一种基于人脸识别的主动语音助手的制作方法
本实用新型涉及人脸识别领域,尤其是涉及一种基于人脸识别的主动语音助手。
背景技术:
随着汽车消费的普及,人们对汽车产品驾乘时的舒适度要求越来越高。整车系统增加了越来越多的娱乐功能,导致一些驾驶安全的隐患。语音助手的引入在一定程度上缓解了这种情况,进而在今天的汽车行业越来越流行。驾驶员只需要说出相关语音指令,就可以操控车机,避免视线偏离前方道路或手动操作等分散注意力的安全隐患。
但是,现阶段市场上的语音助手都是被动性的。语音助手会长时间保持沉默,需要驾驶员说专用指令去唤醒它。它的行为更像是一个指令解释器,而不是一个语音助手,因为它对驾驶员的了解程度很低,这样的语音助理还处于初级阶段有很多待提升的方面。
技术实现要素:
本实用新型的目的是针对上述问题提供一种基于人脸识别的主动语音助手。
本实用新型的目的可以通过以下技术方案来实现:
一种基于人脸识别的主动语音助手,所述语音助手包括外接设备、云端服务器和中央控制模块,所述中央控制模块分别与外接设备和云端服务器连接,所述外接设备包括摄像头和麦克风,所述摄像头和麦克风均安装于车上并与中央控制模块连接。
所述外接设备还包括扬声器,所述扬声器均安装与车上并与中央控制模块连接。
所述云端服务器包括人脸识别芯片和语音识别芯片,所述人脸识别芯片和语音识别芯片均与中央控制模块连接。
所述中央控制模块包括信号传输单元和控制器,所述信号传输单元分别与外接设备和云端服务器连接,所述控制器与信号传输单元连接。
所述信号传输单元包括信号接收器和滤波器,所述信号接收器分别与云端服务器和滤波器连接,所述滤波器与控制器连接。
与现有技术相比,本实用新型具有以下有益效果:
(1)云端服务器中设有人脸识别芯片,可以对驾驶员进行面部识别,并根据面部识别的结果主动发起和驾驶员的交互,主动性能高。
(2)云端服务器中设有语音识别芯片,可以对驾驶员的语音指令进行分析并进行反馈,与面部识别进行结合,提高了整个语音助手的交互性能。
(3)用户可以通过麦克风对语音助手发出的主动指令进行回答,大大简化驾驶员的输出指令的复杂程度。
(4)人脸识别芯片比起传统的人脸识别装置,除了可以识别驾驶员的身份外,可以对驾驶员的面部表情进行捕捉,继而分析驾驶员的注意力状态和情绪状态,在驾驶员注意力不集中或疲劳驾驶时及时提醒驾驶员,提高了驾驶的安全性。
附图说明
图1为本实用新型的结构示意图;
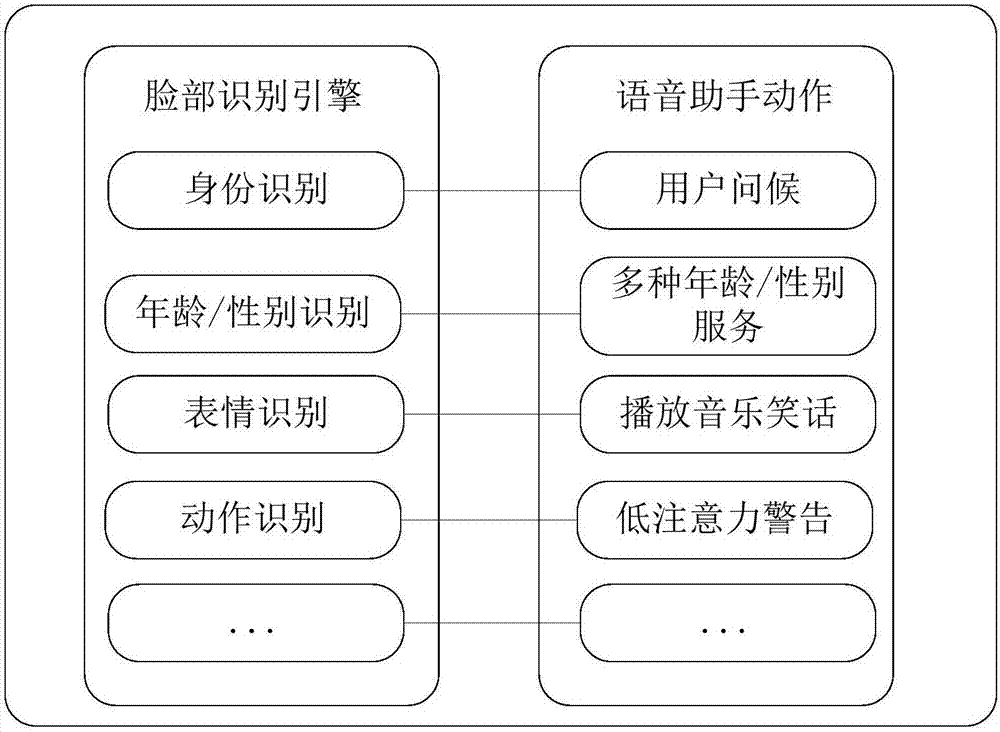
图2为脸部识别信息和指令动作的对应示意图;
其中,1为中央控制模块,2为云端服务器,3为扬声器,4为摄像头,5为麦克风。
具体实施方式
下面结合附图和具体实施例对本实用新型进行详细说明。本实施例以本实用新型技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本实用新型的保护范围不限于下述的实施例。
如图1所示,为基于人脸识别的主动语音助手,包括:外接设备,用于采集驾驶员的脸部识别信号和声音信号,同时根据操作指令进行相关动作;云端服务器2,用于分析脸部识别信号,判断驾驶员的状态,并分析语音信号,判断驾驶员发出的指令;中央控制模块1,用于将外接设备采集到的脸部识别信号和声音信号传输至云端服务器2,并根据云端服务器2的分析结果向外接设备发送操作指令。
其中,外接设备包括:信号采集设备,用于采集驾驶员的脸部识别信号和声音信号,并传输至中央控制模块1;扬声器3,用于根据中央控制模块1的操作指令进行相关动作。信号采集设备包括:摄像头4,用于采集驾驶员的脸部识别信号并传输至中央控制模块1;麦克风5,用于采集驾驶员的声音信号并传输至中央控制模块1。
云端服务器2包括:人脸识别芯片,用于分析脸部识别信号,判断驾驶员的状态,并将判断结果发送至中央控制模块1;语音识别芯片,用于分析语音信号,判断驾驶员发出的指令,并将判断结果发送至中央控制模块1。
中央控制模块1包括:信号传输单元,用于接收外界设备采集到的脸部识别信号和声音信号,并传输至云端服务器2;主控单元,用于根据云端服务器2反馈的分析结果,发送操作指令至外接设备。
上述语音助手在工作时,由摄像头4(本实施例采用高分辨率摄像头)采集脸部识别视频信号后连接到中央控制单元,再传输到云端服务器2上的人脸识别芯片,人脸识别芯片分析信号后将分析结果反馈至中央控制单元,中央控制单元连接扬声器3发出“你好”指令,用户通过麦克风5发出控制指令,最后连接车载娱乐设备完成控制,具体涉及到的工作原理如下:
高分辨率摄像头会捕捉采集到驾驶员的脸部表情信息,比如当前驾驶者是男性或女性,表情是愉悦或者郁闷的。中央控制模块1会从高分辨率摄像头模块获取到视频流,中央控制模块1将获取到的视频流发送到云端服务器2上(或者是本地存储卡)的人脸识别芯片进行解析;人脸识别芯片分析发送过来的视频流中驾驶员的脸部信息,然后反馈结果到中央控制单元;中央控制模块1控制扬声器3向驾驶员说出“你好”指令,根据识别到的结果信息给出一些建议或者警告,比如识别到欢乐的表情,播放一些轻松的音乐;识别到的是四十岁左右的中年男性会给出一些财经类的服务,而识别到的年轻女性时会给出当前流行时尚资讯服务,具体的对应关系如图2所示,比如当语音助手给出“播放歌曲”的指令后,用户反馈给麦克风5,说出类似于“播放刘德华的歌”的指令,然后中央控制模块1接受到用户指令后解析进行下一步的操作;身份识别对应着用户问候;年龄/性别识别对应着多种年龄/性别服务的指令动作;表情识别对应着播放轻松音乐,讲笑话等指令操作。
- 还没有人留言评论。精彩留言会获得点赞!