一种沥青混合料流变次数预测方法及其应用
本发明涉及道路工程,尤其涉及一种沥青混合料流变次数预测方法及其应用。
背景技术:
1、目前,沥青路面的抗车辙性能预测方法可归纳为经验法、力学-经验法和纯力学法三大类:经验法是利用统计回归分析室内试验结果建立沥青混合料变形与材料特性、交通荷载、环境条件等因素之间的数学关系,以此构建车辙预估模型;力学-经验法一般以弹性层状体系理论为基础,结合相关试验数据,建立车辙深度与路面结构和材料参数的经验关系模型;力学法利用沥青混合料材料参数计算沥青路面内部的应力应变,基于弹性或粘弹塑性层状体系理论,通过分析材料变形和应力应变之间的关系来预测沥青路面的车辙深度。
2、而流变次数是表征沥青混合料抗车辙性能的关键指标,通常流变次数越大,抗车辙性能越好,上述经验法和力学-经验法虽使用便捷,但其预测性能存在采集数据集依赖性等问题,且其中由于部分经验模型是从有限的材料和环境条件中得出,其与路面服役性能的相关性并不理想,缺乏鲁棒性,导致推广应用困难;力学法虽可有效克服以上弊端,但其本构模型复杂、参数较多、求解耗时,同样存在推广应用困难的问题。
技术实现思路
1、针对现有技术的不足,本发明提供了一种沥青混合料流变次数预测方法及其应用,解决了传统经验性预测模型缺乏鲁棒性、与实际情况不符或本构模型复杂、参数较多、推广使用困难等弊端的技术问题。
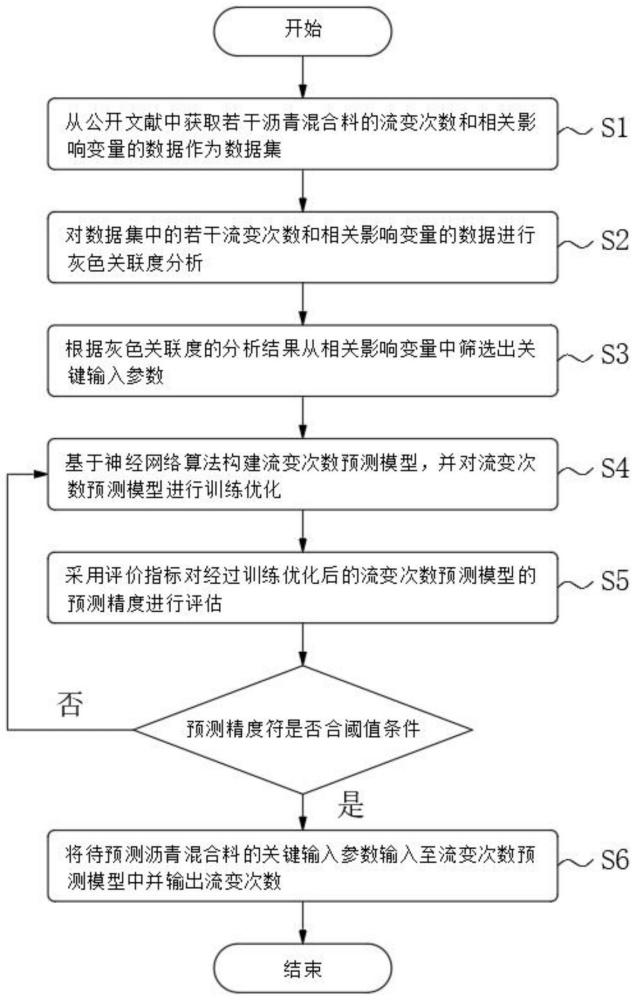
2、为解决上述技术问题,本发明提供了如下技术方案:一种沥青混合料流变次数预测方法,该方法包括以下步骤:
3、s1、从公开文献中获取若干沥青混合料的流变次数和相关影响变量的数据作为数据集;
4、s2、对数据集中的若干流变次数和相关影响变量的数据进行灰色关联度分析;
5、s3、根据灰色关联度的分析结果从相关影响变量中筛选出关键输入参数;
6、s4、基于神经网络算法构建流变次数预测模型,并对流变次数预测模型进行训练优化;
7、s5、采用评价指标对经过训练优化后的流变次数预测模型的预测精度进行评估;
8、若预测精度符合阈值条件,则进入步骤s6;
9、若预测精度不符合阈值条件,则返回步骤s4进行训练优化直至符合;
10、s6、将待预测沥青混合料的关键输入参数输入至流变次数预测模型中并输出流变次数。
11、进一步地,在步骤s1中,相关影响变量包括测试温度(℉)、测试应力水平(psi)、测试侧限水平(psi)、沥青粘度参数a、沥青粘度参数vts、空隙率、矿料间隙率、沥青饱和度(%)、沥青含量(%)、有效沥青体积百分率(%)、19mm筛孔筛余百分率(%)、9.5mm筛孔筛余百分率(%)、4.75mm筛孔筛余百分率(%)和0.075mm筛孔通过百分率(%)。
12、进一步地,在步骤s2中,具体过程包括以下步骤:
13、s21、以流变次数作为母序列y,相关影响变量作为子序列xj;
14、s22、分别计算母序列y和子序列xj无量纲化的参考序列y(i)和比较序列xj(i);
15、s23、分别计算比较序列xj(i)和参考序列y(i)对应元素的关联系数wj(i);
16、s24、根据关联系数wj(i)计算若干流变次数和相关影响变量之间的灰色关联度cj。
17、进一步地,在步骤s22中,参考序列y(i)的计算公式为:
18、
19、比较序列xj(i)的计算公式为:
20、
21、上式中,n为数据集中样本的数量,m为相关影响变量的数量,j为m个相关影响变量中的一个影响变量。
22、进一步地,在步骤s23中,关联系数wj(i)的计算公式为:
23、
24、上式中,i=1,2,…,n;j=1,2,…,m;n为数据集中样本的数量,m为相关影响变量的数量,j为m个相关影响变量中的一个影响变量。
25、进一步地,在步骤s23中,灰色关联度cj的计算公式为:
26、
27、上式中,n表示灰色关联度cj的数量,i表示第i个关联系数。
28、进一步地,在步骤s3中,关键输入参数包括测试温度(℉)、测试应力水平(psi)、测试侧限水平(psi)、沥青粘度参数a、沥青粘度参数vts、沥青饱和度(%)、沥青含量(%)、4.75mm筛孔筛余百分率(%)和0.075mm筛孔通过百分率(%)。
29、进一步地,在步骤s4中,具体包括以下步骤:
30、s41、将数据集划分为训练集和验证集,训练集和验证集分别占整个数据集的70-80%和20-30%,最后对数据集进行归一化处理,其中以关键输入参数作为输入量,相对应的流变次数作为输出变量;
31、s42、采用训练算法为levenberg-marquardt的反向传播算法并设置初始参数,确定激活函数为线性函数purelin和单极性s型函数logsig,选择隐藏层数m和隐藏层节点数n,初步构建流变次数预测模型;
32、s43、对流变次数预测模型进行重复运行,根据运行结果调整训练算法levenberg-marquardt的参数和隐藏层数m以及隐藏层节点数n,直至流变次数预测模型误差达到最小时完成训练优化。
33、进一步地,在步骤s5中,评价指标包括均方差mse、相关系数r、预测值标准误差se和测量值标准误差sy的比值se/sy以及决定系数r2四个指标参数;
34、阈值条件为:当均方差mse趋向于0、相关系数r值≥0.9、预测值标准误差se和测量值标准误差sy的比值se/sy<0.35、决定系数r2≥0.9时,流变次数预测模型的预测精度符合阈值条件。
35、借由上述技术方案,本发明提供了一种沥青混合料流变次数预测方法及其应用,至少具备以下有益效果:
36、1、本发明通过神经网络算法和已有文献中的数据建立沥青混合料流变次数预测模型,克服了传统预测模型缺乏鲁棒性、与实际情况不符或本构模型复杂、参数较多、不宜推广使用等弊端,既操作方便,计算速度快,又能精准预测沥青混合料的流变次数,准确性高。
37、2、本发明通过灰色关联度分析对变量简化处理并筛选关键输入参数,不仅能够避免因模型中包含太多不相关的输入变量而降低训练效率和预测精度,还能够简化数据提取步骤,实际应用时只需提取以上关键输入参数导入模型,即可达到精准预测的目的。
38、3、本发明通过多个指标评价流变次数预测的预测性能,并根据指标优化调整神经网络的算法参数、隐藏层层数m和隐藏层节点数n等,当流变次数预测的误差达到最小时完成训练优化,以保证获得的沥青混合料流变次数预测的精度最佳。
技术特征:
1.一种沥青混合料流变次数预测方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s1中,相关影响变量包括测试温度(℉)、测试应力水平(psi)、测试侧限水平(psi)、沥青粘度参数a、沥青粘度参数vts、空隙率、矿料间隙率、沥青饱和度(%)、沥青含量(%)、有效沥青体积百分率(%)、19mm筛孔筛余百分率(%)、9.5mm筛孔筛余百分率(%)、4.75mm筛孔筛余百分率(%)和0.075mm筛孔通过百分率(%)。
3.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s2中,具体过程包括以下步骤:
4.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s22中,参考序列y(i)的计算公式为:
5.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s23中,关联系数wj(i)的计算公式为:
6.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s23中,灰色关联度cj的计算公式为:
7.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s3中,关键输入参数包括测试温度(℉)、测试应力水平(psi)、测试侧限水平(psi)、沥青粘度参数a、沥青粘度参数vts、沥青饱和度(%)、沥青含量(%)、4.75mm筛孔筛余百分率(%)和0.075mm筛孔通过百分率(%)。
8.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s4中,具体包括以下步骤:
9.根据权利要求1所述的沥青混合料流变次数预测方法,其特征在于,在步骤s5中,评价指标包括均方差mse、相关系数r、预测值标准误差se和测量值标准误差sy的比值se/sy以及决定系数r2四个指标参数;
10.一种用于实现上述权利要求1-9任一项所述的沥青混合料流变次数预测方法的应用,其特征在于,通过预测沥青混合料的流变次数用于表征其抗车辙性能,并精准量化沥青混合料的抗永久变形性能,保证沥青路面高温性能,提升沥青路面设计的可靠度提供坚实支撑。
技术总结
本发明涉及道路工程技术领域,解决了传统经验性预测模型缺乏鲁棒性、与实际情况不符或本构模型复杂、参数较多、推广使用困难等弊端的技术问题,尤其涉及一种沥青混合料流变次数预测方法及其应用,该方法包括以下步骤:S1、从公开文献中获取若干沥青混合料的流变次数和相关影响变量的数据作为数据集;S2、对数据集中的若干流变次数和相关影响变量的数据进行灰色关联度分析。本发明通过神经网络算法和已有文献中的数据建立沥青混合料流变次数预测模型,克服了传统预测模型缺乏鲁棒性、与实际情况不符或本构模型复杂、参数较多、不宜推广使用等弊端,既操作方便,计算速度快,又能精准预测沥青混合料的流变次数,准确性高。
技术研发人员:张德润,管运豪,周宏云,王春,吴勇,韩里呷,徐文,栾东兴,莫国雄,张健
受保护的技术使用者:华中科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!