一种基于深度强化学习的多智能机器人通信控制仪器
本发明涉及深度学习领域和强化学习领域,特别地,涉及一种基于深度强化学习的多智能机器人通信控制技术,是多智能机器人的新控制仪器。
背景技术:
1、人工智能技术和机器学习算法的发展,在自动控制领域发挥了关键的作用,其中强化学习是机器学习的重要分支,它描述和解决智能体在与环境的交互过程中以最大化奖励为目标来不断更新自身策略的问题。近年来,随着科技的发展,计算能力与存储能力得到极大提高,并且深度学习在诸多领域中了取得极大的成就。深度学习和强化学习的结合就在此背景下应运而生,产生了深度强化学习。多智能体系统是在同一个环境中由多个交互智能体组成的系统,多用于解决复杂环境中由有大规模控制对象的问题。深度强化学习的发展促进了多智能体领域的发展,将深度强化学习算法和多智能体系统结合在一起产生了多智能体深度强化学习。
2、在机器人技术中,强化学习对于使机器人能够为自己创建一个高效的自适应控制系统至关重要,它可以从自己的经验和行为中学习。强化学习在智能机器人控制方面具有较大的优势,因为强化学习算法无需预先给定模拟数据,对于数据集样本容量的要求也较低,因此具有更好的适用性。但是现有的多智能机器人集群控制算法稳定性差,精确度低,无法完成最优路径规划、实时动作控制等任务。因此,对于多智能机器人控制,探究稳定性更好、精确度更高的控制方法有着重要的实际价值以及理论意义,也是国内外多智能机器人的难点和热点。
技术实现思路
1、为了克服目前多智能机器人控制稳定性差,精确度低的不足,本发明的目的在于提供一种控制能力强,智能性高的基于深度强化学习的多智能机器人通信控制仪器。
2、本发明解决其技术问题所采用的技术方案是:
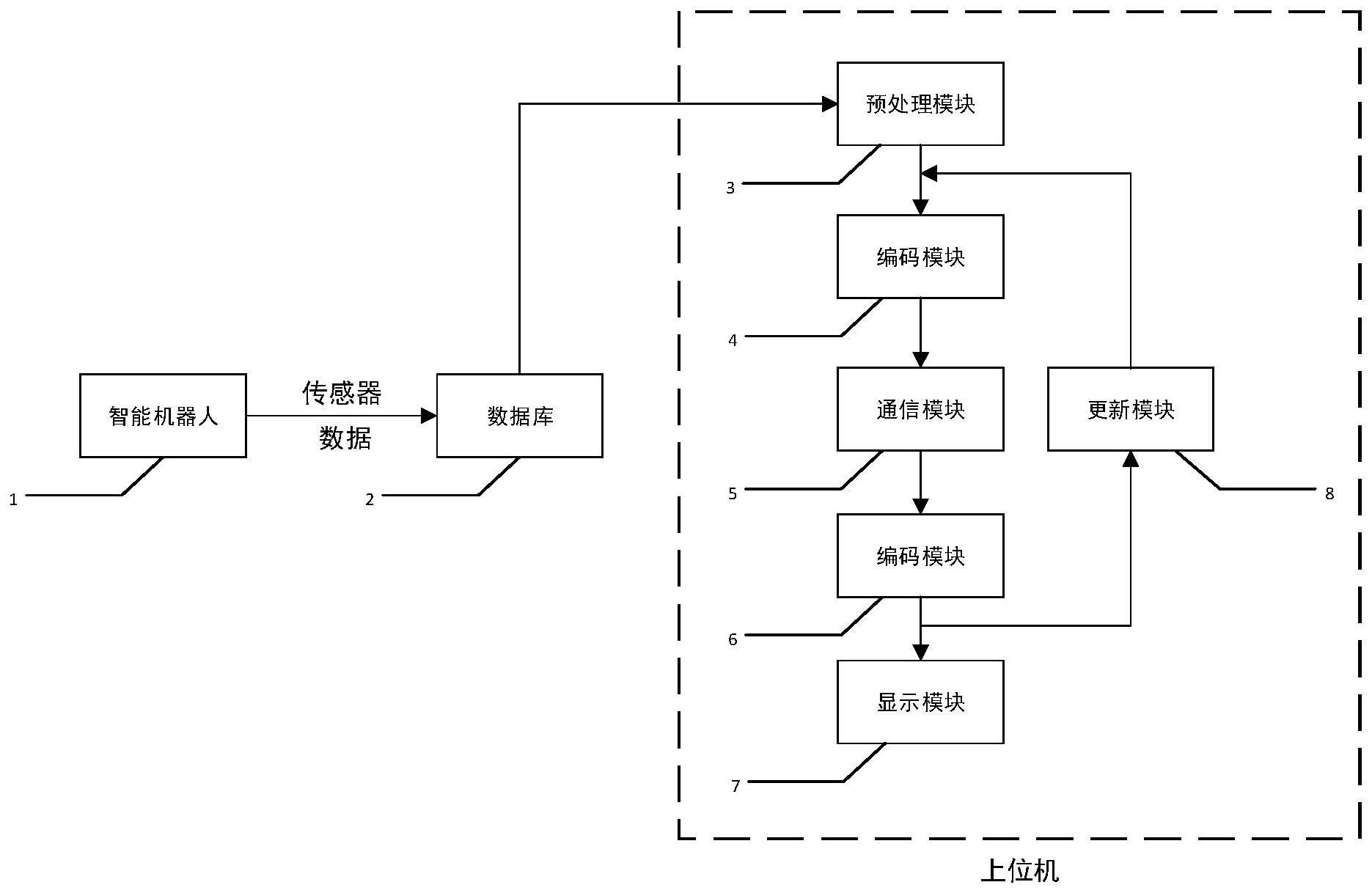
3、一种基于深度强化学习的多智能机器人通信控制仪器,该仪器由通信模块、数据库和上位机构成,通信模块、数据库和上位机依次相连,构成一个完整的控制仪器。其特征在于,多智能机器人观测数据的获取过程按如下步骤进行:
4、1)在仿真环境中使用多智能机器人传感器和gps系统得到周围环境数据和自身数据,其中环境数据用s表示,自身观测用oi表示,自身动作用ai表示,将观测数据与动作数据列为一个组合,即
5、pi=(oi,ai)
6、其中,pi为第i个智能机器人观测动作对;
7、2)在仿真环境中执行每个智能机器人的动作得到及时反馈值ri和下一时刻的观测o′i,将反馈值和下一时刻观测与观测动作对组合为一条经验xi
8、xi=(oi,ai,ri,o′i)
9、其中,xi为第i个智能机器人的历史经验;
10、3)把多智能机器人的历史经验数据存储到所述控制仪的数据库中,数据库中的历史经验数据供上位机调用;
11、基于深度强化学习的多智能机器人通信控制仪器中的上位机,其特征在于,所述上位机包括:
12、4)数据预处理模块,用于对数据库中的数据进行预处理,采用如下过程完成:
13、4.1)数据库中采集样本大小为b的n个智能机器人的历史经验数据得到训练样本集xb
14、xb={x1,x2,...,xn}
15、其中,xi为每个智能机器人的历史经验;
16、4.2)将每个智能机器人的经验按类别分为一组,即
17、ob={o1,o2,...,on}
18、ab={a1,a2,...,an}
19、rb={r1,r2,...,rn}
20、o′b={o′1,o′2,...,o′n}
21、(ob,ab,rb,o′b)即为得到的经过预处理模块预处理的多智能机器人数据,下标b表示该条数据是从采样样本中得到的;
22、5)信息编码模块,用于对经过预处理的多智能机器人数据进行编码,得到输入神经网络的输入数据,采用如下过程完成:
23、5.1)对于步骤4.2)中得到的多智能机器人数据,分割出其中的ob数据;
24、5.2)对ob数据中的每个观测信息oi进行编码,编码过程按如下步骤进行:
25、5.3)搭建全连接层,其中输入维度为每个智能机器人的观测维度,输出维度为编码器长度即64,选择relu激活函数作为神经网络激活函数;
26、5.4)每个观测信息oi输入到编码器f中得到各自的观测编码ei,进一步提取观测信息的特征
27、
28、其中,θe是编码器的神经网络参数;
29、通信模块,用于利用编码后得到的观测编码在多智能机器人中通信,采用如下过程完成:
30、6)搭建通信模块,通信模块由一个gru单元和一个全连接层组成;
31、6.1)gru单元的输入是每个智能机器人的观测编码ei,隐含层神经元数量为32。全连接层的输入是gru单元的输出特征,大小是隐含层维度32,输出为整合信息记为hi;
32、
33、其中,θc是通信模块的神经网络参数,gru模块参数少,模型小,容易部署。本发明上述新颖的信息编码模块和通信模块能够提取更多的多智能机器人观测信息特征,增强了智能机器人行为可解释性,算法速度更快、精度更高。
34、6.2)将每个智能机器人的整合信息整理为hb={h1,h2,...,hn},作为模型训练的训练数据集;
35、模型训练模块,用于通过通信模块后得到的整合信息hb表示的训练样本集训练深度强化学习算法,采用如下过程完成:
36、6.3)搭建多智能体深度强化学习算法框架,即多智能体深度确定性策略梯度算法(maddpg),训练过程按如下步骤进行:
37、6.4)初始化每个智能机器人的critic网络和actor网络的权值和偏置值;
38、6.5)将训练样本集hb={h1,h2,...,hn}和观测数据集ob={o1,o2,...,on}输入到模型训练模块中,首先通过actor网络得到每个智能机器人当前时刻的动作其中i表示智能机器人编号,t表示当前时刻
39、
40、其中μθ是由θ参数化的actor网络,表示当前时刻智能机器人i的观测数据,表示当前时刻智能机器人i的整合信息数据;
41、6.6)得到每个智能机器人当前时刻的动作后,将当前时刻智能机器人i的观测和动作一起输入到critic网络中,得到每个智能机器人在不同时刻的q值
42、
43、其中是由参数化的critic网络,表示除当前智能机器人外的智能机器人采取的动作,可以从数据库中存储的历史经验得到;
44、6.7)重复步骤6.5)-6.6)直至采样样本中每个智能机器人的历史经验数据都得到了对应时刻的q值;
45、6.8)从采样样本中得到历史经验数据,通过贝尔曼方程计算目标q值,
46、
47、其中,yt是当前时刻t的目标q值,是当前时刻智能机器人i的奖励值,γ是折扣因子,下标t+1表示下一时刻,和是网络参数不同结构相同的神经网络,选择神经网络输出值更小的q值来作为目标q值的计算依据,重复11.5)直至智能机器人得到每个时刻的目标q值;
48、所述模型训练模块中critic函数的损失函数loss为均方差损失函数
49、
50、其中mse表示均方差,ot是智能机器人当前观测,at是智能机器人当前动作,所述模型训练模块中actor函数的损失函数为
51、
52、at=μθ(ot)
53、其中是由参数化的critic网络,μθ是由θ参数化的actor网络,ot是智能机器人当前观测,at是智能机器人当前动作;
54、7)模型更新模块,用于评估模型训练模块得到的多智能体深度强化学习算法的效果,采用如下过程完成:
55、在仿真环境中,多智能机器人通过多智能体深度强化学习算法执行动作,与环境交互得到反馈值,将该条经验上传到数据库中,如果数据库中存在与之相同的历史经验,则比较反馈值大小,若新反馈值大则通过训练模块提高执行动作的概率,反之则减小执行动作的概率。如果数据库中不存在相同的历史经验,则存储在数据库中并通过多智能体深度强化学习算法计算o值,更新数据库;
56、8)结果显示模块:用于将多智能机器人的运动过程在上位机进行显示,采用如下过程完成:
57、在仿真环境中运行多智能机器人运动程序,将多智能机器人执行结果显示在上位机的屏幕上。
58、本发明的技术构思为:多智能机器人通过所载传感器获取观测数据,对观测数据进行预处理和信息编码,并用处理后的数据训练深度强化学习算法,建立多智能体通信控制模型,实现多智能机器人的通信控制。
59、本发明的有益效果主要表现在:1、利用信息编码模块提取更多的多智能机器人观测信息特征,增强智能机器人行为可解释性,算法速度更快、精度更高;2、利用通信模块在多智能机器人中传递信息,提高多智能机器人的合作能力,使控制更稳定。
- 还没有人留言评论。精彩留言会获得点赞!