一种基于深度学习的双臂机器人仿人作业规划方法与流程
本发明涉及一种机器人的机械臂作业规划方法,具体涉及一种基于深度学习的双臂机器人仿人作业规划方法,属于机器人技术领域。
背景技术:
在武警公安反恐防暴、战场作战、有害气体及核辐射等危险复杂的作业环境中,路径规划主要考虑的是机器人如何能从初始状态无碰撞地运动到目标状态的问题,路径规划的技术水平是衡量机器人智能化程度的重要指标。由于人类具有强大的学习能力,通过不断的运动学习与不同环境的适应训练积累大量的运动动作样本。在执行与之前相似的运动任务时,依据动作样本,根据实际环境稍加改变便可以快速有效地完成所需的运动动作。
现有的路径规划方法主要有基于图的路径规划算法例如a*算法、可视图法、人工势场算法,以及基于随机采样的概率路图算法(prm)和快速扩展随机树算法(rrt)等。
由于机械臂相对于移动机器人来说维度较高,传统的路径规划算法存在计算量太大,障碍物难以描述,算法不完备,不最优等问题,基于采样的规划算法满足概率完备,但由于采样引入了一定的随机性,每次规划结果都可能不相同,存在规划结果无法预判的问题。
基于这一问题,本领域需要一种利用人类运动动作样本作为指导,另一方面结合当前机器人所处的具体环境对人类运动动作样本进行选择或改变,从而实现双臂机器人进行仿人作业规划的方法。
技术实现要素:
本发明的目的在于提供一种既能将人类运动动作作为机器人运动规划的指导,同时也能考虑机器人当前所处的具体环境的运动规划方法。
本发明的技术方案如下。
本发明第一方面提供了一种基于深度学习的双臂机器人仿人作业规划方法,包括如下步骤:
步骤s1,训练策略网络;所述策略网络能够根据机械臂当前状态和目标状态计算下一时刻机械臂处于各状态的概率,给出多种运动方案
步骤s2,确定评价函数;所述评价函数用于对所述策略网络提供的运动方案进行评估;
步骤s3,结合所述策略网络和所述评价函数执行树搜索,得到机械臂路径规划的结果。
优选地,所述策略网络采用人类运动动作样本。
优选地,所述人类运动动作样本通过运动捕捉设备获取。
优选地,所述评价函数用于评估从机械臂从当前状态运动到下一时刻各状态的代价。
优选地,所述评价函数还用于评估运动过程中机械臂是否与自身和周围环境发生碰撞。
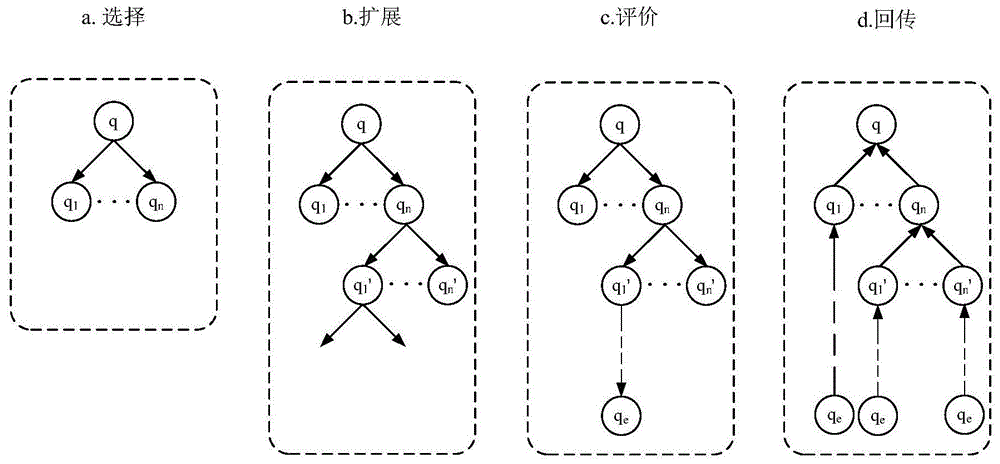
优选地,所述树搜索将机械臂的每个运动状态视作树的一个节点;通过所述策略网络对机械臂的运动进行多步扩展得到树的多个节点,根据所述评价函数对扩展的叶节点进行评估,并从叶节点回传更新各根节点的值,最终根据各节点的值选取最优节点作为机械臂路径规划的结果。
优选地,所述步骤s3进一步包括:
步骤s31,选择步骤;根据策略网络得到的人类可能的运动动作,选择其中概率较大的动作q;
步骤s32,扩展步骤;在动作q之后,继续利用策略网络选择概率较大的子节点对树进行扩展,得到多个子树,扩展一定步数之后停止;
步骤s33,评价步骤;从扩展完成的树的叶节点开始利用评价函数对每一个节点进行评估;
步骤s34,回传步骤;从叶节点开始向树的根节点回传评价函数的结果,每个叶节点的评价值都随回传的子节点的评价值而更新;所有的回传完成之后得到最初选择的节点q的最终评价值,从而选择具有最高评价值的节点作为机械臂的下一步运动。
本发明第二方面提供了一种双臂机器人仿人作业规划系统,包括:
策略网络训练装置;所述策略网络能够根据机械臂当前状态和目标状态计算下一时刻机械臂处于各状态的概率,给出多种运动方案
评价函数确定装置;所述评价函数用于对所述策略网络提供的运动方案进行评估
树搜索装置;所述树搜索装置能够结合所述策略网络和所述评价函数执行树搜索,得到机械臂路径规划的结果。
优选地,所述策略网络采用人类运动动作样本;所述评价函数用于对所述策略网络提供的运动方案进行评估;所述树搜索将机械臂的每个运动状态视作树的一个节点;通过所述策略网络对机械臂的运动进行多步扩展得到树的多个节点,根据所述评价函数对扩展的叶节点进行评估,并从叶节点回传更新各根节点的值,最终根据各节点的值选取最优节点作为机械臂路径规划的结果。
本发明第三方面提供了一种双臂机器人,包括两个基本对称的机械臂,其特征在于,所述双臂机器人按照根据本发明第一方面中任一项所述的基于深度学习的双臂机器人仿人作业规划方法对所述两个基本对称的机械臂的作业进行路径规划。
通过以上技术方案,本发明能够取得如下的技术效果。
(1)本发明将基于深度学习的策略网络,基于运动环境的评价函数和树搜索结合,形成一种新的机器人运动规划方法。
(2)在训练策略网络时,将人类运动动作作为样本,借鉴人类运动的特点,实现双臂机器人的作业规划的仿人特性。
附图说明
图1是本发明的基于深度学习的双臂机器人仿人作业规划方法的示意图。
具体实施方式
实施例1
如附图1本发明实施例1提供了一种基于深度学习的双臂机器人仿人作业规划方法,包括如下步骤:
步骤s1,训练策略网络;所述策略网络能够根据机械臂当前状态和目标状态计算下一时刻机械臂处于各状态的概率,给出多种运动方案
步骤s2,确定评价函数;所述评价函数用于对所述策略网络提供的运动方案进行评估;
步骤s3,结合所述策略网络和所述评价函数执行树搜索,得到机械臂路径规划的结果。
在一优选的实施方式中,所述策略网络采用人类运动动作样本。
在一优选的实施方式中,所述人类运动动作样本通过运动捕捉设备获取。
在一优选的实施方式中,所述评价函数用于评估从机械臂从当前状态运动到下一时刻各状态的代价。
在一优选的实施方式中,所述评价函数还用于评估运动过程中机械臂是否与自身和周围环境发生碰撞。
在一优选的实施方式中,所述树搜索将机械臂的每个运动状态视作树的一个节点;通过所述策略网络对机械臂的运动进行多步扩展得到树的多个节点,根据所述评价函数对扩展的叶节点进行评估,并从叶节点回传更新各根节点的值,最终根据各节点的值选取最优节点作为机械臂路径规划的结果。
在一优选的实施方式中,所述步骤s3进一步包括:
步骤s31,选择步骤;根据策略网络得到的人类可能的运动动作,选择其中概率较大的动作q;
步骤s32,扩展步骤;在动作q之后,继续利用策略网络选择概率较大的子节点对树进行扩展,得到多个子树,扩展一定步数之后停止;
步骤s33,评价步骤;从扩展完成的树的叶节点开始利用评价函数对每一个节点进行评估;
步骤s34,回传步骤;从叶节点开始向树的根节点回传评价函数的结果,每个叶节点的评价值都随回传的子节点的评价值而更新;所有的回传完成之后得到最初选择的节点q的最终评价值,从而选择具有最高评价值的节点作为机械臂的下一步运动。
实施例2
本发明实施例2提供了一种双臂机器人仿人作业规划系统,包括:
策略网络训练装置;所述策略网络能够根据机械臂当前状态和目标状态计算下一时刻机械臂处于各状态的概率,给出多种运动方案
评价函数确定装置;所述评价函数用于对所述策略网络提供的运动方案进行评估
树搜索装置;所述树搜索装置能够结合所述策略网络和所述评价函数执行树搜索,得到机械臂路径规划的结果。
在一优选的实施方式中,所述策略网络采用人类运动动作样本;所述评价函数用于对所述策略网络提供的运动方案进行评估;所述树搜索将机械臂的每个运动状态视作树的一个节点;通过所述策略网络对机械臂的运动进行多步扩展得到树的多个节点,根据所述评价函数对扩展的叶节点进行评估,并从叶节点回传更新各根节点的值,最终根据各节点的值选取最优节点作为机械臂路径规划的结果。
实施例3
本发明实施例3提供了一种双臂机器人,包括两个基本对称的机械臂,其中,所述双臂机器人按照根据本发明实施例1中任一实施方式所述的基于深度学习的双臂机器人仿人作业规划方法对所述两个基本对称的机械臂的作业进行路径规划。
- 还没有人留言评论。精彩留言会获得点赞!