一种基于L-SHADE-MLP的机器人定位误差预测方法及系统
本发明属于机器人定位误差相关,更具体地,涉及一种基于l-shade-mlp的机器人定位误差预测方法及系统。
背景技术:
1、工业机器人的发展受限于有限的定位精度,为了满足机器人高精加工要求,需进一步降低机器人绝对定位误差。工业机器人定位误差主要分为几何误差和非几何误差。现有使用扩展卡尔曼滤波与人工神经网络结合算法、遗传粒子群(gpso)、深度置信网络和图神经网络等技术对定位误差进行预测。上述技术均是在修改机器人参数模型对几何误差进行补偿的基础上,再结合神经网络模型预测非几何误差。
2、现有技术存在问题:(1)运动学标定法将机器人视作理想模型,无法对非几何误差进行补偿,且商用机器人通常无权限修改机器人的几何参数,技术难以实施;(2)对于机器人定位任务来说,机器人定位误差通常是一个连续值的预测问题,获取大规模的标注数据较困难、成本较高。当数据集规模较小时,复杂的神经网络模型易陷入局部最优解;(3)图神经网络等模型在对新关节角预测时,需要重新完成图构建,推理速度较慢,实时性较差;(4)若在几何误差补偿基础上进行非几何误差补偿,过程中产生误差重叠,相较于直接预测综合误差,预测精度较低,推理速度也较慢。
3、总而言之,现有技术方法或定位误差精度较低,或推理时间较长,实时性较差,不能满足机器人定位误差预测的高精度与系统的实时性要求。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于l-shade-mlp的机器人定位误差预测方法及系统,其结合改进l-shade算法的全局搜索能力和mlp模型的局部搜索能力直接对机器人关节角对应的定位误差进行高效的综合预测,克服了mlp模型容易陷入局部最优解的缺点,同时提高了机器人定位误差预测的准确性。
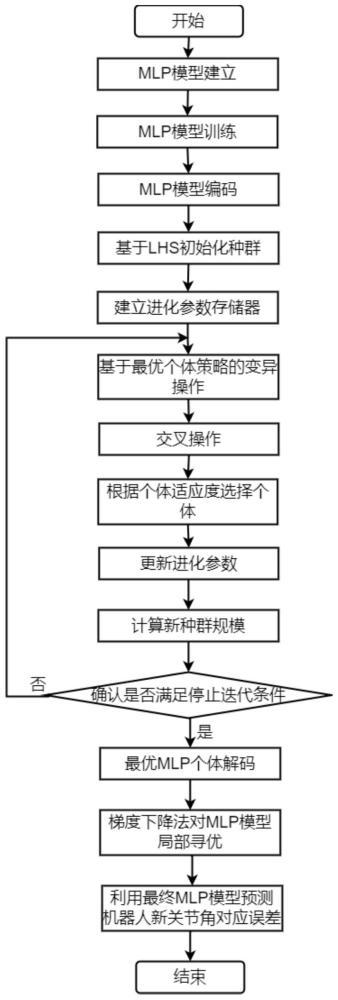
2、为实现上述目的,按照本发明的一个方面,提供了一种基于l-shade-mlp的机器人定位误差预测方法,该方法包括以下步骤:
3、(1)构建多层感知机模型,并利用定位误差及其对应的机器人关节角数据对所述多层感知机模型进行训练;
4、(2)通过实数编码方式将mlp参数模型转换为改进l-shade算法的种群个体,并基于拉丁超立方采样初始化种群;
5、(3)对种群个体执行基于最优个体变异策略的变异操作和交叉操作以得到试验个体;
6、(4)对比试验个体及初始个体的适应度以选择出优秀个体,同时根据所选择到的个体自适应调整进化参数;
7、(5)判断是否满足停止迭代条件,若满足则迭代过程停止,转至步骤(6);否则跳转至步骤(3);
8、(6)根据实数编码的逆过程将最优mlp个体解码为mlp参数模型,并基于梯度下降法完成mlp模型的局部寻优,得到最终mlp模型,进而采用最终mlp模型预测新的机器人关节角所对应的定位误差。
9、进一步地,若当前适应度收敛到最小值或已迭代次数超过最大迭代次数时,迭代过程停止,完成最优mlp个体的搜索。
10、进一步地,构建mlp模型时,确定最佳神经元个数范围所采用的公式为:
11、
12、式中,n、m表示输入层和输出层神经元个数,常数α∈{1,2,…,10};
13、隐含层激活函数设置为elu函数:
14、
15、式中,α为缩放因子,取α=1;
16、输出层激活函数设置为线性函数:
17、f(x)=x (3)。
18、进一步地,编码过程指将mlp模型上的各个权值、偏置按照一定的顺序级联成一个实数向量,这个向量的每个维度都表示一个参数,将编码后的mlp模型对应的实数向量称为mlp个体。
19、进一步地,所述利用拉丁超立方采样初始化种群的步骤包括:首先,取参数空间为mlp个体的每一维,将每一维分割为互不重叠的n个长度相同的区间;然后,对于每一维,在其每一个区间中随机选取一个点;最后,通过从每一维里随机选取初始采样中的点组成d维变量。
20、进一步地,用最优个体变异策略引导l-shade算法种群变异所采用的公式为:
21、
22、式中,是从种群pg中的适应度最高的p·n个中随机选择出的个体,p∈(0,1);分别是从pg、pg∪a中随机选择的个体;a为外部存储器,存储之前迭代过程中被成功选择的个体。
23、进一步地,当个体维度的数值超出限制范围(-1,1)后,对差分向量进行修正:
24、
25、式中,xmin=-1;xmax=1;vi,j,g与xi,j,g的下标表示第g代种群pg的第i号个体的第j维。
26、进一步地,将变异产生个体vi,j,g与初始个体xi,j,g交叉,产生新试验个体ui,j,g:
27、
28、式中,cri为第i号个体的交叉率;
29、体适应度为f:
30、
31、式中,msei表示定位误差三个分量中第i个分量的均方误差;n为样本总量;yij和分别为第i个分量的第j个真实值和预测值。
32、进一步地,进化参数交叉率cr和缩放因子f自适应更新策略为:
33、
34、
35、式中,mcr和mf分别为存储在迭代进化过程中被成功选择试验个体的交叉率cr和缩放因子f集合scr、集合sf的lehmer均值,mcr、mf的更新方式为:
36、
37、
38、
39、
40、δfk=|f(uk,g)-f(xk,g)| (14)
41、式中,下标中的k表示历史存储器b的索引;⊥为自定义的终止值;sk为scr和sf的统一表示;meanwl(scr)、meanwl(sf)分别为集合scr、sf的lehmer均值;δfk为被选择的试验个体与初始个体的适应度差距。
42、本发明还提供了一种基于l-shade-mlp的机器人定位误差预测系统,所述系统包括存储器及处理器,所述存储器储存有计算机程序,所述处理器执行所述计算机程序时执行如上所述的基于l-shade-mlp的机器人定位误差预测方法。
43、总体而言,通过本发明所构思的以上技术方案与现有技术相比,本发明提供的基于l-shade-mlp的机器人定位误差预测方法及系统主要具有以下内容:
44、1.本发明结合mlp模型的局部寻优能力和改进l-shade算法的全局寻优能力,解决了神经网络模型容易陷入局部最优解的问题,提高了机器人定位误差的预测能力。
45、2.采用数据驱动的方法直接对机器人的定位误差进行预测,通过机器人的关节角预测定位误差,无需修改机器人的几何参数,易于实施。
46、3.本发明采用轻型mlp神经网络模型,相交于图神经网络等对每个机器人新关节角需要重新建立单独图结构,极大地提高了推理速度,适合频繁有大量目标点需要进行预测的任务。
47、4.本发明直接对几何与非几何定位误差综合预测,相较于现有技术分步预测,消除了过程中的误差重叠,定位精度得到了显著提高。
- 还没有人留言评论。精彩留言会获得点赞!