一种使用循环一致对抗网络快速计算掩模近场的方法
1.本发明涉及光刻技术的技术领域,尤其涉及到一种使用循环一致对抗网络快速计算掩模近场的方法。
背景技术:
2.光刻技术是超大规模集成电路制造的核心技术之一。在集成电路制造的一系列过程中,只有光刻才能在硅片上产生图案,这也是制造电路三维结构的一个重要步骤。光刻系统主要由照明系统、掩膜、投影物镜、瞳孔和涂有光刻胶的硅晶圆等部分组成,光源发出的光波照射并透过掩膜生成掩膜近场,并经过投影物镜投影、瞳孔的低通滤波和光刻胶刻蚀把掩膜图案转移到硅晶圆上,但是在图像传递过程中的信息丢失使得硅晶圆上的形状发生畸变,并随着波长的减小、数值孔径的增大和工艺过程的复杂度提高变得越加明显。
3.随着半导体集成强度的不断提高,摩尔定律的延续和光刻技术的不断改进,光刻技术节点进入22nm节点,半导体的特征尺寸不断减小,导致euv光通过厚掩模时衍射效应变得非常严重。因此,标量衍射理论不再精确,这要求我们找到一些精确的方法来计算光通过厚掩模后掩模的近场。
4.相关文献(fast mask near-field calculation using fully convolutionnetwork)提出了基于全卷积网络(fcn)的掩模近场计算方法。该方法利用unet 结构并使用扩张卷积扩大感受野去完成端到端和像素到像素的数据转换的网络模型训练,保证训练的稳定性。
5.但是该方法存在两点不足:
6.第一,冗余太大,由于每个像素点都需要取一个patch,那么相邻的两个像素点的patch相似度是非常高的,这就导致了非常多的冗余,导致网络训练很慢。
7.第二,分类准确度和定位精度不可兼得,当感受野选取比较大的时候,后面对应的pooling层的降维倍数就会增大,这样就会导致定位精度降低,但是如果感受野比较小,那么分类精度就会降低。
8.综上所述,现有的掩模近场计算方法在优化网络框架、计算效率和计算精度等方面均有待进一步改善和提高。
技术实现要素:
9.本发明的目的在于克服现有技术的不足,提供一种使用循环一致对抗网络快速计算掩模近场的方法。
10.为实现上述目的,本发明所提供的技术方案为:
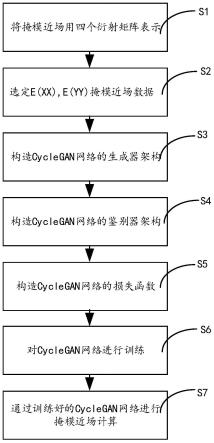
11.一种使用循环一致对抗网络快速计算掩模近场的方法,包括以下步骤:
12.s1、将掩模近场用四个衍射矩阵表示,记为e(uv),其中u=x或y,v=x 或y;x和y表示复数坐标系中的两个偏振方向;
13.s2、选定对掩模近场成像图案贡献最大的e(xx)与e yy)提取掩模近场数据,而忽
略贡献e(xy)与e yx)的影响;
14.s3、构造cyclegan网络的生成器架构,采用最近邻算法进行上采样,使用跨步卷积进行下采样,并构建下采样块、上采样块和残差块;
15.s4、构造cyclegan网络的鉴别器架构;
16.s5、构造cyclegan网络的损失函数,该损失函数包括由掩模正向生成掩模近场成像图案的目标函数、由掩模近场反向生成掩模近场成像图案的目标函数、循环一致性损失函数、恒等映射损失函数;
17.s6、对cyclegan网络进行训练,得到训练好的cyclegan网络;
18.s7、通过训练好的cyclegan网络进行掩模近场计算。
19.进一步地,所述步骤s1中,e(uv)表示由在v方向极化的单位入射电场产生的在u方向偏振的近场的复振幅,公式表示为:
20.e(uv)=e
real
(uv)+ie
imag
(uv)
21.其中,e
real
(uv)和e
imag
(uv)分别表示e(uv)的实部和虚部;i表示复数坐标系中的复数坐标轴,即虚轴。
22.进一步地,所述步骤s2中,获取掩模近场实部与虚部数据阵列的公式如下:
[0023][0024][0025]
其中,表示e(xx)在xx方向的振幅数值阵列,表示e(xx)在xx方向的相位数值阵列;表示e(yy)在yy方向的振幅数值阵列,表示e(yy)在 yy方向的相位数值阵列。
[0026]
进一步地,构造cyclegan网络的损失函数公式如下:
[0027]
l
gan
(g,f)=l
gan
(g,dy,x,y)+l
gan
(f,d
x
,y,x)
[0028]
+λl
cycle
(g,f)+μl
identity
(g,f);
[0029]
其中,l
gan
(g,dy,x,y)为由掩模正向生成掩模近场成像图案的目标函数; l
gan
(f,d
x
,y,x)为由掩模近场反向生成掩模近场成像图案的目标函数;l
cycle
(g,f) 为循环一致性损失函数;l
identity
(g,f)为恒等映射损失函数;λ和μ均为权重。
[0030]
进一步地,由掩模正向生成掩模近场成像图案的目标函数公式如下:
[0031][0032]
目标是为了以确保生成的掩模近场图案与由数据得到的掩模图案尽可能的接近;
[0033]
由掩模近场反向生成掩模近场成像图案的目标函数公式如下:
[0034]
[0035]
目标是为了以确保生成的掩模图案与由数据得到的掩模近场图案尽可能的接近;
[0036]
其中,e是数学期望,~是服从关系,以及p是输入数据;p
data
(x)是掩码数据分布,p
data
(y)是掩模近场数据分布,生成网络g是从掩模到掩模近场的映射,即正向映射;生成网络f是从掩模近场到掩模的映射,即反向映射;鉴别网络d
x
用于区分真实掩模与由掩模近场反向生成的掩模,鉴别网络dy用于区分掩模近场和由掩模正向生成的掩模近场。
[0037]
进一步地,循环一致性损失函数公式如下:
[0038][0039]
其中,真实数据和反向生成的数据之间的差异由l1范数衡量;
[0040]
恒等映射损失函数公式如下:
[0041][0042]
进一步地,在cyclegan网络训练过程中,在更新参数时,保留一个模式缓冲区来存储之前生成的图案,并使用这些模式来更新鉴别器,而不仅仅是新生成的模式;对于两个生成对抗网络中的对抗性损失,用最小二乘损失代替负对数似然函数。
[0043]
与现有技术相比,本方案原理及优点如下:
[0044]
1)相对于现有的掩模近场计算方法,本方案中的cyclegan掩模近场计算方法克服了以往传统的严格电磁场掩模近场计算计算量大和计算时间长的问题,使得实时近场计算成为可能。
[0045]
2)本方案以机器学习中生成对抗网络(gan)的框架为基础,构造两个生成器分别正向和反向生成掩模近场和掩模的成像图案;然后利用循环一致损失作为约束条件,以确保正向与反向生成的掩模近场与掩模成像图案一一对应,并构造出包含对抗损失和约束条件循环一致损失的函数,得到总的损失函数;在取得更快的掩模近场计算速度时,也具有更低的损失函数值。
[0046]
3)采用无监督学习的训练方式,去学习输入数据集与输出数据集之间的映射,而不是单一的输入与输出之间的映射,因此无监督训练模型方式拥有非常广泛的应用范围,且存在巨大的研究价值。
附图说明
[0047]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的服务作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0048]
图1为本发明一种使用循环一致对抗网络快速计算掩模近场的方法的原理流程图;
[0049]
图2为4个生成模型测试掩模近场生成效果的结果成像示意图;
[0050]
图3为4个网络训练效果的损失函数示意图;
[0051]
图4为4个网络测试效果的损失函数示意图;
[0052]
图5为cyclegan网络的生成器框架结构示意图;
[0053]
图6为cyclegan网络的鉴别器框架结构示意图。
具体实施方式
[0054]
下面结合具体实施例对本发明作进一步说明:
[0055]
本实施例所述的一种使用循环一致对抗网络快速计算掩模近场的方法,其原理为:以机器学习中生成对抗网络(gan)的框架为基础,构造两个生成器分别正向和反向生成掩模近场和掩模的成像图案;然后利用循环一致损失作为约束条件,以确保正向与反向生成的掩模近场与掩模成像图案一一对应,并构造出包含对抗损失和约束条件循环一致损失的函数,得到总的损失函数,即:
[0056]
l
gan
(g,f)=l
gan
(g,dy,x,y)+l
gan
(f,d
x
,y,x) +λl
cycle
(g,f)+μl
identity
(g,f)
[0057]
其中第一项是由掩模正向生成掩模近场成像图案的目标函数公式,第二项是由掩模近场反向生成掩模成像图案的目标函数公式,第三项是约束条件循环一致损失函数,第四项是恒等映射损失函数;
[0058]
一方面,克服了以往传统的严格电磁场掩模近场计算方法在计算过程中没有任何近似的约束,使得提升运算速度成为可能;
[0059]
另一方面,该方法以机器学习中生成对抗网络(gan)的框架为基础,构造两个生成器分别正向和反向生成掩模近场和掩模的成像图案;然后利用循环一致损失作为约束条件,以确保正向与反向生成的掩模近场与掩模成像图案一一对应,并构造出包含对抗损失和约束条件循环一致损失的函数,得到总的损失函数;在取得更快的掩模近场计算速度时,也具有更低的损失函数值。
[0060]
如图1所示,本实施例所述的一种使用循环一致对抗网络快速计算掩模近场的方法,包括以下步骤:
[0061]
s1、将掩模近场用四个衍射矩阵表示,记为e(uv),其中u=x或y,v=x 或y;x和y表示复数坐标系中的两个偏振方向;
[0062]
e(uv)表示由在v方向极化的单位入射电场产生的在u方向偏振的近场的复振幅,公式表示为:
[0063]
e(uv)=e
real
(uv)+ie
imag
(uv)
[0064]
其中,e
real
(uv)和e
imag
(uv)分别表示e(uv)的实部和虚部;i表示复数坐标系中的复数坐标轴,即虚轴。
[0065]
s2、选定对掩模近场成像图案贡献最大的e(xx)与e(yy)提取掩模近场数据,而忽略贡献e(xy)与e(yx)的影响;
[0066]
获取掩模近场实部与虚部数据阵列的公式如下:
[0067]
[0068][0069]
其中,表示e(xx)在xx方向的振幅数值阵列,表示e(xx)在xx方向的相位数值阵列;表示e(yy)在yy方向的振幅数值阵列,表示e(yy)在 yy方向的相位数值阵列。
[0070]
s3、构造cyclegan网络的生成器架构,采用最近邻算法进行上采样,使用跨步卷积进行下采样,并构建2个下采样块、2个上采样块和9个残差块。在模块中,relu用作激活函数,instancenorm用于实例归一化,reflectionpad2d 用于相反方向的边缘像素值填充。
[0071]
s4、构造cyclegan网络的鉴别器架构;构造4个下采样块和1个卷积层,最后使用卷积产生一维输出。在下采样块中,leakyrelu用作激活函数, instancenorm用于实例归一化,第一层不使用归一化,同样采用跨步卷积进行下采样。
[0072]
s5、构造cyclegan网络的损失函数,公式如下:
[0073]
l
gan
(g,f)=l
gan
(g,dy,x,y)+l
gan
(f,d
x
,y,x)
[0074]
+λl
cycle
(g,f)+μl
identity
(g,f);
[0075]
其中,l
gan
(g,dy,x,y)为由掩模正向生成掩模近场成像图案的目标函数; l
gan
(f,d
x
,y,x)为由掩模近场反向生成掩模近场成像图案的目标函数;l
cycle
(g,f 为循环一致性损失函数;l
identity
(g,f)为恒等映射损失函数;λ和μ均为权重。
[0076]
具体地,由掩模正向生成掩模近场成像图案的目标函数公式如下:
[0077][0078]
目标是为了以确保生成的掩模近场图案与由数据得到的掩模图案尽可能的接近;
[0079]
g表示生成器,d表示鉴别器;最后送入鉴别器的数据有真实数据与生成器生成的数据,来判别它们是否为真实数据,概率范围在0-1之间;鉴别器d的作用是希望把真实数据判定为1,把生成数据判定为0;生成器g希望通过仿照的方式去欺骗鉴别器d,使得d把生成数据也判定为1;这样就形成了一种对抗的博弈,之所以是ming和是真实数据与生成数据之间的差异性。d判定真实数据接近1,判定生成数据接近0,会增大生成数据与真实数据之间的差异(max) 而g其实就是在伪造真实数据,经过训练,g生成的数据将会越来越接近真实数据,所以它们之间的差异性就会越来越小(min)。最终达到平衡时,d判定生成数据与真实数据的概率值都为0.5,即无法区分真假,或者说它们完全一样(0.5 是因为这里只有一个生成器,本实施例共用了两个生成器,取了平均所以最后是收敛到达0.25)
[0080]
由掩模近场反向生成掩模近场成像图案的目标函数公式如下:
[0081][0082]
目标是为了以确保生成的掩模图案与由数据得到
g和loss d两者都应该收敛到0.25,而不是一般gan网络的 0.5。
[0103]
如图4所示,测试loss曲线显示了本发明所述模型的稳定性,而计算时间曲线也反映了该模型计算速度的稳定性。
[0104]
如图5所示,在生成器网络中,采用最近邻算法进行上采样,使用跨步卷积进行下采样,并构建2个下采样块、2个上采样块和9个残差块。在模块中,relu 用作激活函数,instancenorm用于实例归一化,reflectionpad2d用于相反方向的边缘像素值填充。
[0105]
如图6所示,在构造cyclegan网络的鉴别器架构时,构造了4个下采样块和1个卷积层,最后使用卷积产生一维输出。在下采样块中,leakyrelu用作激活函数,instancenorm用于实例归一化,第一层不使用归一化,同样采用跨步卷积进行下采样。
[0106]
由图2可知,相比现有的掩模近场计算方法,本发明所涉及的cyclegan算法相比fcn以及传统方法可以使损失循环一致收敛,从而改进了收敛效率;与基于fcn的掩模近场计算方法相比由于采用正向与反向的生成网络,从而提高了运算效率以及运算精度。
[0107]
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1