疾病风险预测模型的建立方法及装置与流程
本技术涉及数据分析处理,具体涉及一种疾病风险预测模型的建立方法及装置。
背景技术:
1、随着医疗健康水平的提升,居民人口逐渐进入老龄化和长寿时代,各种慢性疾病是中老年人群中基本不可避免的。人们越发希望能够有一种提供健康风险评估和预防的解决方案,提高对患病风险预测的准确度,从而帮助人们预知各种疾病的患病风险,从而尽早采取相应的预防或治疗措施。
2、中国专利(授权公告号cn 110993103 b)公开了一种疾病风险预测模型的建立方法和疾病保险产品的推荐方法,其中,该建立方法通过获取预设地区医保参保人员的历史诊疗数据,对历史诊疗数据进行分类抽样处理以得到样本数据集,每个样本数据均包括每个样本在预设时间范围内的历史疾病诊断编码信息,对样本数据集进行剔除无效数据的预处理,并根据疾病属性和病灶部位对预处理后的样本数据集中所有样本各自的历史疾病诊断编码信息进行聚类,得到疾病聚类特征标签,采用预设特征选择算法对疾病聚类特征标签进行筛选以得到重疾聚类特征标签,根据重疾聚类特征标签、性别、年龄和所述就诊行为信息,并结合极端梯度提升算法建立预设重疾对应的疾病风险预测模型,为疾病保险产品推荐的精准度奠定基础。
3、上述方法至少存在以下问题:1)模型构建单纯依赖数据缺乏医学知识,在数据样本不足或者质量不佳的情况,模型的逻辑不可靠。2)极端梯度算法复杂可解释性较差。3)保险产品推荐的根据不足,没有和相应的健康体或标准体对比,对保险产品设计的参考不够具体。
4、因此,亟需一种疾病风险预测模型的建立方法,能够在数据样本数量不足或质量不佳的情况下,提高模型预测精度。
技术实现思路
1、本技术的至少一个实施例提供了一种疾病风险预测模型的建立方法及装置,能够在数据样本数量不足或质量不佳的情况下,提高模型预测精度。
2、根据本技术的一个方面,至少一个实施例提供了一种疾病风险预测模型的建立方法,包括:
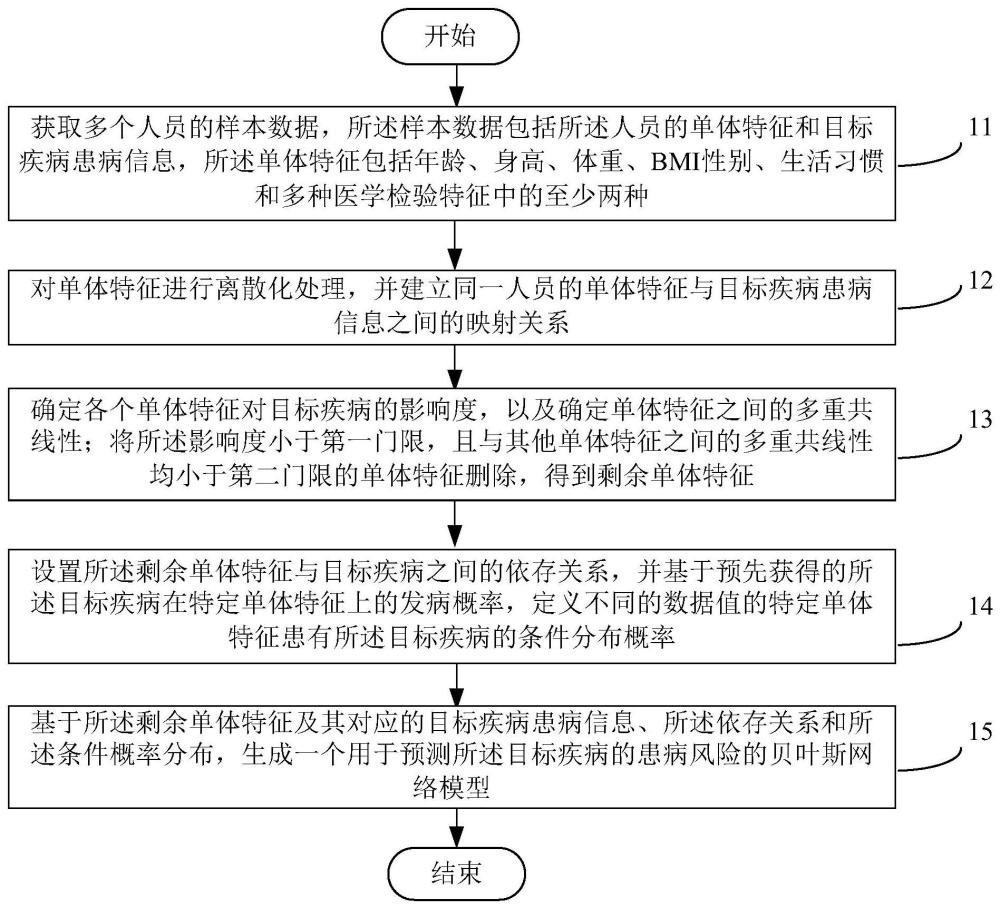
3、获取多个人员的样本数据,所述样本数据包括所述人员的单体特征和目标疾病患病信息,所述单体特征包括年龄、身高、体重、身体质量指数bmi性别、生活习惯和多种医学检验特征中的至少两种;
4、对单体特征进行离散化处理,并建立同一人员的单体特征与目标疾病患病信息之间的映射关系;
5、确定各个单体特征对目标疾病的影响度,以及确定单体特征之间的多重共线性;将所述影响度小于第一门限,且与其他单体特征之间的多重共线性均小于第二门限的单体特征删除,得到剩余单体特征;
6、设置所述剩余单体特征与目标疾病之间的依存关系,并基于预先获得的所述目标疾病在特定单体特征上的发病概率,定义不同的数据值的特定单体特征患有所述目标疾病的条件分布概率;
7、基于所述剩余单体特征及其对应的目标疾病患病信息、所述依存关系和所述条件概率分布,生成一个用于预测所述目标疾病的患病风险的贝叶斯网络模型。
8、可选的,在对单体特征进行离散化处理,并建立同一人员的单体特征与目标疾病患病信息之间的映射关系之前,所述方法还包括:
9、对所述样本数据进行数据预处理,所述数据预处理包括:
10、删除数据值缺失率大于第三门限的单体特征;
11、在第一人员的第一单体特征的数据值缺失但第二单体特征的数据值未缺失,所述第一单体特征与第二单体特征之间的相关系数大于第三门限,且第一单体特征与第二单体特征存在预定函数关系的情况下,根据所述预定函数关系和所述第一人员的第二单体特征的数据值,计算得到第一单体特征的数值并对所述第一人员的第一单体特征进行填补;
12、基于missforest算法,对所述多个人员的样本数据中数据值缺失的单体特征进行数据值插补。
13、可选的,对所述多个人员的样本数据中数据值缺失的单体特征进行数据值插补,包括:
14、针对所述多个人员的样本数据中部分数据值缺失的第三单体特征,生成第一样本集,所述第一样本集包括所述多个人员的样本数据中数据值未缺失的第三单体特征;
15、重复执行以下步骤,构建得到多个决策树模型:从第一样本集中随机抽取预设数量的部分样本,基于抽取的部分样本构建一个决策树模型;
16、基于每个决策树模型,预测所述多个人员的样本数据中数据值缺失的第三单体特征,获得一个预测值;计算基于所述多个决策树模型获得的多个预测值的多种统计值,得到多个候选值;
17、通过k-fold交叉验证,分别对每个候选值进行评估,根据评估结果,选择最优的候选值,对数据值缺失的第三单体特征进行插补。
18、可选的,所述多种统计值包括平均值、中位数、众数中的至少两种。
19、可选的,还包括:
20、使用分类指标对生成的所述贝叶斯网络模型进行评估,所述分类指标包括召回率、精确率和auc。
21、可选的,还包括:
22、获取待预测人员的单体特征;
23、将所述待预测人员的单体特征输入至所述贝叶斯网络模型,得到所述目标疾病的患病概率。
24、可选的,还包括:
25、使用shaply可解释算法,对所述目标疾病的患病概率与所述待预测人员的单体特征之间的关系进行解释。
26、根据本技术的另一方面,至少一个实施例提供了一种疾病风险预测模型的建立装置,包括:
27、第一获取模块,用于获取多个人员的样本数据,所述样本数据包括所述人员的单体特征和目标疾病患病信息,所述单体特征包括年龄、身高、体重、身体质量指数bmi性别、生活习惯和多种医学检验特征中的至少两种;
28、第一处理模块,用于对单体特征进行离散化处理,并建立同一人员的单体特征与目标疾病患病信息之间的映射关系;
29、第二处理模块,用于确定各个单体特征对目标疾病的影响度,以及确定单体特征之间的多重共线性;将所述影响度小于第一门限,且与其他单体特征之间的多重共线性均小于第二门限的单体特征删除,得到剩余单体特征;
30、第三处理模块,用于设置所述剩余单体特征与目标疾病之间的依存关系,并基于预先获得的所述目标疾病在特定单体特征上的发病概率,定义不同的数据值的特定单体特征患有所述目标疾病的条件分布概率;
31、生成模块,用于基于所述剩余单体特征及其对应的目标疾病患病信息、所述依存关系和所述条件概率分布,生成一个用于预测所述目标疾病的患病风险的贝叶斯网络模型。
32、可选的,还包括:
33、预处理模块,用于在对单体特征进行离散化处理,并建立同一人员的单体特征与目标疾病患病信息之间的映射关系之前,对所述样本数据进行数据预处理,所述数据预处理包括:
34、删除数据值缺失率大于第三门限的单体特征;
35、在第一人员的第一单体特征的数据值缺失但第二单体特征的数据值未缺失,所述第一单体特征与第二单体特征之间的相关系数大于第三门限,且第一单体特征与第二单体特征存在预定函数关系的情况下,根据所述预定函数关系和所述第一人员的第二单体特征的数据值,计算得到第一单体特征的数值并对所述第一人员的第一单体特征进行填补;
36、基于missforest算法,对所述多个人员的样本数据中数据值缺失的单体特征进行数据值插补。
37、可选的,所述预处理模块,还用于:
38、针对所述多个人员的样本数据中部分数据值缺失的第三单体特征,生成第一样本集,所述第一样本集包括所述多个人员的样本数据中数据值未缺失的第三单体特征;
39、重复执行以下步骤,构建得到多个决策树模型:从第一样本集中随机抽取预设数量的部分样本,基于抽取的部分样本构建一个决策树模型;
40、基于每个决策树模型,预测所述多个人员的样本数据中数据值缺失的第三单体特征,获得一个预测值;计算基于所述多个决策树模型获得的多个预测值的多种统计值,得到多个候选值;
41、通过k-fold交叉验证,分别对每个候选值进行评估,根据评估结果,选择最优的候选值,对数据值缺失的第三单体特征进行插补。
42、根据本技术的另一方面,至少一个实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有程序,所述程序被处理器执行时,实现如上所述的方法的步骤。
43、与现有技术相比,本技术实施例提供的疾病风险预测模型的建立方法及装置,能够在数据样本数量不足或质量不佳的情况下,提高模型预测精度。另外,本技术实施例还能够提供预测结果的可解释性。
- 还没有人留言评论。精彩留言会获得点赞!