一种多模型集成学习提升逆合成可信度的方法与流程
1.本技术涉及计算机技术领域,特别是涉及一种化学反应逆合成的预测方法和装置。
背景技术:
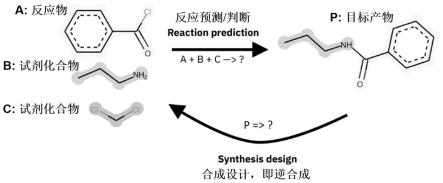
2.在药物化学应用领域中新化学分子的有机合成,需要对每一步要合成的目标产物p拆分成更容易购买或合成的反应物,称为逆合成,即逆推能发生反应得到p的反应物a+b+c。逆合成通常有多种分解策略产生多种候选反应,对于有机化学家设想的或计算机算法虚拟产生的候选反应,需进行正向预测的判断,避免实验失败产生损失和浪费。自动进行逆合成设计是实现自动有机合成设计装置的必要步骤。
3.通过大量有机化学反应数据训练的人工智能(ai)、特别是深度学习模型,为逆合成(retrosynthesis)和反应正向预测(reactionprediction)提供的有效建模途径。在自动化进行有机合成反应的装置中,反应预测能作为判断单步逆合成产生的反应是否通过的“裁判”,而自动合成路线是否成功依赖于对候选单步反应的判断准确度。
4.目前,逆合成产生模型产生的多个候选反应准确率较低,需要进一步开发准确率更高的逆合成预测方法。
技术实现要素:
5.基于此,有必要针对目前反应预测模型预测准确度不高的技术问题,提供一种化学反应产物的预测方法和装置。
6.在一方面中,本发明公开了一种逆合成化学反应物的预测方法,所述方法包括:
7.步骤1:训练并输出m》1个逆合成模型,rmt1、rmt2、
…
rmtm,训练并输出n》1个正向反应预测模型fmt1、fmt2、
…
fmtn;
8.步骤2:对逆合成模型生成的反应物做去重处理,去除重复的反应物,保留剩余候选反应物;
9.步骤3:将候选反应物和候选主干反应通过正向反应预测模型进行可信度计算,获得n个模型的n≤n个可信度conf1、conf2、
…
confn,输出平均可信度c,通过c≥th筛选最终通过的候选反应物,th选自 0.2至1.0中的任意数,优选为0.9至1.0中的任意数。
10.在一个具体实施例中,所述重复的反应物为多个逆合成模型中重复的反应试剂、反应条件中的一种或多种。
11.在一个具体实施例中,其中步骤1中逆合成模型的产生方法包括:随机种子初始化网络参数、从数据集中采样不同的样本构造训练集或不同的transformer网络架构。
12.在一个具体实施例中,其中步骤1中正向模型的产生方法包括:随机种子初始化网络参数或从数据集中采样不同的样本构造训练集。
13.在一个具体实施例中,其中步骤2中去除重复的主干反应的步骤包括:逆合成模型一次产生多个候选反应,若候选反应包括重复的反应物,则对重复的反应物进行删除只留
一个实例;将删除重复后的候选反应的化合物进行按原子数或字符长度的排序,若排序后的两个主干反应的排序化合物通过标准化的smiles表示均完全相同并可完全匹配,判断为重复并只保留一个。
14.在一个具体实施例中,其中步骤3中所述平均可信度c计算方法如下:
15.另一方面,本发明提供了一种化学反应产物的预测装置,所述装置包括:
16.第一模块,用于训练并输出m》1个逆合成模型,rmt1、rmt2、
…ꢀ
rmtm,训练并输出n》1个正向反应预测模型fmt1、fmt2、
…
fmtn;
17.第二模块,用于对逆合成模型生成的反应物做去重处理,去除重复的反应物和重复的主干反应,保留剩余候选反应物和候选主干反应;
18.第三模块,用于将候选反应物和候选主干反应通过正向反应预测模型进行可信度计算,获得n个模型的n≤n个可信度conf1、conf2、
…ꢀ
confn,输出平均可信度c,通过c≥th筛选最终通过的候选反应物, th选自0.2至1.0中的任意数,优选为0.9至1.0中的任意数。
19.在一个具体实施例中,所述重复的反应物为多个逆合成模型中重复的反应试剂、反应条件中的一种或多种。
20.在一个具体实施例中,在第一模块中,逆合成模型的产生方法包括:随机种子初始化网络参数、从数据集中采样不同的样本构造训练集或不同的transformer网络架构。
21.在一个具体实施例中,在第一模块中,正向模型的产生方法包括:随机种子初始化网络参数或从数据集中采样不同的样本构造训练集。
22.在一个具体实施例中,在第二模块中,去除重复的主干反应的步骤包括:逆合成模型一次产生多个候选反应,若候选反应包括重复的反应物,则对重复的反应物进行删除只留一个实例;将删除重复后的候选反应的化合物进行按原子数或字符长度的排序,若排序后的两个主干反应的排序化合物通过标准化的smiles表示均完全相同并可完全匹配,判断为重复并只保留一个。
23.在一个具体实施例中,在第三模块中,所述平均可信度c计算方法如下:
24.c=(conf1+conf2+
…
+confn)/n
25.另一方面,本发明提供了一种设备,所述设备包括处理器即储存器,所述储存器用于储存计算机程序,所述处理器用于根据所述计算机程序执行如前所述的逆反应化合物反应物预测方法。
26.又一方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质用于储存计算机程序,所述计算机程序用于执行如前所述的逆反应化合物反应物预测方法。
附图说明
27.图1示出逆合成(synthesis design,or retrosynthesis)和正向反应预测(reaction prediction)的关系,问号表示的是各问题所需要预测的目标。
28.图2示出化合物反应产物预测方法的流程示意图。
具体实施方式
29.以下根据实施例,并且结合附图,详细描述本发明。从下文的详细描述中,本发明的上述方面和本发明的其他方面将是明显的。本发明的范围不局限于下列实施例。
30.结合图2说明,本发明通过控制数据集差异和模型参数,训练m》1 个单步逆向的逆合成模型,rmt1、rmt2、
…
rmtm,和n》1个正向反应预测模型fmt1、fmt2、
…
fmtn;集成m个逆合成模型的输出候选;集成 n个正向反应预测模型的输出,通过主干去重的反应判别方法去除反应意义上的重复,保留具真正多样性的反应候选;计算多模型的综合可信度(confidence)c,并通过c≥th筛选最终通过的反应候选;本发明的一个特征是,th可以在[0.2,1.0]的范围中设置,优选[0.9,1.0],例如th可选为0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9或1.0,优选为0.9、 0.95、0.99或1.0。
[0031]
本发明的一个特征是主干去重的反应判别方法,通过去除和反应转化策略不相关的化合物,判断多个反应中是否具有重要的不同化合物,保留具有反应意义多样性的候选,删除重复反应。具体地,本方法维护一个已知试剂列表,如候选反应具有列表中的化合物,则进行删除;删除后的反应称为主干反应,对主干化合物进行按原子数或字符长度的排序,若排序后的两个主干反应相同,判断为重复并只保留一个实例。
[0032]
在本发明的一个实施例中,对m个rmt1、rmt2、
…
rmtm逆合成模型,每个模型选取其输出可信度最高的k≥1个候选反应,称为top
‑ꢀ
k,并取其产生候选的并集,提高候选反应的多样性。
[0033]
在本发明的一个实施例中,对n个fmt1、fmt2、
…
,fmtn正向反应预测模型,每个模型输出的top-k预测,只取和候选反应目标产物吻合的1个预测,或在没有吻合的情况下取0个,最终从n个模型的预测得到了n≤n个可信度conf1、conf2、
…
confn,并进行集成运算,如输出平均可信度(mean),得到该候选反应的综合可信度c。
[0034]
本发明装置的一个特征是,经过上述先通过主干去重再进行可信度集成运算的方法筛选通过的高可信度逆合成候选反应,输入到搜索 (search)模块中,根据相关的搜索分数进行排序,并将试剂列表不包括的反应物,作为需进一步作为合成目标产物,输入到m个单步逆合成模型中进行逆推。
[0035]
当所有的逆推反应物都可被原料库包含,上述过程终止,并获得自动设计的从原料库包含的化合物起始进行的多步合成反应路线,经过所有的反应步骤后可得到最终目标产物。
[0036]
相关路线可选地可对接自动操作的反应设备,进行自动化的合成实验。
[0037]
实施例1逆合成化学反应物的预测方法
[0038]
本实施例选取机器翻译的转换器(transformer)[philippeschwaller et al.molecular transformer:a model for uncertainty-calibratedchemical reaction prediction,2019sep 25;5(9):1572-1583,ashish vaswani, noam shazeer,niki parmar,jakob uszkoreit,llion jones,aidan n gomez, lukasz kaiser,and illia polosukhin.attention is all you need.in advancesin neural information processing systems,pp.5998
–
6008,2017]模型,例如通过选取不同的模型网络层数layers={4,6,8},模型中的注意力机制的头数目heads={4,8,16},编码相关反应层的向量长度vectors= {256,384,512},可最多获得3
×3×
3=27个不同的正向预测模型。在正向模型的训练中,反应数据集在使用作为训练数据时,反应物作为训练输入,产物作为训练的输出目标。类似地,逆向模型可以选用同样的转换器模型,其和正向预测的区别是将训练反应数据集中的产物作为训练输入,反应物作为训练的输出目标。
[0039]
本实施例使用的训练数据为公开的化学反应数据集,来源于美国专利局uspto公开的专利反应。反应数据表现形式为precursors
‑ꢀ
》product,其中precursors为反应物包括试剂,如图1的a+b+c可表示为a.b.c;product为反应的产物,如图1的化合物p。化合物可以通过标准的smiles序列字符表示。
[0040]
在transformer模型训练中,需提供输入的序列数据x和输出的序列数据y,形成包含数万至数百万训练数据对(x,y)的训练数据集d。模型通过固定次数的迭代更新其模型参数θ,使得模型的转化函数y =f(x|θ)得到的y尽量和真实的y一致,并最大化其confidence=p(y |x,θ)。本实施例可以使用同样的反应数据集形式,对逆向和正向分别进行训练。在逆向训练中,(x,y)为(product,precursors);在正向预测的训练中,(x,y)为(precursors,product)。
[0041]
产生不同逆向模型的方法有3种:使用不同的随机种子初始化网络参数、从数据集中采样不同的样本构造训练集或采用不同的 transformer网络架构。通过上述方法,获得了n个不同逆向模型。
[0042]
逆向模型的集成(ensemble)方法是对不同模型的预测结果(pm1, pm2,pm3
…
)取并集预测(predictions):
[0043]
predictions=p
m1
∪p
m2
∪p
m3
[0044]
需要注意的是不同模型的预测结果有可能是重复的,或者反应中重要的“主干”反应物是相同的,需要去除冗余的候选反应。
[0045]
产生不同正向模型的方法有2种:使用不同的随机种子初始化网络参数或从数据集中采用不同的样本构造训练集。通过上述方法可以获得m个不同的正向模型
[0046]
正向模型的ensemble方法是经典的“deep ensemble”:
[0047]
对decoder的输出和attention部分进行ensemble,然后生成对应的smiles。
[0048]“主干”去重方法,反应物可以分为两类,一类出现在已知的化合物列表如常用试剂列表,此类列表可以在各类公开的化合物网站中获取得到,如https://www.labnetwork.com.cn/有50000多种未经去重的试剂。这类化合物对下一步的逆合成分析没有意义,可以忽略;另一类没有出现在试剂列表,是下一步需要进一步解决的分子,定义为主干。如下示意,如果两个反应的主干相同,在逆合成分析中的意义是一致的,只保留一个反应即可。
[0049][0050]
取confidence最大的主干反应作为真正的候选反应
[0051]
confidence的具体计算方式可以是反应数据的x部分,经过已训练的机器模型transformer的多层神经网络的各层权重计算后,在模型的输出层,得到输出产物中所有可
能的m个元素符号的原始权重zi (》0),i=1,2,
…
,m,并通过如下的softmax进行归一化概率计算作为每一个字符i的confidence,并输出概率最大的元素符号序列作为预测y。
[0052][0053]
在其他实施例中,机器模型可替换为其他基于深度神经网络,如 [coley,connor w.,et al.a graph-convolutional neural network model forthe prediction of chemical reactivity.chemical science 10.2(2019):370
‑ꢀ
377.,john bradshaw,matt j.kusner,brooks paige,marwin h.s.segler, jos
é
miguel hern
á
ndez-lobato,a generative model for electron paths, https://arxiv.org/abs/1805.10970],均使用同样的softmax对输出层进行计算,只是输出的元素符号形式有所变化。
[0054]
经过内部实验,本实施例在单步逆合成的50个
×
3次=150个全新目标化合物逆合成的测试中,和单模型相比,本模型集成学习方法的单步逆合成候选反应多样性平均提升50%,正向模型ensemble后单步正确率提升1.9%,在同样参数设置下,每50个目标化合物,能在限定计算步骤完成合成路线的目标从45个提升到50个。
[0055]
本实施例进一步的细分实验表明,对25个分子,逆向生成的候选反应总数进行主干去重后,冗余candidate数量下降330%,对应的搜索计算效率提升5.2倍。候选反应总数:去重前28621,去重后8658。
[0056]
3个逆向模型ensemble主干去重后的候选反应数目从单个逆向模型的350-427增加为734,对应多样性是单个模型的1.7-2.1倍。正向模型ensemble后单步正确率提升1.9%。
[0057]
模型1模型2模型3集成主干去重后350369427734
[0058]
本发明方法可提升正确率,使得高可信度预测具有高准确率,并最终提升反应预测的准确度,同时该方法也具备数据量小和时间短的优点。
[0059]
本领域的技术人员应当明了,尽管为了举例说明的目的,本文描述了本发明的具体实施方式,但可以对其进行各种修改而不偏离本发明的精神和范围。因此,本发明的具体实施方式和实施例不应当视为限制本发明的范围。本发明仅受所附权利要求的限制。本文中引用的所有文献均完整地并入本文作为参考。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1