一种声纹识别的方法及装置与流程
本发明属于身份识别技术领域,尤其涉及一种声纹识别的方法及装置。
背景技术:
声纹识别是指根据声音所包含的说话人的生物特征,识别说话人的一种身份识别技术。由于声纹识别具有安全可靠性,使其可在需要进行身份识别的安全性保护领域和个性化应用场合中使用。例如,在移动支付领域,通过识别某段语音是否是目标说话人所说的,实现说话人的确认,进而使得只有具有权限的目标说话人才可以登录支付系统,并完成支付。
但是,在声纹识别的过程中,当身份识别失败时,即说话人并不是具有权限的目标说话人时,并不能进行下一步的处理,使得当有人模仿目标说话人的声音以实现通过冒用目标说话人的身份登录支付系统,对支付系统造成破坏时,不能对冒用目标说话人身份的人进行预警,导致降低支付系统的安全性。
技术实现要素:
有鉴于此,本发明的目的在于提供一种声纹识别的方法及装置,以解决现有技术中存在的无法对冒用目标说话人的说话人进行预警,以防止对支付系统造成破坏进而降低支付系统安全性的问题。
技术方案如下:
本发明提供一种声纹识别的方法,包括:
采集声音信息;
利用声纹模型对所述声音信息进行声纹识别,得到所述声音信息的声纹特征信息;
计算所述声纹特征信息与预警声纹特征信息之间的相似度;其中,所述预警声纹特征信息是认证失败后存储的声纹特征信息;
根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;
判断所述声纹特征信息是预警声纹特征信息,则发出警告。
优选地,所述采集声音信息包括:
采集语音信息;
滤除所述语音信息中的环境信息,得到有效声音信息。
优选地,所述计算所述声纹特征信息与预警声纹特征信息之间的相似度包括:
利用最小哈希算法,计算所述声纹特征信息与预警声纹特征信息之间的相似度。
优选地,所述根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息包括:
判断所述相似度是否超过预设阈值。
优选地,判断所述声纹特征信息是否是预警声纹特征信息之后,还包括:
判断所述声纹特征信息不是预警声纹特征信息,则对所述声纹特征信息进行身份认证。
本发明还提供一种声纹识别的装置,包括:
采集单元,用于采集声音信息;
识别单元,用于利用声纹模型对所述声音信息进行声纹识别,得到所述声音信息的声纹特征信息;
计算单元,用于计算所述声纹特征信息与预警声纹特征信息之间的相似度;其中,所述预警声纹特征信息是认证失败后存储的声纹特征信息;
判断单元,用于根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;
报警单元,用于所述判断单元判断所述声纹特征信息是预警声纹特征信息时,发出警告。
优选地,所述采集单元包括:
采集子单元,用于采集语音信息;
滤除子单元,用于滤除所述语音信息中的环境信息,得到有效声音信息。
优选地,所述计算单元为:
利用最小哈希算法,计算所述声纹特征信息与预警声纹特征信息之间的相似度。
优选地,所述判断单元为:
判断所述相似度是否超过预设阈值。
优选地,还包括:
认证单元,用于所述判断单元判断所述声纹特征信息不是预警声纹特征信息时,对所述声纹特征信息进行身份认证。
与现有技术相比,本发明提供的上述技术方案具有如下优点:
从上述技术方案可知,本申请中通过采集声音信息,利用声纹模型对声音信息进行声纹识别,得到所述声音信息的声纹特征信息;计算所述声纹特征信息与预警声纹特征信息之间的相似度;根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;判断所述声纹特征信息是预警声纹特征信息,则发出警告。当采集到的声音信息时预警声纹特征信息时,确定当前说话者为冒用目标说话人身份的说话者,不仅认证失败而且发出警告,且后续仍然存在冒用目标说话人身份的行为时,会继续发出警告,实现了对冒用目标说话人的事前预防,事中警告,事后跟踪确认的功能,提高了支付系统的安全性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种声音识别的方法的流程图;
图2是本发明实施例提供的另一种声音识别的方法的流程图;
图3是本发明实施例提供的一种声音识别的装置的结构示意图;
图4是本发明实施例提供的另一种声音识别的装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例公开了一种声纹识别的方法,应用在需要进行身份识别的系统中,例如支付系统,参见图1,该实施例包括以下步骤:
s101、采集声音信息;
利用采集设备采集声音信息。其中,采集设备可以为安装有需要进行身份识别的系统的电子设备上具备的设备。以安装有支付系统的移动终端为例,移动终端可以为手机,采集设备可以为手机上的话筒、麦克风。
采集到的信息包括说话人朗读随机生成的字符、字符串或者数字的语音,或者说话人随意说的一段语音。
s102、利用声纹模型对所述声音信息进行声纹识别,得到所述声音信息的声纹特征信息;
声纹模型为预先利用足够多的样本训练后得到的声纹模型。声纹模型通过对采集到的声音信息进行分析,可以得到采集到的声音信息的声纹特征信息。其中,声纹特征信息包括倒频谱、共振峰、基音和反射系数等能够反映说话者声纹特性的信息。
s103、计算所述声纹特征信息与预警声纹特征信息之间的相似度;其中,所述预警声纹特征信息是认证失败后存储的声纹特征信息;
本实施例中以支付系统为例说明,支付系统中预先存储了与目标说话者对应的目标声纹特征信息,其中,目标声纹特征信息是通过声纹模型分析得到的,目标说话者为具有访问权限的用户。具有访问权限的用户可以为多个,为了区分不同的用户,为每个用户设置唯一标识其身份的标识,标识可以为身份证号、姓名或者手机号。
在利用本实施例公开的声纹识别方法对采集到的声音进行识别的过程为:采集到声音信息后,利用声纹模型对采集到的所述声音信息进行声纹识别,得到采集到的所述声音信息的声纹特征信息;计算得到的声纹特征信息分别与预先存储在系统中的与目标说话者对应的目标声纹特征信息之间的相似度;判断计算出的相似度中是否存在大于认证阈值的相似度,若存在大于认证阈值的相似度,则计算得到此相似度的目标声纹特征信息对应的目标说话者就是发出采集到的声音信息的说话者,即认证通过。
若存在想要冒用目标说话者的身份,进而实现登录支付系统,对支付系统造成破坏的说话者时,冒用目标说话者身份的说话者发出的声音被采集设备采集到,并通过声纹模型进行分析,得到声纹特征信息,由于声纹特征信息必然与预先存储的目标说话者的目标声纹特征信息是不同的,在计算冒用目标说话者身份的说话者的声纹特征信息与目标声纹特征信息之间的相似度时,相似度不能达到认证阈值,进而不能认证通过,即认证失败。
通常情况下,冒用目标说话者的身份的说话者在一段时间内会多次尝试冒用身份以登录系统,因此当在一段时间内认证失败的声纹特征信息中,相同或相似的声纹特征信息出现的次数达到设定值时,会存在此声纹特征信息,将此声纹特征信息确定为预警声纹特征信息,即此声纹特征信息对应的说话者为冒用目标说话者身份的,想要蓄意破坏系统的人。其中,次数的设定值较小时,会导致将认证失败的目标说话人误判断为蓄意破坏系统的人,次数的设定值较大时,会导致允许蓄意破坏系统的人多次尝试登录系统,进而降低系统的安全性。因此,在设置次数的设定值时需要综合考虑实际情况进行合理的设置。
系统中不仅预先存储了与目标说话者对应的目标声纹特征信息,而且在识别过程中,通过对认证失败的声纹特征信息进行处理,可以获知认证失败的声纹特征信息是否是与冒用目标说话者身份,想要蓄意破坏系统的人对应的。当确定认证失败的声纹特征信息是与冒用目标说话者身份,想要蓄意破坏系统的人对应,则存储此认证失败的声纹特征信息,将其作为预警声纹特征信息。
由于系统中存储有与目标说话者对应的目标声纹特征信息,还存储有预警声纹特征信息,因此,在得到声纹特征信息后,先计算得到的声纹特征信息与预警声纹特征信息之间的相似度,通过计算两者之间的相似度确定得到的声纹特征信息是否是预警声纹特征信息,即是否是由冒用目标说话者身份,想要蓄意破坏系统的人发出的声音。只有确定得到的声纹特征信息不是预警声纹特征信息,即并不是由冒用目标说话者身份,想要蓄意破坏系统的人发出的声音,才将得到的声纹特征信息与目标声纹特征信息进行比对,即计算相似度,进而确定是由哪个目标说话者发出的声音。
s104、根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;
判断所述声纹特征信息是预警声纹特征信息,则执行步骤s105;
判断所述声纹特征信息不是预警声纹特征信息,则执行步骤s106;
判断所述声纹特征信息是预警声纹特征信息,则说明声纹特征信息是与冒用目标说话者身份,想要蓄意破坏系统的人对应的,即采集到的声音信息是由冒用目标说话者身份,想要蓄意破坏系统的人发出的;
判断所述声纹特征信息不是预警声纹特征信息,则说明声纹特征信息不是与冒用目标说话者身份,想要蓄意破坏系统的人对应的,但是具体是否与目标说话者对应,并且与哪个目标说话者对应,还需要进一步确认。
s105、发出警告;
通过发出警告,可以实现对冒用目标说话者身份,想要蓄意破坏系统的人的警告。
本实施例中需要身份识别的系统中,例如支付系统中,虽然可以识别出认证失败的声纹特征信息是由冒用目标说话者身份的说话者发出的,并发出了警告,但是,支付系统并不能通过此认证失败的声纹特征信息识别出说话者的具体身份。
针对此,在发出警告后,还可以包括将是预警声纹特征信息的声纹特征信息发送至其他的身份认证系统中,例如全国公安系统中,用于从其他的身份认证系统中存储的声纹特征信息与说话者之间的数据库中查找预警声纹特征信息对应的说话者,通过利用其他的身份认证系统实现对预警声纹特征信息的说话者的身份识别,进而实现了事后跟踪确认的目的。
s106、对所述声纹特征信息进行身份认证。
进行身份认证的实现方式为:分别计算所述声纹特征信息与预先存储在系统中的每个与目标说话者对应的目标声纹特征信息之间的相似度;判断计算出的相似度中是否存在大于认证阈值的相似度,若存在大于认证阈值的相似度,则计算得到此相似度的目标声纹特征信息对应的目标说话者就是发出采集到的声音信息的说话者,完成身份认证;若不存在大于认证阈值的相似度,则说明声纹特征信息并不是与目标说话者对应的或者没有识别出是与哪个目标说话者对应,身份认证失败。
从上述技术方案可知,本实施例中通过采集声音信息,利用声纹模型对声音信息进行声纹识别,得到所述声音信息的声纹特征信息;计算所述声纹特征信息与预警声纹特征信息之间的相似度;根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;判断所述声纹特征信息是预警声纹特征信息,则发出警告。当采集到的声音信息时预警声纹特征信息时,确定当前说话者为冒用目标说话人身份的说话者,不仅认证失败而且发出警告,且后续仍然存在冒用目标说话人身份的行为时,会继续发出警告,实现了对冒用目标说话人的事前预防,事中警告,事后跟踪确认的功能,提高了支付系统的安全性。
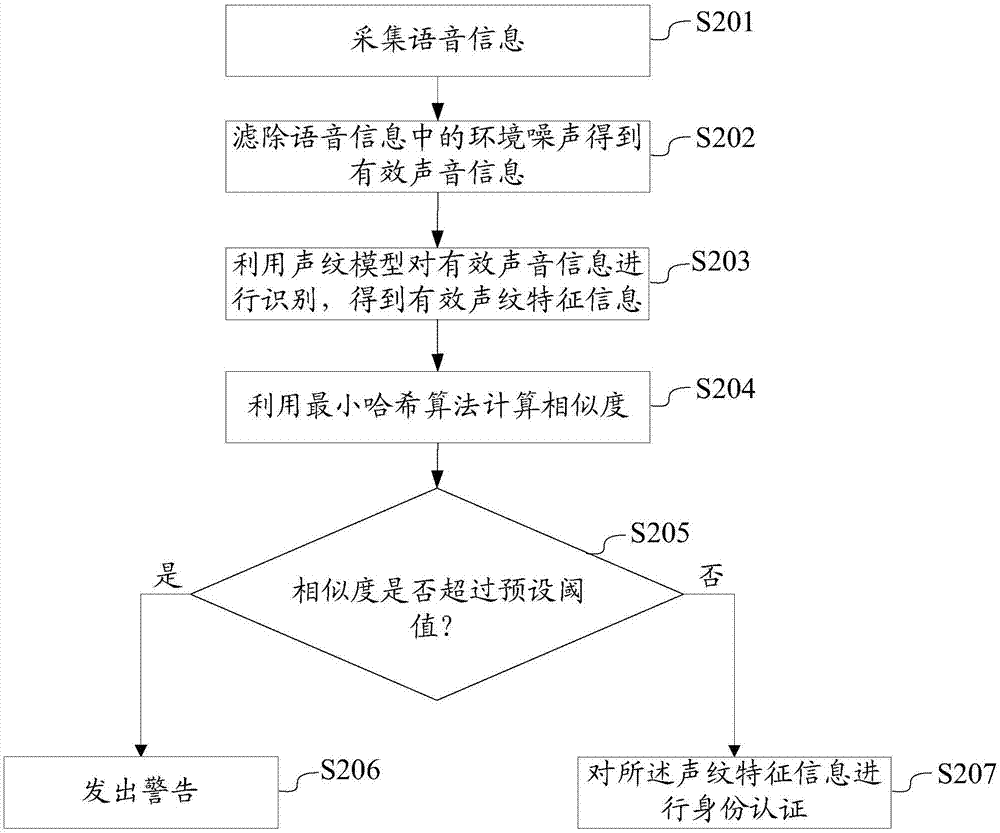
本实施例公开了另一种声纹识别的方法,参见图2,该实施例包括以下步骤:
s201、采集语音信息;
利用采集设备采集用户的语音信息。当用户在环境中朗读随机生成的字符、字符串或者数字,或者说话人随意说一段语音时,采集到的语音信息中包括环境噪声。
s202、滤除所述语音信息中的环境噪声,得到有效声音信息;
在与采集语音信息的相同地点,在采集到语音信息后及时采集环境噪声,使得采集环境噪声的时间尽量与采集语音信息的时间接近,进而保证采集到的环境噪声与采集到的语音信息中包括的环境噪声相同。
采集到环境噪声后,通过滤波的方式将语音信息中包括的环境噪声滤除,得到有效地声音信息。
在其他实施例中,在通过滤除环境噪声的方式得到有效地声音信息后,还包括对有效地声音信息进行分割,得到多个一定时间窗的语音段;然后对得到的多个语音段进行筛选,选择出优质的多个语音段。利用声纹模型对多个优质语音段的集合进行识别。
可以理解的是,在对建立的声纹模型进行训练时,也可以将对采集到的语音信息进行滤除环境噪声,并筛选得到多个优质的语音段作为训练样本,对建立的声纹模型进行训练,以提高声纹模型的准确性。
s203、利用声纹模型对所述有效声音信息进行声纹识别,得到所述有效声音信息的声纹特征信息;
本实施例中步骤s203的实现方式与上一实施例中步骤s102的实现方式类似,此处不再赘述。
s204、利用最小哈希算法,计算所述声纹特征信息与预警声纹特征信息之间的相似度;
通过声纹模型训练后得到的声纹特征信息集合t=[t1,t2……tn],集合中每项元素为一个声纹特征信息,例如t1为倒频谱,t2为共振峰等;存储的一个预警声纹特征信息集合si=[si1,si2,……sim],其中,i表示存储的不同的预警声纹特征信息的标识,当存储的预警声纹特征信息包括多个时,记为s1、s2、……、si,需要分别计算t与s1之间的相似度、t与s2之间的相似度、……、t与si之间的相似度。通常,集合中包括的元素个数是相同的,得到的声纹特征信息的参数是相同的。
计算两个集合之间的相似度,通常需要遍历这两个集合中的所有元素,统计这两个集合中相同元素的个数,来表示集合的相似度。通常使用的计算相似度的方式包括欧式距离、余弦相似度等方式,但是,当两个集合中的元素数量非常大时,同时又有很多集合需要分别判断两两之间的相似度时,采用欧式距离、余弦相似度计算相似度将十分耗时,计算效率低。
本实施例中采用最小哈希算法计算所述声纹特征信息与预警声纹特征信息之间的相似度;
t=[t1,t2……tn]与si=[si1,si2,……sim]相似度计算的公式为:
j(t,si)相似度系数值越大,两个集合之间的相似度越高。
采用最小哈希算法计算声纹特征信息与预警声纹特征信息之间的相似度,可以提高计算相似度的效率。
s205、判断所述相似度是否超过预设阈值;
判断所述相似度超过预设阈值,则所述声纹特征信息是预警声纹特征信息,执行步骤s206;
判断所述相似度没有超过预设阈值,则所述声纹特征信息不是预警声纹特征信息,执行步骤s207;
s206、发出警告;
s207、对所述声纹特征信息进行身份认证。
进行身份认证的实现方式为:分别计算所述声纹特征信息与预先存储在系统中的每个与目标说话者对应的目标声纹特征信息之间的相似度;判断计算出的相似度中是否存在大于预设阈值的相似度,若存在大于预设阈值的相似度,则计算得到此相似度的目标声纹特征信息对应的目标说话者就是发出采集到的声音信息的说话者,身份认证成功;若不存在大于预设阈值的相似度,则说明声纹特征信息并不是与目标说话者对应的或者没有识别出是与哪个目标说话者对应,身份认证失败。
在本实施例中,为了进一步提高已经建立的声纹模型的准确性,在身份认证成功后,存储身份认证成功的有效声音信息,或者存储对有效声音信息进行处理后选择出的多个优质语音段。针对一个目标说话人而言,获取此目标说话人在一段时间内每次身份认证成功的有效声音信息或者多个优质语音段,构成一定数量的训练样本,对声纹模型进行训练,得到训练后的新声纹模型以及训练后得到的新声纹特征信息。
将训练后得到的新声纹特征信息对预先存储的与目标说话人对应的目标声纹特征信息进行补充更新,使得获得与目标说话人相符的多个目标声纹特征信息。
本实施例中通过更新声纹模型已经更新与目标说话人对应的目标声纹特征信息,使得当目标说话人年龄、身体状况、情绪等发生变化时,仍然可以准确的完成身份认证。
在其他实施例中,获取训练样本时包括获取每次身份认证成功时的有效声音信息训练后得到的声纹特征信息与目标声纹特征信息之间的相似度。选择相似度的值大于预设相似度阈值的相似度对应的有效声音信息。通过选择身份认证成功的有效声音信息中,声纹特征信息与目标声纹特征信息相似度满足预设相似度阈值的有效声音信息,对声纹模型进行训练,可以进一步提高声纹模型的准确性。
从上述技术方案可知,本实施例中通过采集声音信息,利用声纹模型对声音信息进行声纹识别,得到所述声音信息的声纹特征信息;计算所述声纹特征信息与预警声纹特征信息之间的相似度;根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;判断所述声纹特征信息是预警声纹特征信息,则发出警告。当采集到的声音信息时预警声纹特征信息时,确定当前说话者为冒用目标说话人身份的说话者,不仅认证失败而且发出警告,且后续仍然存在冒用目标说话人身份的行为时,会继续发出警告,实现了对冒用目标说话人的事前预防,事中警告,事后跟踪确认的功能,提高了支付系统的安全性。同时,对采集到的声音信息进行处理,可以提高声纹模型的准确性。且利用认证成功的有效声音信息,对声纹模型进行训练并且更新与目标说话人对应的目标声纹特征信息,可以进一步提高声纹模型的准确性。
对应上述声音识别的方法,本实施例中公开了一种声音识别的装置,所述装置的结构示意图请参阅图3所示,本实施例中装置包括:
采集单元301、识别单元302、计算单元303、判断单元304、报警单元305和认证单元306;
采集单元301,用于采集声音信息;
识别单元302,用于利用声纹模型对所述声音信息进行声纹识别,得到所述声音信息的声纹特征信息;
计算单元303,用于计算所述声纹特征信息与预警声纹特征信息之间的相似度;其中,所述预警声纹特征信息是认证失败后存储的声纹特征信息;
判断单元304,用于根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;
报警单元305,用于所述判断单元判断所述声纹特征信息是预警声纹特征信息时,发出警告;
认证单元306,用于所述判断单元判断所述声纹特征信息不是预警声纹特征信息时,对所述声纹特征信息进行身份认证。
从上述技术方案可知,本实施例中通过采集声音信息,利用声纹模型对声音信息进行声纹识别,得到所述声音信息的声纹特征信息;计算所述声纹特征信息与预警声纹特征信息之间的相似度;根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;判断所述声纹特征信息是预警声纹特征信息,则发出警告。当采集到的声音信息时预警声纹特征信息时,确定当前说话者为冒用目标说话人身份的说话者,不仅认证失败而且发出警告,且后续仍然存在冒用目标说话人身份的行为时,会继续发出警告,实现了对冒用目标说话人的事前预防,事中警告,事后跟踪确认的功能,提高了支付系统的安全性。
在图3所示装置的基础上,本实施例还提供了另一种声音识别的装置,所述装置的结构示意图请参阅图4所示,所述装置中采集单元301包括:
采集子单元401和滤除子单元402;
采集子单元401,用于采集语音信息;
滤除子单元402,用于滤除所述语音信息中的环境信息,得到有效声音信息;
所述装置中计算单元303,用于利用最小哈希算法,计算所述声纹特征信息与预警声纹特征信息之间的相似度;
所述装置中判断单元304,用于判断所述相似度是否超过预设阈值;判断所述相似度超过预设阈值,则所述声纹特征信息是预警声纹特征信息;判断所述相似度没有超过预设阈值,则所述声纹特征信息不是预警声纹特征信息。
从上述技术方案可知,本实施例中通过采集声音信息,利用声纹模型对声音信息进行声纹识别,得到所述声音信息的声纹特征信息;计算所述声纹特征信息与预警声纹特征信息之间的相似度;根据所述相似度,判断所述声纹特征信息是否是预警声纹特征信息;判断所述声纹特征信息是预警声纹特征信息,则发出警告。当采集到的声音信息时预警声纹特征信息时,确定当前说话者为冒用目标说话人身份的说话者,不仅认证失败而且发出警告,且后续仍然存在冒用目标说话人身份的行为时,会继续发出警告,实现了对冒用目标说话人的事前预防,事中警告,事后跟踪确认的功能,提高了支付系统的安全性。同时,对采集到的声音信息进行处理,可以提高声纹模型的准确性。且利用认证成功的有效声音信息,对声纹模型进行训练并且更新与目标说话人对应的目标声纹特征信息,可以进一步提高声纹模型的准确性。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例提供的装置而言,由于其与实施例提供的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!