一种基于自适应学习率的端到端的语音识别方法与流程
本发明涉及语音识别技术领域,特别涉及一种基于自适应学习率的端到端的语音识别方法。
背景技术:
随着深度学习的兴起,基于深度神经网络的语音识别技术取得了显著的进步。目前,常用的语音识别方法采用基于隐马尔可夫模型和深度神经网络的混合方法,需要训练隐马尔可夫模型以及相应的高斯混合模型,为后续训练深度神经网络提供帧级别的训练标注。但是,基于隐马尔可夫模型和深度神经网络的混合方法的语音识别框架较复杂:一是其训练得到的高斯混合模型并不会用于最终的解码过程中;二是训练模型依赖过多的语言学知识,比如建立决策树时需要的问题集;三是较多的超参数,均需要精细的调参才能获取最优性能,如状态聚类个数和高斯混合模型的高斯数等。
端到端的语音识别一般采用connectionisttemporalclassification(ctc)准则作为递归神经网络(recurrentneuralnetwork,rnn)的目标函数进行训练。在计算得到目标函数对神经网络中各参数的偏导数后,使用最为常见的参数更新方法,结合冲量(momentum)的随机梯度下降法,更新神经网络中的各个参数。ctc准则引入的blank符号对目标函数的贡献与其他建模单元相同,并且blank符号由于其辅助对齐的作用,会频繁出现在对齐路径上,但却对识别结果的统计没有影响。
技术实现要素:
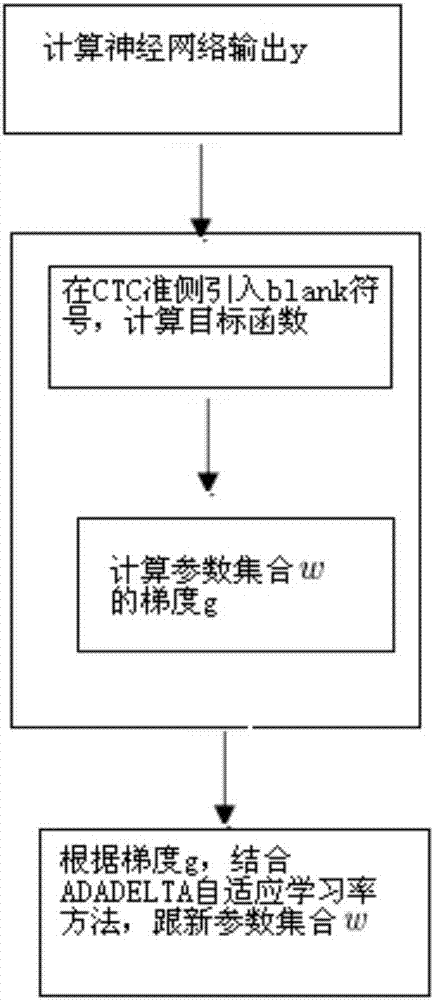
本发明的目的在于,为解决现有的语音识别方法的复杂的语音识别框架的缺陷,提供一种基于自适应学习率的端到端的语音识别方法;该方法具体包括:
(1)、采用双向递归神经网络作为声学模型,分别计算所述前向递归神经网络隐层
(2)、将上述步骤(1)中的声学模型建模单元作为音素,采用connectionisttemporalclassification(ctc)准则,在ctc准则引入了blank符号辅助对齐,构建和计算目标函数:再对目标函数关于神经网络输出进行求偏导计算,所得的偏导数再通过使用误差反向传播算法(errorbackpropagation,bp)计算所述步骤(1)中权值矩阵中的参数集合w的梯度g;
(3)、基于上述步骤(2)所提供的一阶梯度信息,即梯度g,再结合adadelta自适应学习率的方法,对所述步骤(1)中权值矩阵中的参数集合w进行更新。
所述参数集合w包括权值矩阵和偏置构成整个神经网络集合。
计算包含所述步骤(1)中权值矩阵的参数集合w的梯度g如下:
假设一句输入的语音x共有t帧特征,那么一个基于ctc准则的对齐序列表示为p=(p1,...,pt),每一个pt表示时刻t的输出音素,那么该对齐序列的似然概率,即pr(p|x),
其中,
blank出现在任意位置,且其不影响最终的输出结果;给定输入的特征序列x,对应标注为z的似然概率进行如下计算,
其中,pr(z|x)为目标函数,φ(z)为对应的标注z若干带有blank的对齐序列;
计算所述目标函数pr(z|x)关于神经网络输出的偏导数,即为
所述adadelta自适应学习率的方法,其具体计算方法如下:
其中,gt为时刻t的梯度,e[g2]t表示t时刻累加的梯度gt平方的期望,e[g2]t-1为t-1时刻累加梯度的平方的期望,ρ为一个衰减因子,取值范围为(0,1);
假设e[g2]0表示e[g2]t初始化为0;
其中,∈用于防止数学运算错误,rms[g]t为梯度gt均方根值;
其中,δwt表示t时刻神经网络中参数集合w中的任一参数的更新值,rms[δw]t-1为t-1时刻的更新值的均方根值;
其中,e[δw2]t表示t时刻参数w中的任一参数的累加更新值平方的期望,
e[δw2]t-1表示t-1时刻参数ω中的任一参数的累加更新值平方的期望;
假设e[δω2]0表示e[δω2]t初始化为0;
wt+1=wt+δwt
其中,ωt+1为更新后的参数值,ωt为当前参数值。
本发明的优点在于:端到端的语音识别系统抛弃了传统的隐马尔可夫模型,而是利用递归神经网络(recurrentneuralnetwork,rnn)在时间序列建模方面的优点,借助递归神经网络建立语音特征序列到对应音素或字符序列的直接映射。端到端的语音识别建模方法极大地简化了构建语音识别系统的流程;使用ctc准则作为训练目标函数,引入了blank符号且其对似然函数的贡献远大于其他音素;再结合自适应学习率的方法adadelta,通过将神经网络中每个参数的梯度累积下来,可以减弱频繁出现的特征对网络权重的影响。
附图说明
图1是本发明提供的基于自适应学习率的端到端的语音识别方法的lstm结构图;
图2是本发明提供的基于自适应学习率的端到端的语音识别方法的训练流程图;
具体实施方式
以下结合附图对本发明作进一步的详细说明。
如图2所示,本发明提供一种基于自适应学习率的端到端的语音识别方法;该方法具体包括:
(1)、采用双向递归神经网络作为声学模型,分别计算前向和反向的递归神经网络隐层,即
假设输入特征序列使用x=(x1,…,xt),那么所述的前向递归神经网络隐层
其中,σ为sigmoid激活函数,
所述反向递归神经网络隐层
其中,σ为sigmoid激活函数,
前向和反向递归神经网络的隐层输出拼接成为整个网络的隐层输出
y=g(whyh+by)(3)
其中,why为连接隐藏层和输出层的权值矩阵;by为偏置;y为神经网络的最终输出;g(·)为softmax函数,计算公式如下:
其中,z表示神经网络做规整前的输出值,ez为其指数运算,zk表示第k个节点的输出值,k为输出节点个数。
通过公式(1),(2)计算前向和反向的递归神经网络隐层,即
如图1所示,采用lstm计算所述前向递归神经网络隐层
其中,
其中,
其中,
其中,
通过对上述公式(5)-(9)的计算,得出所述前向递归神经网络隐层的最终的输出结果
类似的,采用lstm计算所述反向递归神经网络隐层
其中,
其中,
其中,
其中,
通过对上述公式(10)-(14)的计算,得出所述反向递归神经网络隐层的最终的输出结果
其中,上述所有公式中提到的权值矩阵和偏置构成整个神经网络的参数w的集合;即
其中,
和
通过计算得出的所述前向递归神经网络隐层和所述反向递归神经网络隐层的最终输出结果,即
(2)、根据上述步骤(1)中的声学模型建模单元为音素,采用connectionisttemporalclassification(ctc)准则,在ctc准则中引入了blank符号辅助对齐,构建和计算目标函数,具体计算过程如下:
假设一句输入的语音x共有t帧特征,那么一个基于ctc准则的对齐序列可以表示为p=(p1,...,pt),每一个pt表示时刻t的输出音素,那么该对齐序列的似然概率,即pr(p|x),可以用(15)式描述:
其中
blank可以出现在任意位置,且其不影响最终的输出结果;给定输入的特征序列x,对应标注为z的似然概率进行如下计算,用(16)式描述:
其中,pr(z|x)为目标函数,φ(z)为对应的标注z可以若干带有blank的对齐序列。
随后,计算所述目标函数pr(z|x)关于神经网络输出的偏导数,即为
(3)、基于上述步骤(1)所提供的一阶梯度信息,即g,结合adadelta自适应学习率的方法,对神经网络中的参数集合ω中的任意一个参数进行更新,计算方法如下:
其中,gt为时刻t的梯度,e[g2]t表示t时刻累加的梯度gt平方的期望,e[g2]t-1为t-1时刻累加梯度的平方的期望,ρ为一个衰减因子,取值范围为(0,1);
假设e[g2]0表示e[g2]t初始化为0;
其中,∈是为了防止数学运算错误,rms[g]t为梯度gt均方根值;
其中,δwt表示t时刻神经网络中参数ω的更新值,rms[δω]t-1为t-1时刻的更新值的均方根值;
其中,e[δω2]t表示t时刻参数ω累加更新值平方的期望,e[δω2]t-1表示t-1时刻参数ω累加更新值平方的期望;
假设e[δω2]0表示e[δω2]t初始化为0;
ωt+1=ωt+δωt(21)
其中,ωt+1为更新后的参数值,ωt为当前参数值。
本发明实验使用数据为switchboard数据集,其中训练数据总共为全部训练数据的子集,时长共110小时的电话交谈语音,测试数据为hub5’00中的switchboard测试集。测试评价指标有训练过程中的标注正确率(labelaccuracyrate,lac)和测试集的字错误率(worderrorrate,wer)。测试结果如下表:
由表中可以看出,采用本发明的方法后,在训练集和验证集的标注正确率上分别有接近6%和1%的绝对提升,而字错误率也有0.9%的绝对提升。因此,通过使用adadelta方法可以简化语音识别的框架,并且明显提升端到端的语音识别系统的识别性能。
最后需要说明的是,具体实施方式中所述的实验用图仅用来说明本发明的技术方案软件算法的可行性而非局限于此例,算法已经经过大量实验数据验证,是真实可靠的,搭配硬件便可实现本发明的技术方案。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!