基于二值神经网络声学模型的语音识别系统的制作方法
本发明涉及的是一种信息处理领域的技术,具体是一种基于二值神经网络声学模型的语音识别系统。
背景技术:
现有的用于声学模型建模的神经网络(包括但不限于DNN、CNN、RNN),具有百万甚至数以亿计的网络权重,并且每个权重都是以32位浮点数进行存储,需要的大量的存储和内存才能运行。对于通常的神经网络声学模型,参数量很大就意味着计算量也很大,对设备计算能力的要求很高。对于通常的神经网络声学模型,需要使用大量语音数据进行训练模型,即使有大量的计算资源,训练时间也很长。
在采用32位浮点数作为网络权重的数据类型,在现有的硬件(如CPU,Central Processing Unit,中央处理器,GPU,Graphic Processing Unit,图形处理器)和软件(MKL,英特尔公司专门针对矩阵及其他数学运算的计算加速库,cuDNN,英伟达公司专门针对深度学习的GPU计算加速库)上,在处理大规模数据的情况下,深度神经网络模型速度还不够快。
技术实现要素:
本发明针对现有技术中模型训练速度较慢,且无法通过利用CPU或GPU进行位运算加速等缺陷,提出一种基于二值神经网络声学模型的语音识别系统,使用了二值替换传统的32位浮点数,使得模型的存储和内存占用大幅下降;使用的二值神经网络在计算上可以充分使用硬件指令进行加速运算,以前只能在服务器上使用多个GPU进行计算的模型现在可以在移动设备的CPU上运行;并且本发明在进行模型训练时得益于二值神经网络的加速,模型训练时间也能大幅缩短。
本发明是通过以下技术方案实现的:
本发明涉及一种面向语音识别的二值神经网络声学模型的实现方法,使用二值神经网络对隐马尔科夫模型(HMM)的观测概率分布进行建模,并采用提取后的语音特征进行训练,从而得到声学模型。
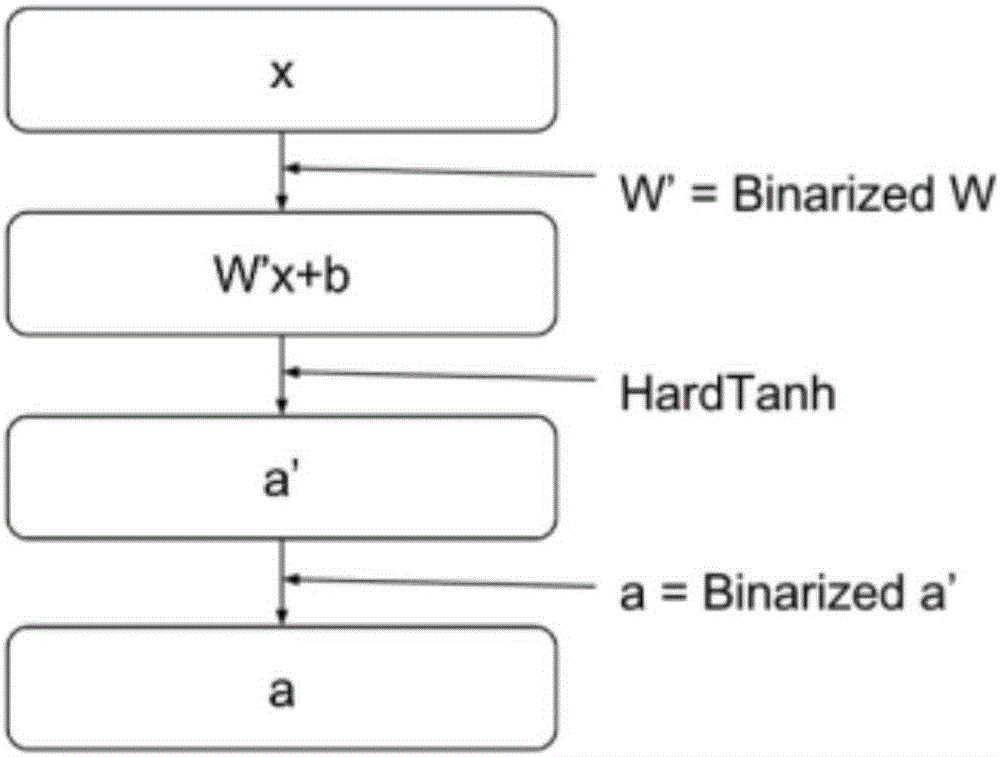
所述的二值神经网络为递归神经网络、卷积神经网络或深度前馈神经网络,其具体包括:依次连接的输入层、至少两个隐层以及输出层,其中:每个隐层对输入向量进行非线性处理后输出。本发明中的隐层对输入向量x以及网络权重W均进行二值化处理。
所述的二值化处理是指:当输入不大于零时输出为-1,否则输出为1。
所述的非线性处理是指:当输入小于-1时输出为-1,当输入大于1时输出为1,其他情况下输入等于输出。
为了加速深度神经网络处理速度,优选将多个输入向量合并成一个矩阵作为输入进行运算,则二值神经网络的输出为矩阵形式。通常情况下,网络大部分运算时间花费在矩阵乘法上。
所述的计算,采用但不限于硬件指令实现,如英特尔CPU的popcnt(),英伟达GPU的__popcll()。
所述的特征是指:将音频(一般是wav文件)经过分帧,即切成多个相邻两段之间有重叠的小段,再在这些小段上应用数学变换(如傅里叶变换),每一段语音就变成了特征,提取过的特征被用作语音识别系统的输入。
所述的隐马尔科夫模型包含多个状态、状态转移概率分布(状态转移矩阵)和观测概率分布(使用GMM,即高斯混合模型进行建模),其中:一个语音音素对应一个HMM,而一个HMM一般包含多个状态。
所述的音素是指:根据语音的自然属性划分出来的最小语音单位,如按照The CMU Pronouncing Dictionary的音素划分规范,英文单词cat所对应的发音因素序列为K AE T(来源http://www.speech.cs.cmu.edu/cgi-bin/cmudict)。
所述的训练是指:使用事先从音频中提取的特征,计算与语音特征数据及文本匹配的隐马尔可夫模型的参数,即状态转移概率分布和观测概率分布。
本发明涉及上述方法得到的二值神经网络声学模型的语音识别系统,包括:采集模块、特征提取模块、训练模块和识别模块,其中:采集模块在离线过程向特征提取模块输出训练音频和对应的文本,在在线测试过程向特征提取模块输出原始音频,特征提取模块分别向训练模块输出训练音频的特征文件和对应标签,向识别模块输出原始音频的特征文件,训练模块使用提取的特征和标签训练二值神经网络声学模型并将训练后的二值神经网络声学模型输出至识别模块,识别模块通过该模型对原始音频的特征文件进行识别。
所述的识别是指:识别模块对原始音频的特征文件使用隐马尔可夫模型进行计算,得出最大概率的对应隐藏状态序列,从而得出音素序列,进一步得到音频对应的文本。
技术效果
与现有其他神经网络加速方案有将使用32位浮点数格式的训练好的神经网络的每个网络权重使用2位或者4位近似,减小模型体积和运算量。本发明在训练和测试模型上,二值神经网络相对于传统神经网络要快得多,能大幅节省研究人员的时间。
相比于其他神经网络加速方案,二值神经网络体积更小,因此硬件设备的cache(CPU或者GPU核心的高速缓存)利用率要更高,减少了从内存重复载入数据的次数,从而更省电。
相比于其他神经网络加速方案,二值神经网络因其体积小,速度快,更适合用于移动设备上,可以用来开发语音识别相关的本地mobile app(移动设备的应用程序),应用范围更广。
附图说明
图1为神经网络示意图;
图2为本发明二值神经网络的每个隐层示意图;
图中:Binarize表示二值化,HardTanh表示非线性变换;
图3为本发明语音识别系统结构示意图。
具体实施方式
如图1所示,本实施例所使用的二值神经网络包括:依次连接的输入层、隐层以及输出层,其中:每个隐层对输入向量进行非线性处理后输出。
如图2所示,可能将本发明中用来图示说明的二值神经网络结构中的非线性变换HardTanh(例如)替换为其他的非线性函数如Sign(符号函数)。不同类型的非线性变换对神经网络模型的影响不同,但是某些情况下可以取得类似的效果,所以这种替代是可能发生的。
由于在神经网络的运算中矩阵乘法耗时最多,通常在80%以上,所以矩阵乘法的加速对整个神经网络运算的加速尤为重要。
当函数自变量为向量或者矩阵时,对向量或者矩阵每个元素分别做这种变换。采用这种结构之后,二值神经网络的隐层的输入和输出都经过了二值化,矩阵运算Wx(或W‘x)实际上可以转化为位运算操作,从而可以充分利用Intel CPU的popcnt()指令或者NVIDIA GPU的__popcll()指令进行加速计算。
对于二值化矩阵运算的加速,矩阵中一行和一列的乘法可以用以下高效的硬件指令a*b=popcnt(xnor(a,b))进行替代,其中popcnt是一种位运算,用来计算一个整数的二进制表示中1的个数,xnor真值表如下所示:
需要注意的是二值化不仅仅包含将权重转化为{-1,1}这种表示,为了在计算机上方便实施,还可能使用{0,1}这种表示,{-1,1}和{0,1}这两种表示在进行矩阵运算中一行和一列的乘法时,只相差一个常数,因此在下文中这两种表示可以互换。
以a=(1,1,0,1),b=(1,0,1,1)为例,传统计算方法为:a*b=1*1+1*0+0*1+1*1=2,需要进行4次乘法和3次加法操作,需要指令数至少为7。
而使用二值化网络模型后,可以将a和b看作是两个整数的2进制表示,从而使用位运算对这两个整数进行操作,c=xnor(a,b)=(1,0,0,1),popcnt(c)=2,只需要2次硬件指令。
考虑到实际模型中,由于权重都是二值表示,64个权重可以使用1个64位整数表示,所以计算加速比相对于例子中a*b的更大。
有如下64个网络权重:
1,0,1,0,1,0,1,1,0,1,0,1,0,1,0,0,1,0,1,0,1,0,0,1,1,0,0,0,1,1,0,0,1,1,1,0,1,0,1,1,0,0,0,1,1,1,1,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,可以将其看作是一个64位整数的二进制表示,而这个64位整数是12345678901234567890。
在GPU上的矩阵乘法实验结果显示,两个大小为(8192,8192)的矩阵相乘,使用二值化表示和GPU硬件指令__popcll(),对比于使用32位浮点数表示和使用英伟达cuDNN加速库运算,在进行矩阵乘法时速度能达3倍以上,相对于未优化过的矩阵乘法基线速度能达20多倍以上。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!