一种基于蛋白质语言模型与蒙特卡洛的多肽设计方法与流程
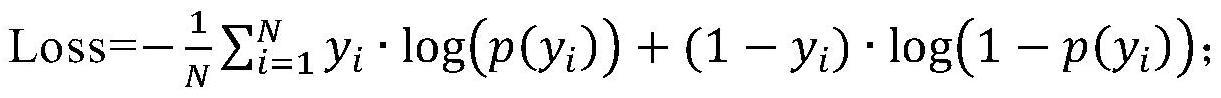
本发明涉及一种基于蛋白质语言模型与蒙特卡洛的多肽设计方法,属于蛋白质多肽设计。
背景技术:
1、蛋白质在生命活动中不是孤立存在的,它需要与不同的配体发生相互作用来完成特定的生物学功能。大多数的治疗药物也是作为配体与目标蛋白质(即受体)相互作用并改变蛋白功能来达到治疗效果的。常见的治疗药物分子包括有机小分子、蛋白质、多肽等。相比于有机小分子和蛋白质而言,多肽型的药物具有天然的优势,其靶向性强且毒副作用弱,是最为优秀的成药对象之一。尽管基于生物实验来设计多肽药物是最为精准的方法,但其耗时、费力且成本高昂,严重阻碍了多肽药物的进程。基于计算的多肽药物设计方法受到了越来越多的关注,主要包括基于结构的和基于序列的两种计算方法。基于结构的计算方法的局限性在于需要已知受体蛋白质的三维结构信息。然而,目前不是所有蛋白质的结构都能被准确测定,大大阻碍了基于结构的计算方法的进展。相反,基于序列的计算方法可以仅从蛋白质序列信息出发设计具有绑定能力的多肽,大幅度提升了多肽药物的设计速度。基于序列的计算方法主要劣势在于用来评价多肽与受体蛋白的绑定能力的指标不精确,从而导致设计性能较低。
2、william f.porto等人于2018年提出的名为joker的方法(见文献joker:analgorithm to insert patterns into sequences for designing antimicrobialpeptides)是为数不多的用于进行多肽设计的基于序列的计算方法,它使用序列模式正则匹配的方式来设计一个固定长度的多肽序列。尽管joker方法可以用来进行多肽设计,但它未充分考虑受体蛋白质序列信息的特异性信息,从而限制了joker方法的多肽设计精度。已有的用于进行多肽设计的基于序列的计算方法在设计精度方面距离实际应用的要求还有很大差距。
技术实现思路
1、为了克服已有的基于序列的计算方法在多肽设计精度上面的不足,本发明提出了一种设计精度高的基于蛋白质语言模型的多肽设计方法。
2、本发明的第一个目的是提供一种基于蛋白质语言模型与蒙特卡洛的多肽设计方法,所述方法包括以下步骤:
3、s1、输入一条待进行多肽配体设计的蛋白质序列s;
4、s2、随机生成一条残基数为l的多肽序列p;
5、s3、搭建深度神经网络预测蛋白质序列s与多肽序列p的绑定概率;
6、s4、收集pdb数据库中已被测定会发生相互作用的蛋白质与多肽序列对数据,构建训练集合来训练步骤s3中搭建的深度神经网络模型,获得训练后的深度神经网络模型;
7、s5、采用蒙特卡洛算法,使用步骤s4中训练后的深度神经网络模型作为能量函数,生成蒙特卡洛轨迹,轨迹中的任一点为一个潜在的多肽设计结果:
8、s501、利用步骤s4中训练的深度神经网络模型,来预测蛋白质序列s与多肽序列p的绑定概率,记作e;
9、s502、随机生成一个1到5之间的整数r,若r为1,则随机从20种常见氨基酸类型中挑选一种氨基酸类型,将该类型的一个氨基酸放置在多肽序列p的n端;若r为2,则随机从20种常见氨基酸类型中挑选一种氨基酸类型,将该类型的一个氨基酸放置在多肽序列p的c端;若r为3,则从多肽序列p的n端删除一个氨基酸;若r为4,则从多肽序列p的c端删除一个氨基酸;若r为5,随机从多肽序列p中挑选一个氨基酸,并将其替换成一个随机类型的氨基酸;将上述新生成的多肽序列记作pnew;
10、s503、利用步骤s4中训练的深度神经网络模型,来预测蛋白质序列s与步骤s502中生成的多肽序列pnew的绑定概率,记作enew;
11、s504、若enew大于e,则pnew为蒙特卡洛轨迹中的一个点,并将pnew作为多肽序列p重新执行步骤s501至步骤s503;若enew小于等于e,则随机生成一个0到1之间的数rd,若rd小于e(enew-e)/t,t为蒙特卡洛算法中的温度参数,则pnew为蒙特卡洛轨迹中的一个点,并将pnew作为多肽序列p重新执行步骤s501至步骤s503,否则直接执行步骤s501至步骤s503;
12、s505、上述过程重复执行,直至获得n个蒙特卡洛轨迹点结束,从这n个轨迹点中,选出与蛋白质序列s绑定概率最高的轨迹点作为最终设计的多肽序列pfinal。
13、进一步地,所述神经网络包含第一子模块、第二子模块、一层交叉注意力层以及一层全连接层;蛋白质序列s输入第一子模块,多肽序列p输入第二子模块,第一子模块和第二子模块的输出直接输入到交叉注意力层,交叉注意力层的输出输入到全连接层,得到s和p的绑定概率。
14、进一步地,第一子模块包含一个冻结了前32层参数的蛋白质语言预训练模型esm2、三个串行的卷积模块和一层全连接层,每个卷积模块包含一层卷积层、一层归一化层和一层激励层。
15、进一步地,第二子模块包含一个冻结了前32层参数的蛋白质语言预训练模型esm2(https://github.com/facebookresearch/esm)、三个串行的卷积模块和一层全连接层,每个卷积模块包含一层卷积层、一层归一化层和一层激励层。
16、进一步地,在步骤s4中,训练步骤s3中搭建的深度神经网络模型时,采用adam优化器和二类交叉熵损失函数来调整网络中的可调参数,adam优化器寻找loss最小时的参数进行自动调整。
17、进一步地,所述二类交叉熵损失函数为
18、其中,yi为第i个训练样本的标签,yi∈{0,1},p(yi)为深度神经网络模型输出的属于yi标签的概率,n为训练样本总数。
19、进一步地,残基数l为5~30。
20、进一步地,蒙特卡洛轨迹点的个数n至少为3000。
21、本发明的第二个目的是提供一种存储器,所述存储器能够执行所述基于蛋白质语言模型与蒙特卡洛的多肽设计方法。
22、本发明的第三个目的是提供一种电子设备,包括处理器;以及,存储器;所述存储器存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器执行所述基于蛋白质语言模型与蒙特卡洛的多肽设计方法。
23、本发明的有益效果是:
24、本发明一方面,从序列信息出发,利用蛋白质语言模型来提取受体蛋白质与新设计的多肽的特征表示,并搭建深度神经网络模型,来预测受体蛋白质与多肽的绑定概率,为提升多肽设计性能做好了准备;另一方面,利用蒙特卡洛算法设计长度不等的多肽序列,并利用上述深度神经网络模型来评估新设计的多肽与受体蛋白质的绑定概率,最高绑定概率对应的多肽序列为最终的设计结果。
技术特征:
1.一种基于蛋白质语言模型与蒙特卡洛的多肽设计方法,其特征在于,所述方法包括以下步骤:
2.根据权利要求1所述的多肽设计方法,其特征在于,所述神经网络包含第一子模块、第二子模块、一层交叉注意力层以及一层全连接层;蛋白质序列s输入第一子模块,多肽序列p输入第二子模块,第一子模块和第二子模块的输出直接输入到交叉注意力层,交叉注意力层的输出输入到全连接层,得到s和p的绑定概率。
3.根据权利要求2所述的多肽设计方法,其特征在于,第一子模块包含一个冻结了前32层参数的蛋白质语言预训练模型esm2、三个串行的卷积模块和一层全连接层,每个卷积模块包含一层卷积层、一层归一化层和一层激励层。
4.根据权利要求2所述的多肽设计方法,其特征在于,第二子模块包含一个冻结了前32层参数的蛋白质语言预训练模型esm2、三个串行的卷积模块和一层全连接层,每个卷积模块包含一层卷积层、一层归一化层和一层激励层。
5.根据权利要求1所述的多肽设计方法,其特征在于,在步骤s4中,训练步骤s3中搭建的深度神经网络模型时,采用adam优化器和二类交叉熵损失函数来调整网络中的可调参数,adam优化器寻找loss最小时的参数进行自动调整。
6.根据权利要求5所述的多肽设计方法,其特征在于,所述二类交叉熵损失函数为
7.根据权利要求1所述的多肽设计方法,其特征在于,残基数l为5~30。
8.根据权利要求1所述的多肽设计方法,其特征在于,蒙特卡洛轨迹点的个数n至少为3000。
9.一种存储器,其特征在于,所述存储器能够执行权利要求1~8任一项所述基于蛋白质语言模型与蒙特卡洛的多肽设计方法。
10.一种电子设备,其特征在于,包括处理器和存储器;所述存储器存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器执行权利要求1~8任一项所述基于蛋白质语言模型与蒙特卡洛的多肽设计方法。
技术总结
本发明公开了一种基于蛋白质语言模型与蒙特卡洛的多肽设计方法,本发明一方面,从序列信息出发,利用蛋白质语言模型来提取受体蛋白质与新设计的多肽的特征表示,并搭建深度神经网络模型,来预测受体蛋白质与多肽的绑定概率,为提升多肽设计性能做好了准备;另一方面,利用蒙特卡洛算法设计长度不等的多肽序列,并利用上述深度神经网络模型来评估新设计的多肽与受体蛋白质的绑定概率,最高绑定概率对应的多肽序列为最终的设计结果。
技术研发人员:张阳,胡俊,李阳
受保护的技术使用者:深药科技(苏州)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!