基于人工智能的碱基检出器的硬件执行和加速的制作方法
1.所公开的技术涉及人工智能类型计算机和数字数据处理系统以及对应数据处理方法和用于仿真智能的产品(即,基于知识的系统、推断系统和知识采集系统);并且包括用于不确定性推断的系统(例如,模糊逻辑系统)、自适应系统、机器学习系统和人工神经网络。具体地,所公开的技术涉及将深度神经网络诸如深度卷积神经网络用于分析数据。
2.优先权申请
3.此pct申请要求2020年2月20日提交的标题为“multi-cycle cluster based real time analysis system”的美国临时专利申请号62/979,412(代理人案号illm 1020-1/ip-1866-prv)和2021年2月15日提交的标题为“multi-cycle cluster based real time analysis system”的美国专利申请号17/176,147(代理人案号illm1020-2/ip-1866-us)的优先权和权益。据此将这些优先权申请以引用方式并入,即如同在本文完整示出一样,以用于所有目的。
4.此pct申请要求2020年2月20日提交的标题为“knowledge distillation-based compression of artificial intelligence-based base caller”的美国临时专利申请号62/979,385(代理人案号illm 1017-1/ip-1859-prv)和2021年2月15日提交的标题为“knowledge distillation-based compression of artificial intelligence-based base caller”的美国专利申请号17/176,151(代理人案号illm 1017-2/ip-1859-us)的优先权和权益。据此将这些优先权申请以引用方式并入,即如同在本文完整示出一样,以用于所有目的。
5.此pct申请要求2020年8月28日提交的标题为“detecting and filtering clusters based on artificial intelligence-predicted base calls”的美国临时专利申请号63/072,032(代理人案号illm 1018-1/ip-1860-prv)的优先权和权益。据此将这些优先权申请以引用方式并入,即如同在本文完整示出一样,以用于所有目的。
6.此pct申请要求2020年2月20日提交的标题为“data compression for artificial intelligence-based base calling”的美国临时专利申请号62/979,411(代理人案号illm 1029-1/ip-1964-prv)的优先权和权益。据此将这些优先权申请以引用方式并入,即如同在本文完整示出一样,以用于所有目的。
7.此pct申请要求2020年2月20日提交的标题为“squeezing layer for artificial intelligence-based base calling”的美国临时专利申请号62/979,399(代理人案号illm 1030-1/ip-1982-prv)的优先权和权益。据此将这些优先权申请以引用方式并入,即如同在本文完整示出一样,以用于所有目的。
8.文献并入
9.以下文献以引用方式并入,即如同在本文完整示出一样:
10.2020年2月20日提交的标题为“artificial intelligence-based base calling of index sequences”的美国临时专利申请号62/979,384(代理人案号illm 1015-1/ip-1857-prv);
11.2020年2月20日提交的标题为“artificial intelligence-based many-to-many base calling”的美国临时专利申请号62/979,414(代理人案号illm 1016-1/ip-1858-prv);
12.2020年3月20日提交的标题为“training data generation for artificial intelligence-based sequencing”的美国非临时专利申请号16/825,987(代理人案号illm 1008-16/ip-1693-us);
13.2020年3月20日提交的标题为“artificial intelligence-based generation of sequencing metadata”的美国非临时专利申请号16/825,991(代理人案号illm 1008-17/ip-1741-us);
14.2020年3月20日提交的标题为“artificial intelligence-based base calling”的美国非临时专利申请号16/826,126(代理人案号illm 1008-18/ip-1744-us);
15.2020年3月20日提交的标题为“artificial intelligence-based quality scoring”的美国非临时专利申请号16/826,134(代理人案号illm 1008-19/ip-1747-us);以及
16.2020年3月21日提交的标题为“artificial intelligence-based sequencing”的美国非临时专利申请号16/826,168(代理人案号illm 1008-20/ip-1752-prv-us)。
背景技术:
17.本部分中讨论的主题不应仅因为在本部分中有提及就被认为是现有技术。类似地,在本部分中提及的或与作为背景技术提供的主题相关联的问题不应被认为先前在现有技术中已被认识到。本部分中的主题仅表示不同的方法,这些方法本身也可对应于受权利要求书保护的技术的具体实施。
18.深度神经网络是一种人工神经网络,其使用多个非线性且复杂的变换层来对高级特征进行连续建模。深度神经网络经由反向传播提供反馈,该反向传播携带观察输出和预测输出之间的差异以调整参数。深度神经网络随着大型训练数据集的可用性、并行与分布式计算的能力以及复杂的训练算法而演进。深度神经网络已促进了许多领域诸如计算机视觉、语音识别和自然语言处理的重大进步。
19.卷积神经网络(cnn)和递归神经网络(rnn)是深度神经网络的组成部分。卷积神经网络在具有包括卷积层、非线性层和池化层的架构的图像识别方面尤其成功。递归神经网络被设计成利用输入数据的顺序信息,并且具有在构建模块如感知子、长短期记忆单元和门控递归单元之间循环连接。此外,已提出了针对有限情境的许多其他新兴深度神经网络,诸如深度时空神经网络、多维递归神经网络和卷积自编码器。
20.训练深度神经网络的目标是优化每层中的权重参数,这将较简单的特征逐渐组合成复杂的特征,使得可以从数据中学习到最合适的分层表示。优化过程的单个循环按以下步骤来进行。首先,在给定训练数据集的情况下,前向传递顺序地计算每层中的输出并将函数信号通过网络向前传播。在最终输出层中,目标损失函数测量推断的输出与给定标记之间的误差。为了使训练误差最小化,向后传递使用链规则来反向传播误差信号并计算相对于整个神经网络中的所有权重的梯度。最后,基于随机梯度下降使用优化算法来更新权重参数。虽然批量梯度下降针对每个完整的数据集执行参数更新,但随机梯度下降通过针对
每个小数据示例集执行更新来提供随机逼近。若干优化算法源自随机梯度下降。例如,adagrad和adam训练算法执行随机梯度下降,同时分别基于每个参数的梯度的更新频率和动量自适应地修改学习速率。
21.深度神经网络训练中的另一个核心元素是正则化,该正则化是指旨在避免过度拟合并因此实现良好泛化性能的策略。例如,权重衰减将惩罚因子添加到目标损失函数,使得权重参数收敛到较小绝对值。丢弃在训练期间从神经网络随机移除隐藏单元,并且可被认为是可能子网络的集成。为了增强丢弃的能力,已提出了新的激活函数、最大输出和递归神经网络的丢弃变体(被称为rnndrop)。此外,批量归一化通过归一化微型批量内每次激活的标量特征并学习每个平均值和方差作为参数来提供新的正则化方法。
22.鉴于序列数据是多维和高维的,深度神经网络由于其广泛的适用性和增强的预测能力而在生物信息学研究方面具有巨大前景。卷积神经网络已被用于解决基因组学中基于序列的问题,诸如基序发现、致病性变异鉴定和基因表达推断。卷积神经网络使用权重共享策略,该策略尤其可用于研究dna,因为其可捕获序列基序,该序列基序是dna中被假定具有显著生物学功能的短且反复出现的局部模式。卷积神经网络的标志是卷积滤波器的使用。
23.与基于精密设计的特征和手工制作的特征的传统分类方法不同,卷积滤波器执行特征的自适应学习,类似于将原始输入数据映射到知识的信息表示的过程。在这个意义上,卷积滤波器用作一系列基序扫描器,因为一组此类滤波器能够在训练过程期间识别输入中的相关模式并更新其自身。递归神经网络可捕获具有不同长度的序列数据(诸如,蛋白质或dna序列)中的长程依赖。
24.因此,有机会使用基于深度学习的原则框架来进行模板生成和碱基检出(calling)。
25.在高通量技术时代,以每次工作的最低成本积累最多可解释数据仍然是一个重大挑战。基于簇的核酸测序方法,诸如将桥式扩增用于形成簇的那些方法,已对增加核酸测序通量的目标做出了重要贡献。这些基于簇的方法依赖于对固定在固体载体上的核酸的密集群体进行测序,并且通常涉及使用图像分析软件对在对位于固体载体上不同位置处的多个簇同时测序的过程中产生的光信号进行去卷积。
26.然而,此类基于固相核酸簇的测序技术仍面临着相当大的障碍,这些障碍限制了可实现的通量。例如,在基于簇的测序方法中,在确定物理上彼此太接近而无法在空间上分辨或实际上在固体载体上物理重叠的两个或更多个簇的核酸序列方面可能存在障碍。例如,当前的图像分析软件可能需要宝贵的时间和计算资源来确定从两个重叠簇中的哪一个簇发出了光信号。因此,对于多种检测平台而言,关于可获得的核酸序列信息的数量和/或质量的折衷是不可避免的。
27.基于高密度核酸簇的基因组学方法也扩展到了基因组分析的其他领域。例如,基于核酸簇的基因组学可用于测序应用、诊断和筛选、基因表达分析、表观遗传分析、多态性遗传分析等。当不能解析由紧密接近的或在空间上重叠的核酸簇生成的数据时,这些基于核酸簇的基因组技术中的每一种也会受到限制。
28.显然,仍然需要增加可快速且成本效益高地获得的核酸测序数据的质量和数量以用于各种各样的用途,包括基因组学(例如,用于任何和所有动物、植物、微生物或其他生物物种或群体的基因组表征)、药物遗传学、转录组学、诊断学、预后、生物医学风险评估、临床
和研究遗传学、个体化用药、药物功效和药物相互作用评估、兽医学、农业、进化和生物多样性研究、水产养殖、林业、海洋学、生态和环境管理以及其他目的。
29.所公开的技术提供了基于神经网络的方法和系统,该方法和系统解决了这些需求和类似需求,包括增加了高通量核酸测序技术中的通量水平,并且提供了其他相关优点。
30.深度神经网络和其他复杂机器学习算法的使用可在硬件计算和储存容量方面需要大量资源。另外,期望最小化执行感测和分析操作所需的时间,使得计算。期望实现使结果实时有效地可供客户使用的计算时间。
附图说明
31.在附图中,在所有不同视图中,类似的参考符号通常是指类似的部件。另外,附图未必按比例绘制,而是重点说明所公开的技术的原理。在以下描述中,参考以下附图描述了所公开的技术的各种具体实施,其中:
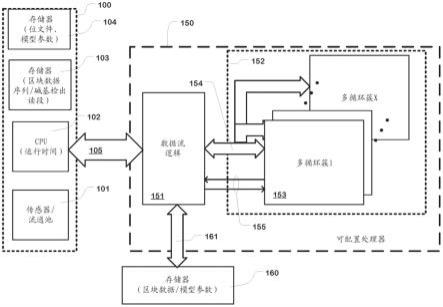
32.图1是包括可配置处理器的碱基检出计算系统的简化图。
33.图2是可由如图1一样的系统执行的简化数据流程图。
34.图3例示了支持碱基检出操作的可配置或可重构阵列的部件的配置架构。
35.图4是可使用如本文所述配置的可配置或可重构阵列执行的神经网络架构的图。
36.图5是由如图4一样的神经网络架构使用的传感器数据的区块的组织的简化图示。
37.图6是由如图4一样的神经网络架构使用的传感器数据的区块的补片的简化图示。
38.图7例示了由如图4一样的神经网络架构使用的输入区块的补片的配置。
39.图8例示了可配置或可重构阵列(诸如现场可编程门阵列(fpga))上的如图4一样的神经网络的配置的一部分。
40.图9例示了可用于执行如图4一样的神经网络的多循环机器学习簇的配置。
41.图10是可使用如本文所述配置的可配置或可重构阵列执行的另选神经网络架构的图。
42.图11是可使用如本文所述配置的可配置或可重构阵列执行的另一个另选神经网络架构的图。
43.图12是可使用如本文所述的可配置或可重构阵列来执行的又一个另选神经网络架构的图,该又一个另选神经网络架构利用可减少本文所述的所有神经网络实施方案的存储器和处理要求的掩膜。
44.图13例示了使用残差块级的深度神经网络的实施方案,该深度神经网络可使用如本文所述的可配置或可重构阵列来实现。
45.图14是例示了如图1一样利用如本文所述的资源的碱基检出操作的主机运行时流程图。
46.图15是例示了如本文所述的逻辑簇的数据流配置的逻辑簇执行流程图。
47.图16是例示了如本文所述的逻辑簇的数据流配置的另选逻辑簇执行流程图。
48.图17例示了基于神经网络的碱基检出器的专门化架构的一个具体实施,该基于神经网络的碱基检出器用于隔离对不同测序循环的数据的处理。
49.图18描绘了隔离层的一个具体实施,每个隔离层可包括卷积。
50.图19a描绘了组合层的一个具体实施,每个组合层可包括卷积。
51.图19b描绘了组合层的另一个具体实施,每个组合层可包括卷积。
52.图20是根据一个具体实施的碱基检出系统的框图。
53.图21是可在图20的系统中使用的系统控制器的框图。
54.图22是可用于实现所公开的技术的计算机系统的简化框图。
具体实施方式
55.所公开的技术的方法具体实施包括:将区块数据储存在存储器中,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据;使用经训练参数执行神经网络的运行以产生感测循环的分类数据,该神经网络的运行对来自包括受试者循环的n个感测循环中的相应感测循环的区块数据的n个阵列的序列进行操作,以产生该受试者循环的分类数据;以及输入单元将区块数据和这些经训练参数从存储器移动到该神经网络以用于该神经网络的运行,这些输入单元包括来自n个感测循环中的相应感测循环的该n个阵列的空间对准补片的数据。
56.本技术公开的另一种方法具体实施包括:将区块数据储存在存储器中,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据阵列;以及使用多个执行簇对该区块数据执行神经网络。在此具体实施中,执行该神经网络包括:将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括来自包括受试者感测循环的相应感测循环的区块数据阵列的数字n个空间对准补片,以及致使这些执行簇将该n个空间对准补片应用于该神经网络以产生该受试者感测循环的该空间对准补片的分类数据的输出补片,其中n大于1。这些输出补片可仅包括来自与生成碱基检出数据的簇相对应的像素的数据,并且因此可具有与这些输入补片不同的大小和尺寸。
57.另外,本文所述的方法可包括系统中的图像重采样,其中输入图像取向由于相机移动/振动而到处抖动。为了补偿,对图像数据进行重采样,将其提供为到网络的输入,以确保跨图像存在共同基础,以简化神经网络的作业。重采样涉及例如将仿射变换(平移、剪切、旋转)应用于图像数据。该重采样可在由主机处理器执行的软件中执行。在其他具体实施中,可在所配置的门阵列或其他硬件中执行重采样。
58.本文所述的位文件、模型参数和运行时程序可使用储存包括配置数据和模型参数的指令的一个或多个非暂态计算机可读储存介质(crm)来单独地或以任何组合实现,这些指令可由处理器执行以执行本文所述的方法。在该方法具体实施的该特定具体实施部分中所讨论的特征中的每个特征同样适用于crm具体实施。如上所示,所有方法特征在此处不再重复,并且应被视为以引用方式重复。
59.又一个具体实施可包括一种系统,该系统包括存储器和可操作以执行储存在存储器中的指令的一个或多个处理器,以执行上述方法。
60.所公开的技术的系统具体实施包括:存储器,该存储器可由储存区块数据的运行时间运行时程序访问,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据;神经网络处理器,该神经网络处理器能够访问该存储器,该神经网络处理器被配置为使用经训练参数执行神经网络的运行以产生感测循环的分类数据,该神经网络的运行对来自包括受试者循环的n个感测循环中的相应感测循环的区块数据的n个阵列的序列进行操作,以产生该受试者循环的分类数据;以及数据流逻辑,该数据流逻辑使用输入单元将区块数
据和这些经训练参数从该存储器移动到该神经网络处理器以用于该神经网络的运行,该输入单元包括来自n个感测循环中的相应感测循环的该n个阵列的空间对准补片的数据。神经网络处理器和数据流逻辑可使用可配置或可重构处理器诸如fpga或cgra来实现。
61.所公开的技术的另一个系统具体实施包括:主机处理器;存储器,该存储器能够由该主机处理器访问,该存储器储存区块数据,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据阵列;以及神经网络处理器,该神经网络处理器能够访问该存储器,该神经网络处理器可包括多个执行簇,该多个执行簇中的该执行逻辑簇被配置为执行神经网络;以及数据流逻辑,该数据流逻辑能够访问该存储器和多个执行簇中的执行簇,以将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括来自相应感测循环(包括受试者感测循环)的区块数据阵列的数字n个空间对准补片,并且使执行簇将n个空间对准补片应用于神经网络以产生受试者感测循环的空间对准补片的分类数据的输出补片,其中n大于1。神经网络处理器和数据流逻辑可使用可配置或可重构处理器诸如fpga或cgra来实现。
62.在该方法具体实施的该特定具体实施部分中所讨论的特征中的每个特征同样适用于系统具体实施。如上所示,所有方法特征在此处不再重复,并且应被视为以引用方式重复。
63.所公开的技术(例如所公开的碱基检出器(例如,图4和图10))可在处理器如中央处理单元(cpu)、图形处理单元(gpu)、现场可编程门阵列(fpga)、粗粒度可重构架构(cgra)、专用集成电路(asic)、专用指令集处理器(asip)和数字信号处理器(dsp)上实现。
64.图1是用于分析来自测序系统的传感器数据(诸如碱基检出传感器输出)的系统的简化框图。(也参见图148)。在图1的示例中,系统包括测序机器100和可配置处理器150。可配置处理器150可与由中央处理单元cpu 102执行的运行时程序协调地执行基于神经网络的碱基检出器(例如,图148的1514)。测序机器100包括碱基检出传感器和流通池101。流通池可包括一个或多个区块,其中遗传物质的簇暴露于分析物流的序列,该分析物流的序列用于引起簇中的反应以识别遗传物质中的碱基。传感器感测流通池的每个区块中该序列的每个循环的反应以提供区块数据。下文更详细地描述了该技术的示例。遗传测序是数据密集型操作,其将碱基检出传感器数据转换为在碱基检出操作期间感测到的遗传物质的每个簇的碱基检出序列。
65.该示例中的系统包括执行运行时程序以协调碱基检出操作的中央处理单元102、用于储存区块数据阵列的序列的存储器103、由碱基检出操作产生的碱基检出读段,以及碱基检出操作中使用的其他信息。另外,在该图示中,系统包括用于储存一个配置文件(或多个文件)诸如fpga位文件的存储器104和用于配置和重新配置可配置处理器150并且执行神经网络的神经网络的模型参数。机器100可包括用于配置可配置处理器以及在一些实施方案中的可重构处理器的程序,以执行神经网络。
66.测序机器100通过总线105耦接到可配置处理器150。总线105可使用高通量技术来实现,诸如在一个示例中,总线技术与当前由pci-sig(pci特别兴趣小组)维护和开发的pcie标准(快速外围部件互连)兼容。另外,在该示例中,存储器160通过总线161耦接到可配置处理器150。存储器160可以是设置在具有可配置处理器150的电路板上的板载存储器。存储器160用于由可配置处理器150高速访问在碱基检出操作中使用的工作数据。总线161还
可使用高通量技术诸如与pcie标准兼容的总线技术来实现。
67.可配置处理器,包括现场可编程门阵列fpga、粗粒度可重构阵列cgra以及其他可配置和可重构的设备,可被配置为比使用执行计算机程序的通用处理器可能实现的更有效或更快地实现各种功能。可配置处理器的配置涉及编译功能描述以产生有时称为位流或位文件的配置文件,以及将配置文件分布到处理器上的可配置元件。
68.该配置文件通过将电路配置为设置数据流模式、分布式存储器和其他片上存储器资源的使用、查找表内容、可配置逻辑块和可配置执行单元(如乘法累加单元、可配置互连和可配置阵列的其他元件)的操作,来定义要由可配置处理器执行的逻辑功能。如果配置文件可在现场通过改变加载的配置文件而改变,则可配置处理器是可重构的。例如,配置文件可储存在易失性sram元件中、非易失性读写存储器元件中以及它们的组合中,分布在可配置或可重构处理器上的可配置元件阵列中。多种可商购获得的可配置处理器适用于如本文所述的碱基检出操作。示例包括可商购获得的产品,诸如xilinx alveo
tm
u200、xilinx alveo
tm
u250、xilinx alveo
tm
u280、intel/altera stratix
tm
gx2800、intel/altera stratix
tm
gx2800和intel stratix
tm
gx10m。在一些示例中,主机cpu可在与可配置处理器相同的集成电路上实现。
69.本文所述的实施方案使用可配置处理器150实现多循环神经网络。可配置处理器的配置文件可通过使用高级描述语言hdl或寄存器传输级rtl语言规范指定要执行的逻辑功能来实现。可使用被设计用于所选择的可配置处理器的资源来编译规范以生成配置文件。为了生成可能不是可配置处理器的专用集成电路的设计,可编译相同或相似的规范。
70.因此,在本文所述的所有实施方案中,可配置处理器的另选方案包括配置的处理器,该配置的处理器包括专用asic或专用集成电路或集成电路组,或片上系统(soc)器件,该配置的处理器被配置为执行如本文所述的基于神经网络的碱基检出操作。
71.一般来讲,如被配置为执行神经网络的运行的本文所述的可配置处理器和配置的处理器在本文中称为神经网络处理器。
72.在该示例中,可配置处理器150通过使用由cpu 102或其他源执行的程序加载的配置文件进行配置,该配置文件配置可配置处理器154上的可配置元件的阵列以执行碱基检出功能。在该示例中,该配置包括数据流逻辑151,该数据流逻辑耦接到总线105和161并且执行用于在碱基检出操作中使用的元件之间分布数据和控制参数的功能。
73.另外,可配置处理器150配置有碱基检出执行逻辑152以执行多循环神经网络。逻辑152包括多个多循环执行簇(例如,153),在该示例中,该多个多循环执行簇包括多循环簇1至多循环簇x。可根据涉及操作的所需通量和可配置处理器上的可用资源的权衡来选择多循环簇的数量。
74.多循环簇通过使用可配置处理器上的可配置互连和存储器资源实现的数据流路径154耦接到数据流逻辑151。另外,多循环簇通过使用例如可配置处理器上的可配置互连和存储器资源实现的控制路径155耦接到数据流逻辑151,这些控制路径提供指示可用簇、准备好向可用簇提供用于执行神经网络的运行的输入单元、准备好提供用于神经网络的经训练参数、准备好提供碱基检出分类数据的输出补片的控制信号,以及用于执行神经网络的其他控制数据。
75.可配置处理器被配置为使用经训练参数来执行多循环神经网络的运行,以产生碱
基流操作的感测循环的分类数据。执行神经网络的运行以产生用于碱基检出操作的受试者感测循环的分类数据。神经网络的运行对序列(包括来自n个感测循环中的相应感测循环的区块数据的数字n个阵列)进行操作,其中n个感测循环在本文所述示例中针对时间序列中每个操作的一个碱基位置提供用于不同碱基检出操作的传感器数据。任选地,如果需要,根据正在执行的特定神经网络模型,n个感测循环中的一些可能会失序。数字n可以是大于1的任何数字。在本文所述的一些示例中,n个感测循环中的感测循环表示时间序列中受试者感测循环之前的至少一个感测循环和受试者循环(subject cycle)之后的至少一个感测循环的一组感测循环。本文描述了其中数字n为等于或大于五的整数的示例。
76.数据流逻辑被配置为使用用于给定运行的输入单元(包括n个阵列的空间对准补片的区块数据)将区块数据和模型参数的至少一些经训练参数从存储器160移动到用于神经网络的运行的可配置处理器。输入单元可通过一个dma操作中的直接存储器存取操作来移动,或者在可用时隙期间与所部署的神经网络的执行相协调地移动的较小单元中移动。
77.如本文所述的用于感测循环的区块数据可包括具有一个或多个特征的传感器数据阵列。例如,传感器数据可包括两个图像,对这两个图像进行分析以识别在dna、rna或其他遗传物质的遗传序列中的碱基位置处的四种碱基中的一种。区块数据还可包括关于图像和传感器的元数据。例如,在碱基检出操作的实施方案中,区块数据可包括关于图像与簇的对准的信息,诸如距中心距离的信息,该距离指示传感器数据阵列中的每个像素距区块上遗传物质的簇的中心的距离。
78.在如下所述的多循环神经网络的执行期间,区块数据还可包括在多循环神经网络的执行期间产生的数据,称为中间数据,该数据可在多循环神经网络的运行期间重复使用而不是重新计算。例如,在多循环神经网络的执行期间,数据流逻辑可将中间数据代替用于区块数据阵列的给定补片的传感器数据写入存储器160。下文更详细地描述了类似于此的实施方案。
79.如图所示,描述了用于分析碱基检出传感器输出的系统,该系统包括可由运行时程序访问的存储器(例如,160),该存储器储存区块数据,这些区块数据包括来自碱基检出操作的感测循环的区块的传感器数据。另外,该系统包括神经网络处理器,诸如能够访问存储器的可配置处理器150。神经网络处理器被配置为使用经训练参数来执行神经网络的运行,以产生用于感测循环的分类数据。如本文所述,神经网络的运行对来自n个感测循环中的相应感测循环(包括受试者循环)的区块数据的n个阵列的序列进行操作,以产生受试者循环的分类数据。提供数据流逻辑151以使用输入单元(包括来自n个感测循环中的相应感测循环的n个阵列的空间对准补片的数据)将区块数据和经训练参数从存储器移动到神经网络处理器以用于神经网络的运行。
80.另外,描述了一种系统,其中神经网络处理器能够访问存储器,并且包括多个执行簇,该多个执行簇中的执行逻辑簇被配置为执行神经网络。数据流逻辑能够访问存储器和多个执行簇中的执行簇,以将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括来自相应感测循环(包括受试者感测循环)的区块数据阵列的数字n个空间对准补片,并且使执行簇将n个空间对准补片应用于神经网络以产生受试者感测循环的空间对准补片的分类数据的输出补片,其中n大于1。
81.图2是示出碱基检出操作的各方面的简化图,该操作包括由主机处理器执行的运
行时程序的功能。在该图中,来自流通池的图像传感器的输出在线200上提供到图像处理线程201,该图像处理线程可对图像执行处理,诸如各个区块的传感器数据阵列中的重采样、对准和布置,并且可由为流通池中的每个区块计算区块簇掩膜的过程使用,该过程识别与流通池的对应区块上的遗传物质的簇对应的传感器数据阵列中的像素。为了计算簇掩膜,一个示例性算法是基于用于使用来源于softmax输出的度量来检测在早期测序循环中不可靠的簇的过程,然后丢弃来自那些阱/簇的数据,并且不针对那些簇产生输出数据。例如,过程可在第一n个(例如,25个)碱基检出期间识别具有高可靠性的簇,并且拒绝其他簇。所拒绝的簇可能是多克隆的或强度非常弱的或因基准点模糊。该程序可在主机cpu上执行。在另选的具体实施中,该信息将潜在地用于识别要传递回cpu的必要的感兴趣的簇,由此限制中间数据所需的储存量(即,下文描述的“脱水”步骤可查看所有具有阱的像素,或者仅处理具有通过滤波器检验的阱/簇的像素可更有效地实现)。
82.根据碱基检出操作的状态,图像处理线程201的输出在线202上提供到cpu中的调度逻辑210,该调度逻辑将区块数据阵列在高速总线203上路由到数据高速缓存204,或者在高速总线205上路由到多簇神经网络处理器硬件220,诸如图1的可配置处理器。硬件220将由神经网络输出的分类数据返回到调度逻辑210,该调度逻辑将信息传递到数据高速缓存204,或者在线211上传递到使用分类数据执行碱基检出和质量评分计算的线程202,并且可以标准格式布置用于碱基检出读段的数据。在线212上将执行碱基检出和质量评分计算的线程202的输出提供到线程203,该线程聚合碱基检出读段,执行其他操作诸如数据压缩,并且将所得的碱基检出输出写入指定目的地以供客户利用。
83.在一些实施方案中,主机可包括执行硬件220的输出的最终处理以支持神经网络的线程(未示出)。例如,硬件220可提供来自多簇神经网络的最终层的分类数据的输出。主机处理器可对分类数据执行输出激活函数诸如softmax函数,以配置供碱基检出和质量评分线程202使用的数据。另外,主机处理器可执行输入操作(未示出),诸如在输入到硬件220之前对区块数据进行重采样、批量归一化或其他调整。
84.图3是可配置处理器诸如图1的可配置处理器的配置的简化图。在图3中,可配置处理器包括具有多个高速pcie接口的fpga。fpga配置有封装器(wrapper)300,该封装器包括参考图1描述的数据流逻辑。封装器300通过cpu通信链路309来管理与cpu中的运行时程序的接口和协调,并且经由dram通信链路310来管理与板载dram 302(例如,存储器160)的通信。封装器300中的数据流逻辑将通过遍历板载dram 302上的数字n个循环的区块数据阵列而检索到的补片数据提供到簇301,并且从簇301检索过程数据315以递送回板载dram 302。封装器300还管理板载dram 302和主机存储器之间的数据传输,以用于区块数据的输入阵列和分类数据的输出补片两者。封装器在线313上将补片数据传输分配的簇301。封装器在线312上将经训练参数诸如权重和偏置提供到从板载dram 302检索的簇301。封装器在线311上将配置和控制数据提供到簇301,该簇经由cpu通信链路309从主机上的运行时程序提供或响应于该运行时程序而生成。簇还可在线316上向封装器300提供状态信号,该状态信号与来自主机的控制信号协作使用,以管理区块数据阵列的遍历,从而提供空间对准补片数据,并且使用簇301的资源对补片数据执行多循环神经网络。
85.如上所述,在由封装器300管理的单个可配置处理器上可存在多个簇,该多个簇被配置用于在区块数据的多个补片的对应补片上执行。每个簇可被配置为使用本文所述的多
个感测循环的区块数据来提供受试者感测循环中的碱基检出的分类数据。
86.在系统的示例中,可将模型数据(包括内核数据,如过滤器权重和偏置)从主机cpu发送到可配置处理器,使得模型可根据循环数进行更新。举一个代表性示例,碱基检出操作可包括大约数百个感测循环。在一些实施方案中,碱基检出操作可包括双端读段。例如,模型训练参数可以每20个循环(或其他数量的循环)更新一次,或者根据针对特定系统和神经网络模型实现的更新模式来更新。在包括双端读段的一些实施方案中,其中区块上的遗传簇中的给定字符串的序列包括从第一末端沿字符串向下(或向上)延伸的第一部分和从第二末端沿字符串向上(或向下)延伸的第二部分,可在从第一部分到第二部分的过渡中更新经训练参数。
87.在一些示例中,可将区块的感测数据的多个循环的图像数据从cpu发送到封装器300。封装器300可任选地对感测数据进行一些预处理和变换,并且将信息写入板载dram 302。每个感测循环的输入区块数据可包括传感器数据阵列,包括每个感测循环每个区块大约4000
×
3000个像素或更多,其中两个特征表示区块的两个图像的颜色,并且每个特征每个像素一个或两个字节。对于其中数字n为要在多循环神经网络的每个运行中使用的三个感测循环的实施方案,用于多循环神经网络的每个运行的区块数据阵列可消耗每个区块大约数百兆字节。在系统的一些实施方案中,区块数据还包括每个区块储存一次的dfc数据的阵列,或关于传感器数据和区块的其他类型的元数据。
88.在操作中,当多循环簇可用时,封装器将补片分配给簇。封装器在区块的遍历中获取区块数据的下一个补片,并将其连同适当的控制和配置信息一起发送到所分配的簇。簇可被配置为在可配置处理器上具有足够的存储器,以保存包括来自一些系统中的多个循环的补片且正被就地处理的数据补片,以及当在各种实施方案中使用乒乓缓冲技术或光栅扫描技术完成对当前补片的处理时将被处理的数据补片。
89.当分配的簇完成其对当前补片的神经网络的运行并产生输出补片时,其将发信号通知封装器。封装器将从分配的簇读取输出补片,或者另选地,分配的簇将数据推送到封装器。然后,封装器将为dram 302中的经处理区块组装输出补片。当整个区块的处理已完成并且数据的输出补片已传输到dram时,封装器将区块的经处理输出阵列以指定格式发送回主机/cpu。在一些实施方案中,板载dram 302由封装器300中的存储器管理逻辑管理。运行时程序可控制测序操作,以连续流的方式完成运行中所有循环的区块数据的所有阵列的分析,从而提供实时分析。
90.图4是可使用本文所述的系统执行的多循环神经网络模型的图。图4所示的示例可称为五循环输入、一循环输出神经网络。对多循环神经网络模型的输入包括来自给定区块的五个感测循环的区块数据阵列的五个空间对准补片(例如,400个)。空间对准补片具有与集合中的其他补片相同的对准行和列尺寸(x,y),使得信息涉及序列循环中的区块上的遗传物质的相同簇。在该示例中,受试者补片是来自循环n的区块数据阵列的补片。一组五个空间对准补片包括来自在受试者补片之前两个循环的循环n-2的补片、来自在受试者补片之前一个循环的循环n-1的补片、来自在来自受试者循环的补片之后一个循环的循环n+1的补片、以及来自在来自受试者循环的补片之后两个循环的循环n+2的补片。
91.该模型包括输入补片中的每个输入补片的神经网络的层的隔离叠堆401。因此,叠堆401接收来自循环n+2的补片的区块数据作为输入,并且与叠堆402、403、404和405隔离,
使得它们不共享输入数据或中间数据。在一些实施方案中,叠堆410-405中的所有叠堆可具有相同的模型和相同的经训练参数。在其他实施方案中,模型和经训练参数在不同叠堆中可能不同。叠堆402接收来自循环n+1的补片的区块数据作为输入。叠堆403接收来自循环n的补片的区块数据作为输入。叠堆404接收来自循环n-1的补片的区块数据作为输入。叠堆405接收来自循环n-2的补片的区块数据作为输入。隔离叠堆的层各自执行内核的卷积操作,该内核包括层的输入数据上的多个滤波器。如在以上示例中,补片400可包括三个特征。层410的输出可包括更多的特征,诸如10个至20个特征。同样,层411至416中的每个层的输出可包括适用于特定具体实施的任何数量的特征。滤波器的参数是神经网络的经训练参数,诸如权重和偏置。来自叠堆401-405中的每个叠堆的输出特征集(中间数据)作为输入被提供到时间组合层的逆层次结构420,其中来自多个循环的中间数据被组合。在例示的示例中,逆层次结构420包括:第一层,该第一层包括三个组合层421、422、423,每个组合层接收来自隔离叠堆中的三个隔离叠堆的中间数据;以及最终层,该最终层包括一个组合层430,该组合层接收来自三个时间层421、422、423的中间数据。
92.最终组合层430的输出是位于来自循环n的区块的对应补片中的簇的分类数据的输出补片。可将输出补片组装成循环n的区块的输出阵列分类数据。在一些实施方案中,输出补片可具有不同于输入补片的大小和尺寸。在一些实施方案中,输出补片可包括可经主机滤波以选择簇数据的逐像素数据。
93.根据特定具体实施,然后可将输出分类数据应用于任选地由主机或在可配置处理器上执行的softmax函数440(或其他输出激活函数)。可使用不同于softmax的输出函数(例如,根据最大输出产生碱基检出输出参数,然后利用使用上下文/网络输出的经学习非线性映射给出碱基质量)。
94.最后,可提供softmax函数440的输出作为循环n的碱基检出概率(450)并且将其储存在主机存储器中以在后续处理中使用。其他系统可使用用于输出概率计算的另一种函数,例如,另一个非线性模型。
95.可使用具有多个执行簇的可配置处理器来实现神经网络,以便在等于或接近一个感测循环的时间间隔的持续时间内完成一个区块循环的评估,从而有效地实时提供输出数据。数据流逻辑可被配置为将区块数据和经训练参数的输入单元分布到执行簇,并且分布输出补片以用于聚合在存储器中。
96.参考图5和图6描述了用于使用双通道传感器数据的碱基检出操作的如图4一样的五循环输入、一循环输出神经网络的数据的输入单元。例如,对于基因序列中的给定碱基,碱基检出操作可执行两个分析物流和两个反应,该两个反应生成两个信号(诸如图像)通道,这些图像可被处理以识别四种碱基中的哪一种碱基位于遗传物质的每个簇的遗传序列的当前位置处。在其他系统中,可利用不同数量的感测数据的通道。
97.图5示出了针对给定区块(区块m)的五个循环的区块数据阵列,该区块m出于执行五循环输入、一循环输出神经网络的目的使用。该示例中的五循环输入区块数据可被写入板载dram或系统中的可由数据流逻辑访问的其他存储器,并且对于循环n-2包括用于通道1的阵列501和用于通道2的阵列511,对于循环n-1包括用于通道1的阵列502和用于通道2的阵列512,对于循环n包括用于通道1的阵列503和用于通道2的阵列513,对于循环n+1包括用于通道1的阵列504和用于通道2的阵列514,对于循环n+2包括用于通道1的阵列505和用于
通道2的阵列515。另外,区块的元数据的阵列520可在存储器中写入一次,在该情况下,包括dfc文件以连同每个循环用作对神经网络的输入。
98.数据流逻辑构成区块数据的输入单元,这些输入单元可参考图6理解,该区块数据包括每个执行簇的区块数据阵列的空间对准补片,该每个执行簇被配置为对输入补片执行神经网络的运行。用于分配的执行簇的输入单元由数据流逻辑通过以下方式构成:从五个输入循环的区块数据阵列501-505、511、515、520中的每个阵列读取空间对准补片(例如,601、602、611、612、620),并且经由数据路径(示意性地,600)将它们递送到被配置用于由分配的执行簇使用的可配置处理器上的存储器。分配的执行簇执行五循环输入/一循环输出神经网络的运行,并且针对受试者循环n递送受试者循环n中的区块的相同补片的分类数据的输出补片。
99.图7例示了补片在给定区块的区块数据阵列上的映射。在该示例中,区块数据的输入阵列700具有x个像素的宽度和y个像素的高度。在将内核(诸如步长为一个像素的3
×
3内核)在神经网络的多个层中卷积之后,输出区块701可减少每个神经网络层两行和两列。在该示例中,两行/列的减少是由3
×
3的内核大小和使用中的(边缘)填充的类型造成的,并且可随配置不同而不同。因此,例如,对于包括该类型的卷积的l/2个层的神经网络,分类数据的输出区块701将具有x-l个像素的宽度。同样,对于包括l/2个层的神经网络,分类数据的输出区块将具有y-l个像素的高度。例如,以具有六个层的神经网络为例,l可以是12个像素。在图7所示的示例中,补片区域未按比例绘制。
100.输入补片以重叠方式形成以考虑到由超出补片尺寸的卷积产生的丢失像素。可根据特定具体实施选择输入补片的大小。在一个示例中,输入补片可具有76
×
76个像素的尺寸,其中每个像素有着具有一个或多个字节的三个通道。输出补片可具有64
×
64像素的尺寸。在实施方案中,用于a/c/t/g碱基检出的碱基检出操作输出分类以及输出补片可针对每个像素包括具有一个或多个字节的四个通道,从而表示分类的置信度评分。在图4的示例中,线435上的输出是四个碱基检出的未归一化置信度评分。
101.数据流逻辑可以光栅扫描方式或其他扫描方式将区块数据阵列寻址到补片,以提供输入补片(例如,705)。例如,对于第一可用簇,可提供补片p0,0。对于下一个可用簇,可提供补片p0,1。该序列可以光栅图样继续,直到区块的所有补片被递送到可用簇以进行处理。
102.在一些实施方案中,输出补片(例如,706)可重新写入与它们的受试者输入补片对准的相同地址空间,从而考虑到用于编码数据的每个像素的字节数量的任何差异。输出补片的面积(像素数)根据卷积层的数量和所执行的卷积的性质相对于输入补片而减小。
103.图8是如图4(例如,401和420)一样的系统中可使用的神经网络的叠堆的简化表示。在该示例中,神经网络的一些函数在主机(例如,800、802)上执行,并且神经网络的其他部分在可配置处理器(801)上执行。
104.第一函数可以是在cpu上形成的批量归一化(层810)。批量归一化是一种训练技术,该训练技术通过在每个批量的基础上归一化数据来改善总体性能结果,但可使用其他技术。在训练期间计算和更新每个层的若干参数。
105.在推断期间,批量归一化参数不会调整并且固定在长期平均值。乘法运算可融合到相邻层中以减少总运算计数。在固定点模型重新训练期间执行该融合,因此推断神经网络可在可配置处理器中实现的bn层中的每个bn层内包含单次加法。第一批量归一化层810
在训练中在cpu上执行。这是在cpu上执行的唯一层。量化批量归一化计算的输出,并且将输出传输到可配置处理器以进行进一步处理。在训练之后,批量归一化被固定的缩放和偏置加法替换。在第一层中,该缩放和偏置加法发生在cpu上。在仅推断具体实施中,实际上不需要使用批量归一化术语。
106.如上文关于可配置处理器所讨论的,多个空间隔离卷积层被执行为神经网络的第一组卷积层。在该示例中,第一组卷积层在空间上应用2d卷积。
107.这些卷积可使用2d winograd卷积的叠堆来有效地实现。运算在每个循环中独立地应用于每个补片上。多循环结构通过这些层保留。存在不同方式来实现卷积,这对于数字逻辑和可编程处理器而言是有效的方式。
108.如图8所示,针对每个叠堆中的数字l/2(l是参考图7描述的)个空间隔离的神经网络层,执行第一空间卷积821,之后执行第二空间卷积822,之后执行第三空间卷积823,并依此类推。如823a处所指示,空间层的数量可以是任何实际数字,针对上下文的该实际数字在不同实施方案中可在从几个到多于20个的范围内。
109.对于sp_conv_0,内核权重例如储存在(1,6,6,3,l)结构中,因为对于该层存在3个输入通道。在该示例中,该结构中的“6”归因于将系数储存在变换的winograd域中(内核大小在空间域中为3
×
3,但在变换域中扩展)。
110.对于该示例,对于其他sp_conv层,内核权重储存在(1,6,6l)结构中,因为对于这些层中的每个层,存在k(=l)个输入和输出。
111.空间层的叠堆的输出被提供到时间层,包括在fpga上执行的卷积层824、825。层824和825可以是跨循环应用1d卷积的卷积层。如824a处所指示,时间层的数量可以是任何实际数字,针对上下文的该实际数字在不同实施方案中可在从几个到多于20个的范围内。
112.第一时间层temp_conv_0层824将循环通道的数量从5减少到3,如图4所示。第二时间层(层825)将循环通道的数量从3减少到1,如图4所示,并且针对每个像素将特征映射图的数量减少到四个输出,从而表示每个碱基检出中的置信度。
113.时间层的输出被累加在输出补片中并且被递送到主机cpu以应用例如softmax函数830或其他函数以归一化碱基检出概率。
114.图9是适用于执行如本文所述的多循环神经网络的执行簇的配置的框图。在该示例中,执行簇包括多个执行引擎eng.0至eng.e-1(例如,900、901、902)。数字n可以是根据设计权衡选择的任何值。对于实际示例,当引擎在单个fpga上实现时,对于每个簇,数字n可在6至10的范围内,但可配置更多或更少的引擎。因此,执行簇包括一组计算引擎,该一组计算引擎具有多个成员,被配置为使用经训练参数对神经网络的多个层的输入数据进行卷积,其中第一层的输入数据是来自输入单元,并且后续层的数据是来自从先前层输出的激活数据。
115.引擎包括:前端,该前端向分配的引擎提供当前数据、滤波器参数和控制,这些引擎执行支持卷积的乘法累加函数的循环;以及后端,该后端包括用于应用支持神经网络的偏置和其他函数的电路。在该示例中,前端包括多个选择器920、921、922,该多个选择器用于从由数据流逻辑从板载dram或其他存储器源递送的输入补片(patch)或者从来自后端910的线950上的先前层馈送回的激活数据中选择用于分配的引擎的数据源。另外,前端包括滤波器储存区925,该滤波器储存区连接到储存用于执行卷积的滤波器参数的源。滤波器
储存区925耦接到引擎中的每个引擎,并且根据在特定引擎中执行的卷积部分提供合适的参数。引擎的输出包括向后端910提供结果的第一路径930、931、932。另外,引擎的输出包括第二路径940、941、942,该第二路径连接到封装器中的数据流逻辑以用于将数据路由回板载存储器或由系统利用的其他存储器。另外,簇包括加载有在执行神经网络时利用的各种偏置值bn_bias和bias的偏置储存区926。操作偏置储存区926以根据被执行的神经网络的特定状态向后端(910)过程提供特定偏置值。
116.神经网络处理器中的多个簇中的簇可被配置为包括内核存储器以储存经训练参数,并且数据流逻辑可被配置为将经训练参数的实例提供到多个执行簇中的执行簇的内核存储器以用于执行神经网络。用于层的权重可以是例如根据感测循环(诸如每x个循环)进行改变的经训练参数,其中x可以是根据经验选择的常数如15或20。另外,数量x可能够根据提供输入区块数据的测序系统的特性而变化。
117.图10是多循环神经网络模型的图,该多循环神经网络模型可等同于图4所示的模型,但是重新使用中间数据执行以节省计算资源。如图10所示,模型是五循环输入、一循环输出神经网络。神经网络的输入包括来自区块数据阵列的当前补片px,y(1000),该当前补片包括来自给定区块的当前感测循环的传感器数据。另外,输入包括来自来自循环n-2、n-1、n和n+1的先前空间对准补片的中间数据int(px,y)。
118.来自循环n+2的输入补片1000被应用于包括层1010、1011、1012、1013、1014、1015、1016的隔离层叠堆。隔离叠堆的最终层1016的输出在线1001上应用以用作神经网络的后续运行的中间数据,并且传递下去以如图所示供线1053、1054、1055多次重复使用。该中间数据可重新写入板载dram作为特定区块和特定循环的区块数据,或者重新写入其他存储器资源。在一些实施方案中,中间数据可在与空间对准补片的区块数据的原始传感器数据阵列相同的位置上写入。
119.在图10中,输入补片1000具有应用于神经网络的第一层1010的多个特征f1。层1010将多个特征f2输出到下一个层1011。下一个层输出多个特征f3,并依次类推,使得随后的层分别输出f4特征、f5特征、f6特征、f7特征和f8特征。在一些实施方案中,特征f1的数量可以是3,如上文相对于输入补片的传感器数据所讨论的。特征f2至f8的数量可以是12或更大并且是相同或不同的。在该情况下,最终层1016的12(或更多)个特征可消耗比输入补片1000更多的存储量,因为其包括更多特征。在其他实施方案中,特征f2至f8的数量可能变化。
120.在一些节约存储量的实施方案中,该多个特征f8可在用作中间数据时减少以保留存储器资源。例如,该多个特征f8的数量可以是2个特征或3个特征,使得当其作为受试者循环的区块数据储存时消耗与原始输入补片相同或比其更少的存储器空间。
121.在图10所示的模型中,循环n-2、n-1、n和n+1的中间数据作为对时间层1021、1022、1023的输入并且以相对于图4讨论的方式在线1002、1003、1004、1005上应用。另外,将隔离叠堆的层1016的输出作为输入应用于时间层中的层1021。最终时间层1030接收时间层1021-1023的输出作为输入。层1030的输出在线1035上应用于softmax函数1040或其他激活函数,该函数的输出被提供为受试者循环(循环n)的碱基检出概率1050。
122.因此,对于图10的神经网络模型,存储器中的感测循环的区块数据包括当前感测循环(n+2)的传感器数据和更早感测循环(n-2、n-1、n和n+1)的从神经网络馈送回的中间数
据。
123.图11例示了示出可针对碱基检出操作执行的10输入、六输出神经网络的另选具体实施。在如图11一样的系统中,如图10一样的节省和重复使用的方法可用于基本上提高效率。在该示例中,来自循环0至9的空间对准输入补片的区块数据被应用于空间层的隔离叠堆,诸如循环9的叠堆1101。将隔离叠堆的输出应用于具有输出1135(2)到1135(7)的时间叠堆1120的逆分层布置,从而提供受试者循环2至7的碱基检出分类数据。
124.图12例示了图10所示的模型的改进,并且包括具有相同参考标号的相似特征。图12与图10不同,因为其包括在层1016的输出处的“脱水”滤波器层1251和区块簇掩膜1252。可通过对传感器数据进行预处理以识别图像中的对应于被测序的遗传物质的簇的像素来生成区块簇掩膜1252。区块簇掩膜1252可应用于可配置处理器中,该可配置处理器包括掩膜逻辑以将区块簇掩膜应用于神经网络中的中间数据。掩膜逻辑可包括“脱水”滤波器层,以仅选择具有与碱基检出操作相关的数据(例如,可靠簇数据)的像素并且以更小的中间数据阵列重新布置像素,并且因此可基本上减小中间数据的大小,以及应用于时间层的数据的大小。
125.区块簇掩膜1252可例如如garcia等人的美国专利申请公布us2012/0020537中所述生成,该专利以引用方式并入,即如同在本文完整示出一样,其中特征识别位置可以是遗传物质的簇的位置。
126.区块簇掩膜1252可识别对应于不可靠簇的那些像素,并且可由脱水滤波器层用于丢弃/滤出此类像素,并且由此仅在对应于可靠簇的那些像素上应用时间层。在一个具体实施中,碱基检出分类评分由输出层生成。输出层的示例包括softmax函数、log-softmax函数、集成输出平均函数、多层感知不确定性函数、贝叶斯高斯分布函数和簇强度函数。在一个具体实施中,输出层针对每个簇并且针对每个测序循环产生每簇每循环概率四要素(probability quadruple)。
127.以下讨论聚焦于使用softmax函数作为输出层的示例的每簇每循环概率四要素。首先解释softmax函数,然后解释每簇每循环概率四要素,这些都用于识别不可靠簇。
128.softmax函数是用于多类分类的优选函数。softmax函数计算每个目标类别相对于所有可能的目标类别的概率。softmax函数的输出范围在零和一之间,并且所有概率的总和等于一。softmax函数计算给定输入值的指数和所有输入值的指数值的总和。输入值的指数与指数值的总和的比率是softmax函数的输出,在本文中称为“指数归一化”。
129.正式地,训练所谓的softmax分类器是回归到类概率,而不是回归到真实分类器,因为它不返回类,而是返回每个类的概率的置信度预测。softmax函数取一类值并将它们转换为总和为1的概率。softmax函数将任意实数值的n维向量压缩到0到1范围内的实数值的n维向量。因此,使用softmax函数确保输出是有效的、指数归一化的概率质量函数(非负且总和为1)。
130.直观地,softmax函数是最大值函数的“柔性”版本。术语“soft”来源于这样的事实:softmax函数是连续且可微的。代替选择一个最大元素,它使向量分解成整体的部分,其中最大输入元素得到比例更大的值,并且另一个元素得到比例更小的值。输出概率分布的性质使得softmax函数适用于分类任务中的概率解释。
131.将z视为对softmax层的输入的向量。softmax层单元是softmax层中的节点的数
量,并且因此z向量的长度是softmax层中的单元的数量(如果具有十个输出单元,则存在十个z元素)。
132.对于n-维向量z=[z1,z2,...zn],softmax函数使用指数归一化(exp)来产生另一个n-维向量p(z),其中归一化值在范围[0,1]内并且总计为一:
[0133][0134][0135]
softmax函数如下应用于三个类:需注意,三个输出总是总和为1。因此,它们定义了离散的概率质量函数。
[0136]
特定的每簇每循环概率四要素识别在特定测序循环为a、c、t和g时碱基掺入特定簇中的概率。当基于神经网络的碱基检出器的输出层使用softmax函数时,每簇每循环概率四要素中的概率是总和为一的指数归一化的分类评分。不可靠簇识别器基于从每簇每循环概率四要素生成滤波器值来识别不可靠簇。在该申请中,每簇每循环概率四要素也称为碱基检出分类评分或归一化碱基检出分类评分或初始碱基检出分类评分或归一化初始碱基检出分类评分或初始碱基检出。
[0137]
滤波器计算器基于其识别的概率来确定每个每簇每循环概率四要素的滤波器值,由此生成每个簇的滤波器值的序列。滤波器值的序列被储存为滤波器值。
[0138]
基于涉及概率中的一个或多个概率的算术运算来确定每簇每循环概率四要素的滤波器值。在一个具体实施中,由滤波器计算器使用的算术运算是减法。在一个具体实施中,通过从概率中的最高概率中减去概率中的第二高概率来确定每簇每循环概率四要素的滤波器值。
[0139]
在另一个具体实施中,由滤波器计算器使用的算术运算是除法。例如,每簇每循环概率四要素的滤波器值被确定为概率中的最高概率与概率中的第二高概率的比率。在又一个具体实施中,由滤波器计算器使用的算术运算是加法。在又另外的具体实施中,由滤波器计算器使用的算术运算是乘法。
[0140]
在一个具体实施中,滤波器计算器使用滤波函数来生成滤波器值。在一个示例中,滤波函数是纯粹度滤波器(chastity filter),该纯粹度滤波器将纯粹度定义为最亮碱基强度除以最亮碱基强度与第二亮碱基强度之和的比率。在另一个示例中,滤波函数是最大对数概率函数、最小平方误差函数、平均信噪比(snr)和最小绝对误差函数中的至少一者。
[0141]
不可靠簇识别器使用滤波器值来将多个簇中的一些簇识别为不可靠簇。识别不可靠簇的数据可呈计算机可读格式或位于计算机可读介质中。不可靠簇可由仪器id、仪器上的运行编号、流通池id、道编号、区块编号、簇的x坐标、簇的y坐标和唯一分子识别器(umi)来识别。不可靠簇识别器将多个簇中的那些簇识别为不可靠簇,这些不可靠簇的滤波器值的序列包含低于阈值“m”的数字“n”个滤波器值。在一个具体实施中,“n”的范围为1至5。在
另一个具体实施中,“m”的范围为0.5至0.99。在一个具体实施中,不可靠簇识别对应于不可靠簇(即,描绘这些不可靠簇的强度发射)的那些像素。
[0142]
不可靠簇是低质量簇,这些低质量簇发射与背景信号相比微不足道的量的所需信号。不可靠簇的信噪比基本上较低,例如,小于一。在一些具体实施中,不可靠簇可能不会产生任何量的所需信号。在其他具体实施中,不可靠簇可相对于背景产生非常低的量的信号。在一个具体实施中,信号是光信号并且旨在包括例如荧光信号、发光信号、散射信号或吸收信号。信号电平是指具有所需或预定义特征的检测到的能量或编码信息的量或数量。例如,光信号可通过强度、波长、能量、频率、功率、亮度等中的一者或多者来量化。其他信号可根据特征诸如电压、电流、电场强度、磁场强度、频率、功率、温度等进行量化。不可靠簇中的信号缺失被理解为信号电平为零或信号电平与噪声没有明显区别。
[0143]
对于不可靠簇的信号质量较差,存在许多潜在原因。如果菌落扩增中已经存在聚合酶链反应(pcr)误差,使得不可靠簇中约1000个分子的相当大比例在某个位置处包含不同碱基,则可观察到两个碱基的信号—这被解释为质量差的标志并且称为相位误差。相位误差发生于以下情况:当不可靠簇中的个体分子在某一循环中不掺入核苷酸(例如,由于3'终止子的不完全移除,称为定相)然后滞后于其他分子时,或者当个体分子在单个循环中掺入多于一个核苷酸(例如,由于核苷酸的掺入没有有效的3'-阻断,称为预定相)时。这导致序列拷贝的读数中的同步丧失。受定相和预定相影响的不可靠簇中的序列的比例随循环数而增加,这就是读段的质量趋于在高循环数下下降的主要原因。
[0144]
不可靠簇也由衰落引起。衰落是不可靠簇的信号强度根据循环数的指数衰减。随着测序运行进展,不可靠簇中的链被过度洗涤,暴露于产生反应性物质的激光发射,并且遭受恶劣的环境条件。所有这些导致不可靠簇中碎片的逐渐损失,从而降低它们的信号强度。
[0145]
不可靠簇也由发育不足的菌落导致,即,在图案化流通池上产生空的或部分填充的阱的小型簇大小的不可靠簇。也就是说,在一些具体实施中,不可靠簇指示图案化流通池上的空的、多克隆的和暗淡的阱。不可靠簇也由无限制扩增引起的重叠菌落导致。不可靠簇也由例如由于位于流通池的边缘上引起的不足照明或不均匀照明导致。不可靠簇也由流通池上的使发射信号模糊的杂质导致。当多个簇沉积在同一阱中时,不可靠簇还包括多克隆簇。
[0146]
图13例示了可执行的深度神经网络的另选的具体实施。图13呈图8的形式,并且包括相同部件的相同附图标号。在图13中,隔离叠堆中的空间卷积层中的一个或多个空间卷积层被残差块结构1301(resblock)替换。在一个示例性配置中的残差块结构可包括第一卷积层和第二卷积层,该第一卷积层和该第二卷积层接收对第一卷积层的输入和第一卷积层的输出的总和作为输入。残差块1301中的第二卷积层在添加之后可能没有激活函数。
[0147]
图14是用于使用如图1一样的系统进行碱基检出操作的简化流程图。在该简化过程中,由cpu 102执行的运行时程序发起碱基检出操作(1401)。这可包括实例化可在主机cpu的多个核心上运行的一个或多个处理线程。在碱基检出操作中,传感器和流通池在其中生成区块数据阵列的循环序列中执行。处理线程等待和接收来自在流通池的区块中跨遗传物质的簇的感测循环序列(例如,区块图像)的数据(1402)。通过以下方式例如在感测操作和神经网络之间处理来自流通池的输出:重新采样,使得每个图像具有共同结构和共同参考帧,例如,基准点是对准的,簇/阱是对准的,dfc数据是恒定的;以及将数据布置在区块数
据阵列的序列中,其中每个序列可包括一个区块数据阵列,其包括用于每个感测循环的数字f个特征(1403)。执行区块图像的该重新采样和布置,因为当神经网络的训练输入中的每个训练输入中的相同像素传达关于来自流通池的基础信号的相同信息时,该神经网络性能得以改善。处理线程经由可配置处理器上的封装器(数据流逻辑151)将区块数据阵列和神经网络经训练参数传输到存储器1060。当足够的数据(诸如包括受试者区块的区块数据的n个完整阵列和n个循环的多个相邻区块)已经被加载到存储器140中(例如,响应于在总线上形成或发出的控制信号如控制触发器和/或控制令牌(前馈单个脉冲))时,处理线程可通过向封装器发信号告知事件来将作业提交到推断引擎,或者封装器可检测事件,以开始神经网络在特定受试者区块上的运行(1404)。封装器将神经网络的经训练参数加载到可用逻辑簇,分配可用逻辑簇并且加载来自数字n个循环的空间对准补片(1405)。封装器可使用例如乒乓缓冲根据序列中的循环数来更新神经网络参数(1406)。例如,在特定具体实施中,可每20个循环更新神经网络模型参数(权重和偏置)。因此,封装器能够访问存储器以及多个执行簇中的执行簇,并且包括逻辑,该逻辑用于向多个执行簇中的可用执行簇提供区块数据的输入单元并且致使执行簇将来自输入单元的n个循环中的每个循环的空间对准补片的区块数据应用于神经网络以产生受试者循环的分类数据的输出补片。dram可被配置有足够的分配空间用于储存,从而支持五循环推断引擎,其中对于流通池上的每个区块,存在针对四个循环的图像。利用指针跳动(pointer juggling),推断所需的第五缓冲区可存在于分配给特定处理线程的主机处理器存储器中(区块数量通常远大于实例化处理器线程的数量)。
[0148]
在对分配的补片运行神经网络之后,簇经由封装器将n个循环的受试者循环的输出补片返回到存储器140,并且向封装器发信号告知可用性(1407)。封装器跟踪补片的序列以遍历区块数据阵列,布置输出补片,并且当区块数据的输出区块或其他单元已在存储器140中构成时发信号告知主机中的等待处理器线程(1408)。因此,封装器可包括组装逻辑,该组装逻辑用于组装来自多个执行簇的输出补片以提供受试者循环的碱基检出分类数据阵列,并且将碱基检出分类数据阵列储存在存储器中。所构成的输出区块由主机检索,或者由封装器推送到主机以用于进一步处理(1409)。任选地,如上所述,输出区块可包括呈未归一化形式的分类数据,诸如用于每个像素或者对应于簇的每个像素的四个对数概率(logit)。在该情况下,主机可对区块数据执行softmax或其他类型的归一化函数,以准备构成碱基检出文件和质量评分(1410)。
[0149]
图15是用于如图4一样的神经网络的如图1一样的系统中的逻辑簇流的一个实施方案的简化流程图。由如图16中所讨论的封装器发起逻辑簇流,并且将包括n个空间对准补片的输入单元移动到簇的存储器(1501)。逻辑簇分配一个或多个可用引擎,并且将n个空间对准补片的空间对准子补片路由到分配的引擎(1502)。空间对准补片的当前输入循环的区块数据包括来自当前循环(循环n+2)和n-1个先前循环(循环n-2、n-1、n和n+1)的区块数据的n个补片(1503)。簇的每个引擎可配置有足够的存储器,以保存当前正被就地处理的数据的一组空间对准子补片,以及当使用例如乒乓输入缓冲区结构或其他存储器管理技术完成当前批量处理时将要处理的数据的子补片。
[0150]
分配的引擎循环通过应用于网络的层中的滤波器,包括应用用于当前网络层的滤波器组以及返回用于下一个层的激活数据(1504)。在该示例中,神经网络包括第一阶段,该第一阶段包括数字n个隔离空间叠堆,该第一阶段馈送包括一组逆分层时间层的第二阶段。
网络的最后一层生成四个特征的输出,每个特征表示当被执行以对dna进行分类时的四种碱基a/c/g/t(腺嘌呤(a)、胞嘧啶(c)、鸟嘌呤(g)和胸腺嘧啶(t))或者当被执行以对碱基进行分类时的四种碱基a/c/g/u((腺嘌呤(a)、胞嘧啶(c)、鸟嘌呤(g)和尿嘧啶(u))中的每一种的分类(1505)。
[0151]
在该示例中,神经网络参数包括用于识别区块中的基因簇的位置的区块簇掩膜(1506)。在一个具体实施中,模板生成步骤识别可靠簇(例如,garcia等人的美国专利申请公布us 2012/0020537中公开的可靠簇)的xy位置坐标。通过引擎(在该示例性流中,通过可配置处理器中的掩膜逻辑)减少由叠堆中的最终空间层生成的中间数据(对其“进行脱水”),该引擎使用掩膜以移除不对应于区块中的簇的位置的像素,从而产生用于后续层的更小量的激活数据(1507)。
[0152]
引擎返回受试者循环(中循环)的输出子补片的特征,并且向逻辑簇发信号告知可用性(1508)。逻辑簇在当前补片上继续执行,直到用于补片的网络的当前层的所有特征完成,然后遍历将子补片分配给引擎并且组装输出子补片的下一个分配的补片,直到完成分配的补片(1509)。最后,封装器将输出补片传输到存储器以组装成输出区块(1510)。
[0153]
图16是用于如图10一样的神经网络的如图1一样的系统中的逻辑簇流的一个实施方案的简化流程图。由如参考图16所讨论的封装器发起逻辑簇流,并且将包括n个空间对准补片的输入单元移动到簇的存储器(1601)。逻辑簇分配一个或多个可用引擎,并且将n个空间对准补片的空间对准子补片路由到分配的引擎(1602)。空间对准补片包括:当前循环(例如,循环n+2)的区块数据阵列的补片,该补片包括具有f个特征(或通道)的传感器数据;以及使用先前循环(循环n-2、n-1、n和n+1)计算的中间数据的n-1个补片(1603)。簇的每个引擎可配置有足够的存储器,以保存当前正被就地处理的数据的一组空间对准子补片,以及当使用例如乒乓输入缓冲区结构或其他存储器管理技术完成当前子补片处理时将要处理的子补片。
[0154]
分配的引擎循环通过应用于空间层和用于应用于当前循环(循环n+2)的隔离叠堆的网络层中的滤波器,包括针对给定层应用用于当前网络层的滤波器组以及返回用于下一个层的激活数据(1604)。在该示例中,神经网络包括:第一阶段,该第一阶段包括当前循环的一个隔离空间叠堆;以及第二阶段,该第二阶段包括一组逆分层时间层,如图10所示。
[0155]
引擎在第一阶段结束时将当前输入循环子补片的激活数据返回到逻辑簇,以在随后的循环中用作中间数据(1606)。该中间数据可在响应循环的区块数据的位置中储存回板载存储器,从而替换传感器数据,或储存在其他位置中。例如,空间层的最终层具有数字f个或更少个特征,使得用于循环的区块数据的存储器的量不会因中间数据而扩展(1607)。另外,在该示例中,神经网络参数包括识别区块中的基因簇的位置的区块簇掩膜(1608)。在使用掩膜的引擎中或在由簇分配的另一个引擎中对来自最终空间层的中间数据“进行脱水”(1609)。这减小了输出子补片的大小,该输出子补片用作中间数据并且应用于第二阶段。
[0156]
在处理当前循环的隔离空间叠堆之后,引擎使用来自当前输入循环(循环n+2)的激活数据和来自n-1个先前循环的中间数据循环通过网络的时间层(1610)。
[0157]
引擎返回受试者循环(循环n)的输出子补片的特征,并且向逻辑簇发信号告知可用性(1611)。逻辑簇累加输出子补片以形成输出补片(1612)。最后,封装器将输出补片传输到存储器以组装成输出区块(1613)。
[0158]
图17例示了基于神经网络的碱基检出器(例如,图4和图10)的专门化架构的一个具体实施,该基于神经网络的碱基检出器用于隔离对不同测序循环的数据的处理。首先描述使用专门化架构的动机。
[0159]
基于神经网络的碱基检出器处理当前测序循环、一个或多个先前测序循环以及一个或多个后续测序循环的数据。附加测序循环的数据提供序列特异性上下文。基于神经网络的碱基检出器在训练期间学习序列特异性上下文,并且对该序列特异性上下文进行碱基检出。此外,前测序循环和后测序循环的数据为当前测序循环提供了预定相和定相信号的二阶贡献。
[0160]
在不同测序循环处和不同图像通道中捕获的图像相对于彼此未对准并且具有残差配准误差。考虑到这种未对准,专门化架构包括空间卷积层,该空间卷积层不混合测序循环之间的信息并且仅混合测序循环内的信息。
[0161]
空间卷积层使用所谓的“隔离卷积”,该隔离卷积通过经由“专用非共享”卷积序列独立处理多个测序循环中的每个测序循环的数据来实现隔离。隔离卷积对仅给定测序循环(即,循环内)的数据和所得特征映射图进行卷积,而不对任何其他测序循环的数据和所得特征映射图进行卷积。
[0162]
例如,考虑输入数据包括(i)待进行碱基检出的当前(时间t)测序循环的当前数据,(ii)先前(时间t-1)测序循环的先前数据,以及(iii)先前(时间t+1)测序循环的后续数据。然后,专门化架构发起三个单独的数据处理管道(或卷积管道),即当前数据处理管道、先前数据处理管道和后续数据处理管道。当前数据处理管道接收当前(时间t)测序循环的当前数据作为输入,并且通过多个空间卷积层独立地处理该当前数据,以产生所谓的“当前空间卷积表示”作为最终空间卷积层的输出。先前数据处理管道接收先前(时间t-1)测序循环的先前数据作为输入,并且通过多个空间卷积层独立地处理该先前数据,以产生所谓的“先前空间卷积表示”作为最终空间卷积层的输出。后续数据处理管道接收后续(时间t+1)测序循环的后续数据作为输入,并且通过多个空间卷积层独立地处理该后续数据以产生所谓的“后续空间卷积表示”作为最终空间卷积层的输出。
[0163]
在一些具体实施中,同步地执行当前处理管道、先前处理管道和后续处理管道。
[0164]
在一些具体实施中,空间卷积层是专门化架构内的空间卷积网络(或子网络)的一部分。
[0165]
基于神经网络的碱基检出器还包括混合测序循环之间(即,循环间)的信息的时间卷积层。时间卷积层从空间卷积网络接收其输入,并且对由相应数据处理管道的最终空间卷积层产生的空间卷积表示进行操作。
[0166]
时间卷积层的循环间可操作性自由源于以下事实:未对准属性通过由空间卷积层序列执行的隔离卷积的叠堆或级联而从空间卷积表示清除,该未对准属性存在于作为输入馈送到空间卷积网络的图像数据中。
[0167]
时间卷积层使用所谓的“组合卷积”,该组合卷积在滑动窗口的基础上逐组地对后续输入中的输入通道进行卷积。在一个具体实施中,这些后续输入是由先前的空间卷积层或先前时间卷积层产生的后续输出。
[0168]
在一些具体实施中,时间卷积层是专门化架构内的时间卷积网络(或子网络)的一部分。时间卷积网络从空间卷积网络接收其输入。在一个具体实施中,时间卷积网络的第一
时间卷积层逐组地组合测序循环之间的空间卷积表示。在另一个具体实施中,时间卷积网络的后续时间卷积层组合先前时间卷积层的后续输出。
[0169]
最终时间卷积层的输出被馈送到产生输出的输出层。输出用于在一个或多个测序循环处对一个或多个簇进行碱基检出。
[0170]
在前向传播期间,专门化架构以两个阶段处理来自多个输入的信息。在第一阶段中,使用隔离卷积来防止输入之间的信息混合。在第二阶段中,使用组合卷积来混合输入之间的信息。将来自第二阶段的结果用于对该多个输入进行单个推断。
[0171]
这不同于其中卷积层同时处理批量中的多个输入并且对该批量中的每个输入进行对应推断的批处理模式技术。相比之下,专门化架构将该多个输入映射到该单个推断。该单个推断可包括多于一个预测,诸如四种碱基(a、c、t和g)中的每种碱基的分类评分(例如,softmax或pre-softmax逐碱基分类评分或逐碱基回归评分)。
[0172]
在一个具体实施中,这些输入具有时间顺序,使得每个输入在不同的时间步长处生成并且具有多个输入通道。例如,该多个输入可包括以下三个输入:在时间步长(t)处由当前测序循环生成的当前输入、在时间步长(t-1)处由先前测序循环生成的先前输入以及在时间步长(t+1)处由后续测序循环生成的后续输入。在另一个具体实施中,每个输入分别来源于由一个或多个先前卷积层产生的当前输出、先前输出和后续输出,并且包括k个特征映射图。
[0173]
在一个具体实施中,每个输入可包括以下五个输入通道:红色图像通道(红色)、红色距离通道(黄色)、绿色图像通道(绿色)、绿色距离通道(紫色)和缩放通道(蓝色)。在另一个具体实施中,每个输入可包括由先前卷积层产生的k特征映射图,并且每个特征映射图被视为输入通道。
[0174]
图18描绘了隔离层的一个具体实施,每个隔离层可包括卷积。隔离卷积通过将卷积滤波器同步地应用于每个输入一次来处理该多个输入。利用隔离卷积,卷积滤波器组合相同输入中的输入通道,并且不组合不同输入中的输入通道。在一个具体实施中,将相同的卷积滤波器同步地应用于每个输入。在另一个具体实施中,将不同的卷积滤波器同步地应用于每个输入。在一些具体实施中,每个空间卷积层包括一组k个卷积滤波器,其中每个卷积滤波器同步地应用于每个输入。
[0175]
图19a描绘了组合层的一个具体实施,每个组合层可包括卷积。图19b描绘了组合层的另一个具体实施,每个组合层可包括卷积。组合卷积通过对不同输入的对应输入通道进行分组并将卷积滤波器应用于每个分组来混合不同输入之间的信息。对这些对应输入通道的分组和卷积滤波器的应用是在滑动窗口的基础上发生的。在该上下文中,窗口跨越两个或更多个后续输入通道,其表示例如两个后续测序循环的输出。由于该窗口是滑动窗口,因此大多数输入通道用于两个或更多个窗口中。
[0176]
在一些具体实施中,不同输入源于由先前空间卷积层或先前时间卷积层产生的输出序列。在该输出序列中,这些不同输入被布置为后续输出并且因此被后续时间卷积层视为后续输入。然后,在该后续时间卷积层中,这些组合卷积将卷积滤波器应用于这些后续输入中的对应输入通道组。
[0177]
在一个具体实施中,这些后续输入具有时间顺序,使得当前输入在时间步长(t)处由当前测序循环生成,先前输入在时间步长(t-1)处由先测序循环生成,并且后续输入在时
间步长(t+1)处由后续测序循环生成。在另一个具体实施中,每个后续输入分别来源于由一个或多个先前卷积层产生的当前输出、先前输出和后续输出,并且包括k个特征映射图。
[0178]
在一个具体实施中,每个输入可包括以下五个输入通道:红色图像通道(红色)、红色距离通道(黄色)、绿色图像通道(绿色)、绿色距离通道(紫色)和缩放通道(蓝色)。在另一个具体实施中,每个输入可包括由先前卷积层产生的k特征映射图,并且每个特征映射图被视为输入通道。
[0179]
卷积滤波器的深度b取决于后续输入的数量,这些后续输入的对应输入通道由卷积滤波器在滑动窗口的基础上逐组地进行卷积。换句话讲,深度b等于每个滑动窗口中的后续输入的数量和组大小。
[0180]
在图19a中,来自两个后续输入的对应输入通道在每个滑动窗口中组合,并且因此b=2。在图19b中,来自三个后续输入的对应输入通道在每个滑动窗口中组合,并且因此b=3。
[0181]
在一个具体实施中,滑动窗口共享相同的卷积滤波器。在另一个具体实施中,针对每个滑动窗口使用不同的卷积滤波器。在一些具体实施中,每个时间卷积层包括一组k个卷积滤波器,其中每个卷积滤波器在滑动窗口的基础上应用于后续输入。
[0182]
图20是根据一个具体实施的碱基检出系统2000的框图。碱基检出系统2000可操作以获得与生物物质或化学物质中的至少一者相关的任何信息或数据。在一些具体实施中,碱基检出系统2000是可类似于台式设备或台式计算机的工作站。例如,用于进行所需反应的大部分(或全部)系统和部件可位于共同的外壳2016内。
[0183]
在特定具体实施中,碱基检出系统2000是被配置用于各种应用的核酸测序系统(或测序仪),各种应用包括但不限于从头测序、全基因组或靶基因组区域的重测序以及宏基因组学。测序仪也可用于dna或rna分析。在一些具体实施中,碱基检出系统2000还可被配置为在生物传感器中生成反应位点。例如,碱基检出系统2000可被配置为接收样品并且生成来源于样品的克隆扩增核酸的表面附着簇。每个簇可构成生物传感器中的反应位点或作为其一部分。
[0184]
示例性碱基检出系统2000可包括被配置为与生物传感器2002相互作用以在生物传感器2002内执行所需反应的系统插座或接口2012。在以下相对于图20的描述中,将生物传感器2002加载到系统插座2012中。然而,应当理解,可将包括生物传感器2002的卡盒插入到系统插座2012中,并且在一些状态下,可暂时或永久地移除卡盒。如上所述,除了别的以外,卡盒还可包括流体控制部件和流体储存部件。
[0185]
在特定具体实施中,碱基检出系统2000被配置为在生物传感器2002内执行大量平行反应。生物传感器2002包括可发生所需反应的一个或多个反应位点。反应位点可例如固定至生物传感器的固体表面或固定至位于生物传感器的对应反应室内的小珠(或其他可移动基板)。反应位点可包括,例如,克隆扩增核酸的簇。生物传感器2002可包括固态成像设备(例如,ccd或cmos成像器)和安装到其上的流通池。流通池可包括一个或多个流动通道,该一个或多个流动通道从碱基检出系统2000接收溶液并且将溶液引向反应位点。任选地,生物传感器2002可被配置为接合热元件,以用于将热能传输到流动通道中或从流动通道传递出去。
[0186]
碱基检出系统2000可包括彼此相互作用以执行用于生物或化学分析的预先确定
的方法或测定方案的各种部件、组件和系统(或子系统)。例如,碱基检出系统2000包括系统控制器2004,该系统控制器可与碱基检出系统2000的各种部件、组件和子系统以及生物传感器2002通信。例如,除了系统插座2012之外,碱基检出系统2000还可包括流体控制系统2006以控制流体在碱基检出系统2000和生物传感器2002的整个流体网络中的流动;流体储存系统2008,该流体储存系统被配置为保存生物测定系统可使用的所有流体(例如,气体或液体);温度控制系统2010,该温度控制系统可调节流体网络、流体储存系统2008和/或生物传感器2002中流体的温度;以及照明系统2009,该照明系统被配置为照亮生物传感器2002。如上所述,如果将具有生物传感器2002的卡盒加载到系统插座2012中,则该卡盒还可包括流体控制部件和流体储存部件。
[0187]
还如图所示,碱基检出系统2000可包括与用户交互的用户界面2014。例如,用户界面2014可包括用于显示或请求来自用户的信息的显示器2013和用于接收用户输入的用户输入设备2015。在一些具体实施中,显示器2013和用户输入设备2015是相同的设备。例如,用户界面2014可包括触敏显示器,该触敏显示器被配置为检测个体触摸的存在并且还识别触摸在显示器上的位置。然而,可使用其他用户输入设备2015,诸如鼠标、触摸板、键盘、小键盘、手持扫描仪、语音识别系统、运动识别系统等。如将在下文更详细地讨论,碱基检出系统2000可与包括生物传感器2002(例如,呈卡盒的形式)的各种部件通信,以执行所需反应。碱基检出系统2000还可被配置为分析从生物传感器获得的数据以向用户提供所需信息。
[0188]
系统控制器2004可包括任何基于处理器或基于微处理器的系统,包括使用微控制器、精简指令集计算机(risc)、专用集成电路(asic)、现场可编程门阵列(fpga)、逻辑电路以及能够执行本文所述功能的任何其他电路或处理器。上述示例仅是示例性的,因此不旨在以任何方式限制术语系统控制器的定义和/或含义。在示例性具体实施中,系统控制器2004执行储存在一个或多个储存元件、存储器或模块中的指令集,以便进行获得检测数据和分析检测数据中的至少一者。检测数据可包括多个像素信号序列,使得可在许多碱基检出循环内检测来自数百万个传感器(或像素)中的每个传感器(或像素)的像素信号序列。储存元件可为呈碱基检出系统2000内的信息源或物理存储器元件的形式。
[0189]
指令集可包括指示碱基检出系统2000或生物传感器2002执行具体操作(诸如本文所述的各种具体实施的方法和过程)的各种命令。指令集可为软件程序的形式,该软件程序可形成有形的一个或多个非暂态计算机可读介质的一部分。如本文所用,术语“软件”和“固件”是可互换的,并且包括储存在存储器中以供计算机执行的任何计算机程序,包括ram存储器、rom存储器、eprom存储器、eeprom存储器和非易失性ram(nvram)存储器。上述存储器类型仅是示例性的,因此不限制可用于存储计算机程序的存储器类型。
[0190]
软件可为各种形式,诸如系统软件或应用软件。此外,软件可以是独立程序的集合的形式,或者是较大程序内的程序模块或程序模块的一部分的形式。软件还可包括面向对象编程形式的模块化编程。在获得检测数据之后,检测数据可由碱基检出系统2000自动处理,响应于用户输入而处理,或者响应于另一个处理机器提出的请求(例如,通过通信链路的远程请求)而处理。在例示的具体实施中,系统控制器2004包括分析模块2138。在其他具体实施中,系统控制器2004不包括分析模块2138,而是能够访问分析模块2138(例如,分析模块2138可单独地托管在云上)。
[0191]
系统控制器2004可经由通信链路连接到生物传感器2002和碱基检出系统2000的
其他部件。系统控制器2004还可通信地连接到非现场系统或服务器。通信链路可以是硬连线的、有线的或无线的。系统控制器2004可从用户界面2014和用户输入设备2015接收用户输入或命令。
[0192]
流体控制系统2006包括流体网络,并且被配置为引导和调节一种或多种流体通过流体网络的流动。流体网络可与生物传感器2002和流体储存系统2008流体连通。例如,选定的流体可从流体储存系统2008抽吸并且以受控方式引导至生物传感器2002,或者流体可从生物传感器2002抽吸并朝向例如流体储存系统2008中的废物储存器引导。虽然未示出,但流体控制系统2006可包括检测流体网络内的流体的流速或压力的流量传感器。传感器可与系统控制器2004通信。
[0193]
温度控制系统2010被配置为调节流体网络、流体储存系统2008和/或生物传感器2002的不同区域处流体的温度。例如,温度控制系统2010可包括热循环仪,该热循环仪与生物传感器2002对接并且控制沿着生物传感器2002中的反应位点流动的流体的温度。温度控制系统2010还可调节碱基检出系统2000或生物传感器2002的固体元件或部件的温度。尽管未示出,但温度控制系统2010可包括用于检测流体或其他部件的温度的传感器。传感器可与系统控制器2004通信。
[0194]
流体储存系统2008与生物传感器2002流体连通,并且可储存用于在其中进行所需反应的各种反应组分或反应物。流体储存系统2008还可储存用于洗涤或清洁流体网络和生物传感器2002以及用于稀释反应物的流体。例如,流体储存系统2008可包括各种储存器,以储存样品、试剂、酶、其他生物分子、缓冲溶液、水性溶液和非极性溶液等。此外,流体储存系统2008还可包括废物储存器,用于接收来自生物传感器2002的废物。在包括卡盒的具体实施中,卡盒可包括流体储存系统、流体控制系统或温度控制系统中的一者或多者。因此,本文所述的与那些系统有关的一个或多个部件可容纳在卡盒外壳内。例如,卡盒可具有各种储存器,以储存样品、试剂、酶、其他生物分子、缓冲溶液、水性溶液和非极性溶液、废物等。因此,流体储存系统、流体控制系统或温度控制系统中的一者或多者可经由卡盒或其他生物传感器与生物测定系统可移除地接合。
[0195]
照明系统2009可包括光源(例如,一个或多个led)和用于照亮生物传感器的多个光学部件。光源的示例可包括激光器、弧光灯、led或激光二极管。光学部件可以是例如反射器、二向色镜、分束器、准直器、透镜、滤光器、楔镜、棱镜、反射镜、检测器等。在使用照明系统的具体实施中,照明系统2009可被配置为将激发光引导至反应位点。作为一个示例,荧光团可由绿色波长的光激发,因此激发光的波长可为大约532nm。在一个具体实施中,照明系统2009被配置为产生平行于生物传感器2002的表面的表面法线的照明。在另一个具体实施中,照明系统2009被配置为产生相对于生物传感器2002的表面的表面法线成偏角的照明。在又一个具体实施中,照明系统2009被配置为产生具有多个角度的照明,包括一些平行照明和一些偏角照明。
[0196]
系统插座或接口2012被配置为以机械、电气和流体方式中的至少一种方式接合生物传感器2002。系统插座2012可将生物传感器2002保持在所需取向,以有利于流体流过生物传感器2002。系统插座2012还可包括电触点,该电触点被配置为接合生物传感器2002,使得碱基检出系统2000可与生物传感器2002通信和/或向生物传感器2002提供功率。此外,系统插座2012可包括被配置为接合生物传感器2002的流体端口(例如,喷嘴)。在一些具体实
施中,生物传感器2002以机械方式、电气方式以及流体方式可移除地耦接到系统插座2012。
[0197]
此外,碱基检出系统2000可与其他系统或网络或与其他生物测定系统2000远程通信。由生物测定系统2000获得的检测数据可储存在远程数据库中。
[0198]
图21是可在图20的系统中使用的系统控制器2004的框图。在一个具体实施中,系统控制器2004包括可彼此通信的一个或多个处理器或模块。处理器或模块中的每一者可包括用于执行特定过程的算法(例如,储存在有形和/或非暂态计算机可读储存介质上的指令)或子算法。系统控制器2004在概念上被例示为模块的集合,但可利用专用硬件板、dsp、处理器等的任何组合来实现。另选地,系统控制器2004可利用具有单个处理器或多个处理器的现成pc来实现,其中功能操作分布在处理器之间。作为进一步的选择,下文所述的模块可利用混合配置来实现,其中某些模块化功能利用专用硬件来执行,而其余模块化功能利用现成pc等来执行。模块还可被实现为处理单元内的软件模块。
[0199]
在操作期间,通信端口2120可向生物传感器2002(图20)和/或子系统2006、2008、2010(图20)传输信息(例如,命令)或从其接收信息(例如,数据)。在具体实施中,通信端口2120可输出多个像素信号序列。通信链路2120可从用户界面2014(图20)接收用户输入并且将数据或信息传输到用户界面2014。来自生物传感器2002或子系统2006、2008、2010的数据可在生物测定会话期间由系统控制器2004实时处理。除此之外或另选地,数据可在生物测定会话期间临时储存在系统存储器中,并且以比实时或脱机操作更慢的速度进行处理。
[0200]
如图21所示,系统控制器2004可包括与主控制模块2130通信的多个模块2131-2139。主控制模块2130可与用户界面2014(图20)通信。尽管模块2131-2139被示出为与主控制模块2130直接通信,但模块2131-2139也可彼此直接通信,与用户界面2014和生物传感器2002直接通信。另外,模块2131-2139可通过其他模块与主控制模块2130通信。
[0201]
多个模块2131-2139包括分别与子系统2006、2008、2010和2009通信的系统模块2131-2133、2139。流体控制模块2131可与流体控制系统2006通信,以控制流体网络的阀和流量传感器,从而控制一种或多种流体通过流体网络的流动。流体储存模块2132可在流体量低时或在废物储存器处于或接近容量时通知用户。流体储存模块2132还可与温度控制模块2133通信,使得流体可储存在所需温度下。照明模块2139可与照明系统2009通信,以在方案期间的指定时间照亮反应位点,诸如在已发生所需反应(例如,结合事件)之后。在一些具体实施中,照明模块2139可与照明系统2009通信,从而以指定角度照亮反应位点。
[0202]
多个模块2131-2139还可包括与生物传感器2002通信的设备模块2134和确定与生物传感器2002相关的识别信息的识别模块2135。设备模块2134可例如与系统插座2012通信以确认生物传感器已与碱基检出系统2000建立电连接和流体连接。识别模块2135可接收识别生物传感器2002的信号。识别模块2135可使用生物传感器2002的身份来向用户提供其他信息。例如,识别模块2135可确定并随后显示批号、制造日期或建议与生物传感器2002一起运行的方案。
[0203]
多个模块2131-2139还包括接收和分析来自生物传感器2002的信号数据(例如,图像数据)的分析模块2138(也称为信号处理模块或信号处理器)。分析模块2138包括用于储存检测数据的存储器(例如,ram或闪存)。检测数据可包括多个像素信号序列,使得可在许多碱基检出循环内检测来自数百万个传感器(或像素)中的每个传感器(或像素)的像素信号序列。信号数据可被储存用于后续分析,或者可被传输到用户界面2014以向用户显示所
需信息。在一些具体实施中,信号数据可在分析模块2138接收到信号数据之前由固态成像器(例如,cmos图像传感器)处理。
[0204]
分析模块2138被配置为在多个测序循环中的每个测序循环处从光检测器获得图像数据。图像数据来源于由光检测器检测到的发射信号,并且通过神经网络(例如,基于神经网络的模板生成器2148、基于神经网络的碱基检出器2158(例如,图4和图10)和/或基于神经网络的质量评分器2168)处理多个测序循环的每个测序循环的图像数据,并且在多个测序循环的每个测序循环处针对分析物中的至少一些产生碱基检出。
[0205]
方案模块2136和2137与主控制模块2130通信,以在进行预先确定的测定方案时控制子系统2006、2008和2010的操作。方案模块2136和2137可包括用于指示碱基检出系统2000根据预先确定的方案执行具体操作的指令集。如图所示,方案模块可以是边合成边测序(sbs)模块2136,该sbs模块被配置为发出用于执行边合成边测序过程的各种命令。在sbs中,监测核酸引物沿核酸模板的延伸,以确定模板中核苷酸的序列。基础化学过程可以是聚合(例如,由聚合酶催化)或连接(例如,由连接酶催化)。在特定的基于聚合酶的sbs具体实施中,以依赖于模板的方式将荧光标记的核苷酸添加至引物(从而使引物延伸),使得对添加至引物的核苷酸的顺序和类型的检测可用于确定模板的序列。例如,为了启动第一sbs循环,可发出命令以将一个或多个标记的核苷酸、dna聚合酶等递送至/通过容纳有核酸模板阵列的流通池。核酸模板可位于对应的反应位点。其中引物延伸导致标记的核苷酸掺入的那些反应位点可通过成像事件来检测。在成像事件期间,照明系统2009可向反应位点提供激发光。任选地,核苷酸还可以包括一旦将核苷酸添加到引物就终止进一步的引物延伸的可逆终止属性。例如,可以将具有可逆终止子部分的核苷酸类似物添加到引物,使得随后的延伸直到递送解封闭剂以除去该部分才发生。因此,对于使用可逆终止的具体实施,可发出命令以将解封闭剂递送到流通池(在检测发生之前或之后)。可发出一个或多个命令以实现各个递送步骤之间的洗涤。然后可重复该循环n次,以将引物延伸n个核苷酸,从而检测长度为n的序列。示例性测序技术描述于:例如bentley等人,nature 456:53-59(2008);wo 04/018497;us 7,057,026;wo 91/06678;wo 07/123744;us 7,329,492;us 7,211,414;us 7,315,019;us 7,405,281和us 2008/014708082,这些文献中的每一篇均以引用方式并入本文。
[0206]
对于sbs循环的核苷酸递送步骤,可一次递送单一类型的核苷酸,或者可递送多种不同的核苷酸类型(例如,a、c、t和g一起)。对于一次仅存在单一类型的核苷酸的核苷酸递送构型,不同的核苷酸不需要具有不同的标记,因为它们可基于个体化递送中固有的时间间隔来区分。因此,测序方法或装置可使用单色检测。例如,激发源仅需要提供单个波长或单个波长范围内的激发。对于其中递送导致多种不同核苷酸同时存在于流通池中的核苷酸递送构型,可基于附着到混合物中相应核苷酸类型的不同荧光标记来区分掺入不同核苷酸类型的位点。例如,可使用四种不同的核苷酸,每种核苷酸具有四种不同荧光团中的一种。在一个具体实施中,可使用在光谱的四个不同区域中的激发来区分四种不同的荧光团。例如,可使用四种不同的激发辐射源。另选地,可使用少于四种不同的激发源,但来自单个源的激发辐射的光学过滤可用于在流通池处产生不同范围的激发辐射。
[0207]
在一些具体实施中,可在具有四种不同核苷酸的混合物中检测到少于四种不同颜色。例如,核苷酸对可在相同波长下检测,但基于对中的一个成员相对于另一个成员的强度
差异,或基于对中的一个成员的导致与检测到的该对的另一个成员的信号相比明显的信号出现或消失的变化(例如,通过化学改性、光化学改性或物理改性)来区分。用于使用检测少于四种颜色区分四种不同的核苷酸的示例性装置和方法描述于例如美国专利申请序列号61/538,294和61/619,878中,其全文以引用方式并入本文。2012年9月21日提交的美国申请13/624,200也全文以引用方式并入。
[0208]
多个方案模块还可包括样品制备(或生成)模块2137,该模块被配置为向流体控制系统2006和温度控制系统2010发出命令,以用于扩增生物传感器2002内的产物。例如,生物传感器2002可接合至碱基检出系统2000。扩增模块2137可向流体控制系统2006发出指令,以将必要的扩增组分递送到生物传感器2002内的反应室。在其他具体实施中,反应位点可能已包含一些用于扩增的组分,诸如模板dna和/或引物。在将扩增组分递送到反应室之后,扩增模块2137可指示温度控制系统2010根据已知的扩增方案循环通过不同的温度阶段。在一些具体实施中,扩增和/或核苷酸掺入等温进行。
[0209]
sbs模块2136可发出命令以执行桥式pcr,其中克隆扩增子的簇形成于流通池的通道内的局部区域上。通过桥式pcr产生扩增子后,可将扩增子“线性化”以制备单链模板dna或sstdna,并且可将测序引物杂交至侧接感兴趣的区域的通用序列。例如,可如上所述或如下使用基于可逆终止子的边合成边测序方法。
[0210]
每个碱基检出或测序循环可通过单个碱基延伸sstdna,这可例如通过使用经修饰的dna聚合酶和四种类型的核苷酸的混合物来完成。不同类型的核苷酸可具有独特的荧光标记,并且每个核苷酸还可具有可逆终止子,该可逆终止子仅允许在每个循环中发生单碱基掺入。在将单个碱基添加到sstdna之后,激发光可入射到反应位点上并且可检测荧光发射。在检测后,可从sstdna化学切割荧光标记和终止子。接下来可为另一个类似的碱基检出或测序循环。在这种测序方案中,sbs模块2136可指示流体控制系统2006引导试剂和酶溶液流过生物传感器2002。可与本文所述的装置和方法一起使用的基于可逆终止子的示例性sbs方法描述于美国专利申请公布2007/0166705 a1、美国专利申请公布2006/0188901 a1、美国专利7,057,026、美国专利申请公布2006/0240439 a1、美国专利申请公布2006/02814714709 a1、pct公布wo 05/065814、美国专利申请公布2005/014700900 a1、pct公布wo 06/064199和pct公布wo 07/01470251,这些专利中的每一篇均全文以引用方式并入本文。用于基于可逆终止子的sbs的示例性试剂描述于:us 7,541,444;us 7,057,026;us 7,414,14716;us 7,427,673;us 7,566,537;us 7,592,435和wo 07/14835368,这些专利中的每一篇均全文以引用方式并入本文。
[0211]
在一些具体实施中,扩增模块和sbs模块可在单个测定方案中操作,其中例如扩增模板核酸并随后将其在同一盒内测序。
[0212]
碱基检出系统2000还可允许用户重新配置测定方案。例如,碱基检出系统2000可通过用户界面2014向用户提供用于修改所确定的方案的选项。例如,如果确定生物传感器2002将用于扩增,则碱基检出系统2000可请求退火循环的温度。此外,如果用户已提供对于所选测定方案通常不可接受的用户输入,则碱基检出系统2000可向用户发出警告。
[0213]
在具体实施中,生物传感器2002包括数百万个传感器(或像素),每个传感器(或像素)在后续的碱基检出循环内生成多个像素信号序列。分析模块2138根据传感器阵列上传感器的逐行和/或逐列位置来检测多个像素信号序列并且将它们归属于对应的传感器(或
像素)。
[0214]
传感器阵列中的每个传感器可产生流通池的区块的传感器数据,其中区块位于流通池上的在碱基检出操作期间设置遗传物质的簇的区域中。传感器数据可包括像素阵列中的图像数据。对于给定循环,传感器数据可包括多于一个图像,从而产生多特征每像素作为区块数据。
[0215]
如本文所用,“逻辑”(例如,数据流逻辑)可以计算机产品的形式来实现,该计算机产品包括具有用于执行本文所述的方法步骤的计算机可用程序代码的非暂态计算机可读储存介质。“逻辑”可以装置的形式来实现,该装置包括存储器和耦接到存储器并且可操作以执行示例性方法步骤的至少一个处理器。“逻辑”可以用于执行本文所述的方法步骤中的一个或多个方法步骤的装置的形式来实现;该装置可包括(i)硬件模块、(ii)在一个或多个硬件处理器上执行的软件模块,或(iii)硬件模块和软件模块的组合;(i)-(iii)中的任一者实现本文阐述的具体技术,并且软件模块储存在计算机可读储存介质(或多个此类介质)中。在一个具体实施中,逻辑实现数据处理功能。逻辑可以是具有指定功能的计算机程序的通用单核或多核处理器、具有计算机程序的数字信号处理器、具有配置文件的可配置逻辑(诸如fpga)、专用电路(诸如状态机),或这些的任何组合。另外,计算机程序产品可体现计算机程序和逻辑的配置文件部分。
[0216]
图22是可用于实现所公开的技术的计算机系统2200的简化框图。计算机系统2200包括经由总线子系统2255与多个外围设备通信的至少一个中央处理单元(cpu)2272。这些外围设备可包括储存子系统2210,该储存子系统包括例如存储器设备和文件储存子系统2236、用户界面输入设备2238、用户界面输出设备2276和网络接口子系统2274。输入和输出设备允许用户与计算机系统2200进行交互。网络接口子系统2274提供到外部网络的接口,包括提供到其他计算机系统中的对应接口设备的接口。
[0217]
用户界面输入设备2238可包括:键盘;指向设备,诸如鼠标、轨迹球、触摸板或图形输入板;扫描仪;结合到显示器中的触摸屏;音频输入设备,诸如语音识别系统和麦克风;以及其他类型的输入设备。一般来讲,使用术语“输入设备”旨在包括将信息输入到计算机系统2200中的所有可能类型的设备和方式。
[0218]
用户界面输出设备2276可包括显示子系统、打印机、传真机或非视觉显示器诸如音频输出设备。显示子系统可包括led显示器、阴极射线管(crt)、平板设备诸如液晶显示器(lcd)、投影设备或用于产生可见图像的一些其他机构。显示子系统还可提供非视觉显示器,诸如音频输出设备。一般来讲,使用术语“输出设备”旨在包括将信息从计算机系统2200输出到用户或输出到另一个机器或计算机系统的所有可能类型的设备和方式。
[0219]
储存子系统2210储存提供本文所述的一些或全部模块的功能和方法的编程和数据构造。这些软件模块通常由深度学习处理器2278执行。
[0220]
在一个具体实施中,神经网络使用深度学习处理器2278来实现,这些深度学习处理器可以是可配置和可重构处理器、现场可编程门阵列(fpga)、专用集成电路(asic)和/或粗粒度可重构架构(cgra)和图形处理单元(gpu)或其他配置的设备。深度学习处理器2278可由深度学习云平台(诸如google cloud platform
tm
、xilinx
tm
和cirrascale
tm
)托管。深度学习处理器14978的示例包括google的tensor processing unit(tpu)
tm
、机架解决方案(如gx4 rackmount series
tm
、gx149 rackmount series
tm
)、nvidia dgx-1
tm
、microsoft的
stratix v fpga
tm
、graphcore的intelligent processor unit(ipu)
tm
、qualcomm的具有snapdragon processors
tm
的zeroth platform
tm
、nvidia的volta
tm
、nvidia的drive px
tm
、nvidia的jetson tx1/tx2 module
tm
、intel的nirvana
tm
、movidius vpu
tm
、fujitsu dpi
tm
、arm的dynamiciq
tm
、ibm truenorth
tm
等。
[0221]
在储存子系统2210中使用的存储器子系统2222可包括多个存储器,包括用于在程序执行期间储存指令和数据的主随机存取存储器(ram)2232和其中储存固定指令的只读存储器(rom)2234。文件储存子系统2236可为程序文件和数据文件提供持久性储存,并且可包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、cd-rom驱动器、光盘驱动器或可移动介质磁带盘。实现某些具体实施的功能的模块可由文件储存子系统2236储存在储存子系统2210中,或储存在处理器可访问的其他机器中。
[0222]
总线子系统2255提供用于使计算机系统2200的各种部件和子系统按照预期彼此通信的机构。尽管总线子系统2255被示意性地示出为单个总线,但总线子系统的另选具体实施可使用多条总线。
[0223]
计算机系统2200本身可具有不同类型,包括个人计算机、便携式计算机、工作站、计算机终端、网络计算机、电视机、主机、服务器群、一组广泛分布的松散联网的计算机或任何其他数据处理系统或用户设备。由于计算机和网络的不断变化的性质,对图22中描绘的计算机系统2200的描述仅旨在作为用于例示本发明的优选具体实施的具体示例。计算机系统2200的许多其他配置是可能的,其具有比图22中描绘的计算机系统更多或更少的部件。
[0224]
条款
[0225]
1.一种用于分析碱基检出传感器输出的系统,该系统包括:
[0226]
主机处理器;
[0227]
存储器,该存储器能够由该主机处理器访问,该存储器储存区块数据,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据阵列;和
[0228]
神经网络处理器,该神经网络处理器能够访问该存储器,该神经网络处理器包括:
[0229]
多个执行簇,该多个执行簇中的这些执行簇被配置为执行神经网络;和
[0230]
数据流逻辑,该数据流逻辑能够访问该存储器和该多个执行簇中的执行簇,以将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括来自包括受试者感测循环的相应感测循环的区块数据阵列的数字n个空间对准补片,并且致使这些执行簇将该n个空间对准补片应用于该神经网络以产生该受试者感测循环的该空间对准补片的分类数据的输出补片,其中n大于1。
[0231]
2.根据条款1所述的系统,该系统包括:组装逻辑,该组装逻辑用于组装来自该多个执行簇的这些输出补片以提供该受试者循环的碱基检出分类数据,并且将该碱基检出分类数据储存在存储器中。
[0232]
3.根据条款1所述的系统,其中该多个执行簇中的执行簇包括:一组计算引擎,该一组计算引擎具有多个成员,被配置为使用经训练参数对该神经网络的多个层的输入数据进行卷积,其中第一层的输入数据是来自这些输入单元,并且后续层的数据是来自从先前层输出的激活数据。
[0233]
4.根据条款3所述的系统,该系统包括:存储器,该存储器储存所述神经网络的经训练参数的多个版本,并且其中该神经网络处理器中的该多个簇中的簇被配置为包括内核
存储器以储存这些经训练参数,并且该数据流逻辑被配置为将经训练参数的实例提供到该多个执行簇中的执行簇的该内核存储器以用于执行该神经网络。
[0234]
5.根据条款4所述的系统,其中这些经训练参数的实例根据该碱基检出操作的这些感测循环中的循环数进行应用。
[0235]
6.根据条款1所述的系统,其中该多个执行簇中的执行簇包括一组计算引擎,该一组计算引擎具有多个成员,该一组计算引擎被配置为向来自该输入单元的子补片和来自从该神经网络的层输出的激活数据的子补片应用用于该神经网络的对应层的多个可配置滤波器。
[0236]
7.根据条款1所述的系统,其中该神经网络针对输入单元的每个空间对准补片执行空间层的隔离叠堆,并且将从这些隔离叠堆输出的来自该n个空间对准补片的数据提供到一个或多个组合层。
[0237]
8.根据条款7所述的系统,其中该多个执行簇中的执行簇被配置为使用所输入的该n个空间对准补片的传感器数据来执行空间层的n个隔离叠堆,以产生该受试者感测循环的该空间对准补片的分类数据的输出补片。
[0238]
9.根据条款7所述的系统,其中该多个执行簇中的执行簇被配置为使用当前空间对准补片的传感器数据来执行空间层的隔离叠堆,将该空间对准补片的中间数据反馈到该存储器以用作其他循环的输入单元中的区块数据,并且将来自先前循环的该中间数据和当前循环的该隔离叠堆的输出提供到该一个或多个组合层以产生该受试者感测循环的该输出补片。在一个具体实施中,该存储器是片上或片外dram或片上存储器,如sram或bram,并且处理器的处理单元执行该神经网络。在此类具体实施中,来自先前循环的该中间数据从该存储器发送到这些片上处理元件(例如,经由dma引擎)以通过例如组合层来进行处理,这些组合层由该芯片执行以作为该芯片/处理器上的该神经网络执行的一部分。
[0239]
10.根据条款1所述的系统,其中该数字n是等于5或更大的整数。
[0240]
11.根据条款1所述的系统,其中逻辑电路被配置为加载遍历多个感测循环的这些区块数据阵列的序列中的输入单元,该加载包括在由执行簇针对先前输入单元执行该神经网络期间将该序列中的下一个输入单元写入该神经网络处理器以用于该执行簇。
[0241]
12.根据条款1所述的系统,该系统包括:该主机处理器中的用于对这些输出补片执行激活函数的逻辑。
[0242]
13.根据条款1所述的系统,该系统包括:该主机处理器中的用于对这些输出补片执行softmax函数的逻辑。
[0243]
14.根据条款1所述的系统,其中这些区块数据阵列包括m个特征,其中m大于一。
[0244]
15.根据条款7所述的系统,该系统包括:针对碱基检出操作的这些区块的区块簇掩膜,该区块簇掩膜储存在该存储器中,并且这些执行簇被配置为使用该区块簇掩膜移除来自出自这些层中的至少一个层的中间数据的数据。
[0245]
16.一种用于分析碱基检出传感器输出的计算机实现的方法,该方法包括:
[0246]
将区块数据储存在存储器中,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据阵列;以及
[0247]
使用多个执行簇对该区块数据执行神经网络,该执行包括:
[0248]
将区块数据的输入单元提供到该多个执行簇中的可用执行簇,这些输入单元包括
来自包括受试者感测循环的相应感测循环的区块数据阵列的数字n个空间对准补片,以及致使这些执行簇将该n个空间对准补片应用于该神经网络以产生该受试者感测循环的该空间对准补片的分类数据的输出补片,其中n大于1。
[0249]
17.根据条款16所述的计算机实现的方法,该方法包括:组装来自该多个执行簇的这些输出补片以提供该受试者循环的碱基检出分类数据,以及将该碱基检出分类数据储存在存储器中。
[0250]
18.根据条款16所述的计算机实现的方法,其中该多个执行簇中的执行簇包括:一组计算引擎,该一组计算引擎具有多个成员,被配置为使用经训练参数对该神经网络的多个层的输入数据进行卷积,其中第一层的输入数据是来自该输入单元,并且后续层的数据是来自从先前层输出的激活数据。
[0251]
19.根据条款18所述的计算机实现的方法,该方法包括:储存该神经网络的经训练参数的多个版本,并且其中神经网络处理器中的该多个执行簇中的簇被配置为包括内核存储器以储存这些经训练参数;以及将经训练参数的实例提供到该多个执行簇中的执行簇的该内核存储器以用于执行该神经网络。
[0252]
20.根据条款19所述的计算机实现的方法,该方法包括:根据该碱基检出操作的这些感测循环中的循环数来应用这些经训练参数的实例。
[0253]
21.根据条款16所述的计算机实现的方法,其中该多个执行簇中的执行簇包括一组计算引擎,该一组计算引擎具有多个成员,该一组计算引擎被配置为向来自该输入单元的子补片和来自从该神经网络的层输出的激活数据的子补片应用用于该神经网络的对应层的多个可配置滤波器。
[0254]
22.根据条款16所述的计算机实现的方法,其中该神经网络针对输入单元的每个空间对准补片包括空间层的隔离叠堆,并且将从这些隔离叠堆输出的来自该n个空间对准补片的数据提供到一个或多个组合层。
[0255]
23.根据条款22所述的计算机实现的方法,其中该多个执行簇中的执行簇被配置为使用所输入的该n个空间对准补片的传感器数据来执行空间层的n个隔离叠堆,以产生该受试者感测循环的该空间对准补片的分类数据的输出补片。
[0256]
24.根据条款22所述的计算机实现的方法,其中该多个执行簇中的执行簇被配置为使用当前空间对准补片的传感器数据来执行空间层的隔离叠堆,将该空间对准补片的中间数据反馈到该存储器以用作其他循环的输入单元中的区块数据,并且将来自先前循环的该中间数据和当前循环的该隔离叠堆的输出提供到该一个或多个组合层以产生该受试者感测循环的该输出补片。
[0257]
25.根据条款16所述的计算机实现的方法,其中该数字n是等于5或更大的整数。
[0258]
26.根据条款16所述的计算机实现的方法,该方法包括:加载遍历多个感测循环的这些区块数据阵列的序列中的输入单元,该加载包括在由执行簇针对先前输入单元执行该神经网络期间将该序列中的下一个输入单元写入该执行簇。
[0259]
27.根据条款16所述的计算机实现的方法,该方法包括:对这些输出补片执行激活函数。
[0260]
28.根据条款16所述的计算机实现的方法,该方法包括:对这些输出补片执行softmax函数。
[0261]
29.根据条款16所述的计算机实现的方法,其中这些区块数据阵列包括m个特征,其中m大于一。
[0262]
30.根据条款16所述的计算机实现的方法,该方法包括:对储存在该存储器中的针对碱基检出操作的这些区块的区块簇掩膜进行储存,并且使用该区块簇掩膜移除来自出自这些层中的至少一个层的该中间数据的数据。
[0263]
31.一种用于分析碱基检出传感器输出的系统,该系统包括:
[0264]
存储器,该存储器能够由该运行时程序访问,该存储器储存区块数据,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据;
[0265]
神经网络处理器,该神经网络处理器能够访问该存储器,该神经网络处理器被配置为使用经训练参数执行神经网络的运行以产生感测循环的分类数据,该神经网络的运行对来自包括受试者循环的n个感测循环中的相应感测循环的区块数据的n个阵列的序列进行操作,以产生该受试者循环的分类数据;和
[0266]
数据流逻辑,该数据流逻辑使用输入单元将区块数据和这些经训练参数从该存储器移动到该神经网络处理器以用于该神经网络的运行,该输入单元包括来自n个感测循环中的相应感测循环的该n个阵列的空间对准补片的数据。
[0267]
32.根据条款31所述的系统,其中该存储器中的感测循环的该区块数据包括该感测循环的传感器数据和该感测循环的从该神经网络馈送回的中间数据中的一者或两者。
[0268]
33.根据条款31所述的系统,其中该存储器储存区块簇掩膜,该区块簇掩膜识别这些传感器数据阵列中的表示该区块中的流通池簇的位置的元素,并且该神经网络处理器包括用于将该区块簇掩膜应用于该神经网络中的中间数据的掩膜逻辑。
[0269]
34.根据条款31所述的系统,该数据流逻辑包括使用配置数据配置的该神经网络处理器的元件。
[0270]
35.根据条款31所述的系统,该系统包括:主机处理系统,该主机处理系统包括运行时程序,并且该数据流逻辑包括用于与该主机上的该运行时程序协调这些运行的逻辑。
[0271]
36.根据条款31所述的系统,该系统包括:主机处理系统,该主机处理系统包括运行时程序,该运行时程序的逻辑将来自这些感测循环的该区块数据和该神经网络的这些经训练参数提供到该存储器。
[0272]
37.根据条款31所述的系统,其中该存储器中的感测循环的该区块数据包括该感测循环的传感器数据和该感测循环的从该神经网络馈送回的中间数据中的一者或两者。
[0273]
38.根据条款31所述的系统,其中感测循环的该传感器数据包括表示用于每个流通池簇检测一个碱基的信号的数据。
[0274]
39.根据条款31所述的系统,其中该神经网络处理器被配置为形成多个执行簇,该多个执行簇中的这些执行逻辑簇对该区块数据的空间对准补片运行该神经网络;并且
[0275]
其中该数据流逻辑能够访问该存储器以及该多个执行簇中的执行簇,以向该多个执行簇中的可用执行簇提供区块数据的输入单元并且致使这些执行簇将这些输入单元的该n个空间对准补片的区块数据应用于该神经网络以产生该受试者循环的分类数据的输出补片。
[0276]
40.根据条款39所述的系统,该系统包括:组装逻辑,该组装逻辑用于组装来自该多个执行簇的这些输出补片以提供该受试者循环的碱基检出分类数据,并且将该碱基检出
分类数据储存在存储器中。
[0277]
41.根据条款39所述的系统,其中该多个执行簇中的执行簇包括:一组计算引擎,该一组计算引擎具有多个成员,被配置为使用经训练参数对该神经网络的多个层的输入数据进行卷积,其中第一层的输入数据是来自这些输入单元,并且后续层的数据是来自从先前层输出的激活数据。
[0278]
42.根据条款41所述的系统,该系统包括:存储器,该存储器储存所述神经网络的经训练参数的多个版本,并且其中该神经网络处理器中的该多个簇中的簇被配置为包括内核存储器以储存这些经训练参数,并且该数据流逻辑被配置为将经训练参数的实例提供到该多个执行簇中的执行簇的该内核存储器以用于执行该神经网络。
[0279]
43.根据条款42所述的系统,其中这些经训练参数的实例根据该碱基检出操作的这些感测循环中的循环数进行应用。
[0280]
44.根据条款39所述的系统,其中该多个执行簇中的执行簇包括一组计算引擎,该一组计算引擎具有多个成员,该一组计算引擎被配置为向来自该输入单元的子补片和来自从该神经网络的层输出的激活数据的子补片应用用于该神经网络的对应层的多个可配置滤波器。
[0281]
45.根据条款39所述的系统,其中该多个执行簇中的执行簇被配置为使用当前空间对准补片的传感器数据来执行空间层的隔离叠堆,将该空间对准补片的中间数据反馈到该存储器以用作其他输入单元中的区块数据,并且将来自先前循环的该中间数据和当前循环的该隔离叠堆的输出提供到该一个或多个组合层以产生该受试者感测循环的该输出补片。
[0282]
46.根据条款31所述的系统,其中该数字n是等于5或更大的整数。
[0283]
47.根据条款31所述的系统,其中这些逻辑电路被配置为加载遍历多个感测循环的这些区块数据阵列的序列中的输入单元,该加载包括在由执行簇针对先前输入单元执行该神经网络期间将该序列中的下一个输入单元写入该神经网络处理器以用于该执行簇。
[0284]
48.根据条款31所述的系统,该系统包括:该主机处理器中的用于对这些输出补片执行激活函数的逻辑。
[0285]
49.根据条款31所述的系统,该系统包括:该主机处理器中的用于对这些输出补片执行softmax函数的逻辑。
[0286]
50.根据条款31所述的系统,其中这些区块数据阵列包括m个特征,其中m大于一。
[0287]
51.根据前述条款中任一项所述的系统,其中该神经网络处理器是可重构处理器。
[0288]
52.根据前述条款中任一项所述的系统,其中该神经网络处理器是可配置处理器。
[0289]
53.一种用于分析碱基检出传感器输出的计算机实现的方法,该方法包括:
[0290]
将区块数据储存在存储器中,该区块数据包括来自碱基检出操作的感测循环的区块的传感器数据;
[0291]
使用经训练参数执行神经网络的运行以产生感测循环的分类数据,该神经网络的运行对来自包括受试者循环的n个感测循环中的相应感测循环的区块数据的n个阵列的序列进行操作,以产生该受试者循环的分类数据;以及
[0292]
使用输入单元将区块数据和这些经训练参数从存储器移动到该神经网络以用于该神经网络的运行,这些输入单元包括来自n个感测循环中的相应感测循环的该n个阵列的
空间对准补片的数据。
[0293]
54.根据条款53所述的计算机实现的方法,其中该存储器中的感测循环的该区块数据包括该感测循环的传感器数据和该感测循环的从该神经网络馈送回的中间数据中的一者或两者。
[0294]
55.根据条款53所述的计算机实现的方法,该方法包括:储存区块簇掩膜,该区块簇掩膜识别这些传感器数据阵列中的表示该区块中的流通池簇的位置的元素,以及将该区块簇掩膜应用于该神经网络中的中间数据。
[0295]
56.根据条款53所述的计算机实现的方法,该数据流逻辑包括使用配置数据配置的该神经网络处理器的元件。
[0296]
57.根据条款53所述的计算机实现的方法,其中该存储器中的感测循环的该区块数据包括该感测循环的传感器数据和该感测循环的从该神经网络馈送回的中间数据中的一者或两者。
[0297]
58.根据条款53所述的计算机实现的方法,其中感测循环的该传感器数据包括表示用于每个流通池簇检测一个碱基的信号的数据。
[0298]
59.根据条款53所述的计算机实现的方法,该方法包括:使用对该区块数据的空间对准补片运行该神经网络的多个执行簇;以及
[0299]
向该多个执行簇中的可用执行簇提供区块数据的输入单元以及致使这些执行簇将这些输入单元的该n个空间对准补片的区块数据应用于该神经网络以产生该受试者循环的分类数据的输出补片。
[0300]
60.根据条款59所述的计算机实现的方法,该方法包括:组装来自该多个执行簇的这些输出补片以提供该受试者循环的碱基检出分类数据,以及将该碱基检出分类数据储存在存储器中。
[0301]
61.根据条款59所述的计算机实现的方法,其中该多个执行簇中的执行簇包括:一组计算引擎,该一组计算引擎具有多个成员,被配置为使用经训练参数对该神经网络的多个层的输入数据进行卷积,其中第一层的输入数据是来自该输入单元,并且后续层的数据是来自从先前层输出的激活数据。
[0302]
62.根据条款61所述的计算机实现的方法,该方法包括:储存该神经网络的经训练参数的多个版本,并且其中神经网络处理器中的该多个簇中的簇被配置为包括内核存储器以储存这些经训练参数;以及将经训练参数的实例提供到该多个执行簇中的执行簇的该内核存储器以用于执行该神经网络。
[0303]
63.根据条款62所述的计算机实现的方法,其中这些经训练参数的实例根据该碱基检出操作的这些感测循环中的循环数进行应用。
[0304]
64.根据条款59所述的计算机实现的方法,其中该多个执行簇中的执行簇包括一组计算引擎,该一组计算引擎具有多个成员,该一组计算引擎被配置为向来自该输入单元的子补片和来自从该神经网络的层输出的激活数据的子补片应用用于该神经网络的对应层的多个可配置滤波器。
[0305]
65.根据条款59所述的计算机实现的方法,其中该多个执行簇中的执行簇被配置为使用当前空间对准补片的传感器数据来执行空间层的隔离叠堆,将该空间对准补片的中间数据反馈到该存储器以用作其他输入单元中的区块数据,并且将来自先前循环的该中间
数据和当前循环的该隔离叠堆的输出提供到该一个或多个组合层以产生该受试者感测循环的该输出补片。
[0306]
66.根据条款53所述的计算机实现的方法,其中该数字n是等于5或更大的整数。
[0307]
67.根据条款53所述的计算机实现的方法,该方法包括:加载遍历多个感测循环的这些区块数据阵列的序列中的输入单元,该加载包括在针对先前输入单元执行该神经网络期间将该序列中的下一个输入单元写入该神经网络。
[0308]
68.根据条款53所述的计算机实现的方法,其中这些区块数据阵列包括m个特征,其中m大于一。
[0309]
69.根据前述计算机实现的方法条款中任一项所述的计算机实现的方法,该方法包括:配置可配置处理器以执行该神经网络。
[0310]
70.根据前述计算机实现的方法条款中任一项所述的计算机实现的方法,该方法包括:配置可重构处理器以执行该神经网络。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1