcaccatcaccaccaccaccatcaccactctggctcgagcctggtgccgcgcggcagccatatgtctggctcgagcagtaaaggtgaagaactgttcaccggtgttgttccgatcctggttgaactggatggtgatgttaacggccacaaattctctgttcgtggtgaaggtgaaggtgatgcaaccaacggtaaactgaccctgaaattcatctgcactaccggtaaactgccggttccatggccgactctggtgactaccctgacctatggtgttcagtgtttttctcgttacccggatcacatgaagcagcatgatttcttcaaatctgcaatgccggaaggttatgtacaggagcgcaccatttctttcaaagacgatggcacctacaaaacccgtgcagaggttaaatttgaaggtgatactctggtgaaccgtattgaactgaaaggcattgatttcaaagaggacggcaacatcctgggccacaaactggaatataacttcaactcccataacgtttacatcaccgcagacaaacagaagaacggtatcaaagctaacttcaaaattcgccataacgttgaagacggtagcgtacagctggcggaccactaccagcagaacactccgatcggtgatggtccggttctgctgccggataaccactacctgtccacccagtctaaactgtccaaagacccgaacgaaaagcgcgaccacatggtgctgctggagttcgttactgcagcaggtatcacgcacggcatggatgaactctacaaatctggcgcgccgggcggtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtaatgcaggtcagaaaggtccgtcaggtgaacctggcagccctggtaaagcaggtagtgccggtgagcagggtccgccgggcaaagatggtagtaatggtgagccgggtagccctggcaaagaaggtgaacgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgtcacccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatacactattctcagaa
tgacttggttgagtactcaccagtcacagaaaagcatcttacggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaacttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgggggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaacaattaatagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaagccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagatcgctgagataggtgcctcactgattaagcattggtaa(seq id no:9)
149.mkkiwlalaglvlafsasaaqyedhhhhhhhhhsgsslvprgshmsgssskgeelftgvvpilveldgdvnghkfsvrgegegdatngkltlkficttgklpvpwptlvttltygvqcfsrypdhmkqhdffksampegyvqertisfkddgtyktraevkfegdtlvnrielkgidfkedgnilghkleynfnshnvyitadkqkngikanfkirhnvedgsvqladhyqqntpigdgpvllpdnhylstqsklskdpnekrdhmvllefvtaagithgmdelyksgapggpqgvvgadgkdgtpgnagqkgpsgepgspgkagsageqgppgkdgsngepgspgkegerglagppgpdgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglrhpetlvkvkdaedqlgarvgyieldlnsgkilesfrpeerfpmmstfkvllcgavlsridagqeqlgrrihysqndlveyspvtekhltdgmtvrelcsaaitmsdntaanlllttiggpkeltaflhnmgdhvtrldrwepelneaipnderdttmpvamattlrklltgelltlasrqqlidwmeadkvagpllrsalpagwfiadksgagergsrgiiaalgpdgkpsrivviyttgsqatmdernrqiaeigaslikhw(seq id no:10)
150.通过组装多个dna片段来构建seq id no:9的多核苷酸。将含有胶原的序列进行密码子优化,并通过gen9dna(现在为ginkgo bioworks)内部合成来合成。gfp也由gen9合成。使用pcr通过酶gxl聚合酶(www.clontech.com/us/products/pcr/gc_rich/primestar_gxl_dna_polymerase?sitex=10020:22372:us)将β-内酰胺酶从质粒pkd46(cgsc2.biology.yale.edu/strain.php?id=68099)中克隆出来。将pet28载体、gfp、胶原和β-内酰胺酶之间的重叠序列设计为30至40bp长,并使用pcr通过酶gxl聚合酶添加。然后使用sgi gibson(us.vwr.com/store/product/17613857/gibson-assembly-hifi-1-step-kit-synthetic-genomics-inc)将打开的pet28a载体和插入物组装在一起成为最终质粒。然后通过eurofins genomics(www.eurofinsgenomics.com)的sanger测序验证质粒序列。
151.将转化的细胞在基本培养基中培养,并以50:50的细胞:甘油比冷冻在具有甘油的1.5ml等分试样中。将一小瓶这种冷冻培养物在50ml基本培养基中于37℃、200rpm下复苏过夜。将细胞转移到300ml基本培养基中,生长6-9小时,以达到od600为5-10。
152.用2.7l的基本培养基+葡萄糖制备生物反应器,并添加300ml od600为5-10的培养物以使起始体积达到3l。使细胞在28℃、ph 7下生长,其中使用包含搅拌、空气和氧气的级联将溶解氧保持在20%饱和度。用28%w/w的氢氧化铵溶液控制ph。一旦40g/l的初始食团在13小时左右耗尽,便会使用基于do-stat的加料算法以加料分批模式进行发酵。在初始生长24-26小时后,od600达到高于100。此时,添加300ml 500g/l蔗糖,并将温度降至25℃。使用1mm iptg诱导高密度培养以产生蛋白质。继续发酵另外20-24小时,并使用台式离心机在
9000rcf、15℃下离心60分钟来收获细胞。将离心回收的细胞沉淀以2x缓冲液比1x细胞的重量比重悬于ph为8的含有0.5m nacl和0.1m kh2po4的缓冲液中。
153.将收获的细胞在匀浆器中以14,000psi的压力破碎2次。所得浆液包含胶原蛋白以及其他蛋白质。
154.在离心和重悬于上述缓冲液中之后,对从生物反应器回收的未匀浆的完整细胞进行酸处理以纯化胶原。使用6m盐酸将重悬的悬浮液的ph降低至ph 3。将酸化的细胞浆液在混合下于4℃温育过夜,然后离心。然后使用10n naoh将ph升至9,并在聚丙烯酰胺凝胶上测试了浆液的上清液,发现与起始沉淀相比,所含胶原的丰度相对较高。如此获得的胶原浆液的盐分高。为了减少体积和盐分,使用emd millipore切向流过滤系统执行浓缩和渗滤步骤(各自使用0.1m2的超滤盒)。使用两个平行的盒的总过滤面积为0.2m2。在tff阶段,体积减少了5x,盐分减少了19x。使最终胶原浆液在sds-page凝胶上电泳,以确认胶原的存在。使用多托盘冻干机将该浆液干燥3天,以获得白色蓬松的胶原粉末。
155.在sds-page凝胶上分析了纯化的胶原-gfp-β-内酰胺酶融合蛋白,并观察到在90千道尔顿的表观分子量处的电泳。该融合蛋白的预期大小为85kda。通过质谱法证实了90kda的条带是正确的胶原融合蛋白。具有dsba分泌标签-his标签-连接子-凝血酶切割位点和gfpβ-内酰胺酶融合蛋白的截短胶原(版本2):
156.下面公开了具有dsba分泌标签-his标签-连接子-凝血酶切割位点和gfpβ-内酰胺酶融合蛋白的海蜇胶原。在seq id no:11中提供了编码该胶原的密码子优化的核苷酸序列。在seqid no:12中公开了氨基酸序列。dsba分泌标签由seq id no:11的核苷酸1-72编码,并且编码seq id no:12的氨基酸1-24。his标签由seq id no:11的核苷酸73-99编码,并且编码seq id no:12的氨基酸25-33的9组氨酸标签。连接子由seq id no:11的核苷酸100-111编码,并且编码seq id no:12的氨基酸34-37。凝血酶切割位点由seq id no:11的核苷酸112-135编码,并且编码seq id no:12的氨基酸38-45。具有连接子的绿色荧光蛋白(gfp)由seq id no:11的核苷酸136-873编码,并且编码seq id no:12的氨基酸46-291。截短胶原序列由seq id no:11的核苷酸874-1440编码,并且编码seq id no:12的氨基酸292-480。具有连接子的β-内酰胺酶由seq id no:11的核苷酸1441-2232编码,并且编码seq id no:12的氨基酸481-744。
157.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatcaccatcaccaccaccaccatcaccactctggctcgagcctggtgccgcgcggcagccatatgtctggctcgagcagtaaaggtgaagaactgttcaccggtgttgttccgatcctggttgaactggatggtgatgttaacggccacaaattctctgttcgtggtgaaggtgaaggtgatgcaaccaacggtaaactgaccctgaaattcatctgcactaccggtaaactgccggttccatggccgactctggtgactaccctgacctatggtgttcagtgtttttctcgttacccggatcacatgaagcagcatgatttcttcaaatctgcaatgccggaaggttatgtacaggagcgcaccatttctttcaaagacgatggcacctacaaaacccgtgcagaggttaaatttgaaggtgatactctggtgaaccgtattgaactgaaaggcattgatttcaaagaggacggcaacatcctgggccacaaactggaatataacttcaactcccataacgtttacatcaccgcagacaaacagaagaacggtatcaaagctaacttcaaaattcgccataacgttgaagacggtagcgtacagctggcggaccactaccagcagaacactccgatcggtgatggtccggttctgctgccggataaccactacctgtccacccagtctaaactgtccaaagacccgaacgaaaagcgcgaccacatggtgctgctggagttcgttactgcagcaggt
atcacgcacggcatggatgaactctacaaatctggcgcgccgggcggtccgcagggtgttgttggtgcagatggtaaagacggtaccccgggtaatgcaggtcagaaaggtccgtcaggtgaacctggcagccctggtaaagcaggtagtgccggtgagcagggtccgccgggcaaagatggtagtaatggtgagccgggtagccctggcaaagaaggtgaacgtggtctggcaggaccgccgggtcctgatggtcgccgcggtgaaacgggttcaccgggtattgccggtgccctgggtaaaccaggtctggaaggtccgaaaggttatcctggtctgcgcggtcgtgatggtaccaatggcaaacgtggcgaacagggcgaaaccggtccagatggtgttcgtggtattccgggtaacgatggtcagagcggtaaaccgggcattgatggtattgatggcaccaatggtcagcctggcgaagcaggttatcagggtggtcgcggtacccgtggtcagctgggtgaaacaggtgatgttggtcagaatggtgatcgcggcgcaccgggtccggatggtagcaaaggtagcgccggtcgtccgggtttacgtcacccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatacactattctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttacggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaacttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgggggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaacaattaatagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaagccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagatcgctgagataggtgcctcactgattaagcattggtaa(seq id no:11)
158.mkkiwlalaglvlafsasaaqyedhhhhhhhhhsgsslvprgshmsgssskgeelftgvvpilveldgdvnghkfsvrgegegdatngkltlkficttgklpvpwptlvttltygvqcfsrypdhmkqhdffksampegyvqertisfkddgtyktraevkfegdtlvnrielkgidfkedgnilghkleynfnshnvyitadkqkngikanfkirhnvedgsvqladhyqqntpigdgpvllpdnhylstqsklskdpnekrdhmvllefvtaagithgmdelyksgapggpqgvvgadgkdgtpgnagqkgpsgepgspgkagsageqgppgkdgsngepgspgkegerglagppgpdgrrgetgspgiagalgkpglegpkgypglrgrdgtngkrgeqgetgpdgvrgipgndgqsgkpgidgidgtngqpgeagyqggrgtrgqlgetgdvgqngdrgapgpdgskgsagrpglrhpetlvkvkdaedqlgarvgyieldlnsgkilesfrpeerfpmmstfkvllcgavlsridagqeqlgrrihysqndlveyspvtekhltdgmtvrelcsaaitmsdntaanlllttiggpkeltaflhnmgdhvtrldrwepelneaipnderdttmpvamattlrklltgelltlasrqqlidwmeadkvagpllrsalpagwfiadksgagergsrgiiaalgpdgkpsrivviyttgsqatmdernrqiaeigaslikhw(seq id no:12)实施例2.人类胶原截短的人类21型α1胶原
159.下文公开了没有his标签、连接子和凝血酶裂解位点的截短的人类21型α1胶原(相对于全长的人类21型α1胶原(seq id no:31)被截短)。编码该胶原的密码子优化的核苷酸序列和氨基酸序列在下文公开。dsba分泌标签由seq id no:13的核苷酸1-72编码,并且编码seq id no:14的氨基酸1-24。截短胶原序列由seq id no:13的核苷酸73-633编码,并且编码seq id no:14的氨基酸25-211。
160.编码该胶原的密码子优化的核苷酸序列在seq id no:13中提供。
161.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatga
agatgcaggttttccgggtctgcctggtccggcaggcgaaccgggtcgtcatggtaaagatggtctgatgggtagtccgggttttaaaggtgaagcaggttcaccgggtgcacctggtcaggatggcacccgtggtgaaccgggtattccgggatttccgggtaatcgtggcctgatgggtcagaaaggtgaaattggtccgcctggtcagcagggtaaaaaaggcgcaccgggtatgccaggactgatgggttcaaatggcagtccgggtcagccaggcacaccgggttcaaaaggtagcaaaggcgaacctggtattcagggtatgcctggtgcaagcggtctgaaaggcgagccaggtgccaccggttctccgggtgaaccaggttatatgggtctgccaggtatccaaggcaaaaaaggtgataaaggtaatcagggcgaaaaaggcattcagggccagaaaggcgaaaatggccgtcagggtattccaggccagcagggcatccagggtcatcatggtgcaaaaggtgaacgtggtgaaaagggcgaaccaggtgttcgttta(seq id no:13)
162.氨基酸序列在seq id no:14中公开。
163.mkkiwlalaglvlafsasaaqyedagfpglpgpagepgrhgkdglmgspgfkgeagspgapgqdgtrgepgipgfpgnrglmgqkgeigppgqqgkkgapgmpglmgsngspgqpgtpgskgskgepgiqgmpgasglkgepgatgspgepgymglpgiqgkkgdkgnqgekgiqgqkgengrqgipgqqgiqghhgakgergekgepgvr(seq id no:14)
164.编码没有dsba分泌标签的截短的人类21型α1胶原的密码子优化的核苷酸序列在seq id no:15中提供。
165.tgcaggttttccgggtctgcctggtccggcaggcgaaccgggtcgtcatggtaaagatggtctgatgggtagtccgggttttaaaggtgaagcaggttcaccgggtgcacctggtcaggatggcacccgtggtgaaccgggtattccgggatttccgggtaatcgtggcctgatgggtcagaaaggtgaaattggtccgcctggtcagcagggtaaaaaaggcgcaccgggtatgccaggactgatgggttcaaatggcagtccgggtcagccaggcacaccgggttcaaaaggtagcaaaggcgaacctggtattcagggtatgcctggtgcaagcggtctgaaaggcgagccaggtgccaccggttctccgggtgaaccaggttatatgggtctgccaggtatccaaggcaaaaaaggtgataaaggtaatcagggcgaaaaaggcattcagggccagaaaggcgaaaatggccgtcagggtattccaggccagcagggcatccagggtcatcatggtgcaaaaggtgaacgtggtgaaaagggcgaaccaggtgttcgttaa(seq id no:15)
166.没有dsba分泌标签的截短的人类21型α1胶原的氨基酸序列在seq id no:16中提供。
167.agfpglpgpagepgrhgkdglmgspgfkgeagspgapgqdgtrgepgipgfpgnrglmgqkgeigppgqqgkkgapgmpglmgsngspgqpgtpgskgskgepgiqgmpgasglkgepgatgspgepgymglpgiqgkkgdkgnqgekgiqgqkgengrqgipgqqgiqghhgakgergekgepgvr(seq id no:16)
168.通过twist bioscience合成seq id no:13的多核苷酸。将pet28载体与seq id no:15和seq id no:16之间的重叠序列设计为20至40bp长,并使用pcr通过酶gxl聚合酶(www.takarabio.com/products/pcr/gc-rich-pcr/primestar-gxl-dna-polymerase)来添加。然后使用in-fusion cloning(www.takarabio.com/products/cloning/in-fusion-cloning)将打开的pet28a载体和插入dna(seq id no:13)组装在一起成为最终质粒。然后通过genewiz(www.genewiz.com/en)的sanger测序验证质粒序列。
169.将转化的细胞在基本培养基中培养,并以50:50的细胞:甘油比冷冻在具有植物甘油的1.5ml等分试样中。将一小瓶这种冷冻培养物在50ml基本培养基中于37℃、200rpm下复苏过夜。将细胞转移到300ml基本培养基中,生长6-9小时,以达到od600为5-10。
170.在本实施例和整个申请中所用的基本培养基如下制备:
1)将5l在di水中的浓度为550g/kg的蔗糖浆液(vwr,产品号97061-170)高压灭菌。2)在3946ml di水中将以下各项高压灭菌:20g(nh4)2hpo4.(vwr,产品号97061-932);66.5g kh2po4.(vwr,产品号97062-348);22.5g h3c6h5o7.(vwr,产品号bdh9228-2.5kg);8.85g mgso4.7h2o.(vwr,产品号97062-134);10ml的1000x痕量金属制剂(表3)。在高压灭菌后,添加:118g的(1)至(2);5ml的25mg/ml硫酸卡那霉素(vwr-v0408);使用28%nh4oh(vwr,产品号bdh3022)将ph调节至6.1。表3.痕量金属制剂七水硫酸亚铁,27.8g/l(spectrum,7782-63-0)七水硫酸锌,2.88g/l(spectrum,7446-20-0)二水氯化钙,2.94g/l(spectrum,2971347)二水钼酸钠,0.48g/l(spectrum,10102-40-6)四水氯化锰,1.26g/l(spectrum,13446-34-9)亚硒酸钠,0.35g/l(spectrum,10102-18-8)硼酸,0.12g/l(spectrum,10043-35-3
171.在25℃至28℃的不同温度下进行发酵。对于某些发酵,将发酵温度保持在恒定温度,并且在发酵完成时立即将胶原纯化。对于其他发酵,将发酵温度维持期望的时间段,并且当od 600细胞密度达到10-20时,降低温度以诱导蛋白质产生。通常,将温度从28℃降低到25℃。在25℃下继续发酵40-60小时后。
172.如下纯化胶原:使用5-50%硫酸将发酵肉汤的ph降低至3-3.5。然后使用离心分离细胞。在聚丙烯酰胺凝胶上测试了酸化肉汤的上清液,发现与起始沉淀相比,所含胶原的丰度相对较高。如此获得的胶原浆液的盐分高。为了减少体积和盐分,使用emd millipore切向流过滤系统执行浓缩和渗滤步骤(各自使用0.1m2的超滤盒)。使用两个平行的盒的总过滤面积为0.2m2。在tff阶段,体积减少了5x,盐分减少了19x。使最终胶原浆液在sds-page凝胶上电泳,以确认胶原的存在。
173.在sds-page凝胶上分析纯化的胶原,并在预期的25千道尔顿的大小处观察到一条清晰的粗条带。使用反相和尺寸排阻hplc色谱法对胶原的滴度和纯度进行定量。滴度通常在每升3至8克/升之间。还通过质谱法进一步分析了纯化的胶原,证实与人类21型胶原的公开序列匹配。截短的人类1型α2(1)胶原
174.下面公开了没有his标签、连接子和凝血酶切割位点的截短的人类1型α2胶原(相对于全长的人类1型α2胶原(seq id no:32)被截短)。密码子优化的核苷酸序列和氨基酸序列在下文公开。dsba分泌标签由seq id no:17的核苷酸1-72编码,并且编码seq id no:18的氨基酸1-24。截短胶原序列由seq id no:17的核苷酸73-636编码,并且编码seq id no:18的氨基酸25-212。
175.编码该胶原的密码子优化的核苷酸序列在seq id no:17中提供。
176.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatatgggtccgcctggtagccgtggtgcaagtggtccggcaggcgttcgtggtccgaatggtgatgcaggtcgtccgggtgaaccgggtctgatgggtcctcgtggtctgcctggttcaccgggtaatattggtcctgcaggtaaagaaggtccggttggtctgccaggtattgatggccgtccgggtccgattggtccagccggtgcacgtggtgaacctggcaatattggttttccgggtcctaaaggtccgaccggtgatccgggtaaaaatggtgataaaggtcatgcaggtctggcaggcgcacgcggtgcacctggtccggatggtaataatggtgcacagggtccaccgggtccgcagggtgttcaaggtggtaaaggcgaacagggtcctgccggtcctccgggttttcagggactgcctggtccgagcggtcctgcgggtgaagttggtaaacctggtgaacgcggtctgcatggtgaatttggcctgcctgggcctgcaggtccgcgtggcgaacgtggtccgccaggtgaaagcggtgcagcaggtccgacaggttaa(seq id no:17)
177.氨基酸序列在seq id no:18中提供。
178.mkkiwlalaglvlafsasaaqyedmgppgsrgasgpagvrgpngdagrpgepglmgprglpgspgnigpagkegpvglpgidgrpgpigpagargepgnigfpgpkgptgdpgkngdkghaglagargapgpdgnngaqgppgpqgvqggkgeqgpagppgfqglpgpsgpagevgkpgerglhgefglpgpagprgergppgesgaagptg(seq id no:18)
179.没有dsba分泌标签的截短的人类1型α2(1)胶原的核酸序列在seq id no:19中提供。
180.atgggtccgcctggtagccgtggtgcaagtggtccggcaggcgttcgtggtccgaatggtgatgcaggtcgtccgggtgaaccgggtctgatgggtcctcgtggtctgcctggttcaccgggtaatattggtcctgcaggtaaagaaggtccggttggtctgccaggtattgatggccgtccgggtccgattggtccagccggtgcacgtggtgaacctggcaatattggttttccgggtcctaaaggtccgaccggtgatccgggtaaaaatggtgataaaggtcatgcaggtctggcaggcgcacgcggtgcacctggtccggatggtaataatggtgcacagggtccaccgggtccgcagggtgttcaaggtggtaaaggcgaacagggtcctgccggtcctccgggttttcagggactgcctggtccgagcggtcctgcgggtgaagttggtaaacctggtgaacgcggtctgcatggtgaatttggcctgcctgggcctgcaggtccgcgtggcgaacgtggtccgccaggtgaaagcggtgcagcaggtccgacaggttaa(seq id no:19)
181.没有dsba分泌标签的截短的人类1型α2(1)胶原的氨基酸序列在seq id no:20中提供。
182.mgppgsrgasgpagvrgpngdagrpgepglmgprglpgspgnigpagkegpvglpgidgrpgpigpagargepgnigfpgpkgptgdpgkngdkghaglagargapgpdgnngaqgppgpqgvqggkgeqgpagppgfqglpgpsgpagevgkpgerglhgefglpgpagprgergppgesgaagptg(seq id no:20)截短的人类1型α2(2)胶原
183.下面公开了没有his标签、连接子和凝血酶切割位点的截短的人类1型α2胶原(相对于全长的人类1型α2胶原(seq id no:32)被截短)。密码子优化的核苷酸序列和氨基酸序列在下文公开。dsba分泌标签由seq id no:21的核苷酸1-72编码,并且编码seq id no:22的氨基酸1-24。截短胶原序列由seq id no:21的核苷酸73-609编码,并且编码seq id no:22的氨基酸25-203。
184.编码该胶原的密码子优化的核苷酸序列在seq id no:21中提供。
185.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcggcgcagtatgaagatggttttcagggtcctgccggtgaaccgggtgaacctggtcagacaggtccggcaggcgcacgtggtcctgca
ggtcctcctggtaaagccggtgaagatggtcatccgggtaaaccgggtcgtcctggtgaacgtggtgttgttggtccgcagggtgcccgtggttttccgggtactccgggtctgccaggttttaaaggtattcgtggtcataatggtctggatggtctgaaaggtcagcctggtgcaccgggtgttaaaggtgaaccaggtgctccgggtgaaaatggcacaccgggtcagaccggtgcgcgtggtctgcctggcgaacgcggtcgtgttggtgcacctggtccagccggtgcacgcggtagtgatggtagcgttggtccggttggtccagcgggtccgattggtagcgcaggtccaccgggttttccaggcgcaccgggtccgaaaggtgaaattggtgcagttggtaatgcaggccctgccggtccagcaggaccgcgtggtgaagttggcctgcctggtctgtaa(seq id no:21)
186.氨基酸序列在seq id no:22中提供。
187.mkkiwlalaglvlafsasaaqyedgfqgpagepgepgqtgpagargpagppgkagedghpgkpgrpgergvvgpqgargfpgtpglpgfkgirghngldglkgqpgapgvkgepgapgengtpgqtgarglpgergrvgapgpagargsdgsvgpvgpagpigsagppgfpgapgpkgeigavgnagpagpagprgevglpgl(seq id no:22)
188.没有dsba分泌标签的截短的人类1型α2(2)胶原的核酸序列在seq id no:23中提供。
189.ggttttcagggtcctgccggtgaaccgggtgaacctggtcagacaggtccggcaggcgcacgtggtcctgcaggtcctcctggtaaagccggtgaagatggtcatccgggtaaaccgggtcgtcctggtgaacgtggtgttgttggtccgcagggtgcccgtggttttccgggtactccgggtctgccaggttttaaaggtattcgtggtcataatggtctggatggtctgaaaggtcagcctggtgcaccgggtgttaaaggtgaaccaggtgctccgggtgaaaatggcacaccgggtcagaccggtgcgcgtggtctgcctggcgaacgcggtcgtgttggtgcacctggtccagccggtgcacgcggtagtgatggtagcgttggtccggttggtccagcgggtccgattggtagcgcaggtccaccgggttttccaggcgcaccgggtccgaaaggtgaaattggtgcagttggtaatgcaggccctgccggtccagcaggaccgcgtggtgaagttggcctgcctggtctgtaa(seq id no:23)
190.没有dsba分泌标签的截短的人类1型α2(2)胶原的氨基酸序列在seq id no:24中提供。
191.gfqgpagepgepgqtgpagargpagppgkagedghpgkpgrpgergvvgpqgargfpgtpglpgfkgirghngldglkgqpgapgvkgepgapgengtpgqtgarglpgergrvgapgpagargsdgsvgpvgpagpigsagppgfpgapgpkgeigavgnagpagpagprgevglpgl(seq id no:24)
192.如本文所述,将seq id no:13、17或21的多核苷酸亚克隆到载体pet28a中以制备转化载体。用载体转化宿主细胞,如实施例1所述表达多核苷酸。
193.在发酵完成之后,使用实施例2中公开的程序从发酵肉汤中纯化截短的人类胶原。如实施例2中公开的,使用sds-page和hplc分析纯化的截短人类胶原。
194.在sds-page分析中,所有三种截短的人类胶原均以预期的分子量电泳。在使用hplc分析截短的人类胶原时,利用了使用实施例1的海蜇胶原的标准曲线。人类胶原的保留时间与海蜇胶原的保留时间略有不同。seq id no:16的保留时间为5.645分钟,seq id no:20的保留时间为5.631分钟,并且seq id no:24在两个峰处电泳,并且保留时间为5.531分钟和5.7分钟。具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短5
195.在seq id no:25中公开了具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短5的氨基酸序列。dsba分泌标签由seq id no:26的核苷酸1-57编码并且氨基酸序列是seq id no:25的氨基酸1-19。胶原的核苷酸序列是seq id no:26的核苷酸58-657并且氨基
酸序列是seq id no:25的氨基酸20-219。flag核苷酸序列是seq id no:26的核苷酸658-684并且氨基酸序列是seq id no:25的氨基酸220-228。
196.mkkiwlalaglvlafsasagdqgpvgrtgevgavgppgfagekgpsgeagtagppgtpgpqgllgapgilglpgsrgerglpgvagavgepgplgiagppgargppgavgspgvngapgeagrdgnpgndgppgrdgqpghkgergypgnigpvgaagapgphgpvgpagkhgnrgetgpsgpvgpagavgprgpsgpqgirgdkgepgekgprglpglgdykddddk(seq id no:25)
197.具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短5的核酸序列在seq id no:26中公开。
198.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcgggtgatcagggtccggttggtcgtaccggtgaagttggtgcagtcgggccgccgggttttgcgggtgaaaaaggcccgtcaggtgaagcaggcaccgctggccctcctggcacgcctggcccacagggtttactgggcgcacctggaattctgggactgccgggcagccgtggagaacgcggtttaccaggtgttgccggtgccgttggtgaacctggtccactgggcattgcagggccgcctggcgcacggggaccgcctggtgctgttggtagtccgggtgtgaatggtgctccgggtgaagccggtcgtgacggtaatccgggaaatgacggcccgccaggccgcgatggtcagccgggtcataaaggtgagcgtggttacccaggtaatattggtccagtcggtgccgccggtgcgccgggtcctcatggccctgtcggtccagccggtaaacatggtaatcgcggtgagacaggtccgtcaggaccagtgggccctgctggcgcagtcggtccgcgcgggccgagtggccctcagggtattcgtggcgataaaggggaaccgggcgaaaaagggccgcggggtctgccaggcctgggtgactacaaagacgacgacgacaaataa(seq id no:26)
199.将seq id no:26的多核苷酸亚克隆到载体pet28a中,在宿主大肠杆菌细胞中表达,并如本文所述纯化截短胶原。纯化的胶原在sds-page上产生一条清晰的条带,并且在约100千道尔顿处观察到抗flag western。在不表达这种蛋白质的情况下,在凝胶上的该位置没有出现条带。具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短6
200.在seq id no:27中公开了具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短6的氨基酸序列。dsba分泌标签由seq id no:28的核苷酸1-57编码并且氨基酸序列是seq id no:27的氨基酸1-19。胶原的核苷酸序列是seq id no:28的核苷酸58-657并且氨基酸序列是seq id no:27的氨基酸20-219。flag核苷酸序列是seq id no:28的核苷酸658-684并且氨基酸序列是seq id no:27的氨基酸220-228。
201.mkkiwlalaglvlafsasakghnglqglpgiaghhgdqgapgsvgpagprgpagpsgpagkdgrtghpgtvgpagirgpqghqgpagppgppgppgppgvsgggydfgydgdfyradqprsapslrpkdyevdatlkslnnqietlltpegsrknpartcrdlrlshpewssgyywidpnqgctmdaikvycdfstgetciraqpenipaknwyrsskdgdykddddk(seq id no:27)
202.具有dsba分泌标签和flag标签的截短的人类1型α2胶原截短6的核酸序列在seq id no:28中公开。
203.atgaaaaagatttggctggcgctggctggtttagttttagcgtttagcgcatcggcgaaaggtcacaatggactgcaaggcctgccaggtattgcaggtcatcatggtgatcaaggtgccccgggaagcgttggtccggcggggccgagaggccctgcgggaccttcaggtccggcaggcaaagatggtcggacaggccatccgggcaccgttggccctgcaggaattcgtggaccgcagggtcatcagggacctgctggtccgccaggtcccccgggccctccgggaccaccgggtgttagtggtggtggttatgattttggctatgatggtgatttttatcgtgcagatcagccgcgtagcgcaccgagc
clinical practice)(fda和ich指南)和适用的政府法规进行的。
211.制备由水、橄榄油甘油聚醚-8酯、甘油、椰子烷烃、丙烯酸羟乙酯/丙烯酰基二甲基牛磺酸钠共聚物、戊二醇、edta二钠、辛甘醇、氯苯甘醚、苯氧乙醇制成的基础制剂(对照制剂)。通过添加足够的胶原来制备含有截短的人类21型胶原的制剂,从而制备含有0.1%w/w胶原的局部制剂。合格性和功效的专业分级评估
212.视觉模拟量表(vas)通常用于临床研究中,以衡量无法直接测量的各种症状、主观特征或态度的强度或频率。vas是一种可靠的量表,并且比简单的顺序量表对小变化更敏感(a.paul-dauphin,f.guillemin,j.virion和s.briancon,"bias and precision in visual analog scales:a randomized controlled trial,"american journal of epidemiology,第150卷,第10期,第1117-27页,1999)。当回答vas项目时,专业评分员通过指示沿着两个端点或锚点回答之间的线(10厘米)的位置来指定其对陈述的同意程度。使用简单的vas评价功效参数,其中10厘米水平线的两端定义为从左(最佳)到右(最坏)定向的极限。光老化的迹象可以分类如下:轻度=1-3.9厘米,中度=4-6.9厘米,严重=7-10厘米。
213.使用了以下vas:
214.顺序量表允许数字直接和客观地关系到给定属性的质量。当回答顺序量表项目时,专业评分员通过选择设置的等级或水平来指定他们对陈述的同意程度。
215.每个受试者的面部皮肤发红(红疹)的外观由专业评分员使用以下五点式顺序量表进行评估(针对基线处的合格性)(表4)。如果合格,每个受试者将在第2周、第4周、第6周和第8周接受进一步的红疹评估。表4.红疹评估的5点式顺序量表
216.皮肤水分测试仪cm 820(courage+khazaka,germany)通过使用一对紧密间隔的电极向皮肤施加交流电并测量电容来测量皮肤表面的相对水合度程度。皮肤含水量的变化会改变电容电路的电导率。
217.皮肤水分测试仪能够以仅约一秒的测量时间可再现地检测水合度水平的微小变化。测量深度小(约10-20μm的角质层),这可确保评估不受较深的皮肤层影响。
218.所有受试者在基线、初次应用后即刻以及在第2周、4周和8周接受其面部的皮肤水分测试仪测量。将一式三份进行测量,并在每个时间点取平均值。将测量位置记录在面部图上,以确保每个时间点的评估一致性。
219.皮肤弹性测试仪mpa 580(courage+khazaka,germany)通过如下来测量皮肤的粘弹性质:对皮肤表面施加吸力,将皮肤吸入探针的孔中并使用光学测量系统确定穿透深度。
220.计算由负压吸起皮肤的阻力(紧致度)及其恢复到原始位置的能力(弹性),并以曲线形式展示。皮肤弹性测试仪的输出包括测量曲线的不同部分的许多参数,包括r0(uf,紧致度)、r2(ua/uf,总弹性)、r5(ur/ue,净弹性)、r7(ur/uf,弹性部分)和r9(r3[last max amp]-r0[uf],疲劳)。
[0221]
所有受试者在基线、初次应用后即刻以及第2周、4周和8周时,在左或右脸颊(遵循准备好的随机码)上进行皮肤弹性测试仪测量。使用r5(ur/ue)和r2(ua/uf)参数报告皮肤弹性。随着皮肤变得更有弹性,该值将增加。使用r0(uf)参数报告皮肤紧致度。随着皮肤变紧,该值将降低。将评估位置记录在每个受试者的面部图上,以确保访视之间的测量一致性。
[0222]
cosmetrics
tm siascope(astron clinica,toft,uk)是一种使用分光光度皮内分析(sia)或生色团映射的无创光学皮肤成像仪器。该技术基于皮肤镜检查和接触式汇兑分光光度法(contact remittance spectrophotometry)的独特组合。硬件包括连接到膝上型计算机的手持式成像探头。该装置放置在与皮肤表面接触的地方,高强度的led以400至1000nm的离散波长(覆盖可见光谱和小范围近红外光谱)照射皮肤。针对每个波长捕获数字图像。检索到三个参数生色团图(深度最大为2mm,周长为11mm),每个参数生色团图对应以下参数之一:表皮黑色素、真皮血红蛋白和真皮胶原。
[0223]
为了本研究的目的,将在基线以及第2周、4周和8周按照准备好的随机码在左或右脸颊上测量真皮胶原。将评估位置记录在每个受试者的面部图上,以确保访视之间的测量一致性。
[0224]
dermascan c usb(cortex technology aps,hadsund,denmark)是一种紧凑型高分辨率超声扫描仪。使用20mhz、高分辨率60
×
150μm、13mm穿透探头,这可提供线性扫描、高精度操作和真实位置检测,以实现图像清晰度和分辨率。
[0225]
该仪器由cyberderm,inc.(broomall,pa,usa)提供。所有受试者均在基线以及第2周、4周和8周在面部上进行超声评估。评估的位置在每次访视时都相同,并将记录在面部图上。获得超声扫描后,将其发送到cyberderm,inc.,以分析真皮厚度(密度)。
[0226]
所有临床摄影均按照irsi的sop进行,以确保整个研究期间高质量图像的再现性。成像在带有哑光黑墙的指定摄影套件中进行,所有自然光都被遮挡。为了使受试者准备进行临床摄影,要求受试者取下所有首饰,包括耳环、项链和任何面部首饰。训练有素的技术人员在光放大回路下检查受试者,以确保在脸部、眼睛或嘴唇上看不到残留的彩色化妆品
或护肤品。为受试者提供黑色斗篷和黑色头带,并指示他们放置以确保将所有头发整齐地束回并被遮盖。
[0227]
clarity
tm 2d研究系统ti(清晰度)(brightex bio-photonics(btbp),san jose ca,usa)捕获高质量的全脸正面、左侧和右侧图像。系统中的三个摄像头使用实时馈送显示和针对基线图像的自动面部对齐检查(以实现可重复性),从而同时捕获16位的18兆像素slr图像。
[0228]
多光谱照明(漫射白光、交叉偏振、蓝光和平行偏振)揭示了皮肤表层上下的皮肤状况。该系统使用皮肤特征识别来应用自动皮肤分割和区域映射,以进行后续皮肤分析。分析图像中与色素沉着、表面下色素沉着、光泽、肤色、发红、皱纹、皮肤质感、毛孔、痤疮和/或嘴唇有关的属性。
[0229]
所有受试者在基线、第2周、4周和8周时在标准光和平行偏振光下拍摄了正视、左视和右视的面部图像。
[0230]
主观调查表允许赞助商能够评估受试者对其皮肤、测试产品及产品效果的看法。问题将采用五点式量表和开放式回答来询问受试者对陈述的同意程度。
[0231]
登记了十四名女性受试者。入选标准为健康状况良好且年龄在35至65岁(登记时含)之间的fitzpatrick iii型皮肤白种女性受试者。入选标准还包括由专业评分员在基线时确定的以下面部老化迹象:a)褶皱/皱纹在10cm量表上的评分≥2cm且≤6cm;和b)面部发红(红疹)在五点式顺序量表上的评分≥1且≤3。表5公开了研究参与者的人口统计数据。表5.人口统计数据
[0232]
在两周的处理之后,专业临床评分员对褶皱/皱纹、紧致度(视觉)、弹性(触觉)、亮度、质感/柔软度(触觉)、质感/光滑度(视觉)和红斑的评价结果显示在表6中。所有测试的特性均得到改善。亮度、质感/柔软度(触觉)、质感/光滑度(视觉)和红斑的分数均有统计学显著的改善。表6.专业临床评分员评价-monadic,与基线比较
*表示相比于基线有统计学显著的改善,p≤0.05
[0233]
表7显示了使用皮肤水分测试仪和皮肤弹性测试仪的仪器评价水合度、紧致度、弹性。皮肤水合度、紧致度和弹性的改善在统计学上是显著的。另外,如通过分光光度皮内分析(sia)所表明的,表7显示了对皮肤细胞产生胶原的刺激。表7.仪器评价-monadic,与基线比较monadic,与基线比较ni=无改善*表示相比于基线有统计学显著的改善,p≤0.05**表示相比于基线有统计学显著的恶化,p≤0.05
[0234]
结果表明,截短的人类21型胶原显示出对皮肤的弹性、亮度、水合度、触觉质感或视觉质感的统计学显著的改善。此外,结果显示,截短的人类21型胶原显示出对可见的褶皱或皱纹的统计学显著的减少以及对红疹的显著减少。
实施例4.在皮肤细胞上进行的截短的人类21型胶原的体外研究截短的人类21型α1胶原刺激成纤维细胞产生i型胶原
[0235]
进行了一系列体外实验以评估截短的人类21型胶原对人类皮肤成纤维细胞和角质形成细胞的作用。在第一个实验中,评价了人类原代成纤维细胞的i型胶原蛋白分泌。将成纤维细胞与0.03%的根据seq id no:16的多肽培养48小时。通过酶联免疫吸附测定法(elisa)分析培养上清液的前胶原i型c-肽,这是i型胶原蛋白分泌总量的读数。如图1所示,用seq id no:16的多肽处理的细胞(图1;“b”)分泌的i型胶原的水平高于未处理的细胞(图1;“a”)或用视黄醇处理的细胞(图1;“c”)。截短的人类21型α1胶原刺激成纤维细胞产生细胞外基质蛋白的基因
[0236]
进行rna测序以分析总体基因表达。暴露48小时后,将成纤维细胞与0.03%的根据seq id no:16的多肽一起温育。与仅在培养基中温育的细胞相比,这些成纤维细胞表达更高水平的多种细胞外基质基因。如图2a所示,相对于未处理的细胞(图2a;“a”)或用视黄醇处理的成纤维细胞(图2a;“b”),用seq id no:16的多肽处理的成纤维细胞(图2a;“c”)上调了i型胶原基因(col1a)。该反应类似于用维生素c处理的成纤维细胞(图2a;“d”)。如图2b所示,用seq id no:16的多肽处理的成纤维细胞(图2b;“b”)相对于未处理的细胞(图2b;“a”)和各种海洋胶原(图2b;“c”、“d”、“e”和“f”)上调了弹性蛋白基因(eln)。如图2c所示,用seq id no:16的多肽处理的成纤维细胞(图2c;“b”)相对于未处理的细胞(图2c;“a”)、视黄醇(图2c;“c”)和维生素c(图2c;“d”)上调了纤连蛋白基因(fn1)。截短的人类21型α1胶原减少经uvb光照射的角质形成细胞的炎症。
[0237]
用40mj/cm2uvb光照射人类原代角质形成细胞,然后用0.1%的seq id no:16的多肽处理24小时。通过elisa确定促炎细胞因子il-1a的水平。如图3所示,与未经处理的经uvb照射的角质形成细胞(图3;“a”)相比,用seq id no:16的多肽处理的经uvb照射的角质形成细胞(图3;“b”)表达较低水平的il-1α。截短的人类21型α1胶原具有抗氧化能力。
[0238]
使用氧自由基吸收能力(orac)测定法评估seq id no:16的多肽的抗氧化潜力。orac测定法是一种无细胞测定法,它使用荧光读数来测量产品的抗氧化能力。数据以trolox(维生素e)当量报告。如图4所示,seq id no:16的多肽的0.1%溶液具有相当于190μm trolox的抗氧化性能。截短的人类21型α1胶原增加经uvb光照射的角质形成细胞的细胞活力。
[0239]
为了进一步评估用seq id no:16的多肽处理对经uvb照射的角质形成细胞的作用,进行了照射前和照射后处理的实验。将人类原代角质形成细胞用0.1%的seq id no:16的多肽预处理24小时,用40mj/cm2uvb光照射,然后再次用0.1%的seq id no:16的多肽处理额外的24小时。使用mtt代谢比色测定法评价细胞活力。如图5所示,与未经这种处理的经uvb照射的角质形成细胞(图5;“a”)相比,用seq id no:16的多肽处理的经uvb照射的角质形成细胞(图5;“b”)显示出更高的细胞活力。实施例5.截短的人类21型胶原的人类临床研究截短的人类21型α1胶原的局部应用与面部皮肤弹性增加有关
[0240]
在临床研究中(n=15位受试者),受试者在使用无蛋白质的基础面部精华达1周的洗脱期后,使用含有0.1%seq id no:16的多肽的局部面部精华持续8周。seq id no:16的
多肽的局部应用与皮肤弹性增加有关,如通过皮肤弹性测试仪测量的。如图6所示,与基线(图6;“a”)相比,100%的受试者表现出改善,其中在2周(图6;“b”)和4周(图6;“c”)时的皮肤弹性增加。人类21型α1胶原的局部应用与面部皮肤胶原含量增加有关
[0241]
在临床研究中(n=15位受试者),受试者在使用无蛋白质的基础面部精华达1周的洗脱期后,使用含有0.1%seq id no:16的多肽的局部面部精华持续8周。seq id no:16的多肽的局部应用与皮肤胶原含量增加有关,如通过siascope测量的。如图7所示,与基线(图7;“a”)相比,皮肤胶原含量在2周(图7;“b”)和8周(图7;“c”)时增加。人类21型α1胶原的局部应用与面部皮肤发红减少有关
[0242]
在临床研究中(n=15位受试者),受试者在使用无蛋白质的基础面部精华达1周的洗脱期后,使用含有0.1%seq id no:16的多肽的局部面部精华持续8周。如图8所示,与基线(图8;“a”)相比,seq id no:16的多肽的局部应用与在4周(图8;“b”)和8周(图8;“c”)时的皮肤发红减少有关。人类21型α1胶原的局部应用与面部皱纹减少有关
[0243]
在临床研究中(n=15位受试者),受试者在使用无蛋白质的基础面部精华达1周的洗脱期后,使用含有0.1%seq id no:16的多肽的局部面部精华持续8周。如图9所示,与基线(图9;“a”)相比,seq id no:16的多肽的局部应用与在4周(图9;“b”)和8周(图9;“c”)时的皮肤皱纹减少有关。实施例6.在皮肤细胞上进行的截短的海蜇胶原的体外研究截短的海蜇胶原刺激皮肤细胞产生i型胶原蛋白
[0244]
进行了一系列体外实验以评估截短的海蜇胶原对人类皮肤成纤维细胞和角质形成细胞的作用。在用seq id no:5的多肽处理48小时后,评价了含有成纤维细胞和角质形成细胞的体外全厚度人类皮肤组织模型(mattek)的i型胶原分泌。然后冲洗组织模型,并与新鲜培养基再温育48小时(96小时时间点)。通过elisa分析培养上清液中的前胶原i型c-肽(i型胶原蛋白分泌总量的读数)。如图10所示,用seq id no:5的多肽处理的组织模型(图10;“a”)分泌的i型胶原的水平高于未处理的组织模型(图10;“b”)或用阳性对照维生素b3处理的组织模型(图10;“c”)。截短的海蜇胶原减少角质形成细胞在暴露于uvb光后的dna损伤
[0245]
在进一步的研究中,用25mj/cm2uvb光照射人类原代角质形成细胞,然后在具有0.03%的seq id no:5的多肽的培养基中温育过夜。从细胞中提取dna,并使用oxiselect uv诱导的dna损伤elisa试剂盒来分析胸腺嘧啶二聚体(dna损伤的指示物)的水平。如图11所示,与未处理的细胞(图11;“a”)相比,用seq id no:5的多肽处理的细胞(图11;“b”)显示出较低水平的腺嘧啶二聚体,因此dna损伤较少。截短的海蜇胶原增加经uvb光照射的角质形成细胞的细胞活力。
[0246]
将人类原代角质形成细胞用40mj/cm2uvb光照射,然后在具有0.03%的seq id no:5的多肽的培养基中温育48小时。使用mtt代谢比色测定法评价细胞活力。如图12所示,与未处理的经uvb照射的角质形成细胞(图12;“a”)相比,用seq id no:5的多肽处理的经uvb照射的角质形成细胞(图12;“b”)显示出更高的细胞活力。截短的海蜇胶原增加暴露于城市灰尘污染的角质形成细胞的细胞活力。
[0247]
为了测试针对城市灰尘的保护,将人类原代角质形成细胞用0.03%的seq id no:5的多肽预处理24小时,然后暴露于2mg/ml城市灰尘(nist 1649b)持续24小时。使用mtt代谢比色测定法评价细胞活力。如图13所示,与未处理的暴露于城市灰尘的角质形成细胞(图13;“a”)相比,用seq id no:5的多肽预处理的角质形成细胞(图13;“b”)在暴露于城市灰尘后显示出更高的细胞活力。截短的海蜇胶原减少经uvb光照射的角质形成细胞的炎症
[0248]
在采用体外全厚度人类皮肤组织模型(mattek)的进一步研究中,用300mj/cm2uvb光照射mattek组织模型,然后用0.01%的seq id no:5的多肽处理24小时。通过elisa确定促炎细胞因子il-1α的水平。如图14所示,与未经处理的经uvb照射的对照组织模型(图14;“b”)相比,用seq id no:5的多肽处理的组织模型(图14;“a”)表达较低水平的il-1α。截短的海蜇胶原具有抗氧化能力
[0249]
还通过orac测定法评价seq id no:5的多肽。如图15所示,seq id no:5的多肽的0.1%溶液具有相当于193μm trolox的抗氧化性能。实施例7.截短的海蜇胶原的人类临床研究截短的海蜇胶原的局部应用与面部皮肤水分增加有关
[0250]
在临床研究中(n=18位受试者),受试者使用含有0.05%的seq id no:5的多肽的局部面霜持续2周。如图16所示,与基线(图16;“a1”)相比,seq id no:5的多肽的局部应用与1周(图16;“a2”)和2周(图16;“a3”)时的皮肤水合度增加有关。与在基线(图16;“b1”)的海洋胶原的局部应用相比,在1周(图16;“b2”)和2周(图16;“b3”)时,seq id no:5的多肽的局部应用也表现出皮肤水合度增加。截短的海蜇胶原的局部应用与面部皮肤弹性增加有关在临床研究中(n=18位受试者),受试者使用含有0.05%的seq id no:5的多肽的局部面霜持续2周。如图17所示,与基线(图17;“a”)相比,seq id no:5的多肽的局部应用与1周(图17;“b”)和2周(图17;“c”)时的皮肤弹性增加有关,皮肤弹性使用皮肤弹性测试仪测量。
[0251]
本文公开的实施方案在不背离本文广泛描述和下文要求保护的结构、方法或其他特征的情况下,可以以其他特定形式来实施。所描述的实施方案在所有方面仅被认为是说明性的,而不是限制性的。落在权利要求的等同含义和范围内的所有改变均应包含在权利要求的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1