一种基于深度强化学习的多智能体在三维场景中的群集控制方法及系统
本发明涉及人工智能,具体涉及一种基于深度强化学习的多智能体在三维场景中的群集控制方法及系统。
背景技术:
1、随着科技的不断发展,人类不仅仅希望工具可以帮助其提高效率,而且能够模拟人类的思维进行自主学习,从而可以不在人为干预下解决问题。人工智能自诞生发展到现在,理论和技术不断发展并且日趋成熟,应用范围也不断扩大,其中包括图像识别、机器人、自然语言处理以及计算机游戏。可以想象,人工智能在未来会为人类的生活提供更多的便捷。
2、计算机游戏不仅包括数学、物理、渲染等工业方面的技术,而且还需要剧情创作、艺术创作以及音乐和声音特效等技术。因此计算机游戏是一项综合性的复杂产业。随着计算机技术的不断发展,游戏在画面表现力上得到了巨大的提升。同时,为了使游戏更加有趣味性以及游戏中的角色更符合对应现实中角色的行为,计算机游戏中的人工智能逐渐成为人工智能的主要研究领域之一。在早期的游戏中,开发人员为了让游戏角色表现出一定的智能性,会为不同类型的游戏设计一些简单但执行性能高效的技术,如目标追逐与躲避、智能寻路以及序列化的脚本动作。然而,这一阶段的游戏角色行为往往局限于开发人员定义的行为,具有固定性,玩家在经过一段时间的游戏体验后,很可能会发现其中的规律。但是,由于这类方法易于开发和调试以及执行效率高,到目前仍有很多游戏采用这种技术应用到游戏角色中去。
3、在计算机硬件、3d图形渲染、虚拟现实技术以及音频音效的支持下,计算机游戏衍生许多类型不同的游戏,包括战争策略、动作射击、角色扮演、经营模拟等。随着游戏环境质量的提高和游戏类型的增多,早期简单确定的基于脚本化的人工智能远远不能满足现代游戏的需要。不同类型的游戏需要的人工智能理论和技术也不相同,例如棋牌类游戏需要人工智能中的博弈理论,而战争类型需要游戏角色的协作智能等。游戏需要为此提供更加真实可信的人工智能。因此,游戏开发需要完整的人工智能模型,使得游戏角色具有完整的智能行为,游戏角色能够感知并接收外部环境的某些信息,根据外部环境的状态和信息以及自身的状态做出符合人类思维的行为。具有“自主学习”的游戏角色,称之为智能体。
4、人工智能在理论学术方面有着巨大的发展,学术上的人工智能对于智能体的定义是,能够感知环境做出决策,然后做出相应行为来获取最大化利益的系统。一般来说,学术上的人工智能研究不存在计算机硬件和计算时间方面的限制,其主要目的是在于模拟人类的思维和决策。然而,游戏人工智能需要考虑到游戏是一种对即时性要求非常高的系统,需要在一定时间内完成对游戏角色在人工智能方面的处理。但是随着计算机硬件的提升以及gpu的出现,将cpu从需要巨大计算量的图形渲染中解放出来,使得将传统理论上的人工智能应用到游戏这一实时系统中成为可能。
5、目前应用在游戏中的理论人工智能包括:基于范例推理、产生式系统、规划系统、专家系统、多智能体系统、遗传算法、人工神经网络、群聚技术、模糊逻辑和一阶逻辑等技术已经被用于一些对智能要求较高游戏中。
6、综上所述,计算机游戏特别是即时战略游戏能够提供复杂且逼真的环境,为研究理论上的人工智能并将其用于实际场景中提供了良好的平台。因此,基于游戏的人工智能不仅能够提升游戏的质量,更重要的是将人工智能从理论转换成可用于现实生活中的重要技术,计算机游戏是具有广阔前景的人工智能研究平台。由此可见,研究即时战略游戏的人工智能是非常有必要的。
7、目前在战略游戏中,多智能体在三维场景中的编队控制,是通过矩阵进行阵型设置,生成的对象仅跟随阵型的中心点移动,该方法在进行阵型变换时需要对矩阵进行大量的计算,同时对象限制于阵型中,编队的可塑性低。
技术实现思路
1、为了克服现有技术的不足,本发明提供一种基于深度强化学习的多智能体在三维场景中的群集控制方法及系统,用于解决现有多智能体在三维场景中的编队控制方法,进行阵型变换时需要进行大量的计算以及编队可塑性低的技术问题,从而达到降低阵型变换时的计算量以及增强编队可塑性的目的。
2、为解决上述问题,本发明所采用的技术方案如下:
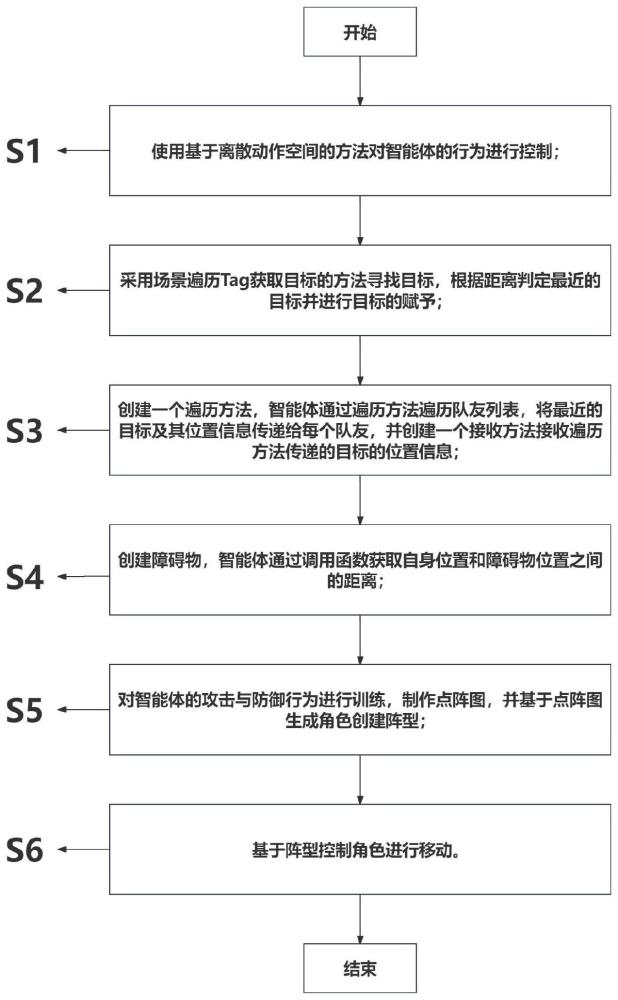
3、一种基于深度强化学习的多智能体在三维场景中的群集控制方法,包括以下步骤:
4、使用基于离散动作空间的方法对智能体的行为进行控制;
5、采用场景遍历tag获取目标的方法寻找目标,根据距离判定最近的目标并进行目标的赋予;
6、创建一个遍历方法,所述智能体通过所述遍历方法遍历队友列表,将最近的目标及其位置信息传递给每个队友,并创建一个接收方法接收所述遍历方法传递的目标的位置信息;
7、创建障碍物,所述智能体通过调用函数获取自身位置和障碍物位置之间的距离;
8、对所述智能体的攻击与防御行为进行训练,制作点阵图,并基于所述点阵图生成角色创建阵型;
9、基于所述阵型控制所述角色进行移动。
10、作为本发明优选的实施方式,在使用基于离散动作空间的方法对智能体的行为进行控制时,包括:
11、根据ml-agents语法创建actions.discreteaction[]数组;
12、通过behavior parameters组件设置所述actions.discreteaction[]数组中值的范围,并将所述actions.discreteaction[]数组中的值随机输出,分别赋给move、rotate、attack和attdef四个变量,以表示所述智能体在不同方面的行为决策;
13、根据move的值,确定所述智能体在x轴和z轴上的移动行为,并通过设置所述智能体的位置改变量,决定施加给所述智能体的移动力的方向;
14、根据rotate的值,确定所述智能体围绕y轴的旋转行为,并通过设置智能体的旋转改变量,决定所述智能体围绕y轴旋转的方向;
15、根据attack和attdef的值,确定所述智能体是否进行攻击或者防御行为;
16、根据ismove的值,判断智能体是否进行移动。
17、作为本发明优选的实施方式,在判定最近的目标并进行目标的赋予时,包括:
18、创建findclosestenemy()方法,根据所述智能体的位置与敌人的位置之间的距离,找到最近的敌人;
19、将所述最近的敌人赋值给所述智能体的target属性,通过ml-agents中射线传感器组件,模拟所述智能体的视角,并设置需要观测的对象tag,以获取环境的数据;
20、其中,在所述findclosestenemy()方法中,所述智能体通过gameobject.findwithtag("enemy")来查找所有带有标签"enemy"的物体,遍历所有找到的敌人,并获取所述智能体与敌人之间的距离,根据距离的平方差,确定最近的敌人,并将其赋值给target;
21、设定一个距离目标点一定单位距离的范围,当所述智能体处于这个范围内时,给予正向奖励分数,以使所述智能体倾向于靠近所述目标点,一旦所述智能体成功到达所述目标点并获得奖励分数,则所述智能体通过与环境数据交互,学习到前往所述目标点的最佳路线。
22、作为本发明优选的实施方式,在创建接收方法进行接收时,包括:
23、创建一个receivetarget()方法接收findteam()方法传递的目标的位置信息;
24、在所述findteam()方法传递目标的位置信息时,包括:
25、若最近的敌人位置信息是有效的,则将敌人位置信息一起传递给队友,否则只传递最近的敌人对象信息,队友接收到信息后根据目标敌人来优化自己的策略网络;
26、其中,所述遍历方法为findteam()方法,所述接收方法为receivetarget()方法。
27、作为本发明优选的实施方式,在创建障碍物时,包括:
28、判断是否需要清除之前生成的障碍物,若需要清除,则调用cleargeneratedobjects函数清除之前生成的障碍物;
29、创建generate函数方法用于生成障碍物并添加在start函数中调用;
30、其中,在生成障碍物时,包括:
31、通过一个循环,生成指定数量的障碍物,并在每次循环中,通过generaterandomposition函数生成一个随机位置,并检查所述随机位置是否与已生成的障碍物重叠;
32、若重叠,则继续生成新的随机位置,直到找到合适的位置或达到最大尝试次数;
33、若未重叠,则认为找到可生成障碍的随机位置,返回所述随机位置,并通过instantiate函数在所述随机位置实例化一个新的障碍物,并将其添加到generatedobjects列表中。
34、作为本发明优选的实施方式,在通过调用函数获取自身位置和障碍物位置之间的距离时,包括:
35、所述智能体通过调用vector3.distance函数获取自身位置和障碍物位置之间的距离,若小于预设值,则给予负向奖励以避免所述智能体与所述障碍物碰撞;
36、所述智能体通过调用vector3.distance函数获取获取自身位置和敌人位置之间的距离,若小于预设值,则给予正向奖励以促使所述智能体接近敌人。
37、作为本发明优选的实施方式,在对所述智能体的攻击与防御行为进行训练时,包括:
38、通过将武器模型和防具模型与所述智能体手部绑定,设置所述智能体可攻击防御的范围大于武器与防具可运动的最大距离,并获取攻击目标和防御物品的位置信息;
39、通过判定所述武器模型上点位与目标身体的距离,判断攻击的命中状况;
40、通过判定所述防具模型中心点与目标武器的距离,判断防御的成功与否。
41、作为本发明优选的实施方式,在基于所述点阵图生成角色创建阵型时,包括:
42、在genformation函数中,通过formation的evaluatepoints函数获取一个要生成角色的点阵图,并将所述点阵图转换为包含vector3坐标的points列表;
43、根据points列表与当前生成的角色数量的比较,决定是生成更多角色还是删除多余的角色;
44、若所述points列表中的点比生成的角色数量多,则需要生成更多角色;
45、获取需要生成的角色数量,创建一个包含所述需要生成的角色数量的子集;
46、调用spawnavatar函数,在所述子集中循环,为每个点生成一个角色;在生成角色时,实例化unitprefab并设置其位置、旋转和所属的父级对象,同时获取其相关的组件,并将生成的角色添加到spawnedunits列表中;
47、在循环中遍历所述spawnedunits列表,更新每个角色的位置和方向。
48、作为本发明优选的实施方式,在基于所述阵型控制所述角色进行移动时,包括:
49、在getallunits函数中,传入一个列表参数targets,用于存储所有角色的位置信息;
50、在所述getallunits函数的实现中,清空目标列表,遍历所生成的每一个角色,对于每个角色,将其位置信息添加到目标列表targets中;
51、在主函数中的moveunits协程中,通过调用getallunits(target)来获取所有角色的位置信息;
52、创建movingunits数组存放需要移动的角色,若一个角色不在所述moving units数组中,则表示角色为非移动单位;将所述非移动单位的位置向后偏移,直至移动到目标位置;
53、其中,在移动非移动单位时,包括:
54、定义一个偏移量moveoffset,通过所述偏移量moveoffset确定所述非移动单位的最终位置;调用协程movetopositions在一定的时间内逐渐将所述非移动单位从其起始位置逐渐移动到目标位置。
55、一种基于深度强化学习的多智能体在三维场景中的群集控制系统,包括:
56、行为控制单元:用于使用基于离散动作空间的方法对智能体的行为进行控制;
57、目标寻找单元:用于采用场景遍历tag获取目标的方法寻找目标,根据距离判定最近的目标并进行目标的赋予;
58、位置信息获取单元:用于创建一个遍历方法,所述智能体通过所述遍历方法遍历队友列表,将最近的目标及其位置信息传递给每个队友,并创建一个接收方法接收所述遍历方法传递的目标的位置信息;
59、障碍物创建单元:用于创建障碍物,所述智能体通过调用函数获取自身位置和障碍物位置之间的距离;
60、行为训练及阵型构建单元:用于对所述智能体的攻击与防御行为进行训练,制作点阵图,并基于所述点阵图生成角色创建阵型;
61、移动控制单元:基于所述阵型控制所述角色进行移动。
62、相比现有技术,本发明的有益效果在于:
63、(1)本发明通过提出一种通过ml-agents强化学习算法训练智能体,并使用点阵图设计可变的阵型,根据敌方单位的距离或操作者的指令释放智能体,通过强化学习的智能体能够自主地寻找敌方单位,减少了对索敌系统的编写,同时由于强化学习的适应性,能够在各种不同障碍布局的环境下适应环境并索敌,一定程度上的减少了开发的流程;
64、(2)本发明采用深度强化学习算法来训练智能体,在智能体中设计一个行为模式,通过观察信息作为输入来输出动作。智能体通过不断学习优化,逐步改善其自主决策和行动能力。该训练方法在不使用编辑器自带的寻路系统的前提下使智能体能自主地决定如何在环境中移动和行动,而不是依赖预设的路径规划系统,使得智能体能够更好地应对场景中布局的变化;
65、(3)本发明采用点阵图进行群集坐标设置,实现群集阵型的自由变换和多样化移动。通过对点阵图进行采样,得到群集对象的坐标,并利用这些坐标生成相应的角色。生成的角色被限制在坐标范围内,避免了在移动过程中阵型受到破坏的问题。当需要切换图片时,程序将再次进行采样和坐标设置,从而实现群集阵型的变换。同时,通过对点位的设置,可以应用不同的阵型移动方式,赋予群集多样化的行动形式。生成的角色被妥善存储在数组中,便于管理和控制。通过遍历数组并利用协程,可以在点阵图的基础上实现更多种多样的阵型设置。采用基于点阵图的群集坐标设置和多样化阵型移动方法,为应对不同的应用场景和需求提供了灵活且具有可扩展性的解决方案。
66、下面结合附图和具体实施方式对本发明作进一步详细说明。
- 还没有人留言评论。精彩留言会获得点赞!