肺结节的分类模型的训练方法与流程
本公开大体涉及一种肺结节的分类模型的训练方法。
背景技术:
作为世界上最常见和死亡率最高的恶性肿瘤,肺癌在临床中仍缺乏有效的早期筛查与诊断手段。
目前,通常使用低剂量螺旋ct(lowdosecomputedtomography,ldct)对高危人群进行筛查。同时,目前常用血清标志物、痰液检查、气管镜检查等临床手段作为临床确诊肺癌的辅助手段。
然而,对于不确定的肺小结节,ldct筛查假阳性率高达96.4%,且具有存在辐射、灵敏度特异度受限、无法进行良恶性判断等诸多局限。对于血清标志物、痰液检查、气管镜检查等临床手段,均存在假阳性率高和操作繁琐等局限性。
技术实现要素:
本公开是鉴于上述的状况而提出的,其目的在于提供一种用于肺结节分类的具有高灵敏度和高特异性的分类模型的训练方法。
为此,本公开的提供了从多个具有肺结节的肺结节患者的血液样本中获取所述肺结节患者的tcr免疫组库,获取与所述肺结节患者相匹配的个人信息和与肺结节相关的病理信息,所述个人信息包括肺结节患者的年龄、性别、吸烟史、以及疾病史中的至少一种,所述病理信息包括肺结节患者的结节数量、结节大小、以及结节类型中的至少一种;利用多重聚合酶链式反应对tcr免疫组库中的目标基因进行扩增,对扩增后的目标基因进行测序并获得二代高通量测序序列,基于所述二代高通量测序序列获得目标基因的dna序列以及与所述dna序列对应的序列类型,并根据所述dna序列和所述序列类型获得多样性指数信息;
基于数据样本信息形成训练集和测试集,所述数据样本信息包括所述个人信息、所述病理信息、以及所述多样性指数信息,在所述分类模型的训练过程中,利用所述训练集获得损失函数,所述损失函数包括残差平方和项以及l1正则项,利用损失函数对所述分类模型进行训练,利用测试集对所述分类模型进行测试。
由此,能够收集多个具有肺结节的肺结节患者的个人信息和病理信息。并且能够对肺结节患者的与肺结节相关的基因序列进行分析以获得肺结节患者的多样性指数信息。进而能够利用个人信息、病理信息以及多样性指数信息形成训练集和测试集。通过训练集和包括残差平方和项和l1正则项的损失函数对分类模型进行训练,能够获得具有高灵敏度和高特异性的分类模型,并且能够利用测试集对分类模型进行测试以保证分类模型高灵敏度和高特异性。
另外,在本公开所涉及的训练方法中,可选地,在所述数据样本信息中进行随机抽样以获得所述训练集和所述测试集。在这种情况下,能够充分利用数据样本信息以获得训练集和测试集,同时能够提高分类模型的泛用性。
另外,在本公开所涉及的训练方法中,可选地,还包括利用测试集对所述分类模型进行测试获得的测试结果,利用所述测试结果获得roc曲线与坐标轴围成的面积、灵敏度、特异性、准确率,并对所述分类模型进行评估。在这种情况下,能够从多个角度体现分类模型的分类效果。
另外,在本公开所涉及的训练方法中,可选地,所述数据样本信息分为数字信息和文字信息,所述数字信息包括结节数量和多样性指数,所述文字信息包括吸烟史、结节类型和结节是否有毛刺。在这种情况下,能够获得多种数据类型的数据样本信息,并且能够获得各种数据类型的数据样本信息与肺结节分类的关系。
另外,在本公开所涉及的训练方法中,可选地,所述多样性指数信息用于反映序列类型的克隆多样性,所述多样性指数信息包括香农指数。在这种情况下,能够利用香农指数反映序列类型的多样性,从而能够获得香农指数与肺结节分类的关系。
另外,在本公开所涉及的训练方法中,可选地,所述二代高通量测序序列包括双端测序序列和基于所述双端测序序列获得的单端序列,对扩增后的tcr免疫组库进行测序以获得多个双端测序序列,根据所述多个双端测序序列的重复区域将所述多个双端测序序列合并成所述单端序列。在这种情况下,能够利用多个双端测序序列合并以获得更完整的序列。
另外,在本公开所涉及的训练方法中,可选地,所述目标基因为t细胞抗原受体基因,利用多重聚合酶链式反应对t细胞抗原受体基因的cdr3区域进行扩增。在这种情况下,能够对tcr免疫组库中特定片段的进行扩增,进而能够对tcr免疫组库中特定片段进行测序。
另外,在本公开所涉及的训练方法中,可选地,通过对比所述单端序列与v、d、j三个基因序列,获得所述cdr3区域的dna序列和cdr3区域的类型。在这种情况下,能够对tcr免疫组库中特定片段的进行扩增,进而能够对tcr免疫组库中特定片段进行测序,并且由于cdr3区域负责直接与mhc所呈递的多肽结合,因此能够通过对tcr免疫组库中的与cdr3区域相匹配的片段进行扩增以获得与t细胞抗原受体的多样性相关性最高的基因片段。
另外,在本公开所涉及的训练方法中,可选地,所述肺结节的结节最长径在6mm至30mm范围内。在这种情况下,能够利用不同程度的肺结节患者对分类模型进行训练。
另外,在本公开所涉及的训练方法中,可选地,利用所述测试结果或对所述分类模型的输入特征的数量和类型进行调整。在这种情况下,能够适当地调整输入特征的数量,并且能够优化分类模型。
根据本公开,能够提供一种用于肺结节分类的具有高灵敏度和高特异性的分类模型的训练方法。
附图说明
现在将仅通过参考附图的例子进一步详细地解释本公开,其中:
图1是示出了本公开示例所涉及的肺结节的分类模型的训练方法的应用场景示意图。
图2是示出了本公开示例所涉及的肺结节的分类模型的训练方法的流程示意图。
图3是示出了本公开示例所涉及的训练方法中获取数据样本信息的流程图。
图4是示出了本公开示例所涉及的获得单端序列的示意图。
图5是示出了本公开示例所涉及的cdr3的示意图。
图6是示出了本公开示例所涉及的肺结节的分类模型的结构框图。
具体实施方式
以下,参考附图,详细地说明本公开的优选实施方式。在下面的说明中,对于相同的部件赋予相同的符号,省略重复的说明。另外,附图只是示意性的图,部件相互之间的尺寸的比例或者部件的形状等可以与实际的不同。需要说明的是,本公开中的术语“包括”和“具有”以及它们的任何变形,例如所包括或所具有的一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可以包括或具有没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。本公开所描述的所有方法可以以任何合适的顺序执行,除非在此另有指示或者与上下文明显矛盾。
本公开所涉及的肺结节的分类模型的训练方法也可以简称为训练方法。本公开所涉及的训练方法是一种针对肺结节的分类模型的练方法,并且能够通过该训练方法获得高灵敏度和高特异性的肺结节的分类模型,以下结合附图进行详细描述本公开。
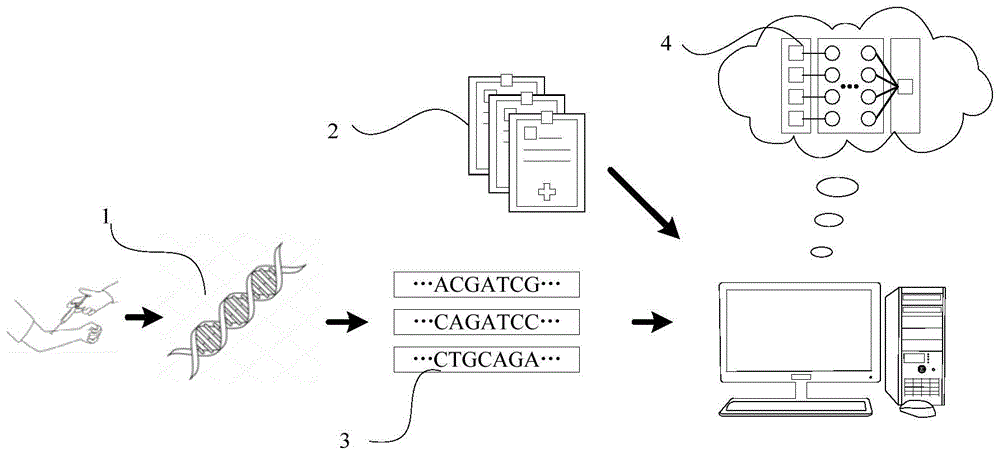
图1是示出了本公开示例所涉及的肺结节的分类模型的训练方法的应用场景示意图。
在一些示例中,如图1所示,可以从多个具有肺结节的肺结节患者的血液样本中获取与肺结节相关的tcr免疫组库1,测序后获得二代高通量测序序列3,获取与肺结节患者相匹配的临床信息2,其中临床信息2包括个人信息和与肺结节相关的病理信息。
在一些示例中,tcr免疫组库1可以是指t细胞抗原受体(tcellreceptor,tcr)免疫组库。
在一些示例中,根据收集到的来自多个肺结节患者的tcr免疫组库1、个人信息以及病理信息形成训练集,并利用训练集对分类模型4进行训练。在这种情况下,能够提高分类模型4的泛用性,并且能够利用tcr免疫组库1、个人信息等信息和分类模型4获得肺结节的分类结果。
在一些示例中,可以利用损失函数对分类模型4进行训练。这种情况下,能够不断地迭代并优化分类模型4。在一些示例中,损失函数可以包括残差平方和项和l1正则项。这种情况下,能够降低相关性较小的输入参数对结构造成影响,进而能够提高分类模型4的灵敏度和特异性。
在一些示例中,根据收集到的来自多个肺结节患者的tcr免疫组库1、个人信息以及病理信息形成测试集,并利用测试集对分类模型4进行训练。在这种情况下,能够测试分类模型4的灵敏度、特异性和准确性。
由此,能够收集多个具有肺结节的肺结节患者的个人信息和病理信息。并且能够对肺结节患者的与肺结节相关的基因序列进行分析以获得肺结节患者的多样性指数信息。进而能够利用个人信息、病理信息以及多样性指数信息形成训练集和测试集。通过训练集和包括残差平方和项和l1正则项的损失函数对分类模型4进行训练,能够获得具有高灵敏度和高特异性的分类模型4,并且能够利用测试集对分类模型4进行测试以保证分类模型4高灵敏度和高特异性。
在一些示例中,分类模型4可以基于输入分类模型4的数据获得肺结节的分类。在一些示例中,输入分类模型4的数据可以是训练集或测试集。在一些示例中,肺结节的分类结果可以包括良性结节和恶性结节。在一些示例中,肺结节的分类结果可以包括实性结节和实性结节非实性结节。在一些示例中,肺结节的分类结果可以包括肺结节的恶性几率。
图2是示出了本公开示例所涉及的肺结节的分类模型4的训练方法的流程示意图。
在一些示例中,如图2所示,本公开示例所涉及的肺结节的分类模型4的训练方法包括:获取数据样本信息(步骤s100);形成训练集和验证集(步骤s200);利用训练集训练分类模型4(步骤s300);利用测试集测试分类模型4(步骤s400);
在步骤s100中,可以获取数据样本信息。
图3是示出了本公开示例所涉及的训练方法中获取数据样本信息的流程图。
在一些示例中,如图3所示,获取数据样本信息可以包括:选定第一预设数量的肺结节患者(步骤s101);获取肺结节患者的外周血样本(步骤s102);提取tcr免疫组库1(步骤s103);对tcr免疫组库1进行扩增并构建扩增后的tcr免疫组库1(步骤s104);对扩增后的tcr免疫组库1进行测序(步骤s105);对测序数据进行分析以获得多样性指数信息(步骤s106);
在一些示例中,数据样本信息可以来自多个的肺结节患者。在步骤s101中,可以选定第一预设数量的肺结节患者。在这种情况下,能够获得多个肺结节患者的信息,从而能够利用来自多个的肺结节患者的信息输入分类模型4并获得肺结节患者肺结节的分类。
在一些示例中,第一预设数量可以不小于20。例如第一预设数量可以为20、30、40、50、70、80、100、1000、10000等。在这种情况下,能够根据实际情况选择合适的第一预设数量实现训练方法,并且在条件允许的情况下能够利用大量的数据对分类模型4进行训练以提高分类模型4的分类效果。
在一些示例中,选定的肺结节患者可以是具有肺结节的患者。在这种情况下,能够针对肺结节患者的肺结节进行分类。
在一些示例中,选定的肺结节患者可以是来自同一个医疗机构的肺结节患者。在一些示例中,肺结节患者可以是来自同一区域的肺结节患者。在这种情况下,能够获得针对某一个医疗机构或区域的肺结节患者的肺结节进行分类的分类模型4。
在一些示例中,选定的肺结节患者可以是来自各个医疗机构或各个区域的肺结节患者。在这种情况下,能够获得针对不同来源的肺结节患者的肺结节进行分类的分类模型4。
在一些示例中,选定的肺结节患者可以是性别相同的肺结节患者。在一些示例中,选定的肺结节患者可以是年龄在20-60间的肺结节患者。在这种情况下,能够获得某一种类型的肺结节患者进行分析。但本公开不限于此,选定的肺结节患者可以是通过随机选取获得的肺结节患者。在这种情况下,能够使数据样本信息具有多样性和普遍性。
在一些示例中,选定的肺结节患者的肺结节的结节最长径可以在2mm至35mm范围内。优选的,肺结节患者的肺结节的结节最长径6mm至30mm范围内。在这种情况下,能够利用不同结节大小的肺结节患者对分类模型4进行训练。
在一些示例中,数据样本信息可以包括多个肺结节患者的个人信息、病理信息、以及多样性指数信息。在这种情况下,能够从多个角度获得肺结节患者的信息。
在一些示例中,个人信息可以包括肺结节患者的年龄、性别、吸烟史、以及疾病史中的至少一种。在一些示例中,个人信息还可以包括肺结节患者的生活环境、职业、家族病史中的至少一种。在这种情况下,能够利用分类模型4获得各种个人信息与肺结节的分类的相关性。
在一些示例中,病理信息可以包括肺结节患者的肺结节的结节数量、结节大小、结节是否具有毛刺、以及结节类型中的至少一种。在一些示例中,病理信息还可以包括结节形状、结节密度、结节的变化、发现结节的时间等肺结节的相关信息。在这种情况下,能够获取大量的关于肺结节的信息,从而能够提高分类模型4的维度,获得各种病理信息与肺结节的分类的相关性。
在一些示例中,病理信息可以通过电子计算机断层扫描(computedtomography,ct)获得。
在一些示例中,多样性指数信息也可与t细胞抗原受体(tcellreceptor,tcr)相对应的基因序列相关(后续描述)。在这种情况下,能够获得与t细胞抗原受体相对应的基因序列相关的多样性指数信息与肺结节的分类的相关性。
在一些示例中,数据样本信息还可以包括肺结节患者的肺结节的检测结果。在一些示例中,肺结节患者的肺结节的检测结果可以是金标准的检测结果。在一些示例中,检测结果可以为对肺结节进行病理学检查获得的分类结果。
在一些示例中,数据样本信息可以分为数字信息和文字信息。在一些示例中,数字信息包括可以结节数量和多样性指数等可以用数字进行描述的信息。在一些示例中,文字信息包括吸烟史、结节类型、和/或结节是否有毛刺等可以用文字进行描述的信息。在这种情况下,能够获得多种数据类型的数据样本信息,并且能够获得各种数据类型的数据样本信息与肺结节分类的关系。
在步骤s102中,可以获取肺结节患者的外周血样本。
在一些示例中,可以利用真空采血法、皮肤采血法、或静脉采血法等采血方法获取肺结节患者的外周血样本。在这种情况下,能够根据选择获取肺结节患者的外周血样本的方法。
在步骤s103中,可以提取tcr免疫组库1。在一些示例中,可以利用血液样本获得tcr免疫组库1。在一些示例中,血液样本可以为肺结节患者的外周血样本。
在一些示例中,可以利用血液样本获得(基因组dna文库)gdna文库。在一些示例中,gdna文库可以包括tcr免疫组库1。
在一些示例中,可以利用ctab法、玻璃珠法、超声波法、研磨法、冻融法、异硫氰酸胍法、碱裂解法等方法提取tcr免疫组库1。
在步骤s104中,可以利用多重聚合酶链式反应(多重pcr)对tcr免疫组库1进行扩增。在一些示例中,多重pcr可以是在同一pcr反应体系里加上二对以上引物,同时扩增出多个核酸片段的pcr反应。
在一些示例中,可以利用聚合酶链反应(pcr)对tcr免疫组库1进行扩增。在这种情况下,能够以一种简单、廉价、可靠的方式复制靶标dna片段。在一些示例中,还可以利用连接酶链反应(lcr)对tcr免疫组库1进行扩增。
在一些示例中,目标基因可以为为t细胞抗原受体基因,可以利用多重聚合酶链式反应对t细胞抗原受体基因的cdr3区域进行扩增。在这种情况下,能够对tcr免疫组库中特定片段的进行扩增,进而能够对tcr免疫组库中特定片段进行测序。
在一些示例中,t细胞抗原受体可以包括α亚基和β亚基两个亚基(肽链),每个亚基可以包括第一互补决定区(cdr1)、第二互补决定区(cdr2)和第三互补决定区(cdr3)三个互补决定区(complementaritydeterminingregions,cdr)。在一些示例中,t细胞抗原受体的互补决定区的氨基酸组合可以具有高度的多样性。在这种情况下,能够形成巨大的tcr免疫组库(immunerepertoire,ir)。
在一些示例中,可以对tcr免疫组库1中的与cdr3区域相匹配的片段进行扩增。在一些示例中,可以利用多重聚合酶链式反应对tcr免疫组库1中的cdr3区域(后续描述)进行扩增。在这种情况下,能够对tcr免疫组库1中特定片段的进行扩增,进而能够对tcr免疫组库1中特定片段进行测序,并且由于cdr3区域负责直接与主要组织相容性复合体(majorhistocompatibilitycomplex,mhc)所呈递的多肽结合,因此能够通过对tcr免疫组库1中的与cdr3区域相匹配的片段进行扩增以获得与t细胞抗原受体的多样性相关性最高的基因片段。
在步骤s105中,可以对扩增后的tcr免疫组库1进行测序。
在一些示例中,可以利用基因测序仪对扩增后的tcr免疫组库1进行测序。在一些示例中,可以利用基因测序仪对扩增后的tcr免疫组库1进行二代高通量测序。在这种情况下,能够提高测序效率。
在一些示例中,可以使用平板型电泳基因测序仪对扩增后的tcr免疫组库1进行测序。在一些示例中,可以使用毛细管电泳基因测序仪对扩增后的tcr免疫组库1进行测序。在一些示例中,可以使用novaseq6000测序仪、nextseq550测序仪、或mgi2000测序仪对对扩增后的tcr免疫组库1进行测序。
在步骤s106中,可以对测序数据进行分析以获得多样性指数信息。
在一些示例中,可以对测序数据进行过滤。例如可以过滤测序数据中的低质量数据。
在一些示例中,可以利用测序数据质控软件对测序结果中的测序数据进行过滤。在这种情况下,能够有效并便捷地提高测序数据的质量。
在一些示例中,可以过滤质量较差的序列。具体而言,可以先设定质量阈值和比例阈值,将小于质量阈值的碱基认定为低质量的碱基,若一个序列中的低质量的碱基超过了比例阈值,则可以将该序列认定为低质量的序列,并过滤该序列。在这种情况下,能够过滤质量较差的序列。
在一些示例中,可以过滤低复杂度的序列。具体而言,可以依次比较序列中前后相连的两个碱基,并统计前后相连的两个碱基不同的次数,利用前后相连的两个碱基不同的次数除以长度指数得到序列的复杂度。并过滤复杂度小于复杂度阈值的序列。在一些示例中,长度指数与该序列的长度线性相关。在这种情况下,能够过复杂度较低的序列。
在一些示例中,可以根据序列长度过滤序列。在一些示例中,可以过滤测序数据中的adapter序列。在一些示例中,可以过滤reads两端的部分碱基。
在一些示例中,可以利用fastp、fastqc、fterqc、soapnuke、cutadapt、trimmomatic等软件对测序结果中的测序数据进行过滤。
图4是示出了本公开示例所涉及的获得单端序列的示意图。
在一些示例中,可以对扩增后的tcr免疫组库1进行测序并获得二代高通量测序序列3。在一些示例中,二代高通量测序序列3可以是通过二代高通量测序技术获得的序列。
在一些示例中,二代高通量测序序列3可以包括双端测序序列32和基于所述双端测序序列32获得的单端序列33。
在一些示例中,对测序数据进行测序后,可以获得多个双端测序序列32,可以利用多个双端测序序列32合并成单端序列33。换言之,可以对扩增后的tcr免疫组库1进行测序以获得多个双端测序序列32,根据多个双端测序序列32的重复区域将多个双端测序序列32合并成单端序列33。在这种情况下,能够利用多个双端测序序列32合并以获得更完整的序列。
在一些示例中,双端测序序列32可以是指通过双端测序获得的测序序列。
在一些示例中,如图4所示,可以从a方向和b方向对tcr免疫组库1中的基因片段31进行测序并获得两个双端测序序列32(双端测序序列32a和双端测序序列32b),根据两个双端测序序列32的重复区域321将双端测序序列32a和双端测序序列32b合并成单端序列33。
在一些示例中,可以根据多个双端测序序列32的重复区域对多个双端测序序列32进行组装以获得更长的序列。
在一些示例中,可以从tcr免疫组库1中的dna的两端进行测序并获得两个读长(reads)。在这种情况下,能够有助于后期的序列组装。
在一些示例中,可以基于单端序列获得目标基因的dna序列以及与目标基因的dna序列对应的序列类型。
在一些示例中,可以对单端序列进行分析以获得目标基因的dna序列以及与目标基因的dna序列对应的序列类型。在一些示例中,目标基因可以是t细胞抗原受体(tcr)基因。在一些示例中,利用多重聚合酶链式反应对t细胞抗原受体基因的cdr3区域进行扩增。在一些示例中,单端序列可以通过对比预设基因获得。在一些示例中,预设基因可以是与t细胞抗原受体相关的基因片段。在这种情况下,能够针对t细胞抗原受体进行分析,并且能够通过t细胞抗原受体克隆序列获得免疫组库多样性。
在一些示例中,预设基因可以是与t细胞抗原受体中的cdr3相关的基因。在一些示例中,预设基因可以是位于或部分位于t细胞抗原受体中的cdr3的基因。在这种情况下,能够通过对比单端序列与cdr3相关的基因,以获得cdr3区域的类型。
图5是示出了本公开示例所涉及的cdr3的示意图。
在一些示例中,如图5所示,cdr3可以包括v、d、j三个基因。具体而言,cdr3包括d基因和部分的v基因和j基因。
在一些示例中,预设基因可以包括v、d、j、c(未图示)基因中的一个或多个。在一些示例中,预设基因可以为v、d、j基因。在这种情况下,由于v、d、j三个基因的位于或部分位于cdr3,由此能够通过对比到v、d、j三个基因以获得cdr3区域的dna序列和cdr3区域的类型,进而能够根据cdr3区域的dna序列和cdr3区域的类型的多样性获得多样性指数信息。
在一些示例中,在对单端序列进行分析以获得目标基因的dna序列以及与目标基因的dna序列对应的序列类型后,可以并根据目标基因的dna序列和序列类型获得多样性指数信息。在一些示例中,可以利用统计学方法对目标基因的dna序列进行分析以获得多样性指数信息。
在一些示例中,多样性指数信息可以用于反映序列类型的多样性。在这种情况下,能够利用多样性指数信息映序列类型的多样性,从而能够将多样性指数信息输入分类模型4并获得肺结节的分类结果。
在一些示例中,多样性指数信息包括香农指数。在这种情况下,能够利用香农指数反映序列类型的克隆多样性,从而能够获得香农指数与肺结节分类的关系。
在一些示例中,香农指数可以通过以下公式获得:
其中h为香农指数,n为序列类型的数量,k表示第k种序列类型,pk表示第k种序列类型的基因序列的数量在全部基因序列的数量占比。
在步骤s200中,可以基于数据样本信息形成训练集和测试集。
在一些示例中,可以在数据样本信息中进行随机抽样以获得训练集和测试集。在这种情况下,能够充分利用数据样本信息以获得具有随机性的训练集和测试集,同时能够提高分类模型4的泛用性。
在一些示例中,还可以利用系统抽样或分层抽样的方法对数据样本信息进行抽样以获得训练集和测试集。在这种情况下,能够使训练集和测试集具有针对性,从而能够提高分类模型4针对某些情况的特异性、灵敏度和准确性。
在一些示例中,可以利用交叉验证的方法形成训练集和测试集。具体而言,可以将数据样本信息分成多个组合,并将多个组合中的一个组合作为测试集,剩余的组合作为训练集,利用训练集对分类模型4进行训练,利用测试集对分类模型4进行测试后将多个组合中的另一个组合作为测试集,剩余的组合作为训练集,直至每个样本都被当做一次测试集。
在一些示例中,训练集的肺结节患者人数可以与测试集的肺结节患者人数大致相同。在一些示例中,可以将在数据样本信息平均分成肺结节患者的数量大致相同的训练集和测试集。例如,若数据样本信息具有43名肺结节患者,则可以利用43名肺结节患者中的22名肺结节患者归类为训练集,利用43名肺结节患者中的剩下的21名肺结节患者归类为测试集。
在一些示例中,如上所述,训练集可以用于对分类模型4进行训练并获得训练后的分类模型4,测试集可以用于对训练后的分类模型4进行测试并获得该分类模型4的特异性、灵敏度和准确性。
在一些示例中,还可以利用数据样本信息形成验证集。在一些示例中,验证集用于对训练后的分类模型4进行验证并对分类模型4进行调整。在这种情况下,能够利用验证集对分类模型4进行调整,从而能够提高分类模型4的泛用性,减少分类模型4过拟合现象的发生。
如上所述,数据样本信息可以包括数字信息和文字信息。在一些示例中,将文字信息输入到分类模型4时,可以把文字信息转换成数字。例如对于肺结节患者的吸烟史,可以利用数字1表示有吸烟史,利用数字0表示有没有吸烟史。在一些示例中,还可以利用数字表示肺结节患者的吸烟史时间和/或停止吸烟的时间。在一些示例中,也可以利用数字表示金标准的检测结果。在这种情况下,能够将文字信息转换成更容易被分类模型4处理的数字。
在一些示例中,可以对数据样本信息的数据进行归一化。在这种情况下,能够降低各种类型的数据的数量级的差距。
在一些示例中,分类模型4可以为基于机器学习的分类模型4。以下以基于人工神经网络的分类模型4为例解释分类模型4的原理,但是本公开不限于此,在一些示例中,分类模型4也可以为基于决策树、随机森林、贝叶斯学习的分类模型4。
图6是示出了本公开示例所涉及的肺结节的分类模型4的结构框图。
在一些示例中,如图6所示,分类模型44可以包括输入特征411、作为节点的神经元421,与人工神经网络中的神经元相对应的权重(未图示)、以及传递函数(未图示)。在一些示例中,分类模型44可以包括用于输入层41、中间层42和输出层43。
在一些示例中,输入层41可以用于接收输入特征411,中间层可以用于对输入特征411进行处理并计算分类值431,输出层43可以用于输出分类值431。
在一些示例中,分类值431可以用于表示分类结果。具体而言,可以设置分类阈值,若分类值431大于分类阈值,则可以认为该肺结节患者的肺结节为恶性肺结节,若分类值小于分类阈值,则可以认为该肺结节患者的肺结节为良性肺结节。
在一些示例中,可以根据分类值的计算结果设定分类阈值。例如,分类值的范围为0至1,则分类阈值可以取值为0.5。在一些示例中,可以分类值的计算结果和金标准的检测结果设定分类阈值。例如,分类值大于0.7的肺结节患者的肺结节为恶性肺结节,分类值大于0.7的肺结节患者的肺结节为良性肺结节,则分类阈值可以取值为0.7。
在一些示例中,如上所述,可以利用损失函数对分类模型4进行训练。具体而言,将训练集中的数据作为输入特征输入分类模型4时,可以利用分类模型4的中间层计算分类值,并且基于分类值和金标准的检测结果计算损失函数,并利用反向传播算法调整权重。在这种情况下,能够利用损失函数对分类模型4进行训练,从而能够获得高准确性的分类模型4。
在一些示例中,损失函数可以包括残差平方和项以及正则项。在这种情况下,能够利用残差平方和项可以评估分类模型4的准确性,并且能够利用正则项提高分类模型4的泛用性。
在一些示例中,损失函数的表达式可以为:
其中l为损失函数,m为训练集中肺结节患者的数量,i表示第i个肺结节患者,y(i)表示第i和肺结节患者的金标准的检测结果,j表示第j个输入特征,θj表示第j个输入特征的系数,xj表示第j个输入特征的值,λ表示正则项系数。
在一些示例中,正则项可以包括l1正则项和l2正则项中的至少一项。在一些示例中,可以利用lasso、岭回归、elasticnet、套索回归等回归方法获得分类模型4。在这种情况下,能够根据实际的情况选择不同的回归方法获得分类模型4。
在一些示例中,可以利用分类结果对输入特征的数量和类型进行调整。具体而言,可以根据分类结果的分类值获得输入特征的特征权重,并根据特征权重对输入特征进行排序,去除特征权重较小的特输入特征,并保留特征权重较大的输入特征。在这种情况下,能够适当地调整输入特征的数量,并且能够优化分类模型4。
在步骤s400中,可以利用测试集测试分类模型4。
在一些示例中,可以将测试集作为输入特征并获得的测试结果。在一些示例中,可以利用该测试结果对分类模型4进行评估。具体而言,可以利用测试结果获得接受者操作特性曲线(receiveroperatingcharacteristiccurve,roc曲线)与坐标轴围成的面积(areaundercurve,auc)、灵敏度、特异性、准确率中的至少一个。在一些示例中,可以利用接auc、灵敏度、特异性、准确率对分类模型4进行评估。在这种情况下,能够从多个角度地体现分类模型4的分类效果。
在一些示例中,灵敏度可以为真阳性人数/(真阳性人数+假阴性人数)。在这种情况下,能够利用灵敏度评估分类模型4正确识别恶性肺结节的能力。
在一些示例中,特异度可以为真阴性人数/(真阴性人数+假阳性人数)。在这种情况下,能够利用灵敏度评估分类模型4正确识别良性肺结节的能力。
在一些示例中,准确率可以为(真阳性人数+真阴性人数)/(真阳性人数+假阴性人数+真阴性人数+假阳性人数)。在这种情况下,能够利用准确率评估分类模型4正确分类肺结节的能力。
在一些示例中,分类模型4可以利用测试结果或对分类模型4的输入特征的数量和类型进行调整。具体而言,分类模型4可以基于auc、灵敏度、特异性、或准确率中的至少一个调整输入特征。例如,若利用测试集测试分类模型4后发现auc、灵敏度、特异性、或准确率中的至少一个小于预设值,则可以调整输入特征的数量和/或类型,并重新利用训练集训练分类模型4。在这种情况下,能够适当地调整输入特征的数量,并且能够优化分类模型4。
在分类模型4的训练过程中,利用训练集获得损失函数,损失函数包括残差平方和项以及l1正则项,利用损失函数对分类模型4进行训练,利用测试集对分类模型4进行测试。
此外,本公开的示例描述的应用场景是为了更加清楚的说明本公开的技术方案,并不构成对于本公开提供的技术方案的限定。
虽然以上结合附图和实施方式对本发明进行了具体说明,但是可以理解,上述说明不以任何形式限制本发明。本领域技术人员在不偏离本发明的实质精神和范围的情况下可以根据需要对本发明进行变形和变化,这些变形和变化均落入本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!