基于改进樽海鞘算法的食管癌生存期预测模型的构建与应用
1.本技术涉及癌症生存期预测技术领域,具体涉及一种基于改进樽海鞘算法的食管癌生存期预测模型的构建与应用。
背景技术:
2.食管癌是常见的消化道肿瘤,全世界每年约有30万人死于食管癌。其发病率和死亡率各国差异很大。我国是世界上食管癌高发地区之一,每年平均病死约15万人。随着医疗技术的不断进步,以手术治疗为核心的食管癌综合治疗模式给食管癌患者带来了良好的效果。但是,由于食管癌手术复杂、食管癌病理也较复杂,导致食管癌术后并发症较多,进而术后患者5年存活率只有10%至30%,然后早期食管癌患者经综合治疗,五年生存率要高于70%。又因为人工诊断和传统的统计学方法对患者的预后推断难免会有一些误差和局限性,从而限制了治疗方式和药物种类的选择。所以,对食管癌患者生存预后状况进行及时有效的预测对提高患者的生存率是至关重要的。通过对食管癌患者生存的临床数据进行分析,构建预测模型用以预测食管癌患者的生存期,能够帮助临床医生及时发现患者的生存预后情况,进而能够采取较好地辅助患者的治疗,从而改善食管癌患者的预后,进一步提高食管癌患者的生存率。
3.尽管在过去的几十年里,随着新药物、新技术的引入,食管癌患者的生存期已显著提高,但是由于病理的复杂性,人工判断风险等级存在一定的误差,导致食管癌患者不能得到合适的治疗方式,为了解决这一问题,需要设计一个能够预测食管癌患者生存期模型。
4.传统癌症治疗方法的选择是基于“金标准”方法的基础上,包括三项测试:临床检查、放射成像和病理检查,通过医生的临床经验和专业知识决定采取哪一种治疗方式。传统方法的检测具有侵入性,会给被检查人群带来身体上的不适与痛苦,其次成本高昂,不适合大规模推广使用,同时检查结果也只能被用来证明癌症是否存在,并不能判断出风险等级以及生存期。
5.为了解决上述问题,统计分析方法被用于预测癌症患者风险等级。统计分析方法只需要患者的一些易于获取到的临床特征指标,就能够用于推断变量之间的相互关系,同时效率较高,成本较低。常用的统计分析方法有kaplan-meier(km)、cox、生存树、lasso等。km是一种从观察生存时间来估计生存概率的单变量分析方法,该方法只描述了单变量和生存之间的关系而忽略其他变量的影响,可以很直观地表现出两组或多组的生存率或死亡率。生存树方法适用于大型队列数据且变量很多,经典生存分析方法应用条件难以满足,且结果用树状结构图表示,更直观,更容易理解和解释。虽然统计分析方法能够使用患者易得的临床数据并且较为快速的分析变量之间的关系,然而统计分析对历史统计数据的完整性和准确性要求较高,并且统计分析在对面较为复杂的数据时,准确性和可靠性较差。
6.与统计模型相比,机器学习在处理大规模数据的复杂性和发现预后因素方面显示出了优势。其学习过程通常可以划分为:数据采集、数据预处理、模型训练和预测、模型评价等四个阶段。机器学习技术在面对数量较大且维度较高的数据集时,相比于统计分析具有
绝对优势。通过对患者数据的全面采集,可以对数据进行分析和利用,利用机器学习的方法进一步挖掘数据之间的内在关联,从而构造预后指数,最终建立生存预测模型。生存预测模型可以帮助临床医生根据患者的生存预后制定针对性的个体化治疗方案和较佳的药物选择。
7.公开于该背景技术部分的信息仅用于加深对本公开的背景技术的理解,而不应当被视为承认或以任何形式暗示该信息构成本领域技术人员所公知的现有技术。
技术实现要素:
8.针对樽海鞘算法的探索能力以及开采能力的不平衡,收敛速度慢,收敛精度低以及容易陷入局部最优等问题,本技术发明人提出一种基于划分迭代策略的樽海鞘优化算法:利用划分迭代策略将算法的迭代划分为两个时期,迭代前期以及迭代后期;在迭代前期,使用领导者融合变异策略对领导者位置进行更新,增加算法的探索能力;在迭代后期,采用最优个体引领运动对领导者位置进行更新,优化算法的开采能力;然后利用逐维高斯变异策略对所有的樽海鞘个体进行更新,提高种群的多样性;在算法迭代结束前对最优樽海鞘位置进行最优领域扰动并进行适应度值比较,利用贪婪策略选择最优适应度值,提高其跳出局部最优解的能力。将该算法用于食管癌生存期预测模型的优化,并与其它6种模型进行对比,利用平均绝对误差(mean absolute error,mae),均方误差(mean square error,mse),以及平均绝对百分比误差(mean absolute percent error,mape)作为评价标准对模型进行分析,结果表明了所提出的模型的有效性。
9.根据本公开的一个方面,提供一种基于改进樽海鞘算法的食管癌生存期预测模型的构建方法,包括:
10.(1)分析筛选出食管癌患者死亡的影响因素,将筛选出的因素作为输入变量,生存时间作为输出变量,建立基于bp神经网络的生存期预测模型;
11.(2)利用改进樽海鞘算法对所述bp神经网络的初始权值以及阈值进行优化,所述改进樽海鞘算法包括如下步骤:
12.s1:设置樽海鞘算法的相关参数:种群规模n,最大迭代次数l,个体的维度dim,初始化种群;
13.s2:根据目标函数计算每个樽海鞘个体的适应度值,并对适应度值进行排序;选择适应度最好的位置作为食物源的位置,设置当前迭代次数l=1;
14.s3:判断当前迭代次数l是否小于划分系数,如果小于,则进入到步骤s4,如果大于,则进入到步骤s5;
15.s4:利用领导者融合变异策略对领导者位置进行更新,追随者位置更新时引入自适应惯性权重;
16.s5:利用最优个体引领运动策略对领导者位置进行更新,追随者位置更新时引入自适应惯性权重;
17.s6:计算适应度值并更新樽海鞘的位置,利用逐维高斯变异策略对所有的樽海鞘位置进行更新;
18.s7:利用最优领域扰动策略对最优樽海鞘位置进行更新,并与当前的适应度值作比较,使用贪婪策略选择最优的适应度值;
19.s8:若当前迭代次数l小于最大迭代次数l时,对当前迭代l加1,进入步骤s2;否则输出最优解,算法迭代结束。
20.在本公开的一些实施例中,在所述步骤s2中,所述目标函数表达式为:
[0021][0022]
其中,x为食管癌生存模型的训练样本数,yi为第i个食管癌患者的网络模型的输出值,y
′i为第i个食管癌患者的实际输出值。
[0023]
在本公开的一些实施例中,在所述步骤s4中,领导者位置更新过程如下:
[0024][0025]
a+b+c=1
ꢀꢀꢀ③
;
[0026]
式中,表示第1个樽海鞘个体(领导者),在第j维的位置;是种群中随机选择的两个樽海鞘个体;fj为第j维食物源位置;a,b,c为随机数,在[0,1]之间取值。
[0027]
在本公开的一些实施例中,在所述步骤s5中,领导者位置更新按如下公式进行:
[0028][0029]
式中,fj是第j维食物源位置,r
2 r3是[0,1]区间的随机数;r是[-1,1]区间中的随机数,b的计算公式如下所示:
[0030][0031]
式中,l为当前迭代次数,l是最大迭代次数。
[0032]
在本公开的一些实施例中,在所述步骤s6中,按下式对所有的樽海鞘位置进行更新:
[0033]
q=1-(l-l)2ꢀꢀꢀ⑥
;
[0034]
x(j)=q
×
x(j)+randn
×
x(j)
ꢀꢀꢀ⑦
;
[0035]
式中,q为自适应惯性权重;l为当前的迭代次数;l是最大的迭代次数;x(j)为第j维樽海鞘的位置;randn为高斯变异算子。
[0036]
在本公开的一些实施例中,在所述步骤s7中,利用下式对最优樽海鞘位置进行更新:
[0037][0038]
式中,x(best)为全局更新时的最优位置;x(newbest)为生成的新的位置;其中v,m分别为[0,1]之间的随机数。
[0039]
在本公开的一些实施例中,在所述步骤s7中,对于生成的邻域位置,采用下式判断是否保留:
[0040]
[0041]
式中,f(x(best))为全局更新时的最优位置适应值,如果生成的位置比原位置好,则将其与原位置替换,使其成为全局最优;反之,最优位置保持不变。
[0042]
在本公开的一些实施例中,在所述步骤(1)中,利用单因素cox回归分析筛选得到与食管癌患者生存期相关的5种血液指标:白细胞计数、单核细胞计数、中性粒细胞计数、凝血酶原时间、国际标准化比值作为输入,构建bp神经网络的生存期模型的结构是5-11-1,得优化的维度为:
[0043]
dim=(inputnum+1)
×
hiddennum+(hiddennum+1)
×
outputnum
ꢀꢀꢀ⑩
;
[0044]
其中,inputnum、hiddennum、outputnum分别为bp神经网络的输入层个数,隐含层个数以及输出层个数。
[0045]
本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
[0046]
1.首先采用划分迭代策略平衡算法的探索能力以及开采能力,利用划分系数将算法的迭代划分为两个时期,在迭代前期,采用探索能力较强的领导者融合变异策略对领导者位置进行更新;在迭代后期,则采用开采能力较强的最优个体引领运动进行领导者位置更新;其次对所有的樽海鞘个体进行利用逐维高斯变异,丰富种群的多样性;然后利用最优领域扰动策略对最优樽海鞘位置进行更新,利用贪婪策略获得最优解,避免了算法出现早熟,提高算法跳出局部最优的能力。
[0047]
2.所采用的ipssa算法相较于不同的群智能算法以及不同改进的樽海鞘算法在保证稳定性的前提下,具有较好的收敛速度以及收敛精度,存在一定的竞争优势。
[0048]
3.本技术ipssa-bp模型拟合效果好,准确性高,预测精度高,预测稳定性好。
附图说明
[0049]
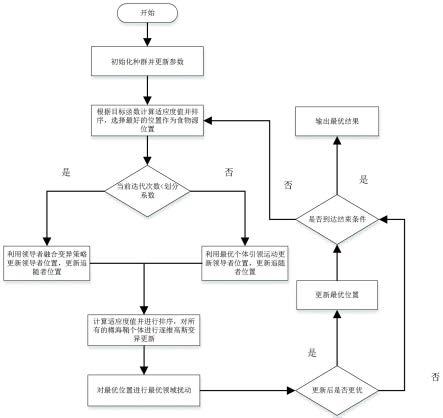
图1为本技术一实施例中的改进樽海鞘算法流程图。
[0050]
图2为本技术一实施例中的改进樽海鞘算法与其它群智能算法的收敛性曲线。
[0051]
图3为本技术一实施例中的樽海鞘算法与其它改进樽海鞘算法的收敛性曲线图。
[0052]
图4为本技术一实施例中的食管癌生存期预测模型测试集期望值与实际值对比图。
[0053]
图5为本技术一实施例中的7种模型仿真评价标准对比图。
具体实施方式
[0054]
为了更好的理解本技术技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
[0055]
实施例一:基于划分迭代策略的樽海鞘优化算法
[0056]
对于群智能算法来说,在搜索的过程中平衡算法的探索以及开采能力能够有效的提高算法的性能。根据樽海鞘算法的特点,本例引入划分迭代策略用于平衡算法的探索能力以及开采能力,利用逐维高斯变异策略提高种群的多样性。最后通过最优领域扰动以及贪婪策略提高算法跳出局部最优的能力。
[0057]
1.划分迭代策略
[0058]
划分迭代策略是一种平衡算法探索以及开采的策略。它将算法的迭代划分为不同的时期,针对不同时期的特点,采用不同的搜索方程进行求解。在原始的樽海鞘算法中,算
法的前期需要更多的探索能力,在算法的后期则需要更多的开采能力。本例利用划分系数将算法的划分迭代为两个时期,迭代前期以及迭代后期。在迭代前期采用探索能力强的方程,在迭代后期利用开采能力强的算法方程。这样就可以平衡算法的探索与平衡能力。在本例中,迭代前期选用领导者融合变异策略进行更新,追随者位置引入自适应惯性权重,提高算法的开采能力。在迭代后期选用最优个体引领运动对领导者位置进行更新,追随者位置引入惯性权重。表1为划分迭代策略的伪代码,其中划分系数的设置如下所示:
[0059]
lh=l/2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1);
[0060]
式中,l是最大的迭代次数,本例将迭代划分为迭代次数相等的两个时期。
[0061]
1.1领导者融合变异策略
[0062]
在原始的樽海鞘算法,领导者的位置主要由食物源进行引导,食物源位置在每次迭代中进行更新,容易陷入局部极值,导致算法的探索能力下降。为了改善这一问题,本例引入了领导者融合变异策略,在所有的樽海鞘个体中随机选择两个樽海鞘个体,将食物源位置和随机选择的两个樽海鞘个体位置进行融合变异,产生新的领导者位置,以此加快领导者位置的更新,从而影响其余个体搜索方向。更新后的领导者的位置不仅受食物源位置影响,还受到随机个体的影响,进而加快算法的收敛速度以及探索能力。具体的更新过程如下所示:
[0063][0064]
a+b+c=1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0065]
式中,表示第1个樽海鞘个体(领导者),在第j维的位置;是种群中随机选择的两个樽海鞘个体,fj为第j维食物源位置;a,b,c为随机数,本文设置取值在[0,1]之间。
[0066]
1.2最优个体引导运动
[0067]
在算法的迭代后期,算法的搜索需要更多的开采能力。本文引入最优个体领导引导运动,团队需要照着一个目标区域(最佳区域)前进,所以领导者需要更新他们的位置靠近目标位置(最佳区域),在跟随者向领导者靠拢的同时,领导者也要不断地向最优区域靠近。领导者位置更新按照公式(4)能够找到食物源附近的最佳位置。有时,领导者必须离开当前的最佳位置,才能找到更好的位置,提升了算法的开采能力。具体公式更新如下所示:
[0068][0069]
式中,fj是第j维食物源位置,r
2 r3是[0,1]区间的随机数;r是[-1,1]区间中的随机数,b的计算公式如下所示:
[0070][0071]
式中,l为当前的迭代次数,l是最大的迭代次数。2
×
r3产生更多的随机运动,因此算法不会陷入局部最优,这就意味着算法在开发阶段也在进行探索。cos(2rπ)搜索具有不同半径的最佳个体,以在个体周围找到更好的位置。
[0072]
1.3追随者位置更新
[0073]
在樽海鞘群算法中,追随者跟随领导者移动,追随者根据牛顿运动定律更新位置,公式为
[0074][0075]
为第i个追随者在第j维上的位置,i
…
2,a是加速度,v0是初速度,t为时间;因为在算法中迭代次数为时间,每次迭代之间的差值为1,初速度为0,在每次更新时一个随迭代次数变化的惯性权重w(l),则追随者的移动公式更新为:
[0076][0077][0078]
式中,l为当前的迭代次数,l是最大的迭代次数,为第i个追随者在第j维上的位置,为第i-1个追随者在第j维上的位置。
[0079]
表1划分迭代策略伪代码
[0080][0081]
2.逐维高斯变异
[0082]
高斯变异策略是使用服从正态分布的随机数作用于原始位置向量以生成新位置。大多数变异算子分布在原始位置周围,这相当于在小范围内执行邻域搜索。这种变异不仅提高了优化算法的优化精度,而且有利于算法跳出局部最优区域。同时,少数算子远离当前位置,增强了种群的多样性,有利于更好地搜索潜在区域,从而提高搜索速度,加快优化算法的收敛趋势。利用高斯变异策略对所有的樽海鞘个体进行逐维高斯变异,增加种群的多样性,表2为逐维高斯变异策略的伪代码。
[0083]
为了更好的调节算法的全局探索能力和局部开心能力,在进行高斯变异的同时引入自适应惯性权重q,自适应惯性权重q值较大时算法的勘探能力强,惯性权重值较小时算法的开发能力强,具体公式更新如下所示:
[0084]
q=1-(l-l)2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9);
[0085]
x(j)=q
×
x(j)+randn
×
x(j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10);
[0086]
式中,l为当前的迭代次数,l是最大的迭代次数;x(j)为第j维樽海鞘的位置;randn为高斯变异算子。
[0087]
表2逐维高斯变异伪代码
[0088][0089]
3.最优领域扰动
[0090]
樽海鞘算法在位置更新时,是把当前的最优位置作为本次迭代的目标。在每次的迭代过程中,最优位置只有出现优于它的位置时才会更新,这就导致了在满足结束条件前,最优位置的更新次数并不多,导致算法搜寻效率不高。于是,本例引入最优领域扰动策略,在最优位置的附近进行随机搜索,找到一个更佳的最优解,这样不仅可以提高算法的收敛速度,而且可以避免算法出现早熟,提高算法跳出局部最优的能力。表3最优领域扰动的伪代码。
[0091][0092]
式中,x(best)为全局更新时的最优位置;x(newbest)为生成的新的位置;其中v,m分别为[0,1]之间的随机数。对于生成的邻域位置,采用贪婪策略
[27]
判断是否保留,公式如下:
[0093][0094]
式中,f(x(best))为全局更新时的最优位置适应值,如果生成的位置比原位置好,则将其与原位置替换,使其成为全局最优。反之,最优位置保持不变。
[0095]
表3最优领域扰动伪代码
[0096][0097]
4.算法流程
[0098]
基于划分迭代策略的樽海鞘优化算法的流程图如图1所示,详细步骤如下:
[0099]
s1:设置樽海鞘算法的相关参数:种群规模n,最大迭代次数l,个体的维度dim,初始化种群。
[0100]
s2:根据目标函数计算每个樽海鞘个体的适应度值,并对适应度值进行排序。选择适应度最好的位置作为食物源的位置,设置当前迭代次数l=1。
[0101]
s3:判断当前迭代次数l是否小于划分系数,如果小于,则进入到步骤s4,如果大于,则进入到步骤s5。
[0102]
s4:利用领导者融合变异策略对领导者位置进行更新,追随者位置更新时引入自适应惯性权重。
[0103]
s5:利用最优个体引领运动策略对领导者位置进行更新,追随者位置更新时引入自适应惯性权重。
[0104]
s6:计算适应度值并更新樽海鞘的位置,利用逐维高斯变异策略对所有的樽海鞘位置进行更新。
[0105]
s7:利用最优领域扰动策略对最优樽海鞘位置进行更新,并与当前的适应度值作比较,使用贪婪策略选择最优的适应度值。
[0106]
s8:若当前迭代次数l小于最大迭代次数l时,对当前迭代l加1,进入步骤s2;否则输出最优解,算法迭代结束。
[0107]
5.函数测试实验
[0108]
(1)与原始算法和不同群智能算法对比
[0109]
将本例ipssa算法与基本的ssa算法以及选取的收敛效果较好的蚁狮算法(alo),灰狼算法(gwo),蜻蜓算法(da)和飞蛾扑火算法(mfo)在f1~f12函数的30维以及100维进行寻优对比。
[0110]
图2给出了ipssa以及其他不同群智能算法在3个单峰函数以及3个多峰函数上30维以及100维上的收敛曲线,收敛曲线可以显示算法陷入局部最优中的次数以及收敛速度。其中横轴为迭代次数,纵轴为最优适应度值。通过图3可知道在经过500次的迭代后,ipssa的收敛速度和收敛精度相较于传统的樽海鞘算法(ssa),蚁狮算法(alo),灰狼算法(gwo),蜻蜓算法(da)和飞蛾扑火算法(mfo)存在有一定的优势。具体来说,ipssa在f1,f3,f8,f10
函数均找到了理论的最优值,且收敛速度最快。对于函数f5(dim=30)在前期的收敛速度较快,但在后期陷入局部最优,但收敛精度仅次于gwo和ssa。对于图3中的其他情形,ipssa均表现出更快的收敛速度和收敛精度。
[0111]
(2)与其它改进樽海鞘算法的寻优对比
[0112]
为了进一步验证ipssa算法的优化性能,将ipssa与所述选取的三种效果较好的改进算法(即essa,mssa,scssa)进行对比,其中essa为mohammed h.qais等人在enhanced salp swarm algorithm:application to variable speed wind generatorsy一文中提出的。文中主要对系数c1进行更新,使得领导者按照平均指数协方差变量c1向食物源位置移动,改变追随者位置公式,使得追随者不仅可以负责探索食物,并可以帮助领导者做出决策,有效提高算法的性能;mssa为陈连兴等人在一种改进的樽海鞘群算法一文中提出的,文中主要对领导者引入加权重心取代最优个体位置,防止过早聚集在最优个体附近,对于追随者引入自适应惯性权重平衡算法的全局搜索和局部寻优能力,最后对于个体进行逐维随机差分变异,减少维度间干扰,提高了种群的多样性。scssa为陈忠云等人在正弦余弦算法的樽海鞘群算法一文中提出,文中引入logistics混沌序列生成初始种群,增加初始个体的多样性;将正弦余弦算法作为局部因子嵌入到樽海鞘群算法中,对樽海鞘个体进行正弦和余弦优化;对最优樽海鞘的领域空间进行差分演化变异策略,增强局部搜索能力。本例中的对比算法参数按照以上文献进行设计。
[0113]
图3包含了本例提出的ipssa算法与其它优秀改进算法在3个单峰函数以及3个多峰函数不同维度的收敛性曲线对比图。从图4可以看出,对于不同类型的测试函数,ipssa均具有较好的收敛速度以及收敛精度。具体的可以看出,ipssa在函数f1,f3,f8都找到了函数的理论最优值,收敛速度也较快。在函数f5的30维以及100维前期的收敛速度较快,但是在后期陷入了局部最优,但其收敛精度仅次于scssa。在其它的基准函数上,ipssa都有较好的收敛精度以及收敛速度。
[0114]
实施例二:基于ipssa-bp的食管癌生存期预测模型及效果验证
[0115]
bp神经网络是以循环的方式不断对初始的权值以及阈值进行更新,直到达到初始设置的计算误差的最小值或者达到初始设定的总训练次数。其优点是可以得到一个更高的精度,能有效解决复杂的问题。但是bp神经网络初始的权值与阈值都是随机生成的,对神经网络的精度有很大的影响,导致评价的结果不可靠。
[0116]
本例将改进的ipssa算法对bp神经网络的初始权值以及阈值进行优化,并与essa,scssa,assa优化的神经网络以及传统的bp神经网络和鲸鱼算法(woa)优化的bp神经网络进行对比,验证算法的有效性。
[0117]
1.基于bp神经网络的食管癌生存期预测模型
[0118]
应用单因素cox回归分析筛选出食管癌患者死亡的影响因素,将筛选出的因素作为输入变量,生存时间作为输出变量,建立bp神经网络的生存期预测模型。选取2007年至2018年郑州大学附属医院共收治的食管癌患者500例,其中男性316例(63.2%),女性184例(36.8%)。患者的平均60.258岁。利用单因素cox回归分析对这些食管癌患者的血液指标进行分析,得到与生存期相关的5种血液指标:白细胞计数(white blood cell count,wbcc)、单核细胞计数(monocyte count,mono)、中性粒细胞计数(neutrophil count,seg)、凝血酶原时间(prothrombin time,pt)、国际标准化比值(international normalized ratio,
inr)作为输入,构建bp神经网络的生存期模型的结构是5-11-1,得优化的维度为:
[0119]
dim=(inputnum+1)
×
hiddennum+(hiddennum+1)
×
outputnum
ꢀꢀꢀ
(12);
[0120]
其中,inputnum、hiddennum、outputnum分别为bp神经网络的输入层个数、隐含层个数以及输出层个数。所以本例需要优化的初始权值以及阈值的个数为5
×
11+11
×
1=66个权值以及12个阈值需要算法优化。选取公式(16)作为适应度函数。函数的具体的表达式为:
[0121][0122]
其中,x为食管癌生存模型的训练样本数,yi为第i个食管癌患者的网络模型的输出值,y
′i为第i个食管癌患者的实际输出值。
[0123]
2.结果分析
[0124]
利用500组食管癌患者的血液样本建立模型。其中,随机的选取食管癌患者的300组数据作为食管癌患者生存期预测模型的训练数据进行训练,剩余的200组数据作为食管癌患者生存期预测模型的测试数据,对食管癌患者的生存水平的预测结果进行预测。将ipssa算法与3种改进算法以及传统的bp神经网络和woa算法进行对比;所有算法的种群规模统一设置为100,其他参数设置参照原始文献进行设置。bp神经网络的参数配置,其中最大训练次数设置为5000次,学习速率设置为0.3,训练目标的最小误差设置为le-9。
[0125]
图4给出了各个算法优化bp神经网络的测试集的实际值与预测值的对比图,在图5中能大致判断出预测模型预测精度,不能定量的反应出模型的预测精度,为了能更好的验证采用ipssa算法优化bp神经网络的预测效果,对所有的模型进行相关的误差分析。采用常用的mae,mse,mape作为评价标准对模型进行定量分析。mae可以准确反应实际预测误差的大小,mae的值越小,说明预测模型的误差越小;mse可以评价数据的变化程度,mse的值越小,说明预测模型的描述实验数据具有更好的精度;maps可以衡量预测的准确性,mape的值越小,说明预测模型的拟合效果越好,具有更高准确性。图5绘制了相应的仿真评价标准对比情况,从图中也可直观的看出,在三项评价指标中,本例ipssa-bp模型都处于最小值,说明ipssa-bp模型的预测精度较好,预测稳定性以及效果也较好,说明ipssa算法的优化性能存在一定的竞争优势。
[0126]
通过3组仿真实验对实施例一提出的ipssa算法的收敛速度以及收敛精度进行分析:1)与不同的群智能算法对比;2)与其它改进樽海鞘算法进行对比;3)食管癌生存期预测模型优化。前2组实验分别在f1~f12函数的不同维度下进行,通过收敛性曲线,friedman检验分析可知,ipssa算法相较于不同的群智能算法以及不同改进的樽海鞘算法在保证稳定性的前提下,具有较好的收敛速度以及收敛精度,存在一定的竞争优势。第3组实验是对食管癌生存期预测模型进行优化,并于其他6种模型进行对比,利用mae,mse,mape作为评价标准对所有模型进行分析,结果表明,ipssa算法的优化性能的有效性。
[0127]
尽管已描述了本技术的一些优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术保护范围的所有变更和修改。
[0128]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本技术权利要求及其等同技术的范围
之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1