病变差异位点识别方法、装置、设备和存储介质与流程
本技术涉及生物信息技术和神经网络应用,尤其涉及病变差异位点识别方法、装置、设备和存储介质。
背景技术:
1、目前,dna序列上的病变修饰(如cpg位点的甲基化修饰的改变)位点的识别主要是通过一些统计学的方法,比如分别计算肿瘤与非肿瘤组织中dna上的每一个cpg位点的甲基化频率,通过统计学的方法计算肿瘤与非肿瘤组织中dna甲基化频率是否存在显著性的差异,进而识别出甲基化差异位点(differentiallymethylated cpg,dmc)。研究发现cpg位点的甲基化状态还受周围dna序列的调控,但是现有统计学方法只考虑cpg位点的甲基化差异,并没有考虑cpg位点周围的dna序列,因此识别能力有待提高。
2、因此,有必要提出了一种结合dna序列信息来寻找病变修饰差异位点的深度学习方法。
技术实现思路
1、本技术旨在针对现有病变差异位点识别方法未考虑到病变位点周围的dna序列而导致识别能力较差的问题,提供病变差异位点识别方法、装置、设备和存储介质。
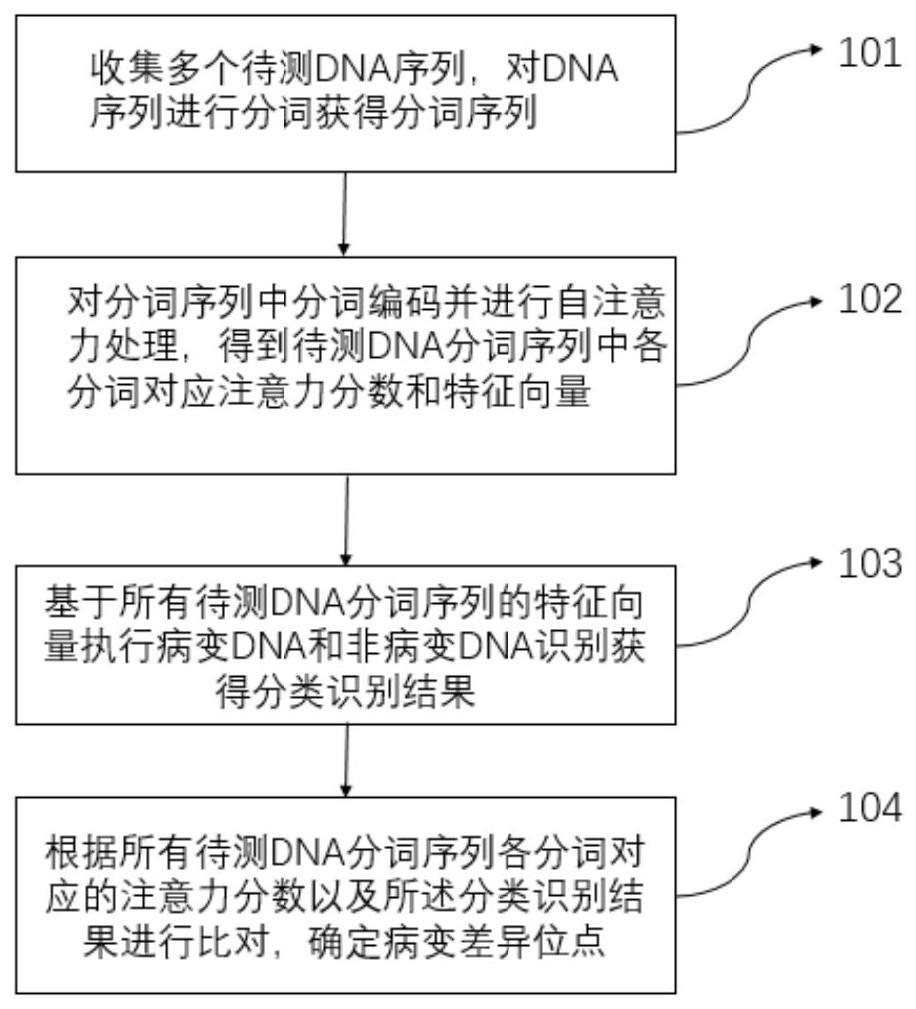
2、第一方面,本技术实施例提供一种病变差异位点识别方法,包括:
3、将多个待测dna分词序列提供给注意力网络模型;通过实施被配置为通过对所述分词序列中分词编码并进行自注意力处理以得到分词对应注意力分数和特征向量的注意力网络模型来获得各分词对应注意力分数和待测dna分词序列的特征向量;
4、将所述待测dna分词序列的特征向量提供给分类识别网络模型;通过实施被配置为基于特征向量执行病变dna和非病变dna识别的分类识别网络模型来获得分类识别结果;
5、根据所有待测dna序列各分词对应注意力分数以及分类识别结果进行比对,确定病变差异位点。
6、在本技术的一个实施例中,注意力网络模型获得各分词对应注意力分数和待测dna分词序列的特征向量,包括:
7、对所述待测dna分词序列中各分词进行嵌入编码处理,得到各分词对应的多维度编码向量;
8、对待测dna分词序列中所有分词对应的多维度编码向量进行自注意力处理得到待测dna分词序列的特征向量;
9、将所述各分词对应的多维度编码向量分别与三个权重矩阵线性相乘得到k、q、v三个向量;
10、基于所述k、q、v三个向量,通过注意力计算函数,得到各分词对应的注意力分数;其中所述注意力计算函数表示如下:
11、
12、其中,dk为向量q或k的列数;softmax表示归一化函数;kt是k的转置。
13、在本技术的一个实施例中,所述注意力网络模型获得各分词对应注意力分数之后,还根据待测dna分词序列的长度对注意力分数进行纠正。
14、在本技术的一个实施例中,所述根据待测dna分词序列的长度对注意力分数进行纠正包括:将确定的注意力分数与纠正系数的乘积作为修正后的注意力分数,其中纠正系数根据所述待测dna分词序列的长度确定。
15、在本技术的一个实施例中,所述纠正系数的表达式如下:
16、
17、其中bp为纠正系数,lc是dna分词序列的长度,lr是所有dna分词序列的平均长度。
18、在本技术的一个实施例中,所述方法还包括:按照如下方式对所述注意力网络模型和分类识别网络模型进行训练:
19、收集已标注为病变dna分词序列和非病变dna分词序列,按照预设比例分为训练集和测试集,并利用所述训练集和测试集对所述注意力网络模型和分类识别网络模型进行训练和测试;
20、基于测试结果调整所述注意力网络模型和分类识别网络模型的参数,直至达到预设的精度要求,以得到所述已训练的注意力网络模型和分类识别网络模型。
21、在本技术的一个实施例中,收集已标注为病变dna分词序列和非病变dna分词序列包括:
22、获取已标注为病变dna序列和非病变dna序列,所述病变dna序列和非病变dna序列为已公开的全基因组dna序列;
23、将dna序列中带有病变位点替换成区别于dna序列中各碱基的转换位,获得替换后的dna序列;
24、对替换后的dna序列进行预处理后得到dna分词序列;
25、从dna分词序列中选取预设比例的分词作为预选分词集合;
26、选取预选分词集合中的分词进行遮蔽,获得遮蔽处理后的dna分词序列。
27、在本技术的一个实施例中,选取预选分词集合中的分词进行遮蔽包括:
28、针对预选分词集合,将其分为含有转换位的分词集合和不含转换位的分词集合;分别按照预设比例从含有转换位的分词集合和/或不含转换位的分词集合中选取分词进行遮蔽。
29、在本技术的一个实施例中,分别按照预设比例从含有转换位的分词集合和/或不含转换位的分词集合中选取分词进行遮蔽包括:
30、按照第一比例从含有转换位的分词集合中选择分词,利用mask进行遮蔽;按照第二比例从含有转换位的分词集合剩下部分选择分词,将分词替换为随机的分词;最后含有转换位的分词集合中其余的分词不进行替换;
31、和/或,按照第三比例从不含转换位的分词集合中选择分词,利用mask进行遮蔽;按照第四比例从不含转换位的分词集合剩下部分选择分词,将分词替换为随机的分词;最后不含转换位的分词集合中其余的分词不进行替换。
32、在本技术的一个实施例中,根据所有待测dna分词序列中各分词对应注意力分数以及所述分类识别结果进行比对,确定病变差异位点,包括:
33、针对病变dna分词序列和非病变dna分词序列,基于各分词的注意力分数确定各碱基对应的注意力分数,根据所述各碱基对应的注意力分数从高到低选取预设比例的碱基构成重要位点区;
34、统计在病变dna分词序列的重要位点区和非病变dna分词序列的重要位点区都出现的位点,若这些位点在病变dna序列和非病变dna序列上存在病变差异,即为病变差异位点。
35、第二方面,本技术还提供病变差异位点识别装置,包括:
36、注意力网络模型,用于对多个待测dna分词序列中各分词编码并进行自注意力处理以得到分词对应注意力分数和待测dna分词序列的特征向量;
37、分类识别网络模型,用于基于所述待测dna分词序列的特征向量执行病变dna和非病变dna识别获得分类识别结果;
38、处理模块,用于根据所有待测dna分词序列中各分词对应注意力分数以及分类识别结果进行比对,确定病变差异位点。
39、在本技术的一个实施例中,所述装置还包括训练模块,所述训练模块用于:
40、收集已标注为病变dna分词序列和非病变dna分词序列,按照预设比例分为训练集和测试集,并利用所述训练集和测试集对所述注意力网络模型和分类识别网络模型进行训练和测试;
41、基于测试结果调整所述注意力网络模型和分类识别网络模型的参数,直至达到预设的精度要求,以得到所述已训练的注意力网络模型和分类识别网络模型。
42、在本技术的一个实施例中,所述训练模块还用于获取已标注为病变dna序列和非病变dna序列,所述病变dna序列和非病变dna序列为已公开的全基因组dna序列;
43、将dna序列中带有病变的位点替换成区别于dna序列中各碱基的转换位,获得替换后的dna序列;
44、对替换后的dna序列进行预处理后得到dna分词序列;
45、从dna分词序列中选取预设比例的分词作为预选分词集合;
46、选取预选分词集合中的分词进行遮蔽,获得遮蔽处理后的dna分词序列。
47、第三方面,本技术还提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面任一种所述的病变差异位点识别方法。
48、第四方面,本技术还提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面任一种所述的病变差异位点识别方法。
49、上述技术方案中的一个技术方案具有如下优点或有益效果:
50、与现有技术相比,本技术基于分词处理后的dna分词序列,充分利用了dna序列信息来寻找病变异位点,并利用了注意力机制和神经网络分类结果,使识别能力提升;
51、本技术在训练注意力网络模型和分类识别网络模型过程中,对病变位点进行遮蔽,结合注意力处理机制,使得网络更多关注病变位点并对其进行学习,进一步提高了病变差异位点识别能力。
52、本技术中计算注意力分数的过程中,根据dna分词序列的长度对注意力分数进行了修正,消除了dna长度对注意力分数的影响,能够全面地反应每个分词的重要性,有利于提高识别效果。
- 还没有人留言评论。精彩留言会获得点赞!