一种比例微分控制的混合信号自适应快速分离方法与流程
本发明涉及盲源信号分离的处理技术领域,特别是一种比例微分控制的混合信号自适应快速分离方法。
背景技术:
独立分量分析是当前盲信源分离的主流方法。已经有很多有效的算法,这些算法的形式不同,它们都可以归类于lms(leastmeansquare)型算法。这些算法都存在一个学习率参数的优选问题,如何提高算法的收敛速度和改进算法的稳态性能一直是盲源分离研究的热点之一。目前一致的观点是必须找到一种有效的变步长学习率,并且该变步长必须与分离状态紧密一致时,才能达到有效加速。有些算法在初始步长基础上构建了变步长学习率,虽然也达到加速目的,但人为添加过多参数,不利于工程的实际使用。
在自动化pid(proportionintegraldifferentiation)算法中,利用预设值和输出反馈值间的差值,比例项p是把调节器的输入偏差乘以一个系数,作为调节器的输出;加大比例值可以减少从非稳态到稳态的时间。积分项i部分其实就是对预设值和反馈值之间的差值在时间上进行累加;当累加到一定值时,再进行处理,避免了振荡,但调节存在明显的滞后,但在向较大目标预设值加速过程是有用的。微分项d是根据差值变化的速率,提前给出相应的调节动作;它能预测误差的变化趋势,超前给出调整。
在盲源分离算法中,峭度累积值随分离程度提高而增大,达到完全分离时的稳定值相当于预设值,而分离过程的峭度累积值相当于输出反馈。因为不同类型的信号具有不同的固有峭度值,混合信号在达到完全分离时,每个信号将达到其固有的峭度值(实际情形是达到一个很小稳定误差下分离时的峭度值),则各个分离信号峭度的累积量也就达到了稳定值;不同的信号混合,其达到的稳定值将不一样,那么,该自然隐性固有存在的稳定值即为本方法的预设值。
注意到分离信号的峭度累积量是由小到大直至稳定的单向变化过程,而变步长的目的是为了稳定地加速这个过程。因此,这里的达到完全分离的峭度的累积量预设值过程就是渐进稳定性问题,即强调的是快速收敛性,而不是稳定于预设值的问题。
对于固定步长自然梯度盲源分离算法存在这样的现象:首先,对于不同类型信号的自然梯度盲源分离算法都存在一个可以计算收敛的最大的步长值ηmax。其次,分离信号的峭度累积量与分离信号输出状态密切相关,两次迭代之间的峭度累积量之差e(k)的变化值域和运算过程的变化斜率表现为:步长值越小,其e(k)的变化值域和运算过程的变化斜率也将变小,尤其开始阶段峭度累积量的e(k)将在越长的迭代次数中几乎接近0的无明显变化,因此达到分离信号峭度累积量预定值的迭代次数也将增长;可见固定步长自然梯度盲源分离收敛速度是与步长相关的,而当取步长取值ηmax时的盲源分离收敛速度是最快的。
技术实现要素:
有鉴于此,本发明的目的是提出一种比例微分控制的混合信号自适应快速分离方法,实现初始步长在一定取值范围内,均具有相同稳定误差下接近一致数量级的最大收敛速度,特别是所涉及变换技术参数均是分离过程输出的相关物理量,分离算法构成具有自适应性,具有实际使用价值。
本发明采用以下方案实现:一种比例微分控制的混合信号自适应快速分离方法,具体包括以下步骤:
步骤s1:计算初始分离信号,采用自然梯度盲源分离算法计算第一次变换矩阵及分离信号:确定步长的初始值η0,取初始分离矩阵w0=0.1*i,其中i为n×n的单位矩阵,并采用下式计算第一次变换矩阵w1,即令下式中k=0:
式中,ηk为变步长学习率,yk表示第k次分离信号,yk=wkx,当k=0时,x为初次输入的n个混合信号;
步骤s2:采用分离迭代计算间对分离信号峭度累积量之差e(k)的进行变换计算,计算与分离输出状态相关的下一次变步长ηk+1,并由该下一次变步长计算新的分离矩阵;
较佳的,根据分离信号的相关峭度累积量jall(k),针对两次迭代之间的分析,获得对下次迭代运算的影响,是一种离散的过程,峭度累积值不断变大的过程,反映的是分离输出信号的峭度累积量与“预设值”(隐性固有存在的稳定值:混合信号在达到完全分离时,每个信号将达到其固有的峭度值,则各个分离信号峭度的累积量也就达到了稳定值,不同的信号混合,其达到的稳定值将不一样)越来越小的偏差。前后两次迭代计算间的峭度累积量之差e(k)可用下式表示:
e(k)=jall(k)-jall(k-1);
e(k)将随着分离接近于完成而越来越小。若历经n次迭代计算后,e(k)等于0,则这时e(k)的累积值就等于峭度累积量的固有“预设值”:
显然,由于该固有“预设值”是个一定的值,n越小则e(k)的变化范围将越大,反之相反。当步长值越大时获得的分离矩阵越接近目标,分离信号的峭度累积量输出也越大,e(k)的变化速度和变化范围越大,将用越短迭代次数达到0而完成分离。所以,e(k)值的变化大小和变化速度是与步长值相关的。可见,在相同稳定误差下完成分离的收敛速度是取决于步长值的。针对每个混合信号的固定步长自然梯度盲源分离都有兼顾稳定性和收敛速度的一个固定步长可取值范围(0<η0≤ηmax),则其能达到的最快迭代收敛速度是取步长ηmax时的分离过程。
以下计算是为了得到,步长小于ηmax的自然梯度盲源分离与步长为ηmax时的自然梯度盲源分离具有相同稳定误差下接近一致数量级的最大收敛速度。显然,如果以e(k)相对于迭代步长的变化量近似作为微分预测的步长增量,由此在初始步长η0(0<η0<ηmax)基础上,构成变步长算法,对初始步长小于ηmax的自然梯度盲源分离将得到一定的提速:
但因为步长越小时,迭代计算的分离程度也越低,分离信号的峭度累积量的e(k)就越小,尤其开始阶段峭度累积量的e(k)将在越长的迭代次数中几乎接近0的无明显变化,则开始阶段的微分预测值也几乎无明显增量,而后续e(k)的变化速率和变化值域都即使得到必要加速,也由于开始段的无变化延迟,则完成分离的收敛速度只能得到一定提高。步长越小时这种开始阶段的延迟将越大,只有在步长值取允许的最大值ηmax时,这种开始段无变化的延迟才几乎不存在。
为了在取0<η0≤ηmax步长初始值时,得到在相同稳定误差下接近一致数量级的最大收敛速度,做以下的计算变换:
步骤s21:计算前后两次迭代计算间的峭度累积量之差e(k):
e(k)=jall(k)-jall(k-1);
式中,jall(k)表示分离信号的相关峭度累积量;
步骤s22:改造e(k)的值域,即把e(k)做指数增量改变,使其变化值域增大:
e(k)=αe(k);
式中,α为选择的指数底;对大于(e(k)-1)以上的值域,因其变化趋势保持可与e(k)相似的变化趋势,则与分离输出状态也是保持相关的。
步骤s23:计算变步长预测增量δηk+1:
采用步骤s22得到的e(k)构成合适的变步长增量(近似的微分预测),则不仅迭代计算开始就很快进入加速状态,提高了e(k)相对于步长的变化速率(变步长计算后的e(k)曲线的斜率),而且该步长增量也与分离输出状态相关,因而具有幅度较大的变步长预测增量。
步骤s24:计算下一次变步长ηk+1:
ηk+1=η0+γδηk+1;
考虑到:①初始步长取值越大时,其e(k)变化斜率也越大,需要的步长增量也应越小;②因为一般步长值都是取小于1的值,把基于固定步长自然梯度算法的e(k)做了指数变化,其值是在1值上叠加指数的值,因此作用系数γ考虑取小于1的值,并且也采用指数变化。由此,构造微分作用系数γ计算如下:
式中,β也为指定的另一指数底,ηmax为允许的最大固定步长(也是该变步长算法中最大初始步长值);当步长初值取值ηmax时,γ值为0而去除步长增量,而当步长初值取小于ηmax时,步长初值越大则γ值越小,从而减小步长增量。
对于不同信号类型,取合适的指数底α和β为合适值时,在取值于0<η0≤ηmax的任意步长初始值时,可达到分离具有相同稳定误差下几乎一致数量级的最大收敛速度。
步骤s25:采用下式计算新的分离矩阵wk+1:
式中,ηk为变步长学习率,yk表示第k次分离信号yk=wkx,其中x为输入的n个未完全分离的混合信号;
步骤s3:判断步骤s2得到的新的分离矩阵是否达到控制精度要求,若是,则进入步骤s4,否则返回步骤s2;
步骤s4:利用达到控制精度要求的分离矩阵wout计算输出分离信号:
y=woutx。
进一步地,分离信号的峭度计算为:利用分离信号边缘负熵近似为如下的四阶边缘累积量:
式中,
在盲源分离过程,jall(k)是非负的,且从小到大变化,最后达到稳定值,反映了完成分离的状态。
进一步地,整个计算过程中针对的信号为欠高斯混合信号或超高斯混合信号;当为欠高斯混合信号时,非线性函数向量
进一步地,对于不同类型的混合信号,步长的初始值η0取固定步长自然梯度分离计算中可收敛步长范围内的值,即0≤η0≤ηmax(随着步长取值的增加,到取一定值时将出现发散而不收敛,该取值范围即为可收敛的取值范围)。
本发明利用分离信号峭度值构成pd(proportiondifferentiation)控制的变步长学习率,可以在初始比例作用(初始步长)基础上,依据与分离输出信号状态密切相关的物理量变换计算,构成微分提前预测的步长增量,尤其是改变了小步长时e(k)开始段的由于接近0而无微分预测增量的状态,迭代开始就很快能进入加速过程。由此,形成动态步长闭环控制的自然梯度盲源分离系统。该闭环分离控制系统对于步长初始值η0从0<η0≤ηmax范围任意取值时,从新得到的e(k)在变化值域、变化斜率和迭代次数均几乎接近一致的状态,因而能在相同分离稳定误差下达到几乎一致数量级的最大分离收敛速度(其小初始步长的计算收敛速度均接近ηmax的效果)。那么,由于本发明的方法是密切跟踪分离过程输出状态的,具有明显有效性,并且由于是充分利用分离过程输出的相关物理量构成算法,形成了分离算法的自适应形式。
与现有技术相比,本发明有以下有益效果:
1、本发明计算中涉及的物理量均是分离过程相关的物理量,微分预测的变步长是与分离信号输出状态密切相关,不仅有较高的准确跟随和最大化分离加速,而且具有自适应的特点。
2、本发明在取值于0<η0<ηmax的任意步长初始值时,可达到分离具有相同稳定误差和几乎一致数量级的最大收敛速度的目标,有利于实际应用。
3、本发明可以在各种信号处理、信号通信、物联网等领域构成实际工程应用的一个信号分离处理环节。
附图说明
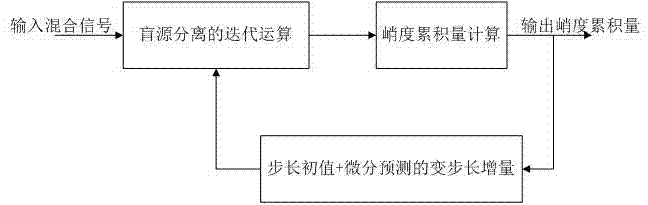
图1是本发明核心原理的实现框图。
图2是超高斯语音信号的源信号图。
图3是超高斯源语音信号的混合矩阵和混合信号图。
图4是欠高斯通信信号的源信号图。
图5是欠高斯源通信信号的混合矩阵和混合信号图。
图6是超高斯混合信号固定步长算法的峭度累积量变化曲线(η0=0.8和0.9)图。
图7是超高斯混合信号固定步长算法的e(k)变化曲线(η0=0.1和0.8)图。
图8是超高斯混合信号固定步长算法的e(k)和对e(k)变换计算(e(k)-1)的变化曲线(η0=0.1)图。
图9是本发明超高斯混合信号变步长算法的峭度累积量变化曲线(η0=0.1和0.8)图。
图10是本发明超高斯混合信号变步长算法的e(k)变化曲线(η0=0.1和0.8)图。
图11是本发明超高斯语音混合信号变步长算法的分离输出信号(η0=0.1)。
图12是欠高斯混合信号固定步长算法的峭度累积量变化曲线(η0=0.4和0.5)图。
图13是欠高斯混合信号固定步长算法的e(k)变化曲线(η0=0.1和0.4)图。
图14是欠高斯混合信号固定步长算法的e(k)和对e(k)变换计算(e(k)-1)变化曲线(η0=0.1)图。
图15是本发明欠高斯混合信号变步长算法的峭度累积量变化曲线(η0=0.1和0.4)图。
图16是本发明欠高斯混合信号变步长算法的e(k)变化曲线(η0=0.1和0.4)图。
图17是本发明欠高斯通信混合信号变步长算法的分离输出信号(η0=0.1)。
表1是本发明变步长算法(η0值取0.1-0.8及α=2和β=1.5合适取值)和固定步长算法对超高斯语音混合信号完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差。
表2是本发明变步长算法(η0值取0.1-0.4及α=2和β=1.5合适取值)和固定步长算法对欠高斯通信混合信号完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本实施例提供了一种比例微分控制的混合信号自适应快速分离方法,具体包括以下步骤:
步骤s1:计算初始分离信号,采用自然梯度盲源分离算法计算第一次变换矩阵及分离信号:确定步长的初始值η0,取初始分离矩阵w0=0.1*i,其中i为n×n的单位矩阵,并采用下式计算第一次变换矩阵w1,即令下式中k=0:
式中,ηk为变步长学习率,yk表示第k次分离信号,yk=wkx,当k=0时,x为初次输入的n个混合信号;
步骤s2:采用分离迭代计算间对分离信号峭度累积量之差e(k)的进行变换计算,计算与分离输出状态相关的下一次变步长ηk+1,并由该下一次变步长计算新的分离矩阵;
较佳的,根据分离信号的相关峭度累积量jall(k),针对两次迭代之间的分析,获得对下次迭代运算的影响,是一种离散的过程,峭度累积值不断变大的过程,反映的是分离输出信号的峭度累积量与“预设值”(隐性固有存在的稳定值:混合信号在达到完全分离时,每个信号将达到其固有的峭度值,则各个分离信号峭度的累积量也就达到了稳定值,不同的信号混合,其达到的稳定值将不一样)越来越小的偏差。前后两次迭代计算间的峭度累积量之差e(k)可用下式表示:
e(k)=jall(k)-jall(k-1);
e(k)将随着分离接近于完成而越来越小。若历经n次迭代计算后,e(k)等于0,则这时e(k)的累积值就等于峭度累积量的固有“预设值”:
显然,由于该固有“预设值”是个一定的值,n越小则e(k)的变化范围将越大,反之相反。当步长值越大时获得的分离矩阵越接近目标,分离信号的峭度累积量输出也越大,e(k)的变化速度和变化范围越大,将用越短迭代次数达到0而完成分离。所以,e(k)值的变化大小和变化速度是与步长值相关的。可见,在相同稳定误差下完成分离的收敛速度是取决于步长值的。针对每个混合信号的固定步长自然梯度盲源分离都有兼顾稳定性和收敛速度的一个固定步长可取值范围(0<η0≤ηmax),则其能达到的最快迭代收敛速度是取步长ηmax时的分离过程。
以下计算是为了得到,步长小于ηmax的自然梯度盲源分离与步长为ηmax时的自然梯度盲源分离具有相同稳定误差下接近一致数量级的最大收敛速度。显然,如果以e(k)相对于迭代步长的变化量近似作为微分预测的步长增量,由此在初始步长η0(0<η0<ηmax)基础上,构成变步长算法,对初始步长小于ηmax的自然梯度盲源分离将得到一定的提速:
但因为步长越小时,迭代计算的分离程度也越低,分离信号的峭度累积量的e(k)就越小,尤其开始阶段峭度累积量的e(k)将在越长的迭代次数中几乎接近0的无明显变化,则开始阶段的微分预测值也几乎无明显增量,而后续e(k)的变化速率和变化值域都即使得到必要加速,也由于开始段的无变化延迟,则完成分离的收敛速度只能得到一定提高。步长越小时这种开始阶段的延迟将越大,只有在步长值取允许的最大值ηmax时,这种开始段无变化的延迟才几乎不存在。
为了在取0<η0≤ηmax步长初始值时,得到在相同稳定误差下接近一致数量级的最大收敛速度,做以下的计算变换:
步骤s21:计算前后两次迭代计算间的峭度累积量之差e(k):
e(k)=jall(k)-jall(k-1);
式中,jall(k)表示分离信号的相关峭度累积量;
步骤s22:改造e(k)的值域,即把e(k)做指数增量改变,使其变化值域增大:
e(k)=αe(k);
式中,α为选择的指数底;对大于(e(k)-1)以上的值域,因其变化趋势保持可与e(k)相似的变化趋势,则与分离输出状态也是保持相关的。
步骤s23:计算变步长预测增量δηk+1:
采用步骤s22得到的e(k)构成合适的变步长增量(近似的微分预测),则不仅迭代计算开始就很快进入加速状态,提高了e(k)相对于步长的变化速率(变步长计算后的e(k)曲线的斜率),而且该步长增量也与分离输出状态相关,因而具有幅度较大的变步长预测增量。
步骤s24:计算下一次变步长ηk+1:
ηk+1=η0+γδηk+1;
考虑到:①初始步长取值越大时,其e(k)变化斜率也越大,需要的步长增量也应越小;②因为一般步长值都是取小于1的值,把基于固定步长自然梯度算法的e(k)做了指数变化,其值是在1值上叠加指数的值,因此作用系数γ考虑取小于1的值,并且也采用指数变化。由此,构造微分作用系数γ计算如下:
式中,β也为指定的另一指数底,ηmax为允许的最大固定步长(也是该变步长算法中最大初始步长值);当步长初值取值ηmax时,γ值为0而去除步长增量,而当步长初值取小于ηmax时,步长初值越大则γ值越小,从而减小步长增量。
对于不同信号类型,取合适的指数底α和β为合适值时,在取值于0<η0≤ηmax的任意步长初始值时,可达到分离具有相同稳定误差下几乎一致数量级的最大收敛速度。
步骤s25:采用下式计算新的分离矩阵wk+1:
式中,ηk为变步长学习率,yk表示第k次分离信号yk=wkx,其中x为输入的n个未完全分离的混合信号;
步骤s3:判断步骤s2得到的新的分离矩阵是否达到控制精度要求,若是,则进入步骤s4,否则返回步骤s2;
步骤s4:利用达到控制精度要求的分离矩阵wout计算输出分离信号:
y=woutx。
在本实施例中,分离信号的峭度计算为:利用分离信号边缘负熵近似为如下的四阶边缘累积量:
式中,
在盲源分离过程,jall(k)是非负的,且从小到大变化,最后达到稳定值,反映了完成分离的状态。
在本实施例中,整个计算过程中针对的信号为欠高斯混合信号或超高斯混合信号;当为欠高斯混合信号时,非线性函数向量
在本实施例中,对于不同类型的混合信号,步长的初始值η0取固定步长自然梯度分离计算中可收敛步长范围内的值,即0≤η0≤ηmax(随着步长取值的增加,到取一定值时将出现发散而不收敛,该取值范围即为可收敛的取值范围)。
本实施例利用分离信号峭度值构成pd(proportiondifferentiation)控制的变步长学习率,可以在初始比例作用(初始步长)基础上,依据与分离输出信号状态密切相关的物理量变换计算,构成微分提前预测的步长增量,尤其是改变了小步长时e(k)开始段的由于接近0而无微分预测增量的状态,迭代开始就很快能进入加速过程。由此,形成动态步长闭环控制的自然梯度盲源分离系统。该闭环分离控制系统对于步长初始值η0从0<η0≤ηmax范围任意取值时,从新得到的e(k)在变化值域、变化斜率和迭代次数均几乎接近一致的状态,因而能在相同分离稳定误差下达到几乎一致数量级的最大分离收敛速度(其小初始步长的计算收敛速度均接近ηmax的效果)。那么,由于本发明的方法是密切跟踪分离过程输出状态的,具有明显有效性,并且由于是充分利用分离过程输出的相关物理量构成算法,形成了分离算法的自适应形式。
特别的,如图1所示,图1是本发明的核心实现框图。
在盲源分离算法中,峭度累积值随分离程度提高而增大,达到完全分离时的稳定值相当于预设值(超高斯混合信号和亚高斯混合信号均有此特点),而分离过程的峭度累积值相当于输出反馈。因为不同类型的信号具有不同的固有峭度值,混合信号在达到完全分离时,每个信号将达到其固有的峭度值(实际情形是达到一个很小稳定误差下分离时的峭度值),则各个分离信号峭度的累积量也就达到了稳定值;不同的信号混合,其达到的稳定值将不一样,那么,该自然隐性固有存在的稳定值即为本方法的预设值。并且注意到分离信号的峭度累积量是由小到大直至稳定的单向变化过程,而变步长的目的是为了稳定地加速这个过程。
形成本发明的前提依据是,对于固定步长自然梯度盲源分离存在以下情形:①对于不同类型信号的自然梯度盲源分离算法都存在一个可以计算收敛的最大的步长值ηmax。②分离信号的峭度累积量与分离信号输出状态密切相关,两次迭代之间的峭度累积量之差e(k)的变化值域和运算过程的变化斜率表现为:步长值越小,其e(k)的变化值域和运算过程的变化斜率也将变小,尤其开始阶段峭度累积量的e(k)将在越长的迭代次数中几乎无明显变化,因此达到分离信号峭度累积量预定值的迭代次数也将增长;可见固定步长自然梯度盲源分离收敛速度是与步长相关的,而当取步长取值ηmax时的盲源分离收敛速度是最快的。
因此,本发明是通过对e(k)进行变换计算为e(k),获得的e(k)>1以上的变化趋势与e(k)相同,但e(k)变化值域更大。e(k)乘上一个合适的作用系数,构成与分离输出状态密切相关的微分预测变步长增量,使迭代计算一开始就有较大的合适步长增量,得到的新的e(k)值可以加速越过原e(k)几乎不变的开始迭代计算阶段,进入加速状态。由此,构成一种动态步长闭环控制的自然梯度盲源分离系统。该闭环分离控制系统对于步长初始值η0从0<η0≤ηmax范围任意取值时,进行变步长盲源分离得到的e(k)在变化值域、变化斜率和迭代次数均具有接近一致的状态,因而能在相同分离稳定误差下达到一致数量级的最大分离收敛速度。
请参见图2、图3、图4和图5。图2是超高斯语音源信号图,图3是超高斯语音信号的混合矩阵和混合信号图;图4是欠高斯通信信号的源信号图,图5是欠高斯通信信号的混合矩阵和混合信号图。
超高斯信号源为5个语音信号(16khz采样率/16bit,15000个数据点),通过电脑声卡采集得到的数字信号。欠高斯信号源为4个通信信号,它们是符号信号、高频正弦信号、低频正弦信号和调幅调制信号,各取15000个数据点。它们是本次实施例的仿真信号。
超高斯信号在实验中取非线性函数为
初始变换矩阵w0取单位矩阵0.1*i。
请参见图6、图7、图8,以及图12、图13和图14。图6是超高斯语音混合信号固定步长自然梯度盲源分离的峭度累积量变化曲线(η0=0.8和0.9),图7是超高斯语音混合信号固定步长算法的e(k)变化曲线(η0=0.1和0.8)图,图8是超高斯混合信号固定步长算法的e(k)和对e(k)变换计算(e(k)-1)变化曲线(η0=0.1和0.8)图;图12是欠高斯语音混合信号固定步长自然梯度盲源分离的峭度累积量变化曲线(η0=0.4和0.5),图13是欠高斯语音混合信号固定步长算法的e(k)变化曲线(η0=0.1和0.4)图,图14是欠高斯混合信号固定步长算法的e(k)和对e(k)变换计算(e(k)-1)变化曲线(η0=0.1和0.4)图。
实验1:采用图3超高斯混合信号进行固定步长自然梯度盲源分离实验:①取固定步长值η0=0.8和0.9进行实验,得到图6的峭度累积量变化曲线图;②取固定步长η0=0.1和0.8进行实验,并计算出e(k)和变换计算后的e(k),得到图7的e(k)变化曲线图,以及图8的e(k)变化曲线图。
实验2:采用图5欠高斯混合信号进行固定步长自然梯度盲源分离实验:①取固定步长值η0=0.4和0.5进行实验,得到图12的峭度累积量变化曲线图;②取固定步长η0=0.1和0.4进行实验,并计算出e(k)和变换计算后的e(k),得到图13的e(k)变化曲线图,以及图14的e(k)变化曲线图。
结果分析:
从图6的峭度累积量变化曲线图可以表明,语音混合信号在固定步长取0.9时出现分离过程不收敛的发散现象,该语音混合信号分离能收敛的步长取值范围为0.1-0.8;从图12的峭度累积量变化曲线图可以表明,通信混合信号在固定步长取0.5时出现分离过程不收敛的发散现象,该通信混合信号能收敛的步长取值范围为0.1-0.4。可见,对不同混合信号的固定步长自然梯度盲源分离均存在一个能保证分离稳定性和收敛性的步长取值范围。
从图7的e(k)变化曲线图可以看出,步长越小e(k)的变化值域越小,完成达到“预设值”峭度累积量的迭代次数也越多,反映了步长值越大收敛速度越快;从图8的e(k)变化曲线图可以看出,对大于(e(k)-1)以上的值域,其变化趋势保持与e(k)值相似的变化趋势,因此该变换与分离输出状态也是保持相关的。从图13的e(k)变化曲线图可以看出,步长越小e(k)的变化值域越小,完成达到“预设值”峭度累积量的迭代次数也越多,反映了步长值越大收敛速度越快;从图14的e(k)变化曲线图可以看出,对大于(e(k)-1)以上的值域,其变化趋势保持与e(k)值相似的变化趋势,因此该变换与分离输出状态也是保持相关的。可见,本发明变换计算得到的e(k)与分离输出状态也是保持相关的。
请参见图9、图10,以及图15、图16。图9是本发明超高斯混合信号变步长算法的峭度累积量变化曲线(η0=0.1和0.8),图10是本发明超高斯混合信号变步长算法的峭度累积量e(k)变化曲线(η0=0.1和0.8);图15是本发明欠高斯混合信号变步长算法的峭度累积量变化曲线(η0=0.1和0.4),图16是本发明欠高斯混合信号变步长算法的峭度累积量e(k)变化曲线(η0=0.1和0.4)。
实验1:采用图3超高斯混合信号进行本发明的变步长盲源分离实验:取本发明的构成变步长算法,步长初始值取η0=0.1和0.8进行分离实验,得到图9的峭度累积量变化曲线,以及图10峭度累积量的e(k)变化曲线。
实验2:采用图5欠高斯混合信号进行本发明的变步长盲源分离实验:取本发明构成变步长算法,步长初始值取η0=0.1和0.4进行分离实验,得到图15的峭度累积量变化曲线,以及图16峭度累积量的e(k)变化曲线。
结果分析:
从图9峭度累积量变化曲线可以看出,由于变换了对e(k)的计算成为e(k),乘上合适的γ系数,使得计算一开始就有合适的起始变化值,改变了小步长开始段e(k)几乎为接近0的状态,由此很快进入了明显加速状态。对超高斯语音混合信号应用本发明分离实验结果表明,步长初始值取η0=0.1和0.8时达到接近一致数量级的收敛速度;从图10也表明步长初始值取η0=0.1和0.8时峭度累积量的e(k)变化曲线有接近一致的变化值域和迭代完成次数。
从图15峭度累积量变化曲线可以看出,由于变换了对e(k)的计算成为e(k),乘上合适的γ系数,使得计算一开始就有合适的起始变化值,改变了小步长开始段e(k)几乎为接近0的状态,由此很快进入了明显加速状态。对欠高斯语音混合信号应用本发明分离实验结果表明,步长初始值取η0=0.1和0.4时达到接近一致数量级的收敛速度;从图16也表明步长初始值取η0=0.1和0.8时峭度累积量的e(k)变化曲线有接近一致的变化值域和迭代完成次数。可见,取低步长初始值时输出得到的e(k)变化斜率提高了,因而也有接近步长为ηmax时的预期收敛速度。
请参见表1和表2,以及图2和图11,图5和图17。表1是本发明变步长算法(η0值取0.1-0.8及α=2和β=1.6合适取值)和固定步长算法对超高斯语音混合信号完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差;表2是本发明变步长算法(η0值取0.1-0.4及α=2和β=1.5合适取值)和固定步长算法对欠高斯语音混合信号完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差。图2是超高斯语音源信号,图11是本发明超高斯语音混合信号变步长算法的分离输出信号图(η0=0.1);图5是欠高斯通信源信号,图17是本发明欠高斯通信混合信号变步长算法的分离输出信号图(η0=0.1)。
实验1:采用图3超高斯混合信号进行本发明的变步长盲源分离实验和固定步长盲源分离实验:①取本发明的构成变步长算法,步长初始值取η0=0.1到0.8进行实验,得到表1中完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差;②采用固定步长算法,步长值取η0=0.1到0.8进行实验,得到表1中完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差。
实验2:采用图5欠高斯混合信号进行本发明的变步长盲源分离实验和固定步长盲源分离实验:①取本发明的构成变步长算法,步长初始值取η0=0.1到0.4进行实验,得到表2中完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差;②采用固定步长算法,步长值取η0=0.1到0.8进行实验,得到表2中完成分离的迭代次数、稳定达到的峭度累积量及最后的稳定误差。
结果分析:
从表1和表2可以看到:(1)采用本发明变步长算法时,超高斯混合信号分离取步长初始值0.1-0.8及指数的底α=2和β=1.6时,均分别几乎达到一致数量级的分离速度,即有接近一致的迭代次数;欠高斯混合信号分离取步长初始值0.1-0.4及指数的底α=2和β=1.5时,均分别几乎达到一致数量级的分离速度,即有接近一致的迭代次数。图8和图11也表明了这一现象。从图2超高斯语音源信号和图11本发明算法的混合信号分离输出信号(η0=0.1)比较也可见,本发明算法达到了完成分离的目的。(2)对于超高斯混合信号,本发明变步长算法取步长初始值0.1到0.8及指数的底α=2和β=1.6时,与固定步长算法取步长0.1到0.8的分离结果比较,具有相同的稳定误差;对于欠高斯混合信号,本发明变步长算法取步长初始值0.1到0.4及指数的底α=2和β=1.5时,与固定步长算法取步长0.1到0.4的分离结果比较,具有相同的稳定误差。从图5欠高斯通信源信号和图17本发明算法的混合信号分离输出信号(η0=0.1)比较可见,本发明算法也达到了完成分离的目的。
可见,采用构成变步长算法在步长初始值取0<η0≤ηmax时,是一种达到相同稳定误差下具有接近一致数量级最大收敛速度的有效方法,而且可实现自适应的特点。
表1
表2
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!