基于云端的设备及其操作方法与流程
本公开一般涉及一种设备,尤其涉及一种基于云端的设备及其操作方法。
背景技术:
在人工智能研究领域,自发性的幽默行为被视为在真正让机器拥有人的思维之前的终极挑战。因此,让机器具备严格意义上和人相同的自发幽默特征在现阶段是没有技术能够实现的。
隐马尔科夫模型(hiddenmarkovmodel,hmm)是一种统计模型,它用来描述一个含有隐含未知参数的马尔科夫过程(隐马尔科夫过程)。隐马尔科夫模型创立于20世纪70年代,80年代得到了传播和发展,成为信号处理的一个重要方向,现已成功地用于语音识别,行为识别,文字识别以及故障诊断等领域。
隐马尔科夫模型(hmm)包含两个随机过程,其中之一是markov链,它描述了状态的转移,产生一定的状态序列,但是是被隐藏起来,无法观测的;另外一个随机过程描述了状态和观测值之间的统计对应关系。不同的状态按照各自概率函数产生一定的观测序列,观测者只能看到观测值而不能看到markov链中的状态,只能通过一个随机过程感知状态的存在及它的特性,所以称之为隐马尔科夫模型,其基本要素包括:
1.隐含状态s
这些状态之间满足马尔科夫性质,是马尔科夫模型中实际所隐含的状态。这些状态通常无法通过直接观测而得到(例如s1、s2、s3等等)。
2.可观测状态o
在模型中与隐含状态相关联,可通过直接观测而得到(例如o1、o2、o3等等,可观测状态的数目不一定要和隐含状态的数目一致)。
3.初始状态概率矩阵π
表示隐含状态在初始时刻t=1的概率矩阵,(例如t=1时,p(s1)=p1、p(s2)=p2、p(s3)=p3,则初始状态概率矩阵π=[p1p2p3])。
4.隐含状态转移概率矩阵a
描述了hmm模型中各个状态之间的转移概率。
其中aij=p(sj|si),1≤i,j≤n.表示在t时刻、状态为si的条件下,在t+1时刻状态是sj的概率。
5.观测状态转移概率矩阵b(confusionmatrix,也称为混淆矩阵)。
令n代表隐含状态数目,m代表可观测状态数目,则:
bij=p(oi|sj),1≤i≤m,1≤j≤n.
表示在t时刻、隐含状态是sj条件下,观察状态oi的概率。
一般情况下,用λ=(a,b,π)三元组来简洁的表示一个隐马尔科夫模型。
hmm可以由说明书附图1表示,节点之间的箭头表示两个状态之间的条件概率关系。图1中方形的节点代表耦合链的观察节点,圆形节点代表耦合链的隐藏节点。
技术实现要素:
以下提供一个或多个方面的简要概述以提供对本公开的多个方面的基本理解。然而,应当注意,以下概述不是构想到的所有方面的详尽综述,并且既不旨在陈述本公开所有方面的关键性或决定性要素,也不试图限定本公开的任何或所有方面的范围。相反,以下概述的唯一目的在于,以简化形式给出本公开的一个或多个方面的一些概念,以作为稍后阐述的具体实施方式的前序。
本公开的目的不在于开发相应的技术让智能体理解并拥有幽默特性,而是通过云端技术和机器学习技术让智能体在和目标受众的互动中具有一些预设好的幽默行为特征。这将更加完善陪伴型机器人的智能特性,从而达到愉悦目标受众的目的。
根据本公开的一个方面,本公开提供了一种基于云端的设备。
根据本公开的一个方面,所述基于云端的设备包括:分析装置,所述分析装置包括:第一hmm分析器,用于分别接收场景输入信号、受众表情输入信号和受众语音输入信号作为第一hmm的可观测序列并根据观测序列概率最大 化的准则推断出第一hmm的隐藏状态变化序列,其中第一hmm的隐藏状态变化序列包括场景隐藏状态变化序列、受众表情隐藏状态变化序列和受众语音隐藏状态变化序列;情绪状态hmm分析器,用于接收所述场景隐藏状态变化序列、受众表情隐藏状态变化序列和受众语音隐藏状态变化序列作为情绪状态hmm的可观测序列并根据观测序列概率最大化的准则推断出情绪状态hmm的隐藏状态变化序列;以及语音信号处理单元,用于对受众语音输入信号进行识别并根据识别结果输出标准指令,决策装置,用于接收所述情绪状态hmm的隐藏状态变化序列和所述标准指令,基于所述情绪状态hmm的隐藏状态变化序列选取幽默行为并整合幽默行为指令和所述标准指令作为最终输出指令。
根据本公开的一个方面,所述第一hmm分析器进一步包括场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器,其中所述场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器以串行或并行的方式连接。
根据本公开的一个方面,所述决策装置包括:幽默行为选取单元,用于对所述情绪状态hmm的隐藏状态变化序列进行概率分析并选取幽默行为和发送幽默行为指令;整合单元,用于对所述幽默行为指令及所述标准指令进行整合以作为最终输出指令,其中,所述情绪状态hmm分析器的输出端连接至所述幽默行为选取单元的输入端,所述幽默行为选取单元的输出端连接至所述整合单元的输入端,且所述语音信号处理单元的输出端连接至所述整合单元的输入端。
根据本公开的一个方面,所述整合包括:当所述幽默行为指令为“错误反馈”时,所述整合单元根据所述幽默行为指令修正所述标准指令,具体为不执行所述标准指令并由所述整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取一些其他表演表达幽默感。
根据本公开的一个方面,所述整合还包括:当所述幽默行为指令为“讲笑话”、“念趣闻”、“搞笑动作”、“唱歌”中的一者时,所述整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取最优幽默输出指令并将所述最优幽默输出指令和所述标准指令作为最终输出指令,其中,所述最优幽默输出指令为最匹配目标受众情绪状态的指令。
根据本公开的一个方面,所述幽默行为和最优幽默输出指令的选取的相关策略通过依照目标受众的不断交互得到的反馈信息进行相应调整。
根据本公开的一个方面,所述数据库包括笑话库、新闻库、动作库和歌曲库。
根据本公开的一个方面,所述概率分析包括所述幽默行为选取单元通过一个预先设定好的从情绪状态到幽默行为集的概率转移矩阵来计算得到幽默行为集的概率分布。
根据本公开的一个方面,所述幽默行为集包括{m1:“讲笑话”,m2:“念趣闻”,m3:“搞笑动作”,m4:“唱歌”,m5:“错误反馈”},其中,m5:“错误反馈”是指通过故意输出错误的反馈来让受众觉得开心。
根据本公开的一个方面,根据观测序列概率最大化的准则推断出隐藏状态变化序列是利用viterbi算法来实现的。
根据本公开的一个方面,所述第一hmm分析器的输出端连接至所述情绪状态hmm分析器的输入端。
根据本公开的一个方面,所述场景hmm分析器、所述受众表情hmm分析器、所述受众语音hmm分析器的输出端中的一个或多个连接至所述情绪状态hmm分析器的输入端。
根据本公开的一个方面,所述分析装置的输出端连接至所述决策装置的输入端。
根据本公开的一个方面,所述设备还包括第一收发器,所述第一收发器的输出端连接至所述分析装置的输入端,且所述决策装置的输出端连接至所述第一收发器的输入端。
根据本公开的一个方面,所述第一收发器的输出端连接至所述第一hmm分析器的输入端以及所述语音信号处理单元的输入端。
根据本公开的一个方面,所述第一收发器的输出端连接至所述场景hmm分析器、受众表情hmm分析器、受众语音hmm分析器的输入端中的一个或多个以及所述语音信号处理单元的输入端。
根据本公开的一个方面,所述第一收发器与机器人的第二收发器通信连接。
根据本公开的一个方面,本公开提供了一种基于云端的设备的操作方法。
根据本公开的一个方面,所述方法包括:利用所述设备中的第一收发器接收来自机器人的第二收发器的输入数据;利用所述设备中的分析装置中的语音信号处理单元从所述设备中的第一收发器接收受众语音输入信号,并对所述受众语音输入信号进行识别,根据识别结果输出标准指令;利用所述设备中的分析装置中的第一hmm分析器分别接收来自所述设备中的第一收发器的场景输入信号、受众表情输入信号以及受众语音输入信号作为第一hmm的可观测序列;由所述第一hmm分析器根据观测序列概率最大化的准则推断出第一hmm的隐藏状态变化序列并将所述隐藏状态变化序列输出至所述分析装置中的情绪状态hmm分析器,其中所述第一hmm的隐藏状态变化序列包括场景隐藏状态变化序列、受众表情隐藏状态变化序列和受众语音隐藏状态变化序列;由所述情绪状态hmm分析器接收所述场景隐藏状态变化序列、、受众表情隐藏状态变化序列、和受众语音隐藏状态变化序列作为情绪状态hmm的可观测序列,并根据观测序列概率最大化的准则来推断出情绪状态hmm的隐藏状态序列;由所述设备中的决策装置基于所述情绪状态hmm的隐藏状态序列选取幽默行为并整合幽默行为指令和所述标准指令作为最终输出指令。
根据本公开的一个方面,所述第一hmm分析器进一步包括以串行或并行的方式连接的场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器,其中所述场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器分别接收场景输入信号、受众表情输入信号和受众语音输入信号作为场景hmm、受众表情hmm和受众语音hmm的可观测序列并根据观测序列概率最大化的准则推断出场景hmm、受众表情hmm和受众语音hmm的隐藏状态变化序列,并且将所述场景hmm、受众表情hmm和受众语音hmm的隐藏状态变化序列发送至所述情绪状态hmm分析器。
根据本公开的一个方面,由所述设备中的决策装置基于所述情绪状态hmm的隐藏状态序列选取幽默行为并整合幽默行为指令和所述标准指令作为最终输出指令的步骤包括:所述设备中的决策装置中的幽默行为选取单元接收所述情绪状态hmm的隐藏状态序列、对所接收的情绪状态hmm的隐藏状态序列进行概率分析、选取幽默行为并将幽默行为指令输出至所述决策装置中的 整合单元;所述整合单元接收所述幽默行为指令以及所述标准指令并对所述幽默行为指令和所述标准指令进行整合以作为最终输出指令。
根据本公开的一个方面,所述整合包括:当所述幽默行为指令为“错误反馈”时,所述整合单元根据所述幽默行为指令修正所述标准指令,具体为不执行所述标准指令并由所述整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取一些其他表演表达幽默感。
根据本公开的一个方面,所述整合还包括:当所述幽默行为指令为“讲笑话”、“念趣闻”、“搞笑动作”、“唱歌”中的一者时,所述整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取最优幽默输出指令并将所述最优幽默输出指令和所述标准指令作为最终输出指令,其中,所述最优幽默输出指令为最匹配目标受众情绪状态的指令。
根据本公开的一个方面,所述幽默行为和最优幽默输出指令的选取的相关策略通过依照目标受众的不断交互得到的反馈信息进行相应调整。
根据本公开的一个方面,所述数据库包括笑话库、新闻库、动作库和歌曲库。
根据本公开的一个方面,所述概率分析包括所述幽默行为选取单元通过一个预先设定好的从情绪状态到幽默行为集的概率转移矩阵来计算得到幽默行为集的概率分布。
根据本公开的一个方面,所述幽默行为集包括{m1:“讲笑话”,m2:“念趣闻”,m3:“搞笑动作”,m4:“唱歌”,m5:“错误反馈”},其中,m5:“错误反馈”是指通过故意输出错误的反馈来让受众觉得开心。
根据本公开的一个方面,所述根据观测序列概率最大化的准则推断出隐藏状态变化序列是利用viterbi算法来实现的。
附图说明
在结合以下附图阅读本公开的实施例的详细描述之后,能够更好地理解本公开的上述特征和优点。在附图中,各组件不一定是按比例绘制,并且具有类似的相关特性或特征的组件可能具有相同或相近的附图标记。为了便于说明,在以下描述中将“交互型机器人”简称为“机器人”。
图1示出了hmm模型示意图。
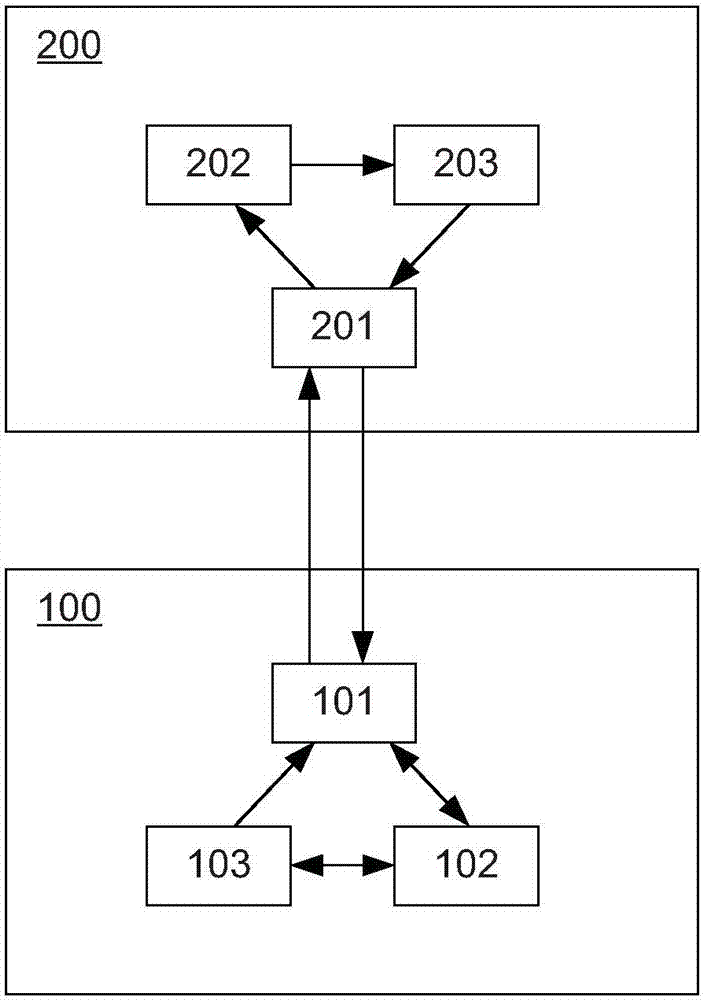
图2示出了根据本公开的实施例的基于云端的设备与机器人交互的结构示意图。
图3a-3c示出了根据本公开的实施例的基于云端的设备的分析装置的结构示意图。
图4示出了根据本公开的实施例的基于云端的设备的决策装置的结构示意图。
具体实施方式
以下结合附图和具体实施例对本公开作详细描述。注意,以下结合附图和具体实施例描述的诸方面仅是示例性的,而不应被理解为对本公开的保护范围进行任何限制。
图2示出了根据本公开的实施例的基于云端的设备200与机器人100交互的结构示意图。在图2中,机器人100包括收发器101、控制装置102和传感装置103。基于云端的设备200包括收发器201、分析装置202和决策装置203。如图2中所示,机器人100的收发器101与基于云端的设备200的收发器201通信连接。进一步,机器人100的收发器101和传感装置103分别与控制装置102交互连接,且传感装置103连接至收发器101。进一步,基于云端的设备200的收发器201连接至分析装置202、分析装置202连接至基于云端的设备200的决策装置203,且决策装置203连接至基于云端的设备200的收发器201。
根据本公开的一些实施例,机器人100的传感装置103可包括图像传感器和声音传感器,其中,图像传感器用于收集目标受众所处场景图像信号以及目标受众表情图像信号,且声音传感器用于收集目标受众语音信号。如图2中所示,传感装置103通过收发器101将所收集到的信息传输至基于云端的设备200,同时基于云端的设备200通过收发器201接收来自机器人100的输入信息。
图3a-3c示出了根据本公开的实施例的基于云端的设备200的分析装置202的结构示意图。在图3a中,基于云端的设备200的分析装置202包括第一hmm分析器202-0、情绪状态hmm分析器202-4以及语音信号处理单元202-5。在图3b-3c中,第一hmm分析器202-0可进一步包括场景hmm分 析器202-1、受众表情hmm分析器202-2、受众语音hmm分析器202-3,其中图3b中的场景hmm分析器202-1、受众表情hmm分析器202-2、受众语音hmm分析器202-3以并行方式连接,图3c中的场景hmm分析器202-1、受众表情hmm分析器202-2、受众语音hmm分析器202-3以串行方式连接。这里应当注意的是,本公开不限于附图中所示的连接方式。例如,场景hmm分析器202-1、受众表情hmm分析器202-2、受众语音hmm分析器202-3中的两者串行之后与剩余一者并行,或者其中的两者并行之后与剩余一者串行。三个hmm分析器的不同连接方式以及连接顺序变化均落在本公开的保护范围内。
结合图2和图3a-3c,机器人100的传感装置103每隔一个单位时间收集一次输入数据,并将连续二十个单位时间内收集到的数据通过收发器101和201传输到基于云端的设备200的分析装置202,该分析装置202中的第一hmm分析器202-0或者场景hmm分析器202-1、受众表情hmm分析器202-2和受众语音hmm分析器202-3分别接收来自收发器201的场景输入信号、受众表情输入信号以及受众语音输入信号。这里,第一hmm分析器202-0或者场景hmm分析器202-1、受众表情hmm分析器202-2和受众语音hmm分析器202-3从收发器201接收到的二十个场景输入信号、受众表情输入信号以及受众语音输入信号分别为对应的第一hmm或者场景hmm、受众表情hmm和受众语音hmm的可观测序列,其中第一hmm为针对场景输入信号、受众表情输入信号和受众语音输入信号所建立的通用hmm,并且场景hmm、受众表情hmm和受众语音hmm分别为针对场景输入信号、受众表情输入信号和受众语音输入信号所建立的hmm。
在一些实施例中,关于场景hmm的隐藏状态包括海岸、森林、沙漠、高山、泳池、厨房、卫生间、客厅、卧室等,关于受众表情hmm的隐藏状态包括感兴趣、高兴、惊讶、伤心、害怕、害羞、轻蔑、生气等。在一些实施例中,关于受众语音hmm,由受众语音hmm分析器所接收到的二十个受众语音输入信号为受众语音hmm的可观测序列,而由每个受众语音输入信号如何转变到下一个受众语音输入信号,即短时统计特征的动态特性为受众语音hmm的隐藏状态。
继续参照图2和图3a-3c,第一hmm分析器202-0、场景hmm分析器202-1、受众表情hmm分析器202-2和受众语音hmm分析器202-3针对相应的hmm可观测序列,根据观测序列概率最大化的准则推断出相应的隐藏状态的变化。
参照图2和图3a-3c,基于云端的设备200的分析装置202进一步包括情绪状态hmm分析器202-4,其中,分析装置202中的第一hmm分析器或者场景hmm分析器202-1、受众表情hmm分析器202-2和受众语音hmm分析器202-3中的一个或多个连接至情绪状态hmm分析器202-4,并且将分析得出的隐藏状态变化序列输出到情绪状态hmm分析器202-4中作为该情绪状态hmm分析器202-4的可观测序列。同样,根据观测序列概率最大化的准则来推断出情绪状态hmm的隐藏状态变化序列。
在一些实施例中,关于情绪状态hmm的隐藏状态包括生气、微愠、愤恨、不平、烦躁、敌意、忧伤、抑郁、忧郁、自怜、寂寞、沮丧、绝望、严重忧郁、焦虑、惊恐、紧张、关切、慌乱、忧心、警觉、疑虑、病态恐惧、病态恐慌、如释重负、满足、幸福、愉悦、兴味、骄傲、感官的快乐、兴奋、狂喜、极端的躁狂、认可、友善、信赖、和善、亲密、挚爱、宠爱、痴恋、震惊、讶异、惊喜、叹为观止、轻视、轻蔑、讥讽、排拒、愧疚、尴尬、懊悔、耻辱等。
在一些实施例中,根据观测序列概率最大化的准则推断出隐藏状态的变化是利用维特比算法(viterbialgorithm)实现的,该维特比算法提供了一种有效的计算方法来分析隐马尔科夫模型的观测序列,并捕获最可能的隐藏状态序列。
继续参照图3a-3c,基于云端的设备200的分析装置202进一步包括语音信号处理单元202-5,该语音信号处理单元202-5从收发器201接收受众语音输入信号,并对受众语音输入信号进行识别,根据识别结果将标准指令输出至决策装置203。
图4示出了根据本公开的实施例的基于云端的设备200的决策装置203的结构示意图。在图4中,决策装置203包括幽默行为选取单元203-1和整合单元203-2。结合图3a-3c和图4,分析装置202中的语音信号处理单元202-5的输出端连接至决策装置203中的整合单元203-2的输入端,情绪状态hmm 分析器202-4的输出端连接至决策装置203中的幽默行为选取单元203-1的输入端,幽默行为选取单元203-1的输出端连接至整合单元203-2的输入端,同时整合单元203-2的输出端连接至收发器201的输入端。
参照图3a-3c和图4,决策装置203中的幽默行为选取单元203-1接收来自分析装置202中的情绪状态hmm分析器202-4的输出。由于采用的是隐马尔科夫模型,因而通过情绪状态hmm分析器202-4分析得出的受众情绪状态是一个概率状态分布。幽默行为选取单元203-1对所接收的受众情绪状态概率分布进行概率分析。具体地,通过一个预先设定好的从情绪状态到输出幽默行为集的概率转移矩阵来计算得到幽默行为集的概率分布,并针对该概率分布对输出指令进行随机取样以作为最终的幽默指令类型。在一个实施例中,可采用蒙特卡洛(montecarlo)方法进行随机取样。蒙特卡洛方法是一种根据生成分布进行取样以让取样结果符合该分布的方法,由此,采用蒙特卡洛方法进行取样可保证输出的可变性。考虑到实用场景中机器人行为的实现难易程度,最终的输出指令分为标准反馈指令加上附加幽默行为。这里,幽默行为集可包括{m1:“讲笑话”,m2:“念趣闻”,m3:“搞笑动作”,m4:“唱歌”,m5:“错误反馈”}。幽默行为选取单元203-1将所选取的幽默行为指令发送至整合单元203-2,在整合单元203-2中,对从幽默行为选取单元203-1接收的幽默行为指令与从语音信号处理单元202-5接收的标准指令进行整合,随后通过收发器201将最终输出指令输出至机器人100。
其中,幽默行为集中的m5:“错误反馈”是指通过故意输出错误的反馈来让受众觉得开心。例如,当受众向机器人发出“过来”的指令时,标准的反馈指令是命令机器人往目标受众靠拢,如果幽默行为选取单元203-1所选取的幽默行为是“错误反馈”,则可以考虑不执行标准反馈并由整合单元203-2通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取一些其他表演表达幽默感,比如假装很生气地说“像我这种贵族可不是能随便使唤的”。对于其他的幽默行为,整合单元203-2通过结合受众语音输入信号搜索云端的数据库来选取最匹配当前受众所处的情绪状态下的最优幽默输出指令,同时,由于一些具体内容上的选取,还需要访问因特网来获取所需的信息。举例来说,如果幽默行为是“讲笑话”,则需要结合受众所处情绪状态选取最为匹配的笑 话库里的笑话。这里,可通过语音信号处理单元202-5向整合单元203-2发送受众语音输入信号。此外,整合单元203-2也可从收发器201直接接收受众语音输入信号。
在一些实施例中,所有这些幽默行为类型选取和内容匹配的相关策略可以通过依照目标受众的不断交互得到的反馈信息进行相应调整,从而实现“增强学习”的效果,从而达到最终实现一个和目标受众配合“默契”的有一定幽默特性的交互性机器人。
根据本公开的一个方面,本公开提供了一种基于云端的设备,其操作方法如下:
第一步,基于云端的设备的收发器接收来自机器人的收发器的输入数据,所述来自机器人的收发器的输入数据是由机器人的传感装置在连续二十个单位时间内收集到的;
第二步,基于云端的设备的分析装置中的语音信号处理单元从基于云端的设备的收发器接收受众语音输入信号,并对受众语音输入信号进行识别,根据识别结果将标准指令输出至基于云端的设备的决策装置中的整合单元;
第三步,基于云端的设备的分析装置中的第一hmm分析器分别接收来自所述设备中的收发器的场景输入信号、受众表情输入信号以及受众语音输入信号作为第一hmm的可观测序列,由所述第一hmm分析器根据观测序列概率最大化的准则推断出第一hmm的的隐藏状态变化序列并将所述隐藏状态变化序列输出至基于云端的设备的分析装置中的情绪状态hmm分析器,其中所述第一hmm的隐藏状态变化序列包括场景隐藏状态变化序列、受众表情隐藏状态变化序列和受众语音隐藏状态变化序列;
其中当所述第一hmm分析器包括以串行或并行的方式连接的场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器时,所述场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器分别接收来自基于云端的设备的收发器的场景输入信号、受众表情输入信号以及受众语音输入信号,这些输入信号分别为对应的hmm的可观测序列;场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器针对相应的hmm的可观测序列,根据观测序列概率最大化的准则推断出相应的隐藏状态变化序列并将这些隐 藏状态变化序列输出至基于云端的设备的分析装置中的情绪状态hmm分析器中;
第四步,基于云端的设备的分析装置中的情绪状态hmm分析器接收来自第一hmm分析器或者场景hmm分析器、受众表情hmm分析器和受众语音hmm分析器的隐藏状态变化序列作为其可观测序列,同时根据观测序列概率最大化的准则来推断出情绪状态hmm的隐藏状态序列;
第五步,基于云端的设备的决策装置中的幽默行为选取单元接收来自分析装置中的情绪状态hmm分析器的输出、通过一个预先设定好的从情绪状态到幽默行为集的概率转移矩阵来计算得到幽默行为集的概率分布、针对该概率分布对输出指令进行随机取样以作为最终的幽默指令类型并将所选取的幽默行为指令发送至整合单元;
第六步,整合单元对从幽默行为选取单元接收的幽默行为指令与从语音信号处理单元接收的标准指令进行整合,并通过收发器将最终输出指令输出至机器人;其中,对于“错误反馈”的幽默行为指令,整合单元根据该幽默行为指令修正标准指令,具体为不执行标准指令并由整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取一些其他表演表达幽默感;对于“讲笑话”、“念趣闻”、“搞笑动作”、“唱歌”的幽默行为指令,整合单元通过结合受众语音输入信号搜索云端的数据库和/或访问因特网来选取最优幽默输出指令并将该最优幽默输出指令和标准指令作为最终输出指令通过收发器输出至机器人,其中,所述最优幽默输出指令为最匹配目标受众情绪状态的指令,所述数据库包括笑话库、新闻库、动作库和歌曲库;
这里要注意的是,以上第二步和第三步是同步进行,不存在先后之分。
上文中已针对根据本公开的各实施例描述了本公开的多个方面,应当理解,以上各实施例仅是示例性而非限制性的,并且可组合以上多个实施例以形成新的替代实施例,或者可仅执行一个实施例的子集来实践本公开。
本领域技术人员将进一步领会,结合本文中所公开的实施例来描述的各种说明性逻辑块、模块、电路和算法步骤可实现为电子硬件、计算机软件、或这两者的组合。为清楚地说明硬件与软件的可互换性,各种说明性组件、框、模块、电路和步骤在上文中是以其功能性的形式来作出一般化描述的。此类功能 性是被实现为硬件还是软件取决于具体应用和施加于整体系统的设计约束。本领域技术人员对于每种特定应用可以用不同的方式来实现所描述的功能性,但是此类实现决策不应被视为背离本公开的范围。
结合本文所公开的实施例描述的各种说明性逻辑模块和电路可以用通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其他可编程逻辑器件、分立的门或晶体管逻辑、分立的硬件组件、或其设计成执行本文所描述功能的任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,该处理器可以是任何常规的处理器、控制器、微控制器、或状态机。处理器还可以被实现为计算设备的组合,例如dsp与微处理器的组合、多个微处理器、与dsp核心协作的一个或多个微处理器、或任何其他此类配置。
结合本文中公开的实施例描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中具体化。软件模块可驻留在ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可移动盘、cd-rom、或本领域中所知的任何其他形式的存储介质中。示例性存储介质耦合到处理器以使得该处理器能从/向该存储介质读取和写入信息。在替换方案中,存储介质可以被整合到处理器。处理器和存储介质可驻留在asic中。asic可驻留在用户终端中。在替换方案中,处理器和存储介质可作为分立组件驻留在用户终端中。
在一个或多个示例性实施例中,所描述的功能可在硬件、软件、固件或其任何组合中实现。如果在软件中实现为计算机程序产品,则各功能可以作为一条或更多条指令或代码存储在计算机可读介质上或经由其进行传送。计算机可读介质包括计算机存储介质和通信介质两者,其包括促成计算机程序从一地向另一地转移的任何介质。存储介质可以是能被计算机访问的任何可用介质。作为示例而非限定,此类计算机可读介质可包括ram、rom、eeprom、cd-rom或其他光盘存储、磁盘存储或其他磁存储设备、或能被用来携带或存储指令或数据结构形式的合意程序代码且能被计算机访问的任何其他介质。任何连接也被正当地称为计算机可读介质。
提供对本公开的先前描述是为使得本领域任何技术人员都能够制作或使 用本公开。对本公开的各种修改对本领域技术人员来说都将是显而易见的,且本文中所定义的普适原理可被应用到其他变体而不会脱离本公开的精神或范围。由此,本公开并非旨在被限定于本文中所描述的示例和设计,而是应被授予与本文中所公开的原理和新颖性特征相一致的最广范围。
- 还没有人留言评论。精彩留言会获得点赞!