基于口音瓶颈特征的声学模型自适应方法与流程
本发明属于语音识别技术领域,具体涉及一种基于口音瓶颈特征的声学模型自适应方法。
背景技术:
迄今为止,语音识别技术已经成为人机交互的重要入口,使用该技术的用户人数日益增长。由于这些用户来自五湖四海,口音千差万别,因而通用的语音识别声学模型很难适用于所有用户。因此,需要针对不同口音的用户,个性化定制相应的声学模型。目前,提取声纹特征的技术已经在说话人领域得到了广泛的应用,而说话人的声纹特征与说话人的口音有着千丝万缕的联系。虽然此前已经有不少学者通过提取声纹特征的技术来提取口音特征,然而这种技术并不能高层次地表征口音特征,而如何高层次地表征口音特征对个性化定制声学模型至关重要。
因此,本领域需要一种新的方法来解决上述问题。
技术实现要素:
为了解决现有技术中的上述问题,即为了能够实现针对不同口音的用户,进行个性化定制声学模型,本发明提供了一种基于口音瓶颈特征的声学模型自适应方法。该方法包括下列步骤:
S1、基于第一深度神经网络,以多个口音音频数据的声纹拼接特征作为训练样本,得到深度口音瓶颈网络模型;
S2、基于所述深度口音瓶颈网络,获取所述口音音频数据的口音拼接特征;
S3、基于第二深度神经网络,以多个所述口音音频数据的所述口音拼接特征作为训练样本,得到口音独立的基线声学模型;
S4、利用特定的口音音频数据的所述口音拼接特征对所述口音独立的基线声学模型的参数进行调整,生成口音依赖的声学模型。
优选地,在步骤S1中,获取所述声纹拼接特征的步骤包括:
S11、从口音音频数据中提取声学特征;
S12、利用所述声学特征提取说话人的声纹特征向量;
S13、融合所述声纹特征向量与所述声学特征,生成声纹拼接特征。
优选地,在步骤S1中,所述第一神经网络是深度前馈神经网络模型,以所述多个所述口音音频数据的声纹拼接特征对所述深度前馈神经网络模型进行训练,得到深度口音瓶颈网络。
优选地,步骤S2进一步包括:
S21、利用所述深度口音瓶颈网络模型提取所述口音音频数据的口音瓶颈特征;
S22、融合所述口音瓶颈特征与所述声学特征,得到所述口音音频数据的口音拼接特征。
优选地,步骤S21进一步包括:将所述口音音频数据的声纹拼接特征作为所述深度口音瓶颈网络模型的输入,利用前向传播算法得到该口音音频数据的口音瓶颈特征。
优选地,在步骤S3中,所述第二神经网络是深度双向长短时记忆循环神经网络,以多个所述口音拼接特征对所述深度双向长短时记忆循环神经网络进行训练,得到口音独立的深度双向长短时记忆循环神经网络的声学模型;
将所述口音独立的深度双向长短时记忆循环神经网络的声学模型作为口音独立的基线声学模型。
优选地,在步骤S4中,利用所述口音拼接特征对所述口音独立的基线声学模型的输出层的参数进行调整,生产口音依赖的声学模型。
优选地,在步骤S4中,对所述口音独立的基线声学模型的最后一个输出层的参数进行调整。
优选地,采用后向传播算法对所述口音独立的基线声学模型的输出层的参数进行调整。
通过采用本发明的基于口音瓶颈特征的声学模型自适应方法,具有以下有益效果:
(1)采用深度口音瓶颈网络提取的口音拼接特征具有更抽象,更通用的表达,能准确获取口音的高层次表征。
(2)利用口音拼接特征去对口音独立的基线声学模型的输出层进行自适应,每一种口音都有对应的输出层,共享隐层参数,能减少模型的存储空间。
(3)通过本发明的基于口音瓶颈特征的声学模型自适应方法,提高了带口音语音识别的准确率。
附图说明
图1是本发明的基于口音瓶颈特征的声学模型自适应方法的流程图;
图2是本发明实施例的整体流程图;
图3是本发明实施例的生成声纹拼接特征的流程图;
图4是本发明实施例的生成口音拼接特征的流程图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
参照图1,图1示出了本发明的基于口音瓶颈特征的声学模型自适应方法的流程图。本发明的方法包括以下步骤:
S1、基于第一神经网络模型,以多个口音音频数据的声纹拼接特征作为训练样本,得到深度口音瓶颈网络;
S2、基于所述深度口音瓶颈网络,获取所述口音音频数据的口音拼接特征;
S3、基于第二神经网络模型,以多个所述口音音频数据的所述口音拼接特征作为训练样本,得到口音独立的基线声学模型;
S4、利用特定的口音音频数据的所述口音拼接特征对所述口音独立的基线声学模型的参数进行调整,生成口音依赖的声学模型。
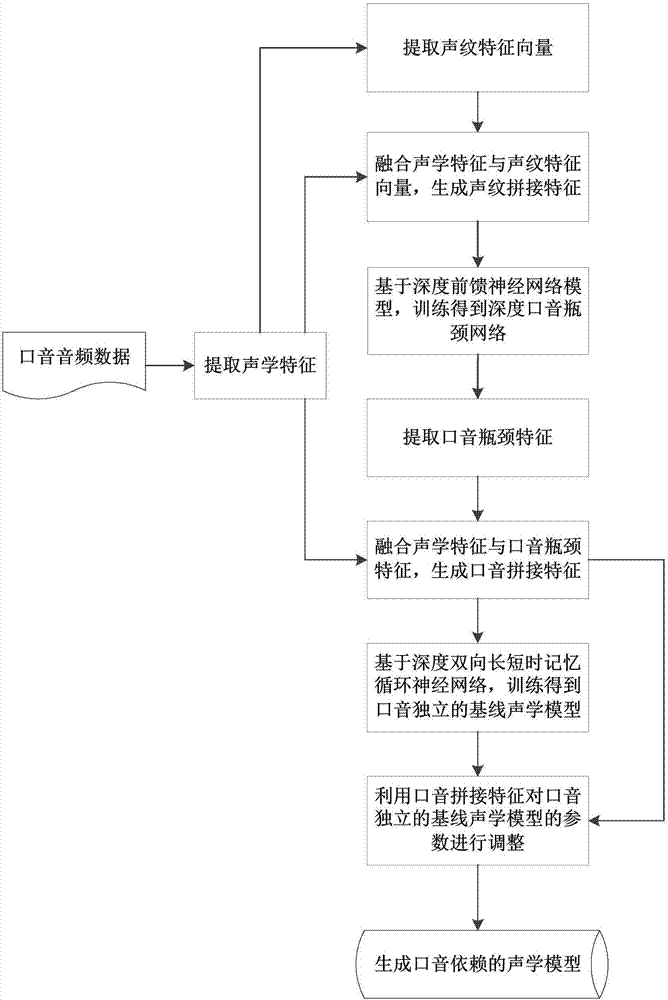
图2示出了2是本发明实施例的整体流程图。下面参照图2对本发明的方法进行详细说明。
在步骤S1中,获取所述声纹拼接特征的步骤包括:
S11、从口音音频数据中提取声学特征。具体地,该步骤中主要采用梅尔频谱特征或者梅尔倒谱特征。以梅尔倒谱特征为例,梅尔倒谱特征的静态参数可以为13维,对其做一阶差分和二阶差分,最终参数的维度为39维,然后利用这39维的特征做后续处理。
S12、利用所述声学特征提取说话人的声纹特征向量。具体地,利用该声学特征训练高斯混合模型-通用背景模型,进而利用该高斯混合模型-通用背景模型从所述声学特征中来提取每个人的声纹特征向量,且该声纹特征向量的维度为80维。
S13、融合所述声纹特征向量与所述声学特征,生成声纹拼接特征。如图3所示,在生产声纹拼接特征的过程中,将S11中提取的声学特征与S12中提取的声纹特征向量融合。具体地,将每个人的声纹特征向量拼接到每帧的声学特征上,从而生成声纹拼接特征。
在步骤S1中,第一神经网络可以是深度前馈神经网络模型,以生成的声纹拼接特征对该深度前馈神经网络模型进行训练,得到深度口音瓶颈网络。在本实施例中,该深度口音瓶颈网络的最后一个隐层节点为60,比其他隐层节点数少,其他隐层节点可为1024或者2048。在本实施例中,该深度前馈神经网络模型的训练准则为交叉熵,训练方法为后向传播算法。深度前馈神经网络模型的激活函数可以为双弯曲激活函数或者双曲线正切激活函数,该网络的损失函数为交叉熵,其属于本领域已知技术,在此不再详细描述。
在步骤S2中,获取口音拼接特征的步骤包括:
S21、利用所述深度口音瓶颈网络提取所述口音音频数据的口音瓶颈特征;
S22、融合所述口音瓶颈特征与所述声学特征,得到所述口音音频数据的口音拼接特征。
具体而言,将步骤S1中得到的深度口音瓶颈网络视为一个特征提取器,以步骤S13中生成的声纹拼接特征作为所述深度口音瓶颈网络的输入,利用前向传播算法得到该口音音频数据的口音瓶颈特征。在本实施例中,该口音瓶颈特征为60维。如图4所示,在生产口音拼接特征的过程中,在帧级别将S21提取的口音瓶颈特征与S11提取的声学特征进行融合,从而生成口音拼接特征。
在步骤S3中,第二神经网络可以是深度双向长短时记忆循环神经网络,以步骤S2中得到的口音拼接特征对该深度双向长短时记忆循环神经网络进行训练,即将S2中得到的口音拼接特征输入该深度双向长短时记忆循环神经网络,其输出层的标签为声韵母。得到口音独立的深度双向长短时记忆循环神经网络的声学模型,并将该口音独立的深度双向长短时记忆循环神经网络的声学模型作为口音独立的基线声学模型。在本实施例中,深度双向长短时记忆循环神经网络的训练准则为联结时序分类函数,训练方法为后向传播算法。深度双向长短时记忆循环神经网络既能记忆输入特征的历史信息,又能预测输入特征的未来知识,其采用三个控制门来实现记忆和预测的功能,这三个控制门分别为输入门,遗忘门和输出门。深度双向长短时记忆循环神经网络属于本领域已知技术,在此不再进行详细描述。
在步骤S4中,利用步骤S2中得到的口音拼接特征对步骤S3中得到的口音独立的基线声学模型的输出层(一般为最后一个输出层)的参数进行微调,生产口音依赖的声学模型。具体地,将每种口音对应的口音拼接特征作为该口音独立的基线声学模型的输入,每种口音对应一个口音依赖的输出层,隐层为所以口音共享。进一步,采用后向传播算法对口音独立的基线声学模型进行参数微调。由于口音独立的基线声学模型是基于双向的长短时记忆神经网络模型,隐层最后生成的口音依赖的声学模型也是基于深度双向长短时记忆循环神经网络模型,其输出层的标签为声韵母,其结合发音词典和语言模型即可识别出音频数据对应的文本。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!