循环核酸序列分析模型训练方法、循环核酸序列分析方法
本公开涉及人工智能,尤其涉及一种循环核酸序列分析模型训练方法、循环核酸序列分析方法。
背景技术:
1、目前,早期的肿瘤诊断是预防和治疗肿瘤的关键。相关技术中通过利用循环核酸序列分析模型对人体血浆中的循环核酸序列进行分析,从而生成关于肿瘤信息的诊断结果。
2、在实现本公开构思的过程中,发明人发现相关技术中至少存在如下问题:在对循环核酸序列分析模型进行训练的过程中,由于循环核酸序列的数据量较大,且肿瘤的循环核酸序列异质性高,导致模型的训练效率较低。
技术实现思路
1、鉴于上述问题,本公开提供了循环核酸序列分析模型训练方法、循环核酸序列分析方法、装置和电子设备。
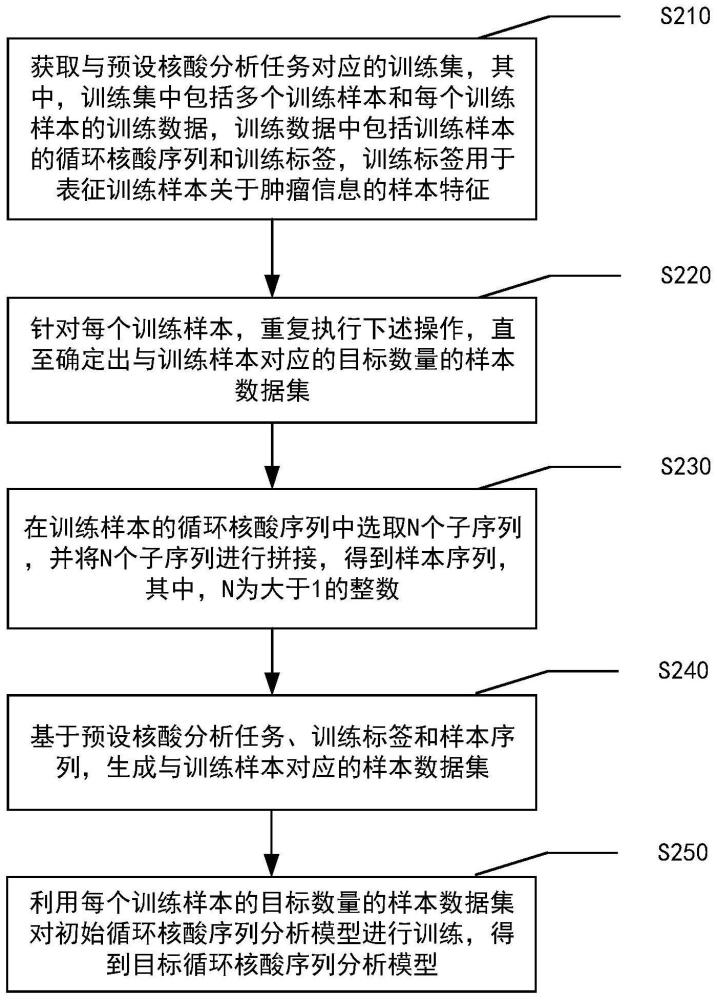
2、根据本公开的第一个方面,提供了一种循环核酸序列分析模型训练方法,包括:
3、获取与预设核酸分析任务对应的训练集,其中,上述训练集中包括多个训练样本和每个上述训练样本的训练数据,上述训练数据中包括上述训练样本的循环核酸序列和训练标签,上述训练标签用于表征上述训练样本关于肿瘤信息的样本特征;
4、针对每个上述训练样本,重复执行下述操作,直至确定出与上述训练样本对应的目标数量的样本数据集;
5、在上述训练样本的循环核酸序列中选取n个子序列,并将上述n个子序列进行拼接,得到样本序列,其中,n为大于1的整数;
6、基于上述预设核酸分析任务、上述训练标签和上述样本序列,生成与上述训练样本对应的样本数据集;
7、利用每个上述训练样本的目标数量的样本数据集对初始循环核酸序列分析模型进行训练,得到目标循环核酸序列分析模型。
8、根据本公开的实施例,上述方法还包括:
9、根据与上述循环核酸序列对应的测序类型,确定上述目标数量,其中,上述循环核酸序列是利用与上述测序类型对应的测试方式进行测试得到的。
10、根据本公开的实施例,上述基于上述预设核酸分析任务、上述训练标签和上述样本序列,生成与上述训练样本对应的样本数据集,包括:
11、将上述预设核酸分析任务、上述训练标签和上述样本序列进行组合,得到上述样本数据集,其中,上述样本数据集如下:
12、xi,train={ii,xi,n,yi}
13、其中,ii表示上述预设核酸分析任务,xi,n表示上述样本序列,n表示上述样本序列中子序列的数量,yi表示上述训练标签。
14、根据本公开的实施例,上述初始循环核酸序列分析模型包括嵌入层和m个解码器,上述利用每个上述训练样本的目标数量的样本数据集对初始循环核酸序列分析模型进行训练,得到目标循环核酸序列分析模型,包括:
15、针对一个上述样本数据集,将上述样本数据集输入上述嵌入层中,输出与上述样本数据集对应的特征向量,其中,上述嵌入层包括位置编码层和词编码层;
16、将上述特征向量依次输入上述m个解码器中进行特征提取,输出序列特征,其中,m为大于1的整数;
17、将上述序列特征输入线性分类器中进行最大似然估计,得到条件概率参数;
18、利用上述条件概率参数对上述初始循环核酸序列分析模型进行调参,得到上述目标循环核酸序列分析模型。
19、根据本公开的实施例,上述解码器中包括掩码自注意力机制层和前馈神经网络层,上述将上述特征向量依次输入上述m个解码器中进行特征提取,输出序列特征,包括:
20、将上述特征向量输入第一解码器中的掩码自注意力机制层中,输出掩码特征,其中,上述第一解码器为上述m个解码器中第一个解码器;
21、将上述掩码特征输入第一解码器中的前馈神经网络层中进行非线性变化,输出变化特征;
22、根据上述m个解码器之间的连接关系,将上述变化特征输入多个第二解码器中依次进行特征提取,输出上述序列特征,其中,上述第二解码器为上述m个解码器除上述第一解码器以外的解码器。
23、根据本公开的实施例,上述将上述序列特征输入线性分类器中进行最大似然估计,得到条件概率参数,包括:
24、将上述序列特征输入上述线性分类器中进行回归分析,得到预测结果;
25、确定基于上述训练标签建立的词库,其中,上述词库如下:
26、w={w1,w2,...,wn}
27、其中,w表示上述词库,n表示上述词库中词语的总数;
28、将上述预测结果输入最大似然函数中,输出中间概率参数,其中,上述最大似然函数如下:
29、
30、其中,k表示上述预测结果的文本长度,θ表示条件概率参数,表示预测结果与词库中每个词语的相似度;
31、基于上述相似度对上述中间概率参数进行调整,得到上述条件概率参数。
32、根据本共公开的另一方面,提供了一种循环核酸序列分析方法,包括:
33、获取目标循环核酸序列和与上述目标循环核酸序列对应的核酸序列分析任务;
34、将上述目标循环核酸序列和上述核酸分析任务进行组合,得到分析数据集;
35、将上述分析数据集输入任一项上述目标循环核酸序列分析模型中,输出用于表征上述目标循环核酸序列关于肿瘤信息的分析结果。
36、根据本共公开的另一方面,提供了一种循环核酸序列分析模型训练装置,包括:
37、数据获取模块,用于获取与预设核酸分析任务对应的训练集,其中,上述训练集中包括多个训练样本和每个上述训练样本的训练数据,上述训练数据中包括上述训练样本的循环核酸序列和训练标签,上述训练标签用于表征上述训练样本关于肿瘤信息的样本特征;
38、数据确定模块,用于针对每个上述训练样本,重复执行下述操作,直至确定出与上述训练样本对应的目标数量的样本数据集;
39、序列拼接模块,用于在上述训练样本的循环核酸序列中选取n个子序列,并将上述n个子序列进行拼接,得到样本序列,其中,n为大于1的整数;
40、数据生成模块,用于基于上述预设核酸分析任务、上述训练标签和上述样本序列,生成与上述训练样本对应的样本数据集;
41、模型训练模块,用于利用每个上述训练样本的目标数量的样本数据集对初始循环核酸序列分析模型进行训练,得到目标循环核酸序列分析模型。
42、根据本共公开的另一方面,提供了一种循环核酸序列分析装置,包括:
43、序列获取模块,用于获取目标循环核酸序列和与上述目标循环核酸序列对应的核酸序列分析任务;
44、数据组合模块,用于将上述目标循环核酸序列和上述核酸分析任务进行组合,得到分析数据集;
45、数据分析模块,用于将上述分析数据集输入上述实施例的任一项上述目标循环核酸序列分析模型中,输出用于表征上述目标循环核酸序列关于肿瘤信息的分析结果。
46、本公开的第三方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当上述一个或多个程序被上述一个或多个处理器执行时,使得一个或多个处理器执行上述方法。
47、根据本公开提供的循环核酸序列分析模型训练方法、循环核酸序列分析方法、装置和电子设备,通过将采集到的核酸序列片段作为子序列,并对子序列进行拼接得到样本序列,将样本序列作为一次进行依次检测的输入,减少了输入到初始循环核算序列分析模型的次数,一定程度上从操作流程上减少了模型训练的时间。对于每次输入初始循环核酸序列分析模型的样本数据集中包括预设核酸分析任务,预设核酸分析任务可以提示初始核酸序列分析模型对血酸序列进行分析和分类,一定程度上避免了初始核酸序列分析模型执行与本次训练无关的操作,提高了初始核酸序列分析模型的的处理效率。另外,初始循环核酸序列分析模型可以根据训练标签学习循环核酸序列和肿瘤信息之间的关联,以及相同训练标签下,不同训练样本的样本数据集之间的相似性,从而提高了初始循环核酸序列分析模型的的分析效率。
- 还没有人留言评论。精彩留言会获得点赞!