语音声色转换方法及装置与流程
本发明涉及通信技术领域,特别是涉及一种语音声色转换方法及装置。
背景技术:
现在市场上存在各种各样的翻译设备,这些翻译设备通过接收翻译对象的语音信号,并翻译成用户想要语种的声音文件,进而为用户进行播放,促进用户与翻译对象之间的沟通交流。但是,现在的这些翻译设备的播放声音一般只支持两种或三种声色的声音,例如百度翻译支持普通男声、普通女声和儿童声音这三种声色的语音播放,微软只支持普通男声和普通女声两种声色的语音播放,声色类型比较少,娱乐性较低,难以满足人们复杂的需求,比如萝莉、大叔、惊悚、搞怪、空灵等声色的语音播放,适合人们的特殊需求,娱乐性也比较高。
技术实现要素:
本发明的主要目的在于提供一种语音声色转换方法及装置,以增加翻译设备语音播放的声色,满足人们的多样化需求。
为达到上述目的,本发明所采取的技术方案是:一种语音声色转换方法,应用于翻译设备,包括:
接收语音信号;
对语音信号进行翻译处理并形成对应的音频文件;
若确定对音频文件进行语音声色转换,则将音频文件转换成对应声色的第一语音文件;
播放第一语音文件。
进一步地,播放第一语音文件的步骤,包括:
若当前正在播放第二语音文件,则根据预置语音文件播放规则设定所述第一语音文件的播放等级和所述第二语音文件的播放等级;
若所述第一语音文件的播放等级高于所述第二语音文件的播放等级,则停止播放所述第二语音文件,并播放所述第一语音文件。
进一步地,对语音信号进行翻译处理并形成对应的音频文件的步骤之后,包括:
按照预设规则将音频文件加载于翻译设备的音频引擎中。
进一步地,按照预设规则将音频文件加载于翻译设备的音频引擎中的步骤,包括:
获取音频文件的大小信息;
根据大小信息选择对应的加载形式,将音频文件加载于翻译设备的音频引擎中。
进一步地,对语音信号进行翻译处理并形成对应的音频文件的步骤,包括:
将语音信号转换为对应的数字信号并发送给第三方语音识别引擎;
接收第三方语音识别引擎对数字信号进行解析形成的识别文本;
将识别文本发送给翻译服务器;
接收翻译服务器按照翻译指令将识别文本翻译为对应的翻译文本;
将翻译文本发送给第三方合成引擎;
接收第三方合成引擎将翻译文本合成的音频文件。
本发明还提出一种语音声色转换装置,应用于翻译设备,包括:
第一接收单元,用于接收语音信号;
第一处理单元,用于对语音信号进行翻译处理并形成对应的音频文件;
第一转换单元,用于若确定对音频文件进行语音声色转换,则将音频文件转换成对应声色的第一语音文件;
第一播放单元,用于播放第一语音文件。
进一步地,第一播放单元包括:
设定模块,用于若当前正在播放第二语音文件,则根据预置语音文件播放规则设定所述第一语音文件的播放等级和所述第二语音文件的播放等级;
播放模块,用于若所述第一语音文件的播放等级高于所述第二语音文件的播放等级,则停止播放所述第二语音文件,并播放所述第一语音文件。
进一步地,还包括:
第一加载单元,用于按照预设规则将音频文件加载于翻译设备的音频引擎中。
进一步地,第一加载单元包括:
获取模块,用于获取音频文件的大小信息;
加载模块,用于根据大小信息选择对应的加载形式,将音频文件加载于翻译设备的音频引擎中。
进一步地,第一处理单元包括:
第一转换发送模块,用于将语音信号转换为对应的数字信号并发送给第三方语音识别引擎;
第一接收模块,用于接收第三方语音识别引擎对数字信号进行解析形成的识别文本;
第一发送模块,用于将识别文本发送给翻译服务器;
第二接收模块,用于接收翻译服务器按照翻译指令将识别文本翻译为对应的翻译文本;
第二发送模块,用于将翻译文本发送给第三方合成引擎;
第三接收模块,用于接收第三方合成引擎将翻译文本合成的音频文件。
本发明的语音声色转换方法及装置可以丰富翻译设备的语音播放声色,提高了翻译设备的娱乐性,满足人们多样化的声色需求。
附图说明
图1是本发明一实施例的翻译设备的结构示意框图;
图2是本发明一实施例的语音声色转换方法的流程示意图;
图3是本发明一实施例的步骤s4的流程示意图;
图4是本发明另一实施例的语音声色转换方法的流程示意图;
图5是本发明又一实施例的语音声色转换方法的流程示意图;
图6是本发明一实施例的步骤s2的流程示意图;
图7是本发明一实施例的语音声色转换装置的结构示意框图;
图8是本发明一实施例的第一转换单元的结构示意框图;
图9是本发明另一实施例的语音声色转换装置的结构示意框图;
图10是本发明另一实施例的第一加载单元的结构示意框图;
图11是本发明一实施例的第一处理单元的结构示意框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
在本发明中如涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
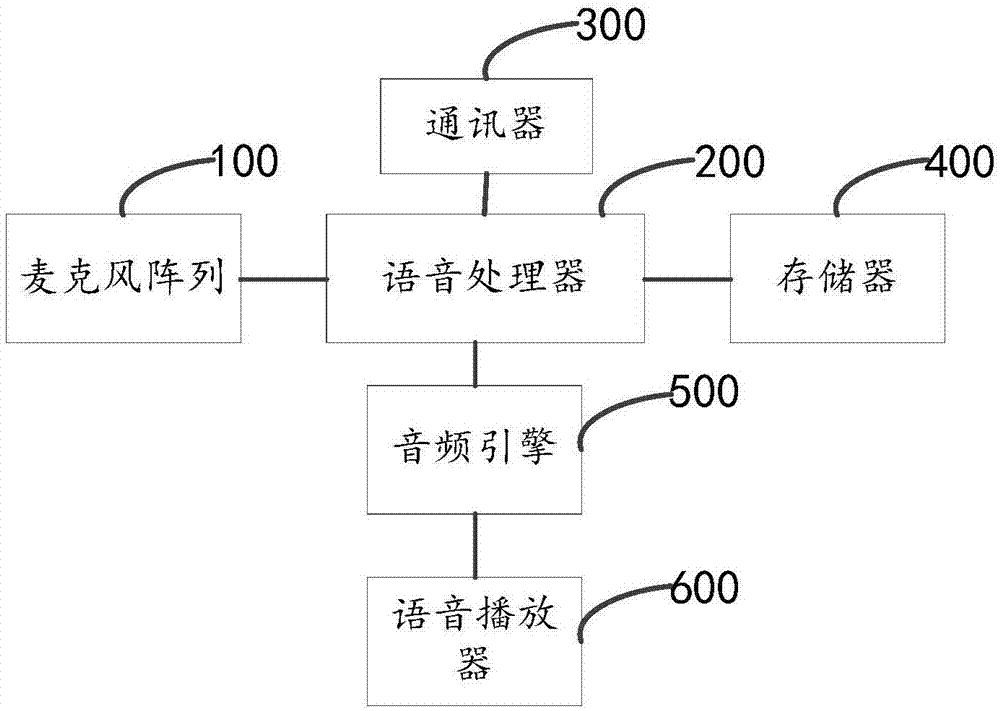
参照图1,本发明实施例的翻译设备包括麦克风阵列100、语音处理器200、通讯器300、存储器400、音频引擎500以及语音播放器600。上述麦克风阵列100是由一定数目的麦克风组成,可以对声场的空间特性进行采样并处理,麦克风阵列可以有效抑制噪声、混响、回声等干扰,保证输入语音的准确性。上述语音处理器200用于对麦克风阵列100接收到的语音信号进行初步处理,可以为fm1188语音处理器。上述通讯器300包括射频收发器、无线天线及网络连接器,射频收发器通过无线天线接收或发送信息文件,网络连接器可以使用wifi网络连接器。上述音频引擎可以为fmod音频引擎、盖莫音频引擎等,本实施例中使用的是fmod音频引擎,音频引擎可以合成不同声色的音频文件。上述语音播放器600可以为扬声器。本实施中,翻译设备不局限于翻译机,也可以是翻译软件或翻译app等。
参照图2,提出本发明一实施例的语音声色转换方法,应用于翻译设备,所述方法包括:
s1、接收语音信号;
s2、对语音信号进行翻译处理并形成对应的音频文件;
s3、若确定对音频文件进行语音声色转换,则将音频文件转换成对应声色的第一语音文件;
s4、播放第一语音文件;
s5、若确定不对音频文件进行语音声色转换,则根据音频文件进行原生语音播放。
在上述步骤s1中,翻译设备通过麦克风阵列接收与用户进行交流的第三人的语音信号。用户在与第三人交谈过程中,如果第三人所使用的语种为用户能听懂的语种,用户无需启动翻译设备,只有在第三人使用的语种为用户不能听懂的语种时,用户才启动翻译设备接收第三人的语音信号,然后进行下一步处理。
在上述步骤s2中,在麦克风阵列接收到语音信号,然后根据用户的翻译要求利用第三方服务器对语音信号进行翻译处理,并合成用户可以听懂的音频文件。
上述步骤s3至s5中,在得到用户可听懂的音频文件后,fmod音频引擎接收该音频文件,如果用户预先设置了需要对音频文件进行声色转换,fmod音频引擎对音频文件进行变声处理,合成符合用户预先设置声色的第一语音文件,例如用户预先设置了空灵声色的,fmod音频引擎则将音频文件进行变声处理,合成空灵声色的第一语音文件。可以预先在fmod中设置各种声色(如空灵、大叔、惊悚、萝莉等)的对应参数,比如将fmod音频引擎的dsp处理类型为音频提高,之后设置变化因子大小为2.0,就是萝莉的声色;将dsp处理为颤抖,设置低频震旦器频率为20,之后再设置声音歪斜数值为0.5,就是惊悚的声色;将dsp处理为音频提高,设置变化因子参数为0.5,就是大叔的声色;将dsp处理为音频提高,设置dsp的延迟因子为300,并且设置回音因子为20,就是空灵的声色,这些参数数值可以根据实际需要设置。如果用户没有预先设置对音频文件进行声色转换,则fmod音频引擎无需对音频文件进行变声处理,直接对音频文件进行原生语音播放,原生语音播放可以普通男声播放,也可以为普通女声播放。
上述语音声色转换方法,可以提供多种声色的语音,用户根据喜好在翻译设备上设置相应声色的语音进行播放,例如空灵声色的语音播放、搞怪声色的语音播放等,丰富了翻译设备的功能,提高了用户的体验感受,娱乐性高,满足了人们多样化的声色需求。
参照图3,播放第一语音文件的步骤,包括:
s41、若当前正在播放第二语音文件,则根据预置语音文件播放规则设定所述第一语音文件的播放等级和所述第二语音文件的播放等级;
s42、若所述第一语音文件的播放等级高于所述第二语音文件的播放等级,则停止播放所述第二语音文件,并播放所述第一语音文件。
上述步骤s41和s42中,第二语音文件是指已经进行了语音声色转换的语音播放文件或者是原声语音播放文件。用户在播放已经转换声色的第二语音文件时,有时会遇到播放时长较长的语音文件,在播放第二语音文件时,翻译设备已经将第三人的下一段话进行声色转换合成的第一语音文件,如果用户此时想要直接播放该新的语音文件,就需要等前一语音文件播放完毕,才能进行播放,用户体验效果不好。因此,在fmod音频引擎对音频文件进行声色转换得到语音文件,在对该语音文件进行播放前,在fmod音频引擎中添加一个可以对语音文件进行播放等级设置的程序,将语音文件设置成不同的播放等级,在设置语音文件的播放等级时,可以按照语音文件转换合成的先后顺序进行设置,设置先转换的第二语音文件播放等级低于后转换的第一语音文件播放等级,在先转换的第二语音文件播放过程中,如果后转换的第一语音文件已经转换完成,由于后转换的第一语音文件播放等级高于先转换的第二语音文件,先转换的第二语音文件就会停止播放,转而播放后转换的第一语音文件。当然也可以设置后转换的第一语音文件播放等级低于先转换的第二语音文件播放等级,这样就会在先转换的第二语音文件播放完毕后再播放后转换的第一语音文件,可以根据用户喜好进行设置。
参照图4,对语音信号进行翻译处理并形成对应的音频文件的步骤之后,包括:
s30、按照预设规则将音频文件加载于翻译设备的音频引擎中。
上述步骤s30,预设规则是指fmod音频引擎会根据音频文件的大小,以不同的形式将音频文件加载到系统中,主要有以下三种形式:samples、stream、compressedsamples。其中samples表示解压成pcm的形式加载到fmod音频引擎的内存中,适用于短小音频数据;stream表示需要从磁盘溢流的形式读入到fmod管理的循环缓冲区,适用于大型的音频文件;compressedsamples表示以特定的压缩格式(如imaadpcm、mp2、mp3等)加载到fmod音频引擎的内存。这三种形式所占用的cpu内存各不相同,根据音频大小生成对应形式的声音文件,可以充分利用fmod音频的引擎的功能,避免fmod音频引擎过度消耗。
参照图5,按照预设规则将音频文件加载于翻译设备的音频引擎中的步骤,包括:
s31、获取音频文件的大小信息;
s32、根据大小信息选择对应的加载形式,将音频文件加载于翻译设备的音频引擎中。
在步骤s31至s32中,fmod音频引擎在接收到音频文件时,会对音频文件的大小进行检测,然后选择对应的形式将音频文件加载到内存中;例如,fmod音频引擎接收到的音频文件为一个短小的音频数据,就会选择以samples的形式将该音频文件加载到内存中,接着进行声色转换处理;再例如fmod音频引擎接收到音频文件为大型的音频文件,就会选择以stream的形式将该音频文件加载到内存,然后进行声色转换处理。
参照图6,对语音信号进行翻译处理并形成对应的音频文件的步骤,包括:
s21、将语音信号转换为对应的数字信号并发送给第三方语音识别引擎;
上述步骤s21中,翻译设备的语音处理器将麦克风阵列接收到的语音信号进行初步处理形成由数字信号组成的音频信息,并将该音频信息通过通讯器发送到第三方服务器,该第三方服务器可以为第三方语音设别引擎。
s22、接收第三方语音识别引擎对数字信号进行解析形成的识别文本;
上述步骤s22中,第三方语音识别引擎接收到音频信息后,就会对音频信息进行解析识别,形成与第三人所用语种对应的识别文本,并将识别文本返回给翻译设备;在该步骤中,如果接收到的音频信息为第三方语音识别引擎无法识别的音频信息,例如第三人所使用的语种不在第三方语音识别引擎的语种数据库内,则第三方语音识别引擎无法识别接收到的音频信息,此时翻译设备可以将音频信息发送给另一个第三方语音识别引擎进行处理,以得到对应的识别文本,或者翻译设备停止后续的处理步骤,并提示用户当前第三人的语音无法翻译,便于用户采取其他处理措施。
s23、将识别文本发送给翻译服务器;
s24、接收翻译服务器按照翻译指令将识别文本翻译为对应的翻译文本;
上述步骤s23和s24中,翻译设备的通讯器将识别文本发送到翻译服务器,翻译服务器就会根据用户的翻译需求,将识别文本翻译成与用户需要的语种对应的翻译文本,并将翻译文本发送给翻译设备;例如第三人使用法语与用户进行交流,用户只能听懂中文,用户则在翻译设备上设置翻译文本对应的语种为中文,翻译服务器就会将识别文本翻译成中文翻译文本。
s25、将翻译文本发送给第三方合成引擎;
上述步骤s25中,翻译设备会将翻译文本发送给第三方合成引擎,第三方合成引擎对翻译文本进行识别,然后合成与翻译文本语种相同的音频文件。
s26、接收第三方合成引擎将翻译文本合成的音频文件。
上述步骤s26中,第三方合成引擎将翻译文本合成对应的音频文件后,就会将该音频文件返回给翻译设备,翻译设备的通讯器接收到音频文件后,就会存储在存储器中。例如翻译文本对应的语种为中文,第三方合成引擎就会将该翻译文本合成为中文形式的音频文件。
参照图7,本发明还提出了语音声色转换装置的一实施例,该语音声色转换装置包括:
第一接收单元1,用于接收语音信号;
第一处理单元2,用于对语音信号进行翻译处理并形成对应的音频文件;
第一转换单元3,用于若确定对音频文件进行语音声色转换,则将音频文件转换成对应声色的第一语音文件;
第一播放单元4,用于播放第一语音文件;
第二播放单元5,用于若确定不对音频文件进行语音声色转换,则根据音频文件进行原生语音播放。
在上述第一接收单元1中,翻译设备通过麦克风阵列接收与用户进行交流的第三人的语音信号。用户在与第三人交谈过程中,如果第三人所使用的语种为用户能听懂的语种,用户无需启动翻译设备,只有在第三人使用的语种为用户不能听懂的语种时,用户才启动翻译设备接收第三人的语音信号,然后进行下一步处理。
在上述第一处理单元2中,在麦克风阵列接收到语音信号,然后根据用户的翻译要求利用第三方服务器对语音信号进行翻译处理,并合成用户可以听懂的音频文件。
在上述第一转换单元3、第一播放单元4和第二播放单元5中,在得到用户可听懂的音频文件后,fmod音频引擎接收该音频文件,如果用户预先设置了需要对音频文件进行声色转换,fmod音频引擎对音频文件进行变声处理,合成符合用户预先设置声色的第一语音文件,例如用户预先设置了空灵声色的,fmod音频引擎则将音频文件进行变声处理,合成空灵声色的第一语音文件。可以预先在fmod中设置各种声色(如空灵、大叔、惊悚、萝莉等)的对应参数,比如将fmod音频引擎的dsp处理类型为音频提高,之后设置变化因子大小为2.0,就是萝莉的声色;将dsp处理为颤抖,设置低频震旦器频率为20,之后再设置声音歪斜数值为0.5,就是惊悚的声色;将dsp处理为音频提高,设置变化因子参数为0.5,就是大叔的声色;将dsp处理为音频提高,设置dsp的延迟因子为300,并且设置回音因子为20,就是空灵的声色,这些参数数值可以根据实际需要设置。如果用户没有预先设置对音频文件进行声色转换,则fmod音频引擎无需对音频文件进行变声处理,直接对音频文件进行原生语音播放,原生语音播放可以普通男声播放,也可以为普通女声播放。
上述语音声色转换方法,可以提供多种声色的语音,用户根据喜好在翻译设备上设置相应声色的语音进行播放,例如空灵声色的语音播放、搞怪声色的语音播放等,丰富了翻译设备的功能,提高了用户的体验感受,娱乐性高,满足了人们多样化的声色需求。
参照图8,上述第一转换单元4包括:
设定模块41,用于若当前正在播放第二语音文件,则根据预置语音文件播放规则设定所述第一语音文件的播放等级和所述第二语音文件的播放等级;
播放模块42,用于若所述第一语音文件的播放等级高于所述第二语音文件的播放等级,则停止播放所述第二语音文件,并播放所述第一语音文件。
上述设定模块41和播放模块42中,第二语音文件是指已经进行了语音声色转换的语音播放文件或者是原声语音播放文件。用户在播放已经转换声色的第二语音文件时,有时会遇到播放时长较长的语音文件,在播放第二语音文件时,翻译设备已经将第三人的下一段话进行声色转换合成的第一语音文件,如果用户此时想要直接播放该新的语音文件,就需要等前一语音文件播放完毕,才能进行播放,用户体验效果不好。因此,在fmod音频引擎对音频文件进行声色转换得到语音文件,在对该语音文件进行播放前,在fmod音频引擎中添加一个可以对语音文件进行播放等级设置的程序,将语音文件设置成不同的播放等级,在设置语音文件的播放等级时,可以按照语音文件转换合成的先后顺序进行设置,设置先转换的第二语音文件播放等级低于后转换的第一语音文件播放等级,在先转换的第二语音文件播放过程中,如果后转换的第一语音文件已经转换完成,由于后转换的第一语音文件播放等级高于先转换的第二语音文件,先转换的第二语音文件就会停止播放,转而播放后转换的第一语音文件。当然也可以设置后转换的第一语音文件播放等级低于先转换的第二语音文件播放等级,这样就会在先转换的第二语音文件播放完毕后再播放后转换的第一语音文件,可以根据用户喜好进行设置。
参照图9,上述语音声色转换装置还包括:
第一加载单元6,用于按照预设规则将音频文件加载于翻译设备的音频引擎中。
上述第一加载单元6中,预设规则是指fmod音频引擎会根据音频文件的大小,以不同的形式将音频文件加载到系统中,主要有以下三种形式:samples、stream、compressedsamples。其中samples表示解压成pcm的形式加载到fmod音频引擎的内存中,适用于短小音频数据;stream表示需要从磁盘溢流的形式读入到fmod管理的循环缓冲区,适用于大型的音频文件;compressedsamples表示以特定的压缩格式(如imaadpcm、mp2、mp3等)加载到fmod音频引擎的内存。这三种形式所占用的cpu内存各不相同,根据音频大小生成对应形式的声音文件,可以充分利用fmod音频的引擎的功能,避免fmod音频引擎过度消耗。
参照图10,上述第一加载单元6包括:
获取模块61,用于获取音频文件的大小信息;
加载模块62,用于根据大小信息选择对应的加载形式,将音频文件加载于翻译设备的音频引擎中。
在上述获取模块61和加载模块62中,fmod音频引擎在接收到音频文件时,会对音频文件的大小进行检测,然后选择对应的形式将音频文件加载到内存中;例如,fmod音频引擎接收到的音频文件为一个短小的音频数据,就会选择以samples的形式将该音频文件加载到内存中,接着进行声色转换处理;再例如fmod音频引擎接收到音频文件为大型的音频文件,就会选择以stream的形式将该音频文件加载到内存,然后进行声色转换处理。
参照图11,上述第一处理单元2包括:
第一转换发送模块21,用于将语音信号转换为对应的数字信号并发送给第三方语音识别引擎。
上述第一转换发送模块21中,翻译设备的语音处理器将麦克风阵列接收到的语音信号进行初步处理形成由数字信号组成的音频信息,并将该音频信息通过通讯器发送到第三方服务器,该第三方服务器可以为第三方语音设别引擎。
第一接收模块22,用于接收第三方语音识别引擎对数字信号进行解析形成的识别文本。
上述第一接收模块22中,第三方语音识别引擎接收到音频信息后,就会对音频信息进行解析识别,形成与第三人所用语种对应的识别文本,并将识别文本返回给翻译设备;在该步骤中,如果接收到的音频信息为第三方语音识别引擎无法识别的音频信息,例如第三人所使用的语种不在第三方语音识别引擎的语种数据库内,则第三方语音识别引擎无法识别接收到的音频信息,此时翻译设备可以将音频信息发送给另一个第三方语音识别引擎进行处理,以得到对应的识别文本,或者翻译设备停止后续的处理步骤,并提示用户当前第三人的语音无法翻译,便于用户采取其他处理措施。
第一发送模块23,用于将识别文本发送给翻译服务器;
第二接收模块24,用于接收翻译服务器按照翻译指令将识别文本翻译为对应的翻译文本。
上述第一发送模块23和第二接收模块24中,翻译设备的通讯器将识别文本发送到翻译服务器,翻译服务器就会根据用户的翻译需求,将识别文本翻译成与用户需要的语种对应的翻译文本,并将翻译文本发送给翻译设备;例如第三人使用法语与用户进行交流,用户只能听懂中文,用户则在翻译设备上设置翻译文本对应的语种为中文,翻译服务器就会将识别文本翻译成中文翻译文本。
第二发送模块25,用于将翻译文本发送给第三方合成引擎。
上述第二发送模块25中,翻译设备会将翻译文本发送给第三方合成引擎,第三方合成引擎对翻译文本进行识别,然后合成与翻译文本语种相同的音频文件。
第三接收模块26,用于接收第三方合成引擎将翻译文本合成的音频文件。
上述第三接收模块26中,第三方合成引擎将翻译文本合成对应的音频文件后,就会将该音频文件返回给翻译设备,翻译设备的通讯器接收到音频文件后,就会存储在存储器中。例如翻译文本对应的语种为中文,第三方合成引擎就会将该翻译文本合成为中文形式的音频文件。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!