一种健康数据采集及智能分析方法
本发明涉及健康数据处理,具体涉及一种健康数据采集及智能分析方法。
背景技术:
1、近年来,健康数据的重要性在医疗和健康管理领域得到了广泛认可。随着技术的进步和智能设备的普及,人们能够方便地收集、存储和分析各种健康数据,如心率、血压、睡眠质量等。这些数据提供了宝贵的信息,可以用于个体化的健康管理、预防疾病和改善生活方式。用户画像是对特定个体的综合描述和分析,包括其特征、需求、行为模式等方面的信息。在健康领域中,用户画像是通过分析个人的健康数据来了解其健康状况、生活方式和特定需求的一种方法。
2、在用户画像的构建过程,需要对采集的用户的健康数据进行降维处理,将降维后的用户数据的特征向量来作为用户画像的信息。但是由于采集的用户的健康数据中维度数据较复杂,并且这些维度数据中存在一些数据的变化是由于其他维度数据而产生的,因此传统的数据降维过程中会使得一些不重要的健康数据作为构建用户画像过程中所使用的数据;
3、基于此,本发明提出一种健康数据采集及智能分析方法,通过对用户的健康数据进行自适应pca降维方法,得到准确的降维结果进而获取准确的用户画像。
技术实现思路
1、本发明提供一种健康数据采集及智能分析方法,以解决现有的问题。
2、本发明的一种健康数据采集及智能分析方法采用如下技术方案:
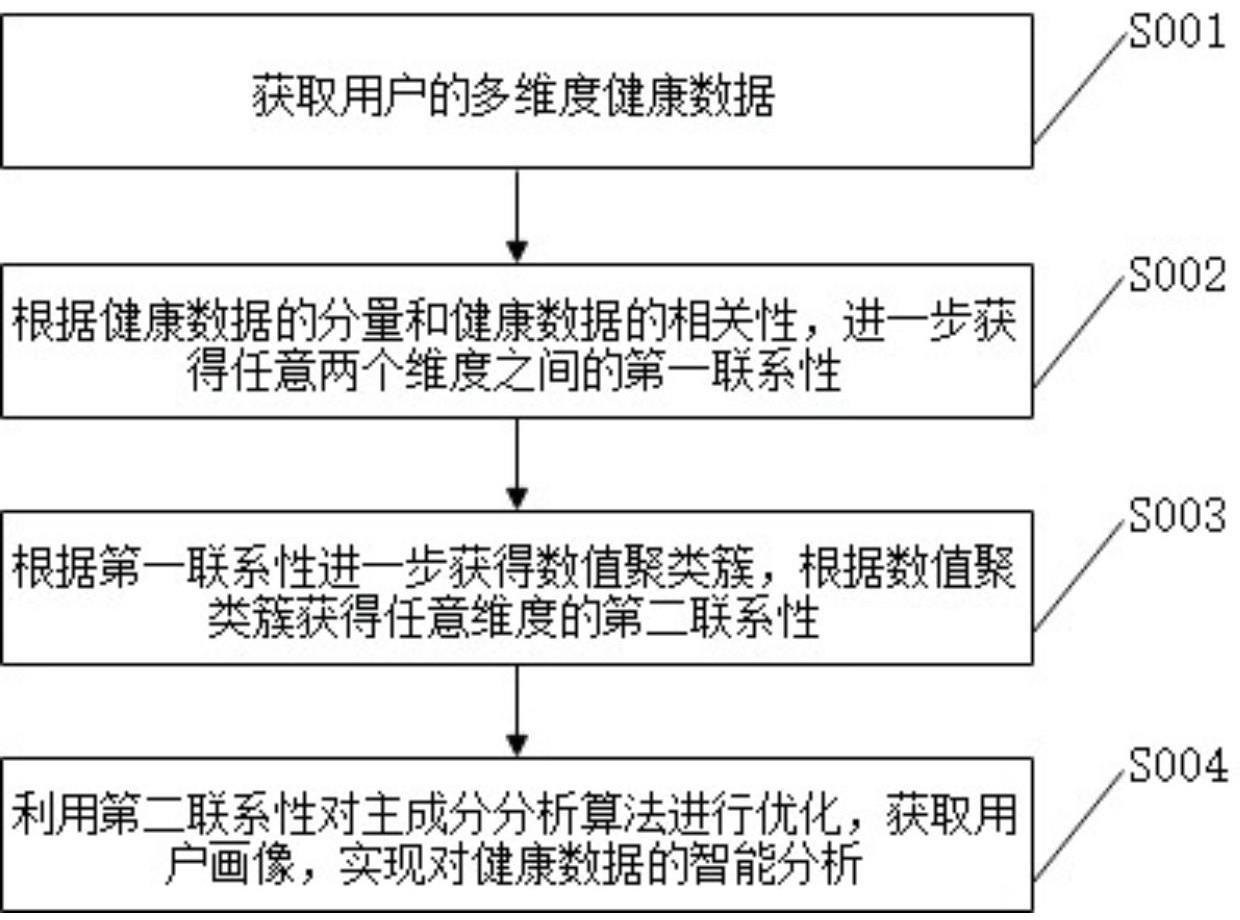
3、本发明提供了一种健康数据采集及智能分析方法,该方法包括以下步骤:
4、获取多个用户的多维度健康数据;
5、获取任意维度健康数据的若干个分量,获取健康数据的分量与健康数据之间的相关性,根据健康数据的分量与健康数据之间的相关性获得健康数据的分量与其他维度的健康数据之间的相关性参数;根据相关性和相关性参数获得不同维度的健康数据之间的关联性;根据健康数据中数据点的差异,获得健康数据的筛选程度,根据筛选程度的大小,获得用户的基本数据;对所有用户的基本数据进行聚类,获得若干个用户聚类簇,根据用户聚类簇中数据点之间的距离,以及健康数据之间的关联性,获得维度时间的第一联系性;
6、根据第一联系性的大小获得维度集合,对任意一个用户聚类簇中,任意维度集合中一个维度的健康数据进行聚类,获得若干个数值聚类簇,根据数值聚类簇获得波动变化范围;根据维度的数量和第一联系性获得参数a,利用健康数据和波动变化范围之间的差异,对参数a进行校正,获得维度的第二联系性;
7、利用第二联系性对主成分分析算法进行校正,获得任意用户的多维度健康数据的降维数据,根据降维数据获取用户画像,实现健康数据的智能分析。
8、进一步的,所述相关性参数的获取方法为:
9、首先,利用独立成分分析算法获取任意维度的健康数据对应的若干个独立成分分量,记为健康数据的分量,并获取第个维度的健康数据的第个分量与第个维度的健康数据之间的皮尔逊相关系数,记为第个维度的第个分量与第个维度的数据之间的相关性,获得用户每天的第个维度的第个分量与第个维度的数据之间的相关性;
10、然后,以天数作为横轴,以相关性作为纵轴,构建相关性的变化曲线,记为相关性曲线,根据健康数据以及健康数据的分量,获得任意维度的健康数据的分量与其他维度的健康数据之间的相关性参数,具体计算方法为:
11、
12、其中,表示第个维度的健康数据的第个分量,与第个维度的健康数据之间的相关性参数;表示第个维度的健康数据的第个分量,与第个维度的健康数据之间的相关性曲线中数据点的数量;表示第个维度的健康数据的第个分量,与第个维度的健康数据之间的相关性曲线中,第个数据点的数值;表示第个维度的健康数据的第个分量,与第个维度的健康数据之间的相关性曲线中,所有数据点的均值。
13、进一步的,所述关联性的获取方法为:
14、将第个维度的健康数据与第个维度的健康数据的所有分量之间的相关性,记为第一特征;
15、第个维度的健康数据的所有分量与第个维度的健康数据之间的相关性参数,记为第二特征;
16、第一特征乘以第二特征,获得第个维度的健康数据与第个维度的关联性。
17、进一步的,所述筛选程度的获取方法为:
18、获取任意健康数据中各个数据点的斜率;并获取任意健康数据的后向差分序列,记为健康差分序列,获取健康差分序列中连续为0时,数字0对应的数量,记为数值不变间隔,获取健康差分序列中所有的数值不变间隔的平均值,记为健康数据的变化平均间隔;利用指数衰减函数将所有数据点的平均斜率进行归一化处理,获得数值x,将数值x与变化平均间隔的乘积结果,记为对应维度的健康数据的筛选程度。
19、进一步的,所述基本数据的获取方法为:
20、对所有维度的健康数据的筛选程度进行线性归一化处理,获取最大的筛选程度对应的健康数据,记为特殊健康数据,获取所有用户的特殊健康数据;
21、获取所有用户中每个维度下的特殊健康数据的数量,将每个维度下的特殊健康数据的数量,与所有用户的所有健康数据的数量的比值,记为对应维度下健康数据的特殊比值,将特殊比值最大时对应维度的健康数据,记为用户的基本数据。
22、进一步的,所述第一联系性的获取方法为:
23、利用dbscan聚类算法,对所有用户的基本数据进行聚类,获得若干个聚类簇,记为用户聚类簇;
24、根据用户聚类簇中数据点之间的距离获得用户聚类簇的聚集性;
25、将所有用户聚类簇的聚集性,与所有用户聚类簇下所有用户中所有维度中,第个维度的健康数据与第个维度的健康数据的平均关联性的乘积结果,记为第个维度与第个维度的第一联系性。
26、进一步的,所述聚集性的获取方法为:
27、利用指数衰减函数,对任意用户聚类簇中所有数据点之间的平均距离,与聚类簇中所有数据点的最大距离治安的比值进行归一化,将归一化结果记为用户聚类簇的聚集性。
28、进一步的,所述波动变化范围的获取方法为:
29、步骤(1),获取任意维度的健康数据与其他维度的健康数据之间的第一联系性,将大于预设的第一联系性阈值时的维度,记为对应维度的联系维度,获得任意维度的若干个联系维度形成的集合,记为维度集合;
30、步骤(2),利用dbscan聚类算法对任意一个用户聚类簇中,任意维度集合中任意一个维度的健康数据的所有数据点进行聚类,获得多个聚类簇,记为数值聚类簇;获取任意数值聚类簇中数据点的数量,记为第一数量;获取任意数值聚簇中每个数据点在健康数据中的时间点,记为第一时间点,获取在其他维度的健康数据中所第一时间点对应的数据点,获取相同数值的数据点的数量,记为第二数量,将第二数量与第一数量的比值记为联合分布概率;
31、步骤(3),根据联合分布概率和健康数据中数据点的数值,获得用户聚类簇中任意用户的第个维度的健康数据,相对第个维度的任意数值聚类簇的波动变化范围,具体计算方法为:
32、
33、其中,表示第个维度的健康数据相对第个维度的波动变化范围;表示第个维度的任意数值聚类簇中数据点的数量;表示第个维度的任意数值聚类簇中的第个数据点的时间点,在第个维度的健康数据中对应数据点的数量;表示第个维度的任意数值聚类簇中第个数据点,与在第个维度的健康数据中对应时间点的第个数据点形成的联合分布概率。
34、进一步的,所述第二联系性的获取方法为:
35、获取第个维度的健康数据相对所有维度的最大波动变化范围,记为,将第个维度的健康数据中所有数据点的数值,与最大波动变化范围之间的最小差值绝对值,记为校正系数;任意用户的第个维度的第二联系性的具体计算方法为:
36、
37、其中,表示第个维度的第二联系性;表示除第个维度外的其他维度的数量,表示第个维度的关联维度的数量;表示校正系数,表示第个维度与对应关联维度中的第个维度之间的第一联系性;表示以自然常数为底数的指数函数。
38、进一步的,所述利用第二联系性对主成分分析算法进行校正,获得任意用户的多维度健康数据的降维数据,根据降维数据获取用户画像,实现健康数据的智能分析,包括的具体步骤如下:
39、首先,利用主成分分析算法对用户的多维度健康数据进行处理,在降维过程中,通过协方差矩阵中获取每个维度的健康数据的特征值,将每个维度的第二联系性与对应的特征值相乘,获得每个维度的健康数据的校正后特征值,完成对多维度健康数据中每一维的健康数据的降维数据;
40、然后,获得大量不同年龄和不同性别的用户的降维数据,将健康、亚健康以及不健康作为降维数据的人工标签,对用户的降维数据进行打标签,将任意用户的所有带有人工标签的降维数据作为一个样本,则由大量的样本形成训练dnn神经网络的数据集,将数据集作为dnn神经网络,结合交叉熵损失函数,对dnn神经网络进行训练,输出用户的健康状态,将用户的年龄、性别以及健康状态,作为用户画像,用于对用户的健康状态进行描述。
41、本发明的技术方案的有益效果是:根据单个用户其自身的维度之间的变化分析,并根据维度数据的分布特性,对多个用户之间进行维度数据层面上的分类,在具有较强相似性的用户之间进行分析,进而得到当前维度与其他维度之间的第一联系性。并结合当前维度数据中的具有关联性的维度数据的分布变化,来获取具有关联性数据的联合分布来获取当前维度数据的波动范围,并结合此波动范围来获取当前维度数据的第二联系性值,进而实现自适应pca降维。避免了传统的pca降维方法中得到的降维结果中包含了较多数据的变化受到其他维度的数据变化影响的维度数据,并且保证了一些具有代表性的维度数据保留,使得计算得到的pca降维结果更加准确,可以精确的构建用户画像。
- 还没有人留言评论。精彩留言会获得点赞!