一种扫地机器人的物体识别方法及系统与流程
本发明涉及物体识别领域,尤其涉及一种扫地机器人的物体识别方法及系统。
背景技术
随着人工智能技术在我国科技产品市场的逐步落地,目前家用扫地机器人正在为越来越多的家庭带来便利。家用扫地机器人通过搭载各种距离探测器(如激光雷达、红外探测器)、里程计、陀螺仪等传感器智能感知周围环境,实现自主行走清扫的功能。对于市面上主流的激光雷达传感器,由于其感知的信息有限,且成本较高,因此难以进一步在普通家庭推广,也难以实现精准的实时识别,在线识别周边环境的物体信息。
技术实现要素:
为了克服上述技术缺陷,本发明提供一种扫地机器人的物体识别方法及系统,通过该方法可实时获得周围物体的类别信息和位置信息,在此基础上可以实现更加精细的语义地图构建和导航避障功能等。
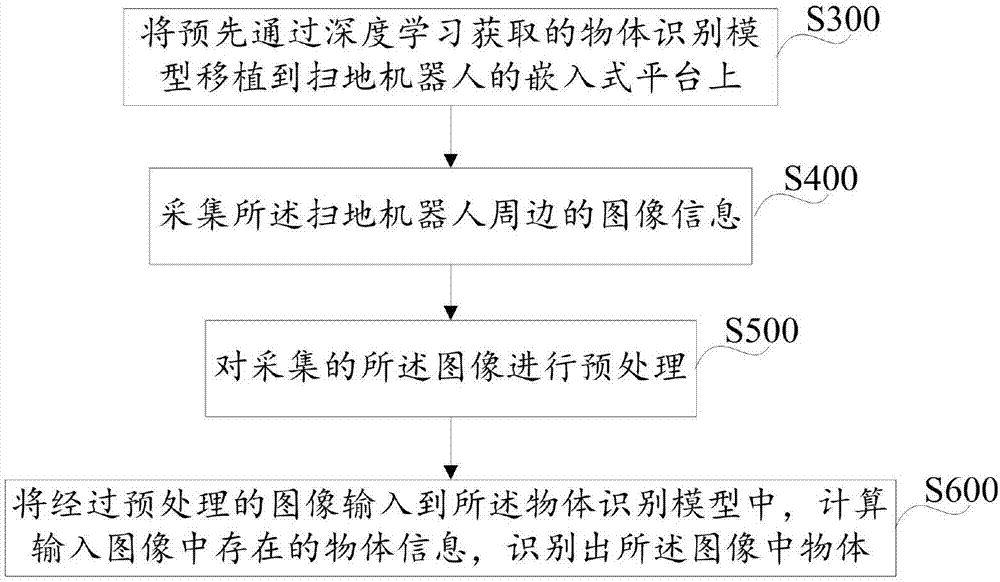
本发明一种扫地机器人的物体识别方法,包括:s300将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;s400采集所述扫地机器人周边的图像信息;s500对采集的所述图像进行预处理;s600将经过预处理的图像输入到所述物体识别模型中,计算输入图像中存在的物体信息,识别出所述图像中物体。
优选地,所述物体识别模型的获取包括:s100确定模型结构及训练参数,生成模型结构文件;s200训练基于深度学习的物体识别模型。
优选地,所述步骤s200包括:s210读取所述模型结构文件,初始化模型参数;s220从训练样本集中随机选取批量大小的训练样本,将每个输入的训练样本划分成大小一致的sxs个网格;s230对于每一个网格,计算出b个检测框信息,及每个检测框对应的置信度及其属于c个类别的概率;s240计算损失函数,获取训练误差;s250根据所述训练误差,采用动量梯度下降法,更新模型参数;s260判断所述训练误差是否低于相应的第一预设阈值,若是,进入步骤s270,否则返回步骤s220;s270将更新后的模型参数保存为模型参数文件。
优选地,所述步骤s240中的训练误差包括:坐标误差、大小误差、类别概率误差,计算公式如下:
loss=errcoord+erriou+errclass;其中:
其中,errcoord,erriou,errclass分别表示坐标误差、大小误差和类别概率误差;xij,yij,wij,hij,cij,pi(cj)分别表示训练样本中第i个网格输出的第j个检测框位置的中心点坐标、宽度、高度、置信度及该网格对应的类别概率值;
优选地,所述步骤s600包括:s610将经过预处理的图像输入到所述物体识别模型中,并将输入图像划分成大小一致的sxs个网格;每个网格负责检测中心落在所述网格中的物体;s620对于每一个网格,计算出b个检测框及其置信度、以及每个检测框属于c个类别的概率;s630计算出每个检测框的类别置信度分数;s640判断所述置信度分数是否低于第二预设阈值,若是,则进入步骤s650,否则进入步骤s660;s650将所述置信度分数低于第二预设阈值的检测框的置信度值设置为0;s660对于所述置信度值不为0的检测框,采用非极大值抑制进行优化,筛选出目标检测框,并根据所述目标检测框输出物体所在的位置、大小和类别概率。
优选地,所述步骤s660包括:s661计算分数最高的检测框与其他检测框重叠的程度,将重叠程度超过第三预设阈值的检测框过滤掉,保留剩余的检测框体作为目标检测框;s662对所述目标检测框逐一确定其类别,输出所述目标检测框对应的物体的位置、大小及其所属类别,作为物体识别结果。
优选地,在所述步骤s660之后还包括:s670根据所述步骤s662的物体识别结果,在所述输入图像中绘制出对应的检测框,并标注物体类别。
另一方面,本发明还公开了一种扫地机器人的物体识别系统,包括:模型移植模块,用于将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;图像采集模块,用于采集所述扫地机器人周边的图像信息;图像预处理模块,用于对采集的所述图像进行预处理;物体识别模块,用于将经过预处理的图像输入到所述物体识别模型中,计算输入图像中存在的物体信息,识别出所述图像中物体。
优选地,所述扫地机器人的物体识别系统,还包括:参数确定模块,用于确定模型结构及训练参数,生成模型结构文件;学习训练模块,用于根据所述参数确定模块生成的模型结构文件,训练基于深度学习的物体识别模型;所述学习训练模块包括:初始化子模块,用于读取所述参数确定模块生成的模型结构文件,初始化模型参数;选取子模块,用于从训练样本集中随机选取批量大小的训练样本,将每个输入的训练样本划分成大小一致的sxs个网格;第一计算子模块,用于对于每一个网格,计算出b个检测框信息,及该检测框对应的置信度,及其属于c个类别的概率;并计算损失函数,获取训练误差;模型更新子模块,用于根据所述训练误差,采用动量梯度下降法,更新模型参数;第一判断子模块,用于判断所述训练误差是否低于相应的第一预设阈值;当判定所述训练误差不低于相应的第一预设阈值时,返回通过选取子模块继续随机选取批量大小的训练样本,继续进行后续的样本训练,直至所述训练误差不低于相应的第一预设阈值为止。存储子模块,用于当判定所述训练误差低于相应的第一预设阈值时,将所述模型更新子模块更新后的模型参数保存为模型参数文件。
优选地,所述物体识别模块包括:图像处理子模块,用于将经过预处理的图像输入到所述物体识别模型中,并将输入图像划分成大小一致的sxs个网格,每个网格负责检测中心落在所述网格中的物体;第二计算子模块,用于对于每一个网格,计算出b个检测框信息、每个检测框对应的置信度及其属于c个类别的概率;并计算出每个检测框的类别置信度分数;第二判断子模块,用于判断所述置信度分数是否低于第二预设阈值;设置子模块,用于当所述第二判断子模块判定所述置信度分数低于第二预设阈值时,将所述置信度分数低于第二预设阈值的检测框的置信度值设置为0;筛选子模块,用于当所述第二判断子模块判定所述置信度分数不低于第二预设阈值时,对于所述置信度值不为0的检测框,采用非极大值抑制进行优化筛选出目标检测框;所述识别输出子模块,用于根据所述筛选子模块筛选出的目标检测框输出物体所在的位置、大小和类别概率。
本发明有益效果如下:
(1)本发明将通过深度学习获取的物体识别模型移植到了扫地机器人的嵌入式平台上,实现了将基于深度学习的物体识别模型运行在计算能力有限的嵌入式平台上。
(2)本发明通过深度学习获取的物体识别模型来识别采集到的扫地机器人周边的图像中的物体信息,通过该方法可以实时获取周围物体的类别信息和位置信息,可以方便扫地机器人实现更加精细的地图构建和导航避障功能等。
(3)相对于扫地机器人通过距离探测器、激光雷达传感器等感知周围环境信息,本发明通过采集扫地机器人周边图像,并利用通过深度学习获取的物体识别模型来识别图像中的物体信息,感知获取的周围环境信息更加丰富,且识别的准确率高。
(4)采用本发明实现扫地机器人对周边环境中物体识别,实时性和准确性高,成本低,相比于现有的扫地机器人,更为智能。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种扫地机器人的物体识别方法实施例的流程图;
图2为本发明一种扫地机器人的物体识别方法另一实施例的流程图;
图3为本发明一种扫地机器人的物体识别方法另一实施例的流程图;
图4为本发明一种扫地机器人的物体识别系统实施例的框图;
图5为本发明一种扫地机器人的物体识别系统另一实施例的框图。
附图标记:
10--模型移植模块;20--图像采集模块;30--图像预处理模块;40--物体识别模块;50--参数确定模块;60--学习训练模块;41--图像处理子模块;42--第二计算子模块;43--第二判断子模块;44--设置子模块;45--筛选子模块;46--识别输出子模块;61--初始化子模块;62--选取子模块;63--第一计算子模块;64--模型更新子模块;65--第一判断子模块;66--存储子模块。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部份实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明公开了一种扫地机器人的物体识别方法,实施例如图1所示,包括:
s300将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;
s400采集所述扫地机器人周边的图像信息;
s500对采集的所述图像进行预处理;
s600将经过预处理的图像输入到所述物体识别模型中,计算输入图像中存在的物体信息,识别出所述图像中物体。
近年来,基于深度学习的物体识别方法在学术界,无论是在准确性还是鲁棒性上都有了质的突破,但如何将其应用到计算能力有限的嵌入式平台上一直工业界的一个难点。本实施例揭示了一种可运行在扫地机器人本体上的基于深度学习的在线物体识别方法,通过该方法可以实时获得周围物体的类别信息和位置信息,在此基础上可以实现更加精细的语义地图构建和导航避障功能等。
本实施例通过在扫地机器人设备上运行基于深度学习的物体识别模型,实时检测出机器人视野范围内的目标物体。具体的,首先将训练好的基于深度学习的物体识别模型移植到视觉扫地机器人所在的嵌入式平台上。通过视觉传感器在线获取扫地机器人周边的图像,经过一系列的预处理,将处理后的图像输入到模型中,由模型计算出图像中目标物体的位置信息和类别概率信息,实现在线物体识别。
本发明方法的另一实施例,如图2所示,包括:
s100确定模型结构及训练参数,生成模型结构文件;
s210读取所述模型结构文件,初始化模型参数;
s220从训练样本集中随机选取批量大小的训练样本,将每个输入的训练样本划分成大小一致的sxs个网格;
s230对于每一个网格,计算出b个检测框信息,及每个检测框对应的置信度及其属于c个类别的概率;
s240计算损失函数,获取训练误差;
s250根据所述训练误差,采用动量梯度下降法,更新模型参数;
s260判断所述训练误差是否低于相应的第一预设阈值,若是,进入步骤s270,否则返回步骤s220;
s270将更新后的模型参数保存为模型参数文件;
s300将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;
s400采集所述扫地机器人周边的图像信息;
s500对采集的所述图像进行预处理;
s600将经过预处理的图像输入到所述物体识别模型中,计算输入图像中存在的物体信息,识别出所述图像中物体。
本实施例在上述实施例的基础上,在移植物体识别模型到扫地机器人的嵌入式平台之前,需要先训练获取该物体识别模型,包括:
(1)确定模型结构及训练参数,生成模型结构文件;
确定模型结构是指确定深度卷积神经网络模型的结构,主要包括输入样本的尺寸、网络的层数、卷积核的尺寸及数量、池化层的尺寸、输出特征的维度等;
确定训练参数,主要包括确定模型的网络学习速率、训练批量大小等。
确定好网络结构训练参数后,据此生成模型结构文件。
比如,使用imagenet1000类数据训练神经网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
生成了模型结构文件后,开始训练基于深度学习的物体识别模型。用步骤1)得到的前20个卷积层网络参数来初始化物体识别模型前20个卷积层的网络参数,然后用voc20类标注数据进行物体识别模型训练。检测通常需要有细密纹理的视觉信息,所以为提高图像精度,在训练检测模型时,可以将输入图像分辨率从224×224resize到448x448。上述实施例中步骤s210-s270即为训练基于深度学习的物体识别模型的训练过程。具体包括:
s210读取模型结构文件,初始化模型参数;
s220开始训练,从样本训练集中随机选取批量大小的训练样本,将每个输入训练样本划分成大小一致的sxs个网格;每个网格负责检测中心落在该栅格中的物体
s230对于每一个网格,计算出b个检测框、每个检测框对应的置信度及其属于c个类别的概率。比如,通过计算预测2个检测框及每个检测框的置信度,及每个检测框分别属于4个类别的概率。这里b个检测框是提前指定的每个网格预测的检测框数量,可以提前进行设置,比如2个或3个等。c个类别,指想让识别模型学习到的物体的类别数量,也就是训练样本中需要学习的物体的类别数量,比如让识别模型学习5个类别:人、桌子、椅子、墙、狗。
每个检测框及该检测框对应的置信度表示为:(x,y,w,h,confidence),其中x,y表示检测框的中心点坐标,w,h分别表示检测框的宽度和高度,confidence表示该检测框对应的置信度,其计算方法如下:
confidence=p(obj)*iou
其中p(obj)表示该检测框中是否包含物体,若包含物体则p(obj)=1,否则为0;iou表示该网格预测的检测框与训练样本中标注的检测框大小的重叠程度;
每个网格预测出其属于c个类别的概率表示为:p(class|obj)。
s240计算损失函数,即通过步骤c计算的输出值与真实值之间的误差。由于识别模型会为每个网格预测b个box(检测框),但我们希望训练时只有一个box为每个物体负责。责任box是和物体的真实box的iou最大的box。
损失函数包括3部分:
坐标误差:表示对物体负责的格子中的责任box和真实box标记之间的误差;
大小误差:表示每个预测box的置信度和真实置信度之间的误差。
类别概率误差:表示为责任格子预测的类别概率分布和真实的概率分布之间的误差。
总的误差(包括坐标误差、大小误差、类别概率误差)的计算方法如下:
loss=errcoord+erriou+errclass;其中:
其中,errcoord,erriou,errclass分别表示坐标误差、大小误差和类别概率误差;xij,yij表示训练样本中第i个网格输出的第j个检测框位置的中心点坐标;wij,hij,cij,pi(cj)分别表示训练样本中第i个网格输出的第j个检测框位置的宽度、高度、置信度及该网格对应的类别概率值;
s250采用动量梯度下降法,更新模型参数;
梯度下降是机器学习中用来使模型逼近真实分布的最小偏差的优化方法。其基本思想就是计算梯度的指数加权平均数,并利用该梯度来更新权重。动量梯度下降法属于现有技术中的一种优化方法,通过该动量梯度下降法不断更新模型的参数,减小与真实值的误差。
s261重复步骤b~e,直至训练误差低于预设的截止阈;比如,设定重复步骤b-e达到预设次数即可训练结束,或者训练调整后的误差达到了最小的预设的一个误差值即可结束训练。
s270最后,训练结束后,将最终训练好的模型参数保存为模型参数文件。
通过上述方式训练好物体识别模型后,再将该模型移植到扫地机器人的嵌入式平台上,即可实现扫地机器人在线识别周边物体,从而便于该扫地机器人后续的地图构建等。
本发明的另一实施例,如图3所示,包括:
s300将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;
s400采集所述扫地机器人周边的图像信息;
s500对采集的所述图像进行预处理;
s610将经过预处理的图像输入到所述物体识别模型中,并将输入图像划分成大小一致的sxs个网格;每个网格负责检测中心落在所述网格中的物体;
s620对于每一个网格,计算出b个检测框及其置信度、以及每个检测框属于c个类别的概率;
s630计算出每个检测框的类别置信度分数;
s640判断所述置信度分数是否低于第二预设阈值,若是,则进入步骤s650,否则,进入步骤s660;
s650将所述置信度分数低于第二预设阈值的检测框的置信度值设置为0;
s660对于所述置信度值不为0的检测框,采用非极大值抑制进行优化,筛选出目标检测框,并根据所述目标检测框输出物体所在的位置、大小和类别概率。
本实施例中重点阐述了利用移植在扫地机器人上物体识别模型来识别图像中的物体的过程。具体的:
(1)将基于深度学习的物体识别模型移植到视觉扫地机器人中的嵌入式平台上。包括:
a.在视觉扫地机器人中的嵌入式平台上搭建模型运行环境;
b.将通过深度学习获取的物体识别模型的模型结构文件和模型参数文件分别保存在flash存储器中;
c.在扫地机器人设备运行时加载上述模型结构文件和模型参数文件。
(2)通过视觉传感器获取具有固定分辨率大小的图像信息。
在采集图像之前,还需要预先设置图像采集的帧率和图像采集模式、分辨率大小等,然后按照预先设置图像采集的帧率实时抽取视频流中的图像信息,并将采集到的图像存储在缓存中。
(3)对所获取的图像进行预处理。
读取缓存中的图像,对目标图像进行预处理,包括:裁剪、降噪、滤波、灰度处理等。
(4)将经过预处理的图像输入到基于深度学习的物体识别模型中。
(5)计算输入图像中存在的物体信息,输出物体所在的位置、大小和类别概率。具体包括:
a.将输入图像划分成大小一致的sxs个网格;
b.对于每一个网格,计算出b个检测框及该检测框对应的置信度及其属于c个类别的概率:(x,y,w,h,confidence,p(class|obj));
c.计算出类别置信度分数score,计算方法如下:
score=confidence*p(class|obj)
对于score低于预先设置阈值的检测框,将其confidence值设置为0;
d.对confidence值不为0的检测框,进行非极大值抑制。方法如下:
首先,计算分数最高的检测框与其他检测框重叠的程度,将重叠程度超过某一阈值的检测框过滤掉,保留剩余的检测框体;
然后,对保留的检测框体逐一确定其类别。最终输出检测框体及其所属类别,作为物体识别结果;
e.可选地,根据上述识别结果在输入图像中绘制出对应的检测框,并标注物体类别。如此,通过在输入图像中绘制出对应的检测框,标注出物体类别后,扫地机器人便可根据该标注的输入图像来构建地图,构建三维空间中各个位置存在的物体信息等,从而快速而准确的完成路径规划和避障等功能。
基于相同的技术构思,本发明还公开了一种扫地机器人的物体识别系统,该系统可采用本发明的方法实现在线物体识别,具体的,本发明的扫地机器人的物体识别系统如图4所示,包括:模型移植模块10,用于将预先通过深度学习获取的物体识别模型移植到扫地机器人的嵌入式平台上;图像采集模块20,用于采集所述扫地机器人周边的图像信息;图像预处理模块30,用于对采集的所述图像进行预处理;物体识别模块40,用于将经过预处理的图像输入到所述物体识别模型中,计算输入图像中存在的物体信息,识别出所述图像中物体。
本发明系统的另一实施例,如图5所示,在上述系统实施例的基础上,移植在扫地机器人的嵌入式平台上的物体识别模型先需要经过学习训练获得。学习训练一般通过在服务器上完成,所述扫地机器人的物体识别系统还包括:参数确定模块50,用于确定模型结构及训练参数,生成模型结构文件;学习训练模块60,用于根据所述参数确定模块50生成的模型结构文件,训练基于深度学习的物体识别模型;具体的,所述学习训练模块60包括:初始化子模块61,用于读取所述参数确定模块50生成的模型结构文件,初始化模型参数;选取子模块62,用于从训练样本集中随机选取批量大小的训练样本,将每个输入的训练样本划分成大小一致的sxs个网格;第一计算子模块63,用于对于每一个网格,计算出b个检测框信息,及该检测框对应的置信度,及其属于c个类别的概率;并计算损失函数,获取训练误差;模型更新子模块64,用于根据所述训练误差,采用动量梯度下降法,更新模型参数;第一判断子模块65,用于判断所述训练误差是否低于相应的第一预设阈值;当判定所述训练误差不低于相应的第一预设阈值时,返回通过选取子模块62继续随机选取批量大小的训练样本,继续进行后续的样本训练,直至所述训练误差不低于相应的第一预设阈值为止。存储子模块66,用于当判定所述训练误差低于相应的第一预设阈值时,将所述模型更新子模块64更新后的模型参数保存为模型参数文件。
本实施例中,参数确定模块50和学习训练模块60一般可以放在服务器上进行参数确定和学习训练,训练好了以后再将训练好的物体识别模型移植到扫地机器人的嵌入式平台上。参数确定模块50确定深度卷积神经网络模型的结构,主要包括输入样本的尺寸、网络的层数、卷积核的尺寸及数量、池化层的尺寸、输出特征的维度等;此外还确定训练参数,主要包括确定模型的网络学习速率、训练批量大小等。确定好网络结构训练参数后,据此生成模型结构文件。开始训练时,先通过初始化子模块61初始化模型参数,然后再通过选取子模块62从样本集里面随机选取训练的样本,然后将训练样本划分成大小一致的sxs个网格,比如将样本图像划分成7x7的网格。然后对每个网格,通过第一计算子模块63预测b个检测框及每个检测框的置信度、以及每个检测框属于c个类别的概率。比如,每个网格,预测2个检测框、及每个检测框的置信度,及每个检测框分别属于4个类别的概率。比如某网格预测2个检测框中第一个检测框属于a物体的概率为30%,属于b物体的概率为60%,属于c物体的概率为3%,属于d物体的概率为7%。这里,每个检测框及该检测框对应的置信度表示为:(x,y,w,h,confidence),其中x,y表示检测框的中心点坐标,w,h分别表示检测框的宽度和高度,confidence表示该检测框对应的置信度,其计算方法如下:
confidence=p(obj)*iou
其中p(obj)表示该检测框中是否包含物体,若包含物体则p(obj)=1,否则为0;iou表示该网格预测的检测框与训练样本中标注的检测框大小的重叠程度;
每个网格预测出其属于c个类别的概率表示为:p(class|obj)。
计算预测完后,再来计算损失函数,看看预测的值与真实值之间的误差是多少,损失函数包括3部分:坐标误差、大小误差、及类别概率误差。总的误差的计算方法如下:
loss=errcoord+erriou+errclass;其中:
其中,errcoord,erriou,errclass分别表示坐标误差、大小误差和类别概率误差;xij,yij表示训练样本中第i个网格输出的第j个检测框位置的中心点坐标;wij,hij,cij,pi(cj)分别表示训练样本中第i个网格输出的第j个检测框位置的宽度、高度、置信度及该网格对应的类别概率值;
较佳的,所述物体识别模块40包括:图像处理子模块41,用于将经过预处理的图像输入到所述物体识别模型中,并将输入图像划分成大小一致的sxs个网格,每个网格负责检测中心落在所述网格中的物体;第二计算子模块42,用于对于每一个网格,计算出b个检测框信息、每个检测框对应的置信度及其属于c个类别的概率;并计算出每个检测框的类别置信度分数;第二判断子模块43,用于判断所述置信度分数是否低于第二预设阈值;设置子模块44,用于当所述第二判断子模块43判定所述置信度分数低于第二预设阈值时,将所述置信度分数低于第二预设阈值的检测框的置信度值设置为0;筛选子模块45,用于当所述第二判断子模块43判定所述置信度分数不低于第二预设阈值时,对于所述置信度值不为0的检测框,采用非极大值抑制进行优化筛选出目标检测框;所述识别输出子模块46,用于根据所述筛选子模块45筛选出的目标检测框输出物体所在的位置、大小和类别概率。
本实施例中,在上述任一实施例的基础上,重点阐述了扫地机器人通过物体识别模型实现物体识别的过程。具体的,在通过图像采集模块20获取到具有固定分辨率大小的图像信息后,再通过预处理模块对该图像进行预处理,预处理包括:裁剪、降噪、滤波、灰度处理等。然后将经过预处理的图像输入到前面通过深度学习及训练获取到的物体识别模型中,通过物体识别模块40计算输入图像中存在的物体信息,输出物体所在的位置、大小和类别概率等信息。具体的通过物体识别模型对输入图像进行识别输出的过程包括:
(1)图像处理子模块41将输入图像划分成大小一致的sxs个网格;
(2)第二计算子模块42对于每一个网格,计算出b个检测框及该检测框对应的置信度及其属于c个类别的概率:(x,y,w,h,confidence,p(class|obj));
(3)第二计算子模块42计算出类别置信度分数score,计算方法如下:
score=confidence*p(class|obj)
设置子模块44对于第二判断子模块43判断出score低于第二预设阈值的检测框,将其confidence值设置为0;
(4)筛选子模块45对confidence值不为0的检测框,进行非极大值抑制。方法如下:a.计算分数最高的检测框与其他检测框重叠的程度,将重叠程度超过某一阈值的检测框过滤掉,保留剩余的检测框体;b.对保留的检测框体逐一确定其类别。最终输出检测框体及其所属类别,作为物体识别结果;
(5)可选地,该物体识别模块40还包括标注模块,该标注模块根据上述识别结果在输入图像中绘制出对应的检测框,并标注物体类别。
本实施例通过在视觉扫地机器人设备上运行基于深度学习的物体识别模型,实时检测出机器人视野范围内的目标物体,并进行标注。首先在gpu服务器上训练基于深度学习的物体识别模型,并可将其移植到视觉扫地机器人所在的嵌入式平台上。通过视觉传感器在线获取视频流中的图像,经过一系列的预处理,将处理后的图像输入到模型中,由模型计算出图像中目标物体的位置信息和类别概率信息,并进行标注,实现在线物体识别。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!