软件加速基因组读段映射的制作方法
背景技术:
1、本技术要求2020年9月15日提交的美国申请序列号63/078,890的权益,该申请全文以引用方式并入。
技术实现思路
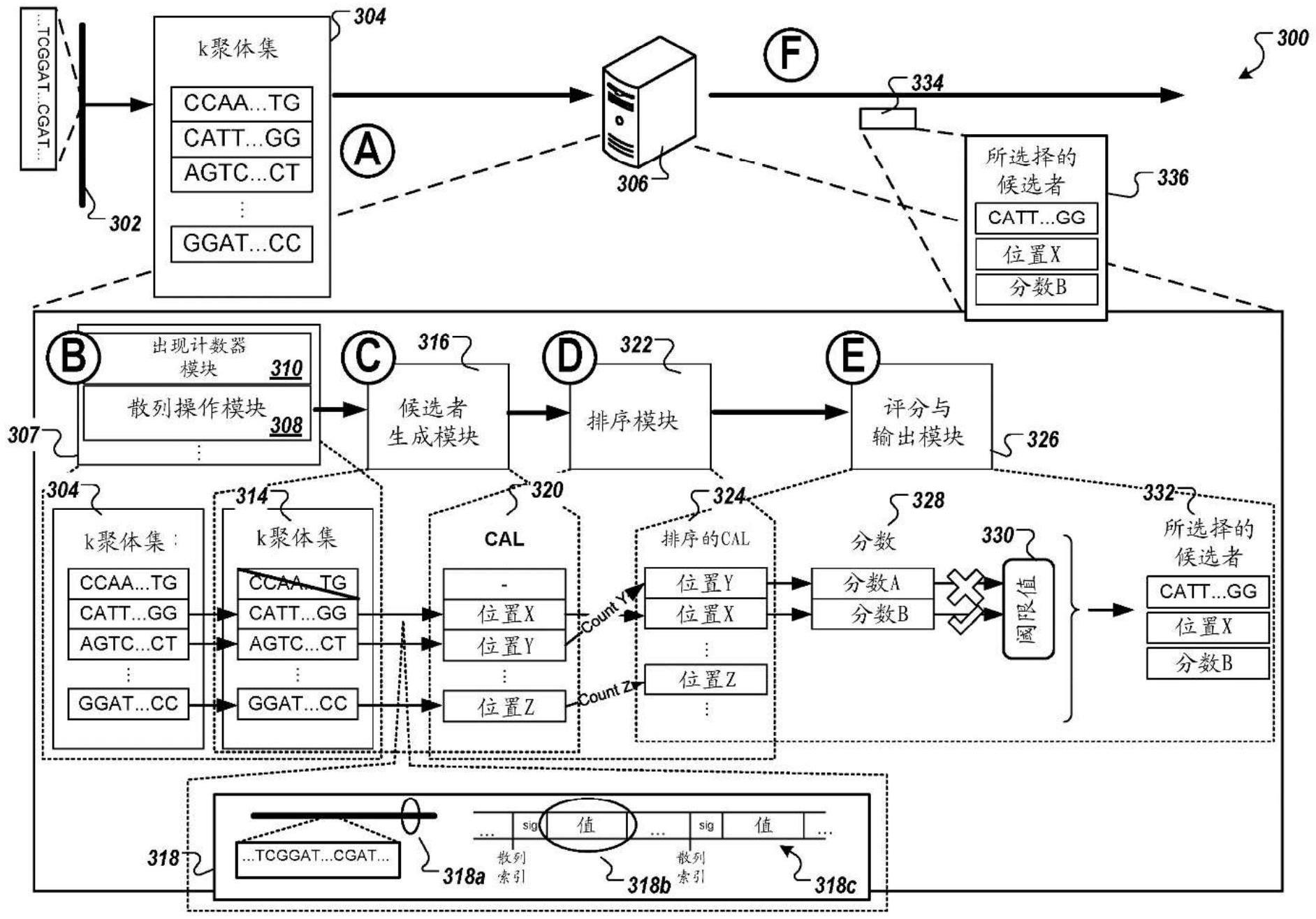
1、本公开涉及用于软件加速基因组读段映射的方法、系统和计算机程序。在一个方面,本公开涉及有利于软件加速基因组读段映射的散列表的生成。该散列表可包括表示使用基因组数据签名索引的参考基因组的数据。在一些具体实施中,所生成的散列表可用于确定所接收的基因组读段和参考基因组之间的映射。
2、根据本公开的一个创新方面,公开了一种用于软件加速基因组数据读段映射的方法。在一个方面,该方法可包括以下动作:由一个或多个计算机从基因组数据读段获得k聚体种子;由一个或多个计算机基于所获得的k聚体种子生成基因组签名;由一个或多个计算机使用散列数据结构确定与该k聚体种子的至少一部分匹配的参考序列位置,其中该散列数据结构包括n个数据单元,这些数据单元包括第一部分和第二部分,该第一部分存储预先确定的基因组签名,该第二部分存储与同该预先确定的基因组签名所来源于的k聚体种子的至少一部分匹配的参考序列位置的第一次出现相对应的值;以及由一个或多个计算机基于一个或多个比对分数选择所确定的参考序列位置作为所获得的k聚体种子的实际比对。
3、其他版本包括已经被配置为执行前述方法的动作的对应系统、装置和计算机程序。
4、这些和其他版本可任选地包括以下特征中的一个或多个特征。例如,在一些具体实施中,该预先确定的基因组签名可仅占用一个存储器存储字节。
5、在一些具体实施中,该值可仅占用四个存储器存储字节。
6、在一些具体实施中,该散列数据结构是具有n个数据单元的单个数组。
7、在一些具体实施中,该方法还可包括:由一个或多个计算机基于与该基因组数据读段的一个或多个k聚体种子相对应的第一值集过滤该基因组数据读段。
8、在一些具体实施中,该第一值集可包括应用于该基因组数据读段的该一个或多个k聚体种子的预先确定的操作的结果,并且其中该第一值集用于从该基因组数据读段获得该k聚体种子。
9、在一些具体实施中,该预先确定的操作可包括该基于基因组数据读段的该一个或多个k聚体种子和散列函数生成散列值。
10、在一些具体实施中,确定该参考序列位置可包括:由一个或多个计算机计算该基因组数据读段的该k聚体种子的第一位置,其中该第一位置对应于该k聚体种子在该基因组数据读段内的位置;以及计算该k聚体种子的第二位置,其中该第二位置对应于该k聚体种子在该参考基因组数据内的位置,并且其中该第二位置是基于该散列数据结构计算的。
11、在一些具体实施中,该方法还可包括:由一个或多个计算机基于该散列数据结构和该基因组数据读段对该一个或多个参考序列位置进行排序。
12、在一些具体实施中,该方法还可包括:由一个或多个计算机基于对该一个或多个参考序列位置进行排序来生成该一个或多个比对分数。
13、在一些具体实施中,该方法还可包括:选择所确定的参考序列位置中的至少一个参考序列位置作为所获得的k聚体种子的该实际比对包括:将该一个或多个比对分数与阈限值进行比较。
14、在一些具体实施中,该方法还可包括:该一个或多个比对分数包括表示来自该基因组数据读段的所获得的k聚体种子和该参考序列位置之间的不匹配的数量的数值。
15、在一些具体实施中,丢弃在与该预先确定的基因组签名所来源于的该k聚体种子的至少一部分匹配的参考序列位置的第一次出现之后的每次后续出现。
16、根据本公开的另一创新方面,公开了一种用于生成用于软件加速基因组数据读段映射的散列表的方法。在一个方面,该方法可包括:由一个或多个计算机接收基因组数据,其中该基因组数据来源于亲本基因组数据;由一个或多个计算机基于该基因组数据生成第一值集;由一个或多个计算机基于该第一值集生成该基因组数据的子集;由一个或多个计算机计算该基因组数据的该子集中的每个k聚体的签名,其中该签名是基于第一散列函数计算的;由一个或多个计算机计算该基因组数据的该子集中的每个k聚体的第一属性,其中该第一属性包括该基因组数据的给定k聚体在该基因组数据的序列内的位置;由一个或多个计算机计算该基因组数据的该子集中的每个k聚体的索引,其中该索引是基于第二散列函数计算的;以及由一个或多个计算机基于该基因组数据的该子集中的每个k聚体的该索引将该基因组数据的该子集中的每个k聚体的该签名和该第一属性存储在散列数据结构内。
17、其他版本包括已经被配置为执行前述方法的动作的对应系统、装置和计算机程序。
18、这些和其他版本可任选地包括以下特征中的一个或多个特征。例如,在一些具体实施中,该基因组数据的该子集中的每个k聚体是包括表示一串一个或多个核苷酸的k个字母的k聚体。
19、在一些具体实施中,该第一值集可包括该基因组数据的给定k聚体在该亲本基因组数据内出现的次数的表示。
20、在一些具体实施中,该第一值集包括基于该基因组数据的对应k聚体计算的散列值的表示。
21、在一些具体实施中,用于存储该子集中的给定k聚体的签名的存储器分配大小小于用于存储该给定k聚体的存储器分配大小。
22、在一些具体实施中,该方法还可包括:由一个或多个计算机将对应于该散列数据结构的数据作为数据包发送到第一设备。
23、在一些具体实施中,该第一设备是存储器存储设备。
24、在一些具体实施中,第二设备从第一设备读取对应于该散列数据结构的该数据。在此类具体实施中,该第二设备可执行一连串操作以基于对应于该散列数据结构的该数据生成第二散列数据结构。
25、如本文所用的种子通常是指从基因组数据读段识别、获得或提取的一连串碱基调用或核苷酸。
26、k聚体(在本文中也称为k聚体种子)是元素(诸如碱基调用或核苷酸)的序列,其中给定k聚体的序列中的元素(例如,碱基调用或核苷酸)的数量由“k”定义。
27、基因组数据读段通常包括由核酸测序仪生成的数据,该数据对应于由该核酸测序仪测序的样品基因组的一部分的碱基调用或核苷酸。
28、基因组签名(在本文中也称为签名)是或包括识别散列表位置(例如,桶、时隙或单元)的数据。这种数据也可称为散列键,例如,基因组散列键。如果签名是从识别基因组数据的位置生成或指向该位置,则该签名是基因组签名。
29、参考序列位置是指参考序列(例如,参考核酸序列)的特定位点或部分。
30、散列数据结构以关联方式存储数据,并且可包括使用散列函数将散列键映射到存储器位置、桶或单元的数据结构。
31、比对分数是或包括指示映射到特定参考序列的基因组数据读段或k聚体种子实际上对应于该特定参考序列位置的置信度水平的数据。
32、基因组数据可包括与受试者(例如,人类受试者)的基因组相关的任何数据。
33、亲本基因组数据可包括从其提取基因组数据的子集的基因组数据的任何超集。例如,基因组数据读段可以是可从其提取k聚体种子的亲本基因组的示例。
34、“基于”特定基因组数据的值是来源于该基因组数据的值。
35、当使用多个散列函数时,第一散列函数可包括散列函数的初次出现。术语第一散列函数的使用并不意味着第一散列函数不同于所使用的任何后续散列函数,但可不同。
36、索引是可用于识别其他数据的存储位置的任何数据。
37、当使用多个散列函数时,第二散列函数可包括散列函数的后续出现。术语第二散列函数的使用并不意味着第二散列函数不同于先前使用的任何先前散列函数,但可不同。
38、如本文所述的所生成的散列表及其使用可提供多个技术益处。技术益处可包括与常规方法相比更快且需要更少存储器和存储要求的软件加速基因组读段映射算法。这些益处可至少部分地基于将基因组读段编码成一字节基因组数据签名以用作散列键以及使用单个数组散列表来实现。这些益处可至少部分地基于将基因组读段编码成一字节基因组数据签名以用作散列键以及使用单个数组散列表来实现。
39、除非另有定义,否则本文所用的所有技术和科学术语的含义与本发明所属领域的普通技术人员通常理解的含义相同。虽然与本文所述的方法和材料类似或等同的方法和材料也可用于本发明的实践或测试,但合适的方法和材料如下所述。本文提及的所有出版物、专利申请、专利和其他参考文献均全文以引用方式并入本文。如发生矛盾,以本说明书及其所包括的定义为准。此外,所述材料、方法和示例仅为例示性的,并非旨在进行限制。
40、本发明的一个或多个实施方案的细节在附图和下文的描述中进行阐述。根据描述、附图和权利要求,本发明的其他特征和优点将显而易见。
- 还没有人留言评论。精彩留言会获得点赞!