轨道生成装置、轨道生成方法以及轨道生成程序与流程
本公开涉及轨道生成装置、轨道生成方法以及轨道生成程序。
背景技术:
1、具有物理性柔软的柔软部的软体机器人与不具有柔软部的硬体机器人相比,可以进行安全的接触,期待应用于组装动作。
2、另一方面,由于柔软度导致的动态的复杂度,从而难以手动设计控制器。
3、对于控制器的设计,学习(例如强化学习)的途径(approach)是有效的,但是,也难以进行控制目的(报酬函数)的设计。这是因为,与硬体机器人相比,难以准确地追随目标状态(位置)等。
4、例如,在机器人将插栓(peg)插入孔中的插入任务中,在将插入位置的误差作为报酬函数的情况下,有时会在插栓未到达孔之上的状态下进行插入、或者在使插栓与孔匹配时势头过度而出现过冲。
5、非专利文献1中公开了将插栓的插入任务划分为多个子任务而通过手动来设计各划分的控制规则的方法。
6、此外,非专利文献2中公开了在机器人的运动学习中使用基于模型的强化学习(guided policy search:指引性策略搜索)的方法。在该方法中,以远离机器人在学习过程中经验过的失败轨道的方式来更新策略。
7、此外,非专利文献3中公开了利用逆强化学习从示教者的成功轨道及失败轨道学习报酬及策略的方法。在该方法中,在更新策略及报酬时,赋予使远离失败轨道这样的约束。
8、非专利文献1:nishimura et al.,"peg-in-hole under state uncertaintiesvia a passive wrist joint with push-activate-rotation function,"2017ieee-ras17th international conference on humanoid robotics(humanoids),pp 67-74,2020.
9、非专利文献2:esteban et al,"learning deep robot controllers byexploiting successful and failed executions,"2018ieee-ras 18th internationalconference on humanoid robots(humanoids),pp 1-9,2018.
10、非专利文献3:shiarlis et al.,"inverse reinforcement learning fromfailure,"international conference on autonomous agents&multiagent systems,pp1060-1068,2016.
技术实现思路
1、发明要解决的技术问题
2、在非专利文献1所公开的方法中存在如下所述的问题:即、只有充分掌握与任务相关的知识的设计者才能划分为多个子任务。
3、此外,在非专利文献2所公开的方法中存在如下所述的问题:即、在学习过程中才首次知道任务的失败,因此,存在由于某种失败而性能大幅变化的可能性。
4、此外,在非专利文献3所公开的方法中存在如下所述的问题:即、为了确认更新后的策略及报酬的正确性,必须反复获取赋予了策略及报酬时的代理的行为的数据。此外,该方法是离散状态空间表达,存在仅在模拟上处理而未必能够应用于实机的问题。
5、本公开是鉴于上述点所作出的发明,其目的在于提供能够生成用于以更高成功率完成任务的目标轨道信息的轨道生成装置、轨道生成方法以及轨道生成程序。
6、用于解决技术问题的技术方案
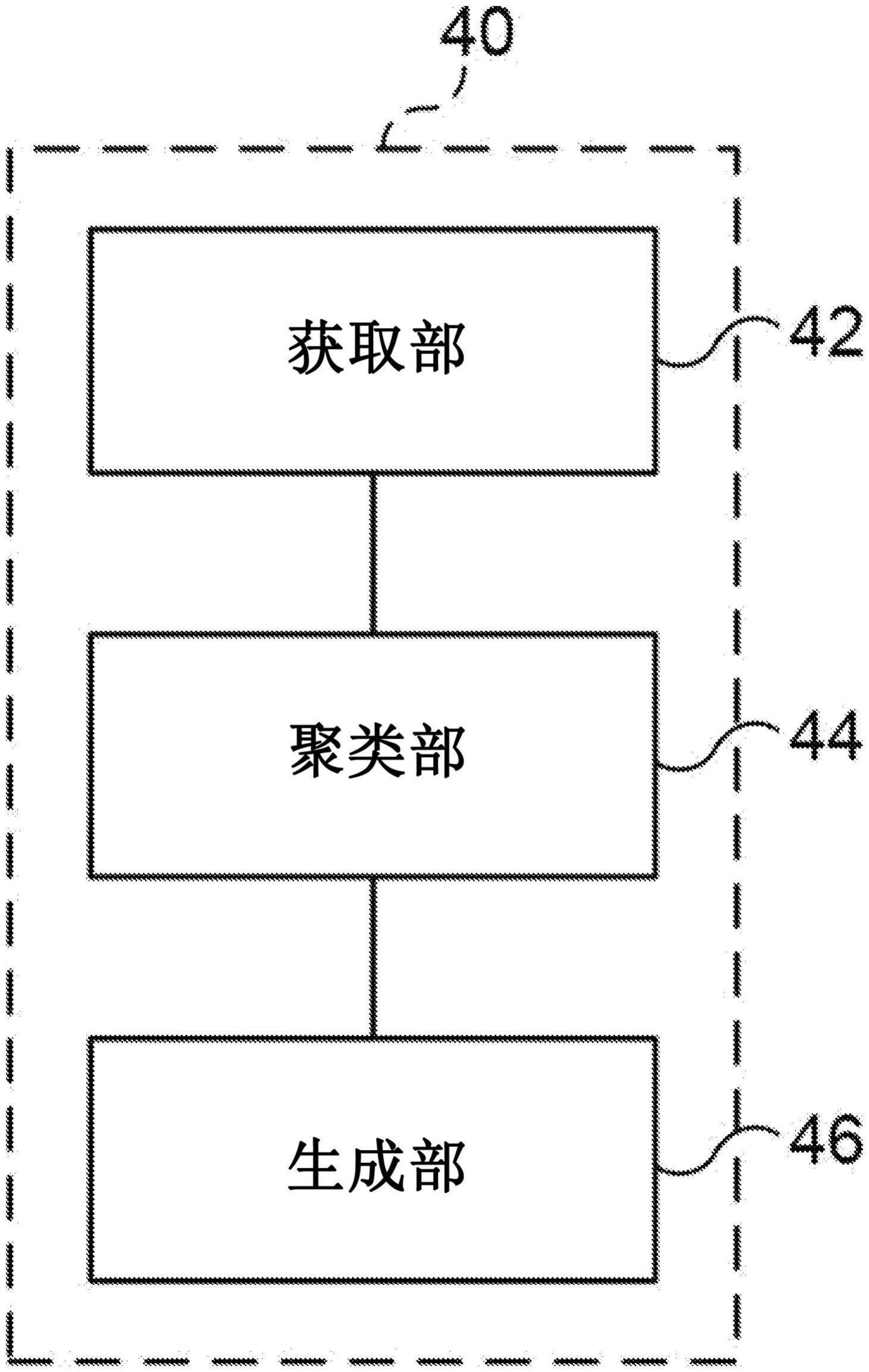
7、公开的第一方面涉及一种轨道生成装置,具备:获取部,获取成功轨道信息和失败轨道信息,所述成功轨道信息和所述失败轨道信息是表示由示教者示教的控制对象的一系列状态的轨道信息,所述成功轨道信息是所述控制对象进行的任务成功时的轨道信息,所述失败轨道信息是所述任务失败时的轨道信息;聚类部,根据属于所述成功轨道信息的所述控制对象的状态以及属于所述失败轨道信息的所述控制对象的状态,生成关于所述控制对象的状态的成功类的簇;以及生成部,基于所述成功类的簇,生成在使所述控制对象执行所述任务时能够作为控制目标使用的表示所述控制对象的一系列状态的目标轨道信息。
8、在上述第一方面中,也可以是,所述聚类部应用采用混合高斯模型的聚类方法,并且,计算出属于所述成功轨道信息及所述失败轨道信息的所述控制对象的状态彼此的相似度,基于计算出的相似度,生成所述成功类的簇。
9、在上述第一方面中,也可以是,所述控制对象的状态是所述控制对象的位置或所述控制对象的位置及姿势,所述聚类部根据属于所述成功轨道信息及所述失败轨道信息的所述控制对象的各状态所包括的位置或位置及姿势计算出所述各状态下的所述控制对象的速度,并根据所述各状态下的位置或位置及姿势以及所述各状态下的速度计算出所述相似度。
10、在上述第一方面中,也可以是,所述聚类部通过对所述控制对象的状态彼此的相似度进行调整的调整参数来调整所述相似度。
11、在上述第一方面中,也可以是,所述聚类部设定所述调整参数,以使属于所述成功轨道信息的所述控制对象的状态彼此之间的相似度变大,而属于所述成功轨道信息的所述控制对象的状态与属于所述失败轨道信息的所述控制对象的状态之间的相似度变小。
12、在上述第一方面中,也可以是,所述生成部对所述成功类的簇应用混合高斯回归法来生成所述目标轨道信息。
13、在上述第一方面中,也可以是,所述获取部还进行用于指引应示教的轨道的显示。
14、公开的第二方面涉及一种轨道生成方法,其中,计算机获取成功轨道信息和失败轨道信息,所述成功轨道信息和所述失败轨道信息是表示由示教者示教的控制对象的一系列状态的轨道信息,所述成功轨道信息是所述控制对象进行的任务成功时的轨道信息,所述失败轨道信息是所述任务失败时的轨道信息;所述计算机根据属于所述成功轨道信息的所述控制对象的状态以及属于所述失败轨道信息的所述控制对象的状态,生成关于所述控制对象的状态的成功类的簇;所述计算机基于所述成功类的簇,生成在使所述控制对象执行所述任务时能够作为控制目标使用的表示所述控制对象的一系列状态的目标轨道信息。
15、公开的第三方面涉及一种轨道生成程序,所述轨道生成程序使计算机执行以下处理:获取控制对象的动作成功时的成功轨道相关的成功轨道信息和所述控制对象的动作失败时的失败轨道相关的失败轨道信息;基于所述成功轨道信息和所述失败轨道信息,将所述成功轨道中的所述控制对象的各位置以及所述失败轨道中的所述控制对象的各位置用预先确定的聚类方法聚类到成功类和失败类;以及基于被聚类到所述成功类的所述控制对象的位置,生成所述控制对象的目标轨道相关的目标轨道信息。
16、发明效果
17、根据本公开,能够生成用于以更高成功率完成任务的目标轨道信息。
技术特征:
1.一种轨道生成装置,具备:
2.根据权利要求1所述的轨道生成装置,其中,
3.根据权利要求2所述的轨道生成装置,其中,
4.根据权利要求2或3所述的轨道生成装置,其中,
5.根据权利要求4所述的轨道生成装置,其中,
6.根据权利要求2至5中任一项所述的轨道生成装置,其中,
7.根据权利要求1至6中任一项所述的轨道生成装置,其中,
8.一种轨道生成方法,在所述轨道生成方法中,计算机执行以下处理:
9.一种轨道生成程序,使计算机执行以下处理:
技术总结
一种轨道生成装置,具备:获取部,获取成功轨道信息和失败轨道信息,成功轨道信息和失败轨道信息是表示由示教者示教的控制对象的一系列状态的轨道信息,成功轨道信息是控制对象进行的任务成功时的轨道信息,失败轨道信息是任务失败时的轨道信息;聚类部,根据属于成功轨道信息的控制对象的状态以及属于失败轨道信息的控制对象的状态,生成关于控制对象的状态的成功类的簇;以及生成部,基于成功类的簇,生成在使控制对象执行任务时能够作为控制目标使用的表示控制对象的一系列状态的目标轨道信息。
技术研发人员:滨屋政志,松原崇充
受保护的技术使用者:欧姆龙株式会社
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!