基于随机森林算法的腹主动脉瘤早期预测方法及系统
本发明涉及一种数据处理领域,更具体地说,它涉及基于随机森林算法的腹主动脉瘤早期预测方法及系统。
背景技术:
1、腹主动脉瘤(aaa)破裂时可导致危及生命的事件,预测腹主动脉瘤采取早期干预和控制的可能性非常重要。超声筛查和计算机断层扫描(ct)图像已经用于腹主动脉瘤的分析。目前,许多研究已将人工智能技术应用于血管外科的辅助诊断和治疗,例如腹主动脉瘤破裂风险的预测。但这些研究只关注腹主动脉瘤形成后的分析。现有技术的方案通常可分为三类:预测腹主动脉瘤腔内修复后破裂的风险和结局。 基于深度学习算法预测腹主动脉瘤的演变以获得破裂风险。分析腹主动脉瘤的致病因素,以进行干预和控制。
2、现在技术中,预测方法主要有以下缺陷:1、缺乏可解释性,目前的研究主要集中在动脉瘤形成后的分析,但显然它已经对患者的身体造成了巨大的伤害。其次,人工智能的“黑匣子”特性阻碍了它在医学领域的进一步应用,医生很难了解预测算法对腹主动脉瘤预测的整个过程,无法在医生和人工智能系统之间建立起互相信任的关系。2、缺乏脉瘤形成之前的有效预测,目前,许多研究已将人工智能技术应用于血管外科的分析与预测,例如超声筛查和计算机断层扫描(ct)图像已经用于腹主动脉瘤的分析,但这些方法只关注腹主动脉瘤形成后的分析,而忽略了如何在腹主动脉瘤形成之前,对腹主动脉瘤的有效预测。
技术实现思路
1、本发明为了解决现有技术中针对腹主动脉瘤早期预测的不足之处,提供一种基于随机森林算法的腹主动脉瘤早期预测方法及系统,本发明以患者的年龄、性别、吸烟、肥胖、高血压以及腹主动脉瘤家族史等特征信息作为第一数据集,基于随机森林算法对第一数据集进行训练,从而得到基于随机森林算法的预测模型,随机森林由多个决策树组成,所有树都彼此独立。当对一个新样本集进行预测时,该样本集属于哪个分类取决于每个决策树的判断,而预测模型本身则是由多个分类器组成,然后通过投票和平均获得最终的预测结果,与现有技术中的预测算法(如神经网络和决策树)相比,随机森林算法具有良好的泛化性能,医生可以了解预测算法对腹主动脉瘤预测的整个过程,从而在医生和人工智能系统之间建立可信任的关系。
2、本发明的上述技术目的是通过以下技术方案得以实现的:
3、本技术的第一方面,提供了一种基于随机森林算法的腹主动脉瘤早期预测方法,方法包括:
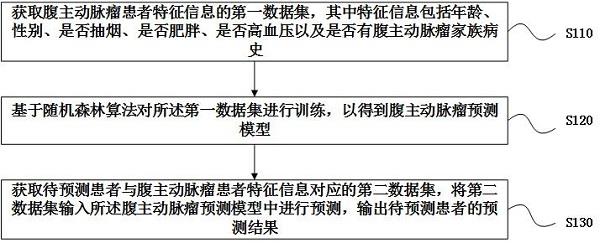
4、获取腹主动脉瘤患者特征信息的第一数据集,其中特征信息包括年龄、性别、是否抽烟、是否肥胖、是否高血压以及是否有腹主动脉瘤家族病史;
5、基于随机森林算法对所述第一数据集进行训练,以得到腹主动脉瘤预测模型;
6、获取待预测患者与腹主动脉瘤患者特征信息对应的第二数据集,将第二数据集输入所述腹主动脉瘤预测模型中进行预测,输出待预测患者的预测结果。
7、在一种实施方案中,基于随机森林算法对所述第一数据集进行训练,以得到腹主动脉瘤预测模型,具体为:
8、随机抽取所述第一数据集的特征信息生成多个随机样本集;
9、基于分类回归算法生成多个随机样本集的分类回归树,并计算多个随机样本集的基尼系数;
10、对于分类回归树当前节点所在的多个随机样本集,在多个随机样本集的基尼系数小于基尼系数阈值时,分类回归算法返回子决策树并停止递归;或者,在多个随机样本集的基尼系数不小于基尼系数阈值时,计算当前节点所在的随机样本集中每个特征信息的基尼系数;
11、将每个特征信息的基尼系数中最小基尼系数对应的特征信息作为最优特征信息,基于所述最优特征信息将对应的随机样本集划分为第一信息集和第二信息集,并将第一信息集和第二信息集分别作为当前节点的左侧子节点和右侧子节点;
12、计算第一信息集和第二信息集的基尼系数,在第一信息集和第二信息集的基尼系数小于基尼系数阈值时,分类回归算法返回子决策树并停止递归,生成多个决策树;
13、由多个分类器对多个决策树进行学习得到腹主动脉瘤预测模型。
14、在一种实施方案中,将第二数据集输入所述腹主动脉瘤预测模型中进行预测,输出待预测患者的预测结果,具体为:
15、将第二数据集按预设比例划分为训练集和测试集;
16、对所述训练集的特征信息进行多次随机采样,得到采样样本集,其中每次随机采样之后将采样的特征信息放回第二数据集进行下一次随机采样;
17、基于多个决策树生成采样样本集的多个权重值;
18、计算多个权重值的和值,以多个权重值的和值除以随机采样的次数,得到待预测患者的预测结果。
19、在一种实施方案中,所述方法还包括:
20、预设第一数据集的特征信息的匹配规则,基于所述匹配规则对决策树所输出的权重值进行修正,对修正后的权重值求和,得到权重修正值;
21、基于腹主动脉瘤预测模型对测试集进行预测,得到测试集的权重平均值;
22、在权重修正值与权重平均值相等时,输出待预测患者的预测结果。
23、在一种实施方案中,从所述第一数据集中随机抽取多个特征信息以得到所述随机样本集,其中所述第一数据集的数据格式为多行多列的数据矩阵。
24、在一种实施方案中,采用接收算子特征曲线对所述腹主动脉瘤预测模型多个输出结果进行选择,以使所述腹主动脉瘤输出待预测患者的预测结果。
25、本技术的第二方面,提供了一种基于随机森林算法的腹主动脉瘤早期预测系统,包括:
26、获取模块,用于获取腹主动脉瘤患者特征信息的第一数据集,其中特征信息包括年龄、性别、是否抽烟、是否肥胖、是否高血压以及是否有腹主动脉瘤家族病史;
27、训练模块,用于基于随机森林算法对所述第一数据集进行训练,以得到腹主动脉瘤预测模型;
28、预测模块,用于获取待预测患者与腹主动脉瘤患者特征信息对应的第二数据集,将第二数据集输入所述腹主动脉瘤预测模型中进行预测,输出待预测患者的预测结果。
29、在一种实施方案中,训练模块包括:
30、随机抽取模块,用于随机抽取所述第一数据集的特征信息生成多个随机样本集;
31、分类树生成模块,基于分类回归算法生成多个随机样本集的分类回归树,并计算多个随机样本集的基尼系数;
32、判断模块,用于对于分类回归树当前节点所在的多个随机样本集,在多个随机样本集的基尼系数小于基尼系数阈值时,分类回归算法返回子决策树并停止递归;或者,在多个随机样本集的基尼系数不小于基尼系数阈值时,计算当前节点所在的随机样本集中每个特征信息的基尼系数;
33、样本划分模块,用于将每个特征信息的基尼系数中最小基尼系数对应的特征信息作为最优特征信息,基于所述最优特征信息将对应的随机样本集划分为第一信息集和第二信息集,并将第一信息集和第二信息集分别作为当前节点的左侧子节点和右侧子节点;
34、决策树生成模块,用于计算第一信息集和第二信息集的基尼系数,在第一信息集和第二信息集的基尼系数小于基尼系数阈值时,分类回归算法返回子决策树并停止递归,生成多个决策树;
35、学习模块,用于由多个分类器对多个决策树进行学习得到腹主动脉瘤预测模型。
36、在一种实施方案中,预测模块,还用于:将第二数据集按预设比例划分为训练集和测试集;对所述训练集的特征信息进行多次随机采样,得到采样样本集,其中每次随机采样之后将采样的特征信息放回第二数据集进行下一次随机采样;基于多个决策树生成采样样本集的多个权重值;计算多个权重值的和值,以多个权重值的和值除以随机采样的次数,得到待预测患者的预测结果。
37、在一种实施方案中,系统还包括:
38、修正模块,用于预设第一数据集的特征信息的匹配规则,基于所述匹配规则对决策树所输出的权重值进行修正,对修正后的权重值求和,得到权重修正值;
39、权重计算模块,用于基于腹主动脉瘤预测模型对测试集进行预测,得到测试集的权重平均值;
40、解释模块,用于在权重修正值与权重平均值相等时,输出待预测患者的预测结果。
41、与现有技术相比,本发明具有以下有益效果:
42、1、本发明提供了一种基于随机森林算法的腹主动脉瘤早期预测方法,以患者的年龄、性别、吸烟、肥胖、高血压以及腹主动脉瘤家族史等特征信息作为第一数据集,基于随机森林算法对第一数据集进行训练,从而得到基于随机森林算法的预测模型,随机森林由多个决策树组成,所有树都彼此独立。当对一个样本集进行预测时,该样本集属于哪个分类取决于每个决策树的判断,而预测模型本身则是由多个分类器组成,然后通过投票和平均获得最终的预测结果,与现有技术中的预测算法(如神经网络和决策树)相比,随机森林算法具有良好的泛化性能,医生可以了解预测算法对腹主动脉瘤预测的整个过程,从而在医生和人工智能系统之间建立可信任的关系。
43、2、本发明进一步的考虑了如何对腹主动脉瘤预测模型的预测结果的可靠性程度进行验证,本发明基于随机森林算法的投票树来解释该算法的决策过程,随机森林主要由多个cart树组成。为了清楚地解释随机森林的决策过程,将每个特征信息作为决策树,并推导了随机森林算法的投票过程。传统的随机森林算法的预测结果是不稳定的,使用可解释性的规则辅助随机森林的推导过程,首先,使用匹配规则对决策树的输出结果进行修正,然后根据测试集中的标签对修正结果进一步验证,在数据集不变的情况下,如果修正结果和通过腹主动脉瘤预测模型对测试集进行所得到权重平均值是相等的,则说明预测结果的具有较高的预测精度。
44、此外,本技术还提供了一种基于随机森林算法的腹主动脉瘤早期预测系统,具备与上述预测方法相同的技术效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!