具有视觉语义感知的机器人虚实交互操作执行系统及方法与流程
本发明涉及机器人虚实交互操作执行技术领域,特别涉及一种具有视觉语义感知的机器人虚实交互操作执行系统及方法。
背景技术:
相关技术中,对于机器人操作智能的实现主要有两种手段:
(1)在虚拟环境下控制仿真机器人,采集虚拟信号,观测状态信息,实现ai算法构建、参数优化、运动学/动力学仿真。
但往往在虚拟环境下进行机器人操作仿真训练,仿真情况下的模拟很难全面的反应真实系统的运行状况,造成结果往往不够精确。
(2)在真实环境下控制实际机器人,采集实际信号,观测状态信息,构建ai学习决策和视觉识别系统。
在真实环境下进行机器人操作训练,存在的问题是工作灵活性差、成本高、硬件装置易损坏、执行频次低。
因此,提出了具有视觉语义感知的机器人虚实交互操作执行系统,来加速智能机器人决策和控制系统研究,解决机器人虚实交互和视觉语义感知的问题是十分必要的。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的一个目的在于提出一种具有视觉语义感知的机器人虚实交互操作执行系统。
本发明的另一个目的在于提出一种具有视觉语义感知的机器人虚实交互操作执行方法。
为达到上述目的,本发明一方面提出了具有视觉语义感知的机器人虚实交互操作执行系统,包括:构建组件,用于构建真实环境或仿真环境确定相应的神经网络参数模型;视觉语义感知组件,用于根据所述神经网络参数模型确定待抓取物体的感兴趣区域,以计算抓取所述感兴趣区域的目标点位信息;规划组件,用于根据所述目标点位信息对所述待抓取物体进行避障和轨迹规划,确定抓取执行操作命令;执行组件,用于根据所述抓取执行操作命令控制真实机械臂或仿真机械臂的动作,完成抓取操作命令。
本发明实施例的具有视觉语义感知的机器人虚实交互操作执行系统,构建了虚实交互的场景,快速、高效、精确的训练ai学习决策系统和视觉语义识别系统,能够用于机器人系统的快速原型开发,算法测试,精确的室内室外环境仿真,有效可靠的性能评估,以及直观可视化的交互显示。
另外,根据本发明上述实施例的具有视觉语义感知的机器人虚实交互操作执行系统还可以具有以下附加的技术特征:
可选地,在本发明的一个实施例中,若选择仿真操作,则所述构建组件通过对环境、视觉相机和机械臂进行仿真,以构建所述仿真环境。
进一步地,在本发明的一个实施例中,所述视觉语义感知组件包括:标注工具,用于对所述待操作物体标注物体类别,为神经网络训练提供训练集;视觉神经网络构架,用于训练所述训练集,获得所述感兴趣区域,并用矩形框得到所述待感兴趣区域所在的区域;双目相机,若在所述仿真环境下,则用于读取相机基坐标系在三维空间中的位姿,并利用自带的算例读取深度信息,若在所述真实环境下,则用于标定内外参数,并利用自带的算例读取深度信息;图像处理工具,用于通过所述矩形框获得所述待操作对象中心点的像素和相对x轴的夹角,再通过双目视觉的基本算法计算出所述机基坐标系下所述待操作对象的位置;处理组件,用于通过所述待操作对象中心点的像素计算出所述矩形框的大小,从而计算出夹爪需要开合的大小。
进一步地,在本发明的一个实施例中,所述目标点位信息包括:通过所述图像处理工具计算出的抓取位姿和通过所述待操作对象中心点的像素确定的夹爪开合大小。
进一步地,在本发明的一个实施例中,所述执行组件包括:关节轨迹控制器,用于根据所述避障和轨迹规划输出连续关节轨迹的位置、速度和力矩;驱动器,用于根据所述关节轨迹控制器输出的数据控制所述真实机械臂或仿真机械臂的动作,执行抓取任务。
为达到上述目的,本发明另一方面提出了一种具有视觉语义感知的机器人虚实交互操作执行方法,包括以下步骤:步骤s1,构建真实环境或仿真环境确定相应的神经网络参数模型;步骤s2,根据所述神经网络参数模型确定待抓取物体的感兴趣区域,以计算抓取所述感兴趣区域的目标点位信息;步骤s3,根据所述目标点位信息对所述待抓取物体进行避障和轨迹规划,确定抓取执行操作命令;步骤s4,根据所述抓取执行操作命令控制真实机械臂或仿真机械臂的动作,完成抓取操作命令。
本发明实施例的具有视觉语义感知的机器人虚实交互操作执行方法,构建了虚实交互的场景,快速、高效、精确的训练ai学习决策系统和视觉语义识别系统,能够用于机器人系统的快速原型开发,算法测试,精确的室内室外环境仿真,有效可靠的性能评估,以及直观可视化的交互显示。
另外,根据本发明上述实施例的具有视觉语义感知的机器人虚实交互操作执行方法还可以具有以下附加的技术特征:
可选地,在本发明的一个实施例中,若选择仿真操作,所述步骤s1则通过对环境、视觉相机和机械臂进行仿真,以构建所述仿真环境。
进一步地,在本发明的一个实施例中,所述步骤s2进一步包括:步骤s201,对所述待操作物体标注物体类别,为神经网络训练提供训练集;步骤s202,利用视觉神经网络框架训练所述训练集,获得所述感兴趣区域,并用矩形框得到所述待感兴趣区域所在的区域;步骤s203,若在所述仿真环境下,则用于读取相机基坐标系在三维空间中的位姿,并利用自带的算例读取深度信息,若在所述真实环境下,则用于标定内外参数,并利用自带的算例读取深度信息;步骤s204,通过所述矩形框获得所述待操作对象中心点的像素和相对x轴的夹角,再通过双目视觉的基本算法计算出所述机基坐标系下所述待操作对象的位置;步骤s205,通过所述待操作对象中心点的像素计算出所述矩形框的大小,从而计算出夹爪需要开合的大小。
进一步地,在本发明的一个实施例中,所述目标点位信息包括:通过所述图像处理工具计算出的抓取位姿和通过所述待操作对象中心点的像素确定的夹爪开合大小。
进一步地,在本发明的一个实施例中,所述步骤s4进一步包括:步骤s401,根据所述避障和轨迹规划输出连续关节轨迹的位置、速度和力矩;步骤s402,根据所述关节轨迹控制器输出的数据控制所述真实机械臂或机械臂的动作,执行抓取任务。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的具有视觉语义感知的机器人虚实交互操作执行系统结构示意图;
图2为根据本发明实施例中视觉语义感知组件执行流程图;
图3为根据本发明实施例的虚实交互系统执行流程图;
图4为根据本发明实施例的具有视觉语义感知的机器人虚实交互操作执行方法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图描述根据本发明实施例提出的具有视觉语义感知的机器人虚实交互操作执行系统及方法,首先将参照附图描述根据本发明实施例提出的具有视觉语义感知的机器人虚实交互操作执行系统。
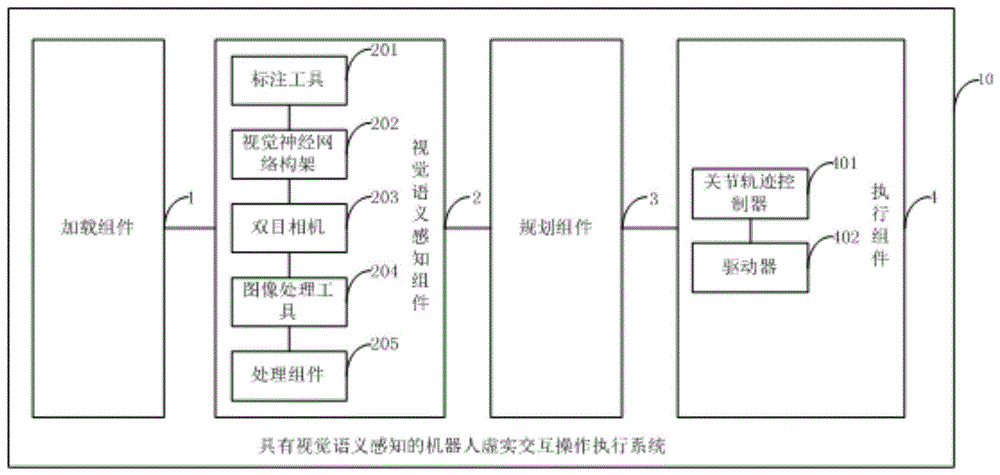
图1是本发明一个实施例的具有视觉语义感知的机器人虚实交互操作执行系统结构示意图。
如图1所示,该具有视觉语义感知的机器人虚实交互操作执行系统10包括:构建组件1、视觉语义感知组件2、规划组件3和执行组件4。
其中,构建组件1用于构建真实环境或仿真环境确定相应的神经网络参数模型。
进一步地,在本发明的一个实施例中,若选择仿真操作,则构建组件通过对环境、视觉相机和机械臂进行仿真,以构建仿真环境。
具体地,如果选择仿真,需要加载仿真物理模型(通过gazebo插件),包括仿真环境、传感器(视觉相机)、模型(机械臂),也可以通过其它仿真物理软件(如v-rep)构建仿真环境,其中仿真模型可以通过solidworks等三维软件生成urdf文件模型。
视觉语义感知组件2用于根据神经网络参数模型确定待抓取物体的感兴趣区域,以计算抓取感兴趣区域的目标点位信息。
进一步地,本发明实施例的视觉语义感知组件2包括:标注工具201用于对待操作物体标注物体类别,为神经网络训练提供训练集。视觉神经网络构架202用于训练训练集,获得感兴趣区域,并用矩形框得到待感兴趣区域所在的区域。双目相机203若在仿真环境下,则用于读取相机基坐标系在三维空间中的位姿,并利用自带的算例读取深度信息,若在真实环境下,则用于标定内外参数,并利用自带的算例读取深度信息。图像处理工具204用于通过矩形框获得待操作对象中心点的像素和相对x轴的夹角,再通过双目视觉的基本算法计算出机基坐标系下待操作对象的位置。处理组件205用于通过待操作对象中心点的像素计算出矩形框的大小,从而计算出夹爪需要开合的大小。
具体而言,如图2所示,本发明实施例的视觉语义感知组件2是在仿真和真实环境下构建基于深度学习的视觉语义感知系统,其具体执行过程为:
(1)开始操作,系统初始化;
(2)选择仿真物理环境或者真实的物理环境;
(3)收集不同环境下(包括离散、堆叠、光线变化、不同放置位置)的物体图片;
(4)采用标注工具(如lableme、vggimageannotator、cocoui)进行标注物体类别,为神经网络训练提供训练集;
(5)利用视觉神经网络构架(mask-rcnn,yolov3,ssd等),训练数据集。获得感兴趣的区域,用矩形框或者mask得到期望物体所在的区域;
(6)标定双目相机,在仿真环境下,可以直接读取到相机基坐标系在三维空间中的位姿。在真实环境下,用棋盘格(如kinect的标定)或用自带的软件(realsensed435)标定内外参数。采用自带的算例读出深度信息;
(7)采用opencv处理感兴趣的区域,如通过最小矩形框,获得物体中心点的像素和相对x轴的夹角,接着通过双目视觉的基本算法计算出在相机坐标系下物体的位置,再通过坐标变换转换到基坐标系下;
(8)通过像素点计算出矩形框的大小,从而计算出夹爪需要开合的大小;
(9)将视觉感知处理得到的结果,通过消息的方式将目标点位信息传递给抓取执行操作的节点。
规划组件3用于根据目标点位信息对待抓取物体进行避障和轨迹规划,确定抓取执行操作命令。
可以理解的是,目标点位信息包括:通过图像处理工具计算出的抓取位姿和通过待操作对象中心点的像素确定的夹爪开合大小。
执行组件4用于根据抓取执行操作命令控制真实机械臂或仿真机械臂的动作,完成抓取操作命令。
进一步地,在本发明的一个实施例中,执行组件4包括:关节轨迹控制器401用于根据避障和轨迹规划输出连续关节轨迹的位置、速度和力矩。驱动器402用于根据关节轨迹控制器输出的数据控制真实机械臂或仿真机械臂的动作,执行抓取任务。
综上,如图3所示,本发明实施例的执行系统的具体实施过程为:
(1)开始操作,系统初始化;
(2)选择仿真或者实物操作;
(3)如果选择仿真,需要加载仿真物理模型(通过gazebo插件),包括仿真环境、传感器(视觉相机)、模型(机械臂),也可以通过其它仿真物理软件(如v-rep)构建仿真环境,其中仿真模型可以通过solidworks等三维软件生成urdf文件模型;
(4)构建好环境后,执行设定好的任务,可以通过编写c++/python节点文件实现;
(5)加载视觉神经网络,依据仿真或实物的选择,确定相应的神经网络参数模型;
(6)通过神经网络给出的结果,判断是否有待操作的任务或者待抓取的对象,如果结果为无,回到执行任务,如果有待抓取物体或操作物体,执行下一步操作任务;
(7)识别到有待操作对象后,通过opencv等图像处理工具计算抓取的位姿,以及通过像素点去确定操作器开合的大小;
(8)将目标点位信息通过消息的方式传递给包含moveit!的节点,在moveit!中进行避障和轨迹规划,通过jointtrajectorycontroller(如effort_controllers/jointtrajectorycontroller)输出连续关节轨迹的位置、速度、力矩;
(9)将信号传输到关节轨迹控制器(通过controller_manager插件实现),通过硬件接口层发送命令给驱动器;
(10)控制仿真机械臂或真实机械臂的动作到相应位置,执行操作任务,一次抓取操作任务完成。
(11)判断总体任务是否完成,如果没有则会跳转到执行任务,继续任务,如果判断完成,则回到设定的初始位置,结束任务。
也就是说,本发明实施例构建了一种基于ros-gazebo-moveit!的机器人虚实交互平台,用于快速原型的开发,以及训练ai模型,其中,基于ros(robotoperatingsystem)系统构架搭建机械臂的软件构架,基于gazebo物理仿真引擎实现仿真环境、仿真机械臂和仿真视觉,基于moveit!实现机器人碰撞检测、避障和路径规划,基于controller_manager插件实现机器人关节空间的规划和仿真机械臂或真实机械臂的接连。
根据本发明实施例提出的具有视觉语义感知的机器人虚实交互操作执行系统,建立了机器人虚实交互平台,可用于快速原型开发、算法测试、精确的室内室外环境仿真、有效可靠的性能评估、直观可视化的交互显示以及训练ai决策和控制系统,还构建了基于深度学习的视觉语义感知系统,识别和感知物体的类别、尺寸、位置,能够稳定、灵巧、快速的实现物体抓取、操作和执行等任务。
其次参照附图描述根据本发明实施例提出的具有视觉语义感知的机器人虚实交互操作执行方法。
图4是本发明一个实施例的具有视觉语义感知的机器人虚实交互操作执行方法流程图。
如图4所示,该具有视觉语义感知的机器人虚实交互操作执行方法包括以下步骤:
在步骤s1中,构建真实环境或仿真环境确定相应的神经网络参数模型。
其中,若选择仿真操作,步骤s1则通过对环境、视觉相机和机械臂进行仿真,以构建仿真环境。
在步骤s2中,根据神经网络参数模型确定待抓取物体的感兴趣区域,以计算抓取感兴趣区域的目标点位信息。
进一步地,在本发明的一个实施例中,步骤s2进一步包括:步骤s201,对待操作物体标注物体类别,为神经网络训练提供训练集;步骤s202,利用视觉神经网络框架训练训练集,获得感兴趣区域,并用矩形框得到待感兴趣区域所在的区域;步骤s203,若在仿真环境下,则用于读取相机基坐标系在三维空间中的位姿,并利用自带的算例读取深度信息,若在真实环境下,则用于标定内外参数,并利用自带的算例读取深度信息;步骤s204,通过矩形框获得待操作对象中心点的像素和相对x轴的夹角,再通过双目视觉的基本算法计算出机基坐标系下待操作对象的位置;步骤s205,通过待操作对象中心点的像素计算出矩形框的大小,从而计算出夹爪需要开合的大小。
在步骤s3中,根据目标点位信息对待抓取物体进行避障和轨迹规划,确定抓取执行操作命令。
其中,在本发明实施例中的目标点位信息包括:通过图像处理工具计算出的抓取位姿和通过待操作对象中心点的像素确定的夹爪开合大小。
在步骤s4中,根据抓取执行操作命令控制真实机械臂或仿真机械臂的动作,完成抓取操作命令。
具体而言,步骤s4进一步包括:步骤s401,根据避障和轨迹规划输出连续关节轨迹的位置、速度和力矩;步骤s402,根据关节轨迹控制器输出的数据控制真实机械臂或仿真机械臂的动作,执行抓取任务。
需要说明的是,前述对具有视觉语义感知的机器人虚实交互操作执行系统实施例的解释说明也适用于该方法,此处不再赘述。
根据本发明实施例提出的具有视觉语义感知的机器人虚实交互操作执行方法,建立了机器人虚实交互平台,可用于快速原型开发、算法测试、精确的室内室外环境仿真、有效可靠的性能评估、直观可视化的交互显示以及训练ai决策和控制系统,还构建了基于深度学习的视觉语义感知系统,识别和感知物体的类别、尺寸、位置,能够稳定、灵巧、快速的实现物体抓取、操作和执行等任务。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本发明中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!