一种材料性能自动预测系统
1.本发明属于材料性能预测领域,特别是涉及一种材料性能自动预测系统。
背景技术:
2.随着材料科学的发展,材料数据积累越来越庞大,从数以亿万计纷繁复杂的数据中提取有用信息,建模性能良好的新型材料成为材料研究的核心和关键。传统材料科学方法包括实验测量和计算模拟虽能较好解决部分材料问题,但由于实验条件限制和理论基础缺乏等,往往需要耗费漫长的时间,实验精度也较低,很难加速材料的发现和设计。近年来,数据驱动的机器学习(machine learning,ml)因其能够快速学习并建立材料影响因素(如成分、工艺、外界环境等描述符)与目标量(如性能等)间的回归映射关系且预测材料性能的准确性接近从头计算,在加速材料性能预测和新材料发现等方面变得越来越流行。
3.目前,ml已被广泛应用于许多不同材料领域,如固态电解质、光伏材料、储能材料、催化剂/光触媒、热电材料、高温超导体以及高熵合金和玻璃等。材料研究者往往基于历史经验或者多种ml算法性能比较来确定最适合给定材料问题的算法。例如,北京科技大学的尹海清等人(2018)研究支持向量回归(svm)、序列最小优化回归和多层感知器算法,使用化学成分、枝晶信息、标本厚度和测量温度等相关材料描述符来预测镍基单晶合金晶格失配,最终多层感知器模型具有较高的相关系数和较低的误差值,具有良好的预测性能。印度科学院材料研究中心的研究人员rajan等人(2018)利用核岭回归、支持向量回归、高斯过程回归和自助集成回归等四个ml模型对二维过渡金属碳化物和氮化物mxenes的带隙进行预测,实验测得高斯过程回归模型获得最低均方根误差为0.14。圣保罗大学的mastelini等人(2021)利用rf、knn、cart三种机器学习方法以分析硫系玻璃的各元素与玻璃转变温度、杨氏模量、热膨胀系数和折射率性质之间的关系,结果表明rf和knn算法在预测性能上优于cart算法。美国伊利诺伊大学的priya等人(2021)将支持向量机、线性回归、神经网络、k-近邻和xg-boost等多种机器学习模型应用于不同温度、大气压下的固体氧化物钙钛矿总电导率研究,最终xgboost获得最低rmse值为0.25,能够快速准确地识别具有高电导率的钙钛矿材料。也就是说,各种线性模型(例如mlr、ridge和lasso)、非线性模型(例如svr、gpr和ann)或者其他集成回归模型(例如,rf、adaboost)均可能在材料性能任务中取得较高预测精度。根据“没有免费午餐”(no free lunch theory)定理,没有一种机器学习算法能够在所有材料任务上都表现得最好。
4.同时,机器学习是一个非常复杂的过程,其性能、训练速度和复杂度在很大程度上取决于超参数设置。对于非计算机专业的材料专家来说,在面对巨大超参数寻优空间,他们往往是借助试错法或基于直觉以最小化模型预测误差作为学习目标来确定某算法的最优超参数。然而,为每个材料任务手工构建良好的机器学习模型,即枚举所有可能的超参数配置并以迭代方式试错是耗时且几乎不可行的。尽管已经有研究者采用一些超参数自动优化方法来简化模型的复杂超参数调整过程,例如网格搜索、随机搜索和贝叶斯优化等,但由于ml回归算法多样及超参数寻优空间复杂耗时,历史经验法、试错法或现有超参数优化方法
均无法避免使材料专家处于耗时和资源密集型的困境。因此,如何更快、更准确地选择回归模型并优化其超参数,以提高材料科学研究中ml模型的可用性和准确性是一个亟待解决的问题。
技术实现要素:
5.为解决上述问题,本发明提供了如下方案:一种材料性能自动预测系统,包括:
6.数据采集模块,用于获取可用于回归任务的材料数据集和其他领域的通用数据集,作为预测系统的输入数据;
7.数据预处理模块,与所述数据采集模块连接,用于对所述材料数据集、通用数据集进行预处理;
8.领域知识库构建模块,与所述数据预处理模块连接,用于通过获取领域知识,构建材料类别树并进行量化表示,构建领域知识矩阵;
9.元数据库构建模块,与所述数据预处理模块连接,用于分别对所述材料数据集、通用数据集进行元特征计算和算法性能评估,获得所述材料数据集、通用数据集的元特征矩阵和性能矩阵,至此构建材料元数据和通用元数据;
10.算法推荐模块,分别与所述领域知识库构建模块、元数据库构建模块连接,用于采用领域知识嵌入的协同推荐机制,将基于材料元数据的算法推荐结果与基于通用元数据的算法推荐结果进行协同,获得最优推荐算法;基于最优推荐算法对材料目标属性进行预测。
11.优选地,所述材料数据集的数据信息至少包括数据来源、样本条数、特征维度、目标属性、材料类别;
12.所述通用数据集的数据信息至少包括数据来源、样本条数、特征维度和目标属性。
13.优选地,所述数据预处理模块包括第一预处理单元、第二预处理单元;
14.所述第一预处理单元用于将数据集的条件属性与目标性能进行原信息溯源,获得统一数据格式;
15.所述第二预处理单元用于对统一数据格式的数据进行缺失值处理、类别型数据处理和标准归一化,获得符合机器学习建模要求的数据。
16.优选地,所述元数据库构建模块包括元特征计算单元、算法性能评估单元;
17.所述元特征计算单元用于所述材料数据集、通用数据集的元特征计算,获得所述材料数据集、通用数据集的元特征矩阵;
18.所述算法性能评估单元用于通过回归算法建模规则,获得数据集输入与输出之间的映射关系,根据所述映射关系预测目标性能,获得性能矩阵。
19.优选地,所述元特征包括传统元特征、增强元特征;
20.所述传统元特征基于数据集的条件属性提取,包括简单元特征、描述数据分布情况的统计元特征、基于主成分的元特征;
21.所述增强元特征包括基于机器学习模型的元特征、描述目标属性的统计元特征、描述目标属性不确定性的元特征;
22.所述基于机器学习模型的元特征通过机器学习算法提取模型性能度量获得;
23.所述目标属性的统计元特征、描述目标属性不确定性的元特征根据数据集的目标性能提取获得。
24.优选地,所述描述目标属性不确定性的元特征,用于度量目标属性数据的不确定,进行概念化的数值表示;
25.所述数值表示通过一个泛高斯分布三元组处理具有不确定概念的目标属性数据,包括期望、熵、超熵;
26.所述期望为一个概念中最具代表性的数据表示;所述熵用于表示概念的粒度尺度;所述超熵用于描述概念粒度的不确定性。
27.优选地,所述领域知识库构建模块包括领域知识获取单元、领域知识表示单元;
28.所述领域知识获取单元用于通过材料数据集的目标属性,构建多叉树结构的材料类别树来可视化材料领域知识;根据所述材料类别树对材料数据集进行逐级分类,获得分类结果;
29.所述领域知识表示单元用于根据材料类别树获取材料类别,并进行量化表示,构建领域知识矩阵。
30.优选地,所述分类结果包括金属材料、无机非金属材料、高分子材料、复合材料;
31.所述金属材料包括黑色金属、有色金属;
32.所述无机非金属材料包括陶瓷、水泥、耐火材料和玻璃;
33.所述高分子材料包括塑料、纤维、涂料、有机溶剂、有机小分子、生物燃料化合物和橡胶材料;
34.所述复合材料包括金属基材料、陶瓷基材料、聚合物基材料、碳-碳复合材料。
35.优选地,所述算法推荐模块包括第一算法推荐单元、第二算法推荐单元、协同推荐排序单元;
36.所述第一算法推荐单元用于根据材料数据集的元数据,将不同领域知识量化并嵌入以指导元学习推荐过程,获得第一推荐结果;
37.所述第二算法推荐单元用于根据通用数据集的元数据直接进行元学习推荐,获得第二推荐结果;
38.所述协同推荐排序单元用于根据所述第一推荐结果、第二推荐结果进行协同排序计算,根据排名获得最优推荐算法;基于最优推荐算法对材料目标属性进行预测。
39.本发明公开了以下技术效果:
40.本发明提供的一种材料性能自动预测系统,给定一个新材料数据集,通过以上领域知识嵌入的协同元学习组件,得出所有候选回归算法在该数据集上的推荐/预测排名。选择综合性能排名靠前的三种回归算法作为最终最优算法推荐给用户。自动的材料性能预测系统旨在通过算法的历史性能排名为给定数据集选择相对较优的算法集,而不是绝对最优的单一算法,以减少算法参数寻优空间和领域专家选择机器学习算法的时间与计算成本,提高机器学习在材料性能预测领域的可靠性与易用性。
附图说明
41.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
42.图1为本发明实施例的系统结构示意图;
43.图2为本发明实施例的可视化材料领域知识的四层材料类别树结构示意图;
44.图3为本发明实施例的六种元学习方法的推荐结果图;
45.图4为本发明实施例的回归算法的真实排名和预测排名图;
46.图5为本发明实施例的推荐算法在不同数据集上的预测结果图。
具体实施方式
47.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
48.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
49.目前,数据驱动的回归机器学习(machine learning,ml)可通过拟合现有历史经验数据中潜在模式来分析和映射材料成分-结构-工艺-性能等之间复杂的构效关系。根据没有免费午餐定理,每个算法都有自己的应用范围,没有适合所有问题的算法。对于非计算专业的材料专家来说,往往只能通过反复试错法或基于历史经验来枚举所有可能的算法和参数配置,这是一项耗时且资源劳动密集型的复杂过程。藉此,基于元学习(meta-learning)的自动机器学习(automated machine learning,automl)可通过从先前建模经验中学习不同的ml模型性能及参数配置,以加快ml在新任务上的设计。然而,目前缺乏将基于meta-learning的automl应用于材料性能回归预测任务中的研究。同时,公开发表可用的材料机器学习用回归数据集有限。
50.藉此,为了加速材料性能预测研究,本实施例提出了一种领域知识嵌入的材料性能自动预测系统。包括面向回归的元数据库构建器、材料领域知识库构建器及协同算法推荐器。元数据库主要由度量材料数据集相似性的增强元特征及适用于材料目标性能预测的回归算法的性能数据构成;材料领域知识是由通过溯源材料数据集所属材料类别而建立的材料类别树进行可视化;协同算法推荐是采用协同机制来协同基于材料元数据的算法推荐结果和基于其他领域元数据的算法推荐结果,其中领域知识被量化并嵌入到自动算法推荐过程。
51.其中,automl通过将机器学习各个阶段如特征工程、算法选择、超参数优化等这些重要步骤进行自动化,降低机器学习在模型构建过程中各种算法选择及参数设定的复杂性,减少领域专家利用机器学习进行科学发现与分析的成本和参与度,提高机器学习的易用性。
52.材料性能预测:数据驱动的机器学习可通过拟合现有历史经验数据中的潜在模式来分析和映射材料成分-结构-工艺-性能等之间复杂的构效关系。
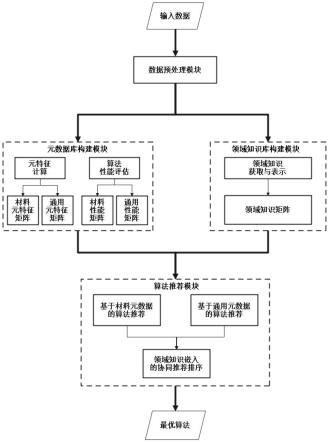
53.元学习:meta-learning通过从先前相似任务中学习建模经验,自动地为给定新任务选择合适的机器学习算法及确定参数,在自动机器学习中被广泛使用。
54.随着机器学习发展伴随着算法选择及参数优化复杂性的难点问题,automl被提出并不断发展。automl通过将传统机器学习过程中与特征工程、超参数优化、模型选择与流程
配置等这些重要步骤进行自动化地学习,以最小的领域知识或实际数据来应用算法和训练模型,从而降低领域专家进入机器学习和深度学习的门槛,使得机器学习模型尽量不依赖人的干预即可被应用。目前研究者已经提出了许多automl框架,但大多数人只关注automl管道的某些部分。例如auto-weka、auto-sklearn、tpot,注重传统ml模型(例如svm、dt、knn);tpot涉及神经网络,但只支持多层感知器;auto-keras是基于keras开发的开源库,它更注重搜索深度学习模型,支持多模式和多任务等等。
55.值得一提的是,被认为是automl先驱工作的auto-weka,它首次考虑组合算法选择和超参数优化(combined algorithm selectionand hyperparameter optimization,cash)问题,使用机器学习框架weka和贝叶斯优化方法来减少人类对机器学习的依赖,使非专家可以轻松构建适用于特定应用场景的高质量分类器。其中,cash是automl的核心,它可以看作是一个层次超参数优化(hpo)问题,可以用随机搜索、贝叶斯优化、进化优化、强化学习、基于梯度的搜索等hpo方法解决。然而,auto-weka因存在高维超参数空间,导致大量的优化计算成本。随后,feurer等人于2015年实现auto-sklearn,其主要包括一个元学习步骤以热启动贝叶斯优化和一个自动化集成构建步骤以使用贝叶斯优化所发现的所有分类器。其中,meta-learning是从已有经验(元数据)中学习不同的超参数配置或机器学习模型在不同相似任务中的表现(元知识)来选择潜在预测性能良好的ml实例,从而大大缩减了cash时间和计算成本,加快机器学习模型在新任务上的设计。如今,越来越多的ml研究者专注于如何更好地描述学习任务,如何快速有效地构建元数据并从其中学习元知识,如何自动元推荐等重要内容研究。
56.对于具有连续属性的材料性能预测是一个监督回归问题。根据没有免费午餐定理,不存在一种单一的通用回归算法在所有材料任务上都优于其他算法的情况,不同算法及其参数需要领域专家反复选择和调优。automl通过组合算法选择和超参数优化问题来自动化机器学习建模过程,从而大大降低领域专家进入机器学习的门槛。然而,对于将automl结合材料性能预测任务的研究尚少。在材料科学研究领域,dunn等人于2021年提出了用于预测无机散装材料特性的automatminer技术。它是一种用于自动创建用于材料科学的完整机器学习管道的工具,主要借助现有的topt技术实现底层cash问题。然而,与大多数automl方法一样,automatminer是通过从头开始训练多个ml模型来选择最优模型进行预测,也就是说,它仅避免了用户干预,但并未缩短建模过程中的等待时间。因此,通过研究将基于元学习的automl用于材料性能预测任务,将有望以较低的时间计算资源提高ml回归预测性能和效率。然而,将基于meta-learning的automl直接引入到材料性能回归任务中面临着三个难点问题:1)缺乏适用于材料回归任务的元数据(面对内部具有复杂物理化学机制的材料数据集,须构建用于区分不同材料任务之间相似性的元特征及可能适用于材料问题的ml算法的性能数据);2)由于大多数材料机器学习研究很少公开其实验数据,从而导致缺乏足够数量的材料数据集以构造元数据进而有可能导致元学习结果过拟合;3)数据驱动的automl容易导致元学习结果与材料领域知识不一致甚至是相悖。在此,后两个问题可以作为同一个问题综合考虑。
57.在此,本发明将基于元学习的automl技术引入到材料性能回归预测任务中,提出了一种自动的材料性能预测系统。具体地,针对元数据构建,基于传统元特征提出了三个新元特征以增强数据集之间的相似性度量;通过调研材料机器学习文献,将18个回归算法用
于本方法中材料性能预测的候选算法。针对有限材料数据集及ml结果缺乏领域知识问题,提出了领域知识嵌入的协同学习机制以将从机器学习两大公开社区openml和uci中收集的公共数据集与材料数据集协同进行元学习,从而缓解元过拟合及提高模型的可解释性和可靠性。
58.如图1所示,本发明提供了一种材料性能自动预测系统,包括以下五大模块:1)数据采集模块是收集可用于回归任务的材料数据集和其他领域的公开通用数据集;2)数据预处理模型用于对所有数据集进行缺失值处理、标准归一化等;3)领域知识库构建模块通过获取领域知识以构建材料类别树并将其进行量化表示,构建领域知识矩阵;4)元数据库构建模块是分别对材料数据集和公开通用数据集,通过元特征计算和算法性能评估得出各自元特征矩阵和性能矩阵,构建两大类元数据;5)算法推荐模块采用领域知识嵌入的协同推荐机制,将基于材料元数据的算法推荐结果与基于通用元数据的算法推荐结果进行协同,最后采用最优推荐算法对材料目标属性进行预测。
59.数据采集模块:
60.通过从41篇材料机器学习文献中,收集了54份用于材料性能预测的回归材料数据集。这些文献中数据集信息包括数据来源、样本条数、特征维度、目标属性、材料类别等,其涵盖材料科学领域不同材料性能研究,例如纳米复合聚合物电解质体系高分子材料电导率研究、lisicon型锂快离子导体材料离子电导率研究、有机小分子的升华焓、生物燃料化合物密度研究等等。此外,又从两大ml公开数据库社区openml和uci中收集适用于回归任务的60份通用数据集,基本信息包括数据来源、样本条数、特征维度和目标属性。
61.数据预处理模块:
62.由于这些公开数据集由不同的研究机构收集且缺乏系统性的存储方式,需要对每份数据集进行人工及程序两步数据预处理,包括将影响因素(x)和目标性能(y)通过溯源原信息手动统一数据格式;利用ml程序处理缺失值、类别型数据和标准归一化。
63.元数据库构建模块:
64.一般地,元学习的元数据由不同ml模型的评估性能和一组在先前数据集上的元特征(或数据集属性)组成,元特征通过影响数据集之间的相似性度量,进而影响ml算法的推荐。本方法利用所有54份材料数据集和60份通用数据集构建元数据库。具体地,将传统四类元特征结合两类新元特征共27个元特征用于表征数据集属性;其次利用18个适用于材料性能预测的回归算法建模材料数据集和通用数据集。最终对应两大类数据集,通过元特征计算与算法性能评估分别得出两大类元特征矩阵和两大类算法性能矩阵。
65.元特征计算
66.元特征是元学习的核心,其用来刻画数据集属性从而以后决策或度量不同数据集间在数据层面上的相似度性。在构建本自动材料性能预测系统中,提出的元特征分为六类,以捕获可能影响回归模型性能的数据集特性:8个描述数据集基本结构的简单元特征、8个描述数据分布情况的统计元特征、3个基于主成分分析(principal component analysis,pca)的元特征、5个基于ml模型的地标landmarking元特征,2个描述目标属性的统计元特征和1个描述目标属性不确定性的元特征。前三组代表从数据集的属性x中提取的常见特征。下一组依靠ml算法来提取模型性能度量,而最后两组是从数据集的目标y中提取的,作为增强的元特征。表1给出了本方法中用到的所有元特征及其定义描述。
67.表1
[0068][0069][0070]
对于增强元特征,一般来说,纯数据驱动的机器学习建模和预测通常是假设学习样本符合一定数据分布下实现的。另一方面,由于材料驱动机制复杂多样,来自测量的实验误差或来自不令人满意的近似值计算误差,都会使得易受材料内部物理化学因素以及时间、温度等外部因素影响的目标属性值的不确定性。因此,研究与目标属性相关的数据分布与不确定性度量对于区分不同材料数据集至关重要。在此,基于目标属性的统计元特征是
从目标向量的峰度和偏度中提取的,以通过描述性统计来表征输出数据的分布。再者,机器学习不确定研究领域的泛高斯分布,可通过期望ey、熵en和超熵he对材料目标属性的不确定概念进行数值表示。其中,ey是一个概念中最具代表性的数据表示;en用来表示概念的粒度尺度,he用来描述概念粒度的不确定性。那么定义c是由三元组(ey,en,he)组成的概念,用于处理具有不确定信息的数据。给定一个新数据集,定义其目标向量为yi=(y1,...,yi,...,y
p
),ey,en,he如式(1)-(4)计算所得。其中s2表示数据集目标属性的方差,p表示数据集的样本数。
[0071][0072][0073][0074][0075]
算法性能评估
[0076]
在预测精度方面,经典和统计的机器学习方法(例如线性回归、支持向量回归、k近邻回归和决策树)更适合较小规模的数据集;而神经网络需要大量数据,并且几乎只有在拥有数千个或更多的训练数据点时预测可行。从模型可解释性的角度来看,线性模型(例如线性回归、岭回归、lasso回归)易于实现且学习结果往往易于理解。同时,在材料科学研究领域中,条件因素与目标属性之间往往存在复杂非线性关系,这导致非线性模型(例如多层感知器、高斯过程回归、贝叶斯岭回归)的学习结果虽然是一个“黑匣子”,但它们被材料专家广泛使用。本发明最终考虑了18种回归算法来预测材料性能,如表2所示。它们是采用不同的建模规则来建立材料数据集输入和输出之间的映射关系。在这里,通过五折交叉验证和贝叶斯优化(bo)方法寻优超参数,均方根误差rmse被用于评估模型预测性能好坏。
[0077]
表2
[0078]
[0079][0080]
领域知识库构建模块:
[0081]
领域知识获取
[0082]
本方法设计了一个名为“材料类别树”的多叉树来可视化材料领域知识。通过溯源每份材料数据集的源机器学习文献以明确材料数据集的目标属性,将各种目标属性作为mct-dk的叶节点。同样地,领域专家通过分析叶节点所属的材料类别来设计倒数第二层。以此向上涉及,直到到达根节点(第0层)。最后,设计出如图2所示的可视化材料领域知识的四层材料类别树,且叶子节点表示的具体材料细分属性如表3所示。总的来看,将所有材料数据集归纳为四大材料主类:金属材料、无机非金属材料、高分子材料和复合材料。具体地,金属材料被分类为黑色金属和有色金属,其涉及多个细分材料,例如铁基金属玻璃、镍基单晶高温合金、高熵合金和多组分β-钛合金等9种。无机非金属材料主要由玻璃、陶瓷材料、水泥和耐火材料四大类组成,共包括lisicon型锂快离子导体、钙钛矿化合物、铁基超导体和nasicon固体电解质等23种细分材料。高分子材料可分为塑料、橡胶、纤维、涂料和有机溶剂等8小类共17种细分材料。其中,例如塑料可按理化性质分为热塑性塑料和热固性塑料;橡胶材料可按制造方法分为天然橡胶和合成橡胶;涂料可按基料种类分为有机涂料、无机涂料和有机-复合涂料等等。复合材料按基体不同可分为金属基材料、陶瓷基材料、聚合物基材料和碳-碳复合材料等。需要注意的是,一些分支(材料类别)缺少相应的叶节点(数据集),但材料专家仍保留这些主要类别以确保材料类别系统的完整性。此外,相信随着公开数据集增加,叶节点分支会越来越丰富,即此材料类别树是支持动态扩增的。
[0083]
表3
[0084][0085][0086]
领域知识表示
[0087]
首先,根据材料类别树,分别获取其“四级”材料类别。具体地,针对每份预测数据集,采用自底向上的策略由叶子节点向根部遍历,所经过的路径共同构成它的材料类别。因为包括根节点在内的材料类别树共有四层,所以一个数据集的完整材料类别会由四个节点构成。例如,铁基超导体的超导转变温度预测数据集,该数据集可根据材料类别树得出其完整材料类别为[材料,无机非金属材料,陶瓷材料,铁基超导体];甲烷水合物形成温度预测数据集,该数据集的完整材料类别为[材料,高分子材料,有机小分子,甲烷水合物]。
[0088]
接着,采用自顶向下策略量化任意两份数据集在领域知识层面上的相似性。假设这里有两份材料数据集i和j,定义为i和j的材料类别相似度,取值如公式(5)所示:
[0089][0090]
其中,表示i与j仅在第一级材料类别上相似,也就是说它们分别属于金属材料、无机非金属材料、高分子材料或复合材料这四大类材料中的任意两个;表示i和j在至第一级别相似基础上又满足第二级别相似,即它们同属于四大类材料中的任一个;同理地,表示i和j在至第三级材料类别相似,而则表示i和j在至第四级类别上相似,这是由材料类别树量化表示出的最高领域知识相似度。例如,上述铁基超导体的超导转变温度预测数据集与甲烷水合物形成温度预测数据集的材料类别相似度为0.2。
[0091]
算法推荐模块:
[0092]
综上所述,分别针对材料数据集和通用数据集,构建了由元特征矩阵和算法性能矩阵组成的两大类元数据以及根据材料类别树获取的材料领域知识量化表示。本方法中,提出领域知识嵌入的协同推荐机制,从而改进现有元学习方法用于算法推荐的过程。分别地,一是根据材料数据集的元数据,将不同领域知识量化并嵌入以指导元学习推荐过程;二是根据通用数据集的元数据直接进行元学习推荐,其中默认将所有通用数据集分别与材料测试数据集在领域知识层面上的不存在类别相似性(或者看作,取值相同)。
[0093]
具体地,假设给定一个新材料测试集d
new
,本方法首先获取描述该数据集属性的27个元特征,利用公式(6)计算出该数据集与每一类所有先验任务(材料数据集与通用数据集)在元特征空间中的欧式距离,并将其作为数据集之间的相似度度量依据。
[0094][0095]
其中,fi与fj表示任意两份数据集的元特征,每组元特征被定义为{f1,...,fk,...,fn},n表示本方法所提出的元特征总数即27.
[0096]
其次,分别面向所有先验材料数据集与所有先验通用数据集,根据它们各自与d
new
的欧式距离进行数据集排序,从而可得到欧式距离最近的m份相似材料数据集和p份相似通用数据集。显然,从数据层面上来看,每两份数据集之间的欧式距离越短,它们之间的相似性就越高。最后,返回相似数据集的算法性能数据以及相似材料数据集对应的材料类别(/领域知识)。
[0097]
再者,一方面,基于相似通用数据集及其性能数据,利用average ranking(ar)方法决策每个回归算法在所有算法中的平均排名,如式(7)所示:
[0098][0099]
其中,代表第j个回归算法在第i个相似数据集上的预测性能排名。为第j个回归算法在不同相似数据集上的预测性能排名,j=1,...,a(a取18,代表所有候选回归算法的总数);p代表相似通用数据集的份数。
[0100]
另一方面,基于相似材料数据集及其性能数据,通过嵌入领域知识来改进ar算法,最终决策每个回归算法在所有算法中的平均排名,如式(8)所示:
[0101][0102]
其中,m代表相似材料数据集的个数;代表第i相似数据集与d
new
在领域知识层面上的相似度,其值是通过上述公式(5)计算所得。
[0103]
然后,采用协同机制,将上述计算所得和这两个不同推荐结果进行协同,如公式(9)所示,其中协同学习因子c
*
在[0.1,1]范围内取值。最后,在协同计算出各个回归算法的最终排名后,通过重新排列这些排名来推荐最终排名靠前的回归模型。可见每个回归算法的排名位置是基于组合评估的质量,即回归算法得到的综合评估质量越好,其排名位置越高,预测时回归拟合度越好。
[0104]
col_r(r
md
,r
pd
,c
*
)=c
*
*r
md
+(1-c
*
)*r
pd
ꢀꢀ
(9)
[0105]
针对现有技术的缺点,提出了一种自动的材料性能预测器。本方法旨在改进基于元学习的automl技术来自动选择回归模型并优化其超参数,以促进具有优异性能的新型材料的设计和发现。本方法综合考虑了传统ml及automl在材料科学领域中存在的问题,将基于元学习的automl用于材料性能预测以解放材料专家干预及减少时间物力消耗,解决了传统机器学习建模过程中算法选择和参数优化难且耗时耗力、数据驱动的ml结果容易与材料领域知识不一致甚至是相悖的问题。首先,人力尽可能多地从已发表材料ml文献与公开ml社区中分别收集材料数据集和其他领域数据集,以充足元学习样本。同时,针对两类数据集分别计算包括三个新元特征在内的27个元特征和训练适用于材料性能预测问题的18个回归算法的性能数据,从而构建用于元学习的增强元数据。此外,通过溯源材料数据集的材料类别构建了材料类别树以可视化材料领域知识。最后,采用一种领域知识嵌入的协同机制将分别基于上述两类元数据的元推荐结果进行协同,实现最终回归算法推荐及性能预测。
[0106]
给定一个新材料数据集,通过以上领域知识嵌入的协同元学习组件,得出所有18个候选回归算法在该数据集上的推荐/预测排名。选择综合性能排名靠前的三种回归算法作为最终最优算法推荐给用户。该自动的材料性能预测器旨在通过算法的历史性能排名为给定数据集选择相对较优的算法集,而不是绝对最优的单一算法,以减少算法选择的空间和领域专家选择机器学习算法的时间与计算成本,提高机器学习才材料性能预测领域的可靠性与易用性。
[0107]
图3为六种不同元学习方法在不同推荐精度下所对应的数据集分布情况(图中四种色条框分别代表推荐精度达到0-0.2、0.4、0.6、0.8-1的材料测试集的个数;图中“acc”表示所有100次实验中的平均推荐结果)。本实验采用留一交叉验证方法,每一次划分都将其中一份数据集作为材料测试数据集d
new
,而其余53份数据集和60份训练集作为元学习的先验数据集。对于每一份d
new
,采用holdout将其划分为80%训练样本和20%测试样本。因此,通过将80%训练样本输入到自动的材料性能预测器(领域知识嵌入的协同元学习推荐方法,mtl-coldk),得出推荐算法排名;通过相同实验设置采用五折交叉验证从头开始训练18个回归算法在这80%训练样本上的性能再归一化排序得算法排名记作真实算法排名。以上验证实验总共进行了100次。将推荐算法中排名前五的回归算法和真实排名前五的回归算法是否一致作为推荐评估指标,
[0108]
具体地,所提mtl-col(利用公式(7)、公式(9))在理想推荐精度下(阈值设置为
0.5)对应的数据集分布情况为39/54、43/54、41/54、44/54、44/54、49/54、48/54、46/54、46/54、44/54。与元任务较少的元学习方法(包括mtl-m和mtl-p)相比,其他两种元任务较多的方法(包括mtl-colcmp和mtl-col)总能获得更好的推荐准确率。更重要的是,在使用相同大规模元数据的情况下,mtl-col在每个实验中都优于使用混合元数据的比较方法mtl-colcmp。进一步,如图3(a)和3(e)所示,在9/10的实验中,mtl-dk比mtl-m获得了更多具有理想推荐精度的材料数据集。在mtl-dk上的num.1、num.4、num.5、num6和num.7实验中,推荐准确度提高的数字分别为2、4、2、2和3。虽然在其他几轮验证实验中通过将领域知识编码嵌入到元学习中并没有明显提高理想准确率,但可以发现它仍然减少了低准确率的数据集数量。此外,将提议的mtl-coldk(利用公式(7)-(9))与mtl-col进行了比较。从图3(d)和3(f)可以看出,前者在8/10实验中实现了具有理想推荐精度的更多或稳定数量的材料数据集。总的来说,相较于其他不采用协同学习机制或不嵌入领域知识指导的五种自动元学习方法相比,本文所提mtl-coldk有着更高且稳定的推荐能力。
[0109]
进一步,随机从54份数据集的选择12份数据集,分析利用所提元学习推荐方法得出的3个最优回归算法的预测能力。图4所示为18个回归算法在每个数据集上的真实排名和预测排名。其中lr、ls、ridge、larslasso和rnasac等多个线性模型的预测性能不是很突出。而knn、adaboost、mlp、krr和rf等非线性模型的预测排名高于其他回归模型。将这一事实归因于材料内部复杂的物理化学机制,导致线性算法无法构建各种因素与目标特性之间的非线性关系。图5所示为最优算法在每个数据集20%测试样本上的预测精度。可以看出,adaboost、mlp和krr模型在大多数情况下都实现了低平均rmse和高平均r2。此外,在材料数据集3、4、12、20和34中,模型par、knn、sgd和elasticnet回归也预测表现良好。
[0110]
本实施例提出的材料性能自动预测系统具有以下优点:
[0111]
1、提出一种自动的材料性能预测系统,将基于元学习的自动机器学习技术引入到材料性能回归预测研究。
[0112]
2、构建适用于材料性能预测问题的27个元特征和18个回归算法的性能数据作为元数据以增强元学习。
[0113]
3、采用协同机制将两类基于不同元数据的元推荐结果进行协同,从而避免元过拟合且提高元学习推荐精度。
[0114]
4、将可视化领域知识的材料类别多叉树量化并嵌入到协同推荐过程,使得回归算法推荐及预测结果更加准确可靠。
[0115]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1