语音互动方法、装置及车辆与流程
本申请涉及语音互动技术领域,具体涉及一种语音互动方法、装置及车辆。
背景技术:
随着我国汽车工业的快速发展和人们生活水平的提高,居民家庭的汽车拥有量快速增加,汽车逐步成为了人们生活中不可或缺的交通工具之一。
智能科技的进步使得用户对汽车内的智能化体验需求越来越明显,越来越多的车载设备也拥有了智能联网功能,车载智能设备呈现百花齐放的发展态势,车载语音助手、车载空气净化器、车载移动电源等车载设备层出不穷,以满足用户在驾驶过程中不断提高的需求。车载语音助手是一款集智能语音、一键通话、网络音乐、电台定制、语音导航等功能为一体的车载智能产品,能够为用户提供更为优质的驾驶体验。
然而,现有的车载语音助手无法根据不同的场景采用不同的声音与用户进行互动,使用的语音过于单调,导致用户不愿意多听或使用,用户体验差。
技术实现要素:
本申请的目的在于,提供一种语音互动方法、装置及车辆,其可以解决上述技术问题,能够根据不同的互动场景采用不同的声音与用户进行互动,用户体验佳。
为解决上述技术问题,本申请提供一种语音互动方法,包括:
接收用户的语音信息;
根据所述语音信息确定待播放内容及当前的互动场景;
根据所述互动场景对应的预设语音包播放所述待播放内容。
其中,所述根据所述语音信息确定待播放内容及当前的互动场景,包括:
分别对所述语音信息进行声纹识别与语音识别;
根据声纹识别的结果确定用户特征,所述用户特征包括年龄、性别中的至少一种;
根据所述用户特征确定当前的互动场景;
根据语音识别得到的语音内容确定与所述语音信息对应的待播放内容。
其中,所述根据所述语音信息确定待播放内容及当前的互动场景,包括:
对所述语音信息进行语音识别;
根据语音识别得到的语音内容确定待播放内容;
根据所述语音内容或所述待播放内容的主题类型确定当前的互动场景。
其中,所述接收用户的语音信息之前,所述方法还包括:
当接收到语音包设置指令时,展示各互动场景的可选语音包,所述可选语音包包括性别关联语音包、年龄关联语音包、语速关联语音包、偏好关联语音包中的至少一种;
将用户选择的语音包设置为对应互动场景的预设语音包。
其中,所述将用户选择的语音包设置为对应互动场景的预设语音包之后,所述方法还包括:
当接收到服务器发送的语音包更新消息时,向所述服务器获取已更新的语音包;
利用所述已更新的语音包替换对应的预设语音包或可选语音包。
其中,所述方法还包括:
对历史使用的预设语音包的声音类型进行深度学习以获取所述用户在不同互动场景下的声音偏好;
根据所述声音偏好向所述用户推荐语音包,或,根据所述声音偏好更新各互动场景的可选语音包。
本申请还提供一种语音互动装置,包括处理器,所述处理器用于执行程序指令以实现的步骤包括:
接收用户的语音信息;
根据所述语音信息确定待播放内容及当前的互动场景;
根据所述互动场景对应的预设语音包播放所述待播放内容。
其中,所述处理器执行所述根据所述语音信息确定当前的互动场景及待播放内容的步骤,包括:
分别对所述语音信息进行声纹识别与语音识别;
根据声纹识别的结果确定用户特征,所述用户特征包括年龄、性别中的至少一种;
根据所述用户特征确定当前的互动场景;
根据语音识别得到的语音内容确定与所述语音信息对应的待播放内容。
其中,所述处理器执行所述根据所述语音信息确定当前的互动场景及待播放内容的步骤,包括:
对所述语音信息进行语音识别;
根据语音识别得到的语音内容确定待播放内容;
根据所述语音内容或所述待播放内容的主题类型确定当前的互动场景。
本申请还提供一种车辆,所述车辆包括如上所述的语音互动装置。
本申请的语音互动方法、装置及车辆,在接收用户的语音信息后,根据语音信息确定待播放内容及当前的互动场景,再根据互动场景对应的预设语音包播放待播放内容。通过这种方式,本申请能够根据不同的互动场景采用不同的声音与用户进行互动,用户体验佳。
上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1是根据一示例性实施例示出的一种语音互动方法的流程示意图。
图2是根据一示例性实施例示出的一种语音互动装置的结构示意图。
具体实施方式
为更进一步阐述本申请为达成预定申请目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本申请语音互动方法、装置及车辆提出的具体实施方式、方法、步骤、结构、特征及其效果,详细说明如下。
有关本申请的前述及其他技术内容、特点及功效,在以下配合参考图式的较佳实施例的详细说明中将可清楚呈现。通过具体实施方式的说明,当可对本申请为达成预定目的所采取的技术手段及功效得以更加深入且具体的了解,然而所附图式仅是提供参考与说明之用,并非用来对本申请加以限制。
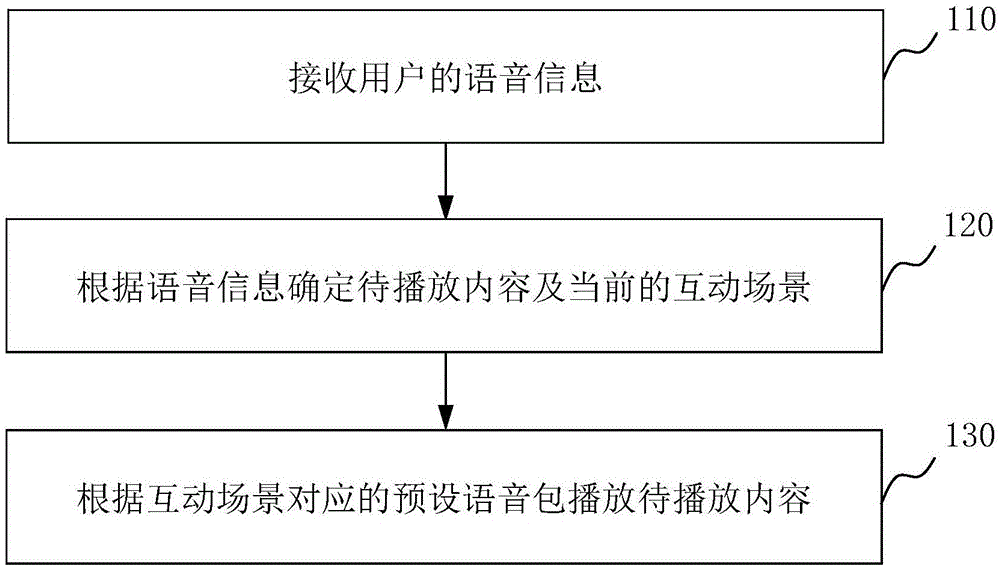
图1是根据一示例性实施例示出的一种语音互动方法的流程示意图。请参考图1,本实施例的语音互动方法,包括但不限于以下步骤:
步骤110,接收用户的语音信息。
其中,当用户需要与语音助手进行互动时,通过语音的方式说出语音指令,例如“播放天气预报”、“介绍一下附近的景点”等,车辆接收用户的语音信息并进行语音识别以获取该语音信息的语音内容,通常是转换成对应的文本信息。
步骤120,根据语音信息确定待播放内容及当前的互动场景。
其中,待播放内容可以是根据语音信息获取的一段话,例如景点导游词、天气预报内容、一段新闻等,待播放内容还可以是根据语音信息获取的预设答复内容,例如“您想听哪一类的新闻”、“是当地的天气预报吗”。互动场景是指与用户进行互动时,由当前用户的用户特征或当前待播放内容的主题所决定的符合用户心境的场景,例如年龄场景、性别场景、互动主题场景等。
在一实施方式中,根据语音信息确定待播放内容及当前的互动场景,包括:
分别对语音信息进行声纹识别与语音识别;
根据声纹识别的结果确定用户特征,用户特征包括年龄、性别中的至少一种;
根据用户特征确定当前的互动场景;
根据语音识别得到的语音内容确定与语音信息对应的待播放内容。
其中,声纹(voiceprint),是用电声学仪器显示的携带言语信息的声波频谱,声纹具有特定性及相对稳定性的特点,利用声纹特征可以进行性别分析或年龄分析,从而确认当前用户的性别、年龄等用户特征,不同的性别、年龄可能决定用户对声音的偏好,例如儿童更喜欢欢快的声音、女性更喜欢轻柔的声音等,因而不同用户特征对应不同的互动场景,例如儿童对话场景、女性对话场景、男性对话场景等。
进行语音识别时,分帧提取语音信息的语音特征信息,根据语音信息生成识别结果,也即语音信息的语音内容,接着,根据语音信息的内容进行语义解析,从识别结果的语句中抽取有效的知识,根据句子的句法结构和句中词的词义等信息,推导语音信息的意义,从而获得语义解析结果,根据语义解析结果可获取对应的待播放内容,对于较为简单的语音信息,则可在识别出语音信息的内容后,直接提取内容的关键字进行待播放内容的匹配。
在一实施方式中,根据语音信息确定待播放内容及当前的互动场景,包括:
对语音信息进行语音识别;
根据语音识别得到的语音内容确定待播放内容;
根据语音内容或待播放内容的主题类型确定当前的互动场景。
其中,进行语音识别时,分帧提取语音信息的语音特征信息,根据语音信息生成识别结果,也即语音信息的语音内容,接着,根据语音信息的内容进行语义解析,从识别结果的语句中抽取有效的知识,根据句子的句法结构和句中词的词义等信息,推导语音信息的意义,从而获得语义解析结果,根据语义解析结果可获取对应的待播放内容,对于较为简单的语音信息,则可在识别出语音信息的内容后,直接提取内容的关键字进行待播放内容的匹配。
在识别出语音信息的内容后,可根据语音内容的关键字确定当前的互动场景,互动场景不限于包括“天气播报”、“导游”、“财经类新闻”、“科技类新闻”等,例如语音信息“播放天气预报”、“介绍附近景点”、“播放财经新闻”的关键字分别为“天气预报”、“景点”、“财经新闻”,对应的互动场景可以分别为“天气播报”、“导游”、“财经类新闻”。作为另一种实施方式,还可以根据待播放内容的主题类型确定当前的互动场景,例如获取的待播放内容为景点导游词、天气预报内容、一段财经新闻,则待播放内容的主题类型分别可确定为天气预报、景点介绍、财经新闻,进而可以确定对应的互动场景可以分别为“天气播报”、“导游”、“财经类新闻”。
步骤130,根据互动场景对应的预设语音包播放待播放内容。
其中,不同的互动场景对应不同的预设语音包,预设语音包可为各互动场景默认的语音包或用户预先针对不同互动场景设置的语音包,每种互动场景的默认语音包可以有多个,例如男性、女性、年轻等多种语音包,播放语音包时,可随机进行使用或根据待播放内容自动进行选择。在本实施例中,语音包为真人发音语音包,语音包也即语音库(又称发音人),是存放声音的仓库,语音库通常都是真人按词语或句组的方式来录制声音,然后集中存储到一个数据库中,通常语音库文件越大,处理文本的能力越强,发音效果越好,越接近真人发音,互动过程更加真实。
预设语音包为各互动场景默认的语音包时,根据一般规律进行默认设置,例如,小孩对话使用老师的声音、天气预报使用电视上天气预报人的声音、历史景观介绍使用导游的声音、科技类新闻使用高科技快节奏的声音、投资类新闻使用财经类的真人发音,等。
预设语音包为用户预先针对不同互动场景设置的语音包时,在一实施方式中,在步骤110接收用户的语音信息之前,还可包括以下步骤:
当接收到语音包设置指令时,展示各互动场景的可选语音包,可选语音包包括性别关联语音包、年龄关联语音包、语速关联语音包、偏好关联语音包中的至少一种;
将用户选择的语音包设置为对应互动场景的预设语音包。
其中,当用户需要针对某互动场景进行语音包设置时,通过语音助手的操作界面触发语音包设置指令进入设置界面,选择需要进行设置的互动场景,界面展示当前选中的互动场景的可选语音包,可选语音包包括性别关联语音包、年龄关联语音包、语速关联语音包、偏好关联语音包中的至少一种,性别关联语音包为不同性别的真人发音的语音包,年龄关联语音为不同年龄段的真人发音的语音包、语速关联语音为不同语速的真人发音的语音包、偏好关联语音包是针对用户对声音类型的偏好而推荐的语音包,从而使得每一种互动场景下还可选择不同的语音包,例如“财经类新闻”可以有男性、女性、年轻等多种真人发音的选择。用户在选择某一可选语音包时,可通过语音播放的方式对语音包进行试听,若试听满意即可选择对应的语音包,将其设置为当前选中的互动场景的预设语音包。
为获取的用户偏好,在一实施方式中,本申请的语音互动方法还可包括以下步骤:
对历史使用的预设语音包的声音类型进行深度学习以获取用户在不同互动场景下的声音偏好;
根据声音偏好向用户推荐语音包,或,根据声音偏好更新各互动场景的可选语音包。
其中,在用户每次设置好语音包后,记录用户在不同互动场景下使用的预设语音包的声音类型,例如年龄、性别、语速、语调,通过历史使用的预设语音包的声音类型进行深度学习,即可得到用户在不同互动场景下的声音偏好,在得到用户的声音偏好后,根据声音偏好向用户推荐在不同互动场景下适用的语音包,或者,根据声音偏好更新各互动场景的可选语音包,使得用户在设置语音包时有更多符合偏好的选择。
在一实施方式中,在上述步骤将用户选择的语音包设置为对应互动场景的预设语音包之后,还可包括以下步骤:
当接收到服务器发送的语音包更新消息时,向服务器获取已更新的语音包;
利用已更新的语音包替换对应的预设语音包或可选语音包。
其中,已有的语音包,包括预设语音包或可选语音包,均可以在线进行自动更新和升级,实际实现时,服务器在语音包有更新时,向车辆发送的语音包更新消息,若用户设置自动更新或选择进行更新,则车辆向服务器获取已更新的语音包,并利用已更新的语音包替换对应的预设语音包或可选语音包,使得利用语音包进行语音播放的内容更加丰富、声音更加真实。
本申请的语音互动方法,在接收用户的语音信息后,根据语音信息确定待播放内容及当前的互动场景,再根据互动场景对应的预设语音包播放待播放内容。通过这种方式,本申请能够根据不同的互动场景采用不同的声音与用户进行互动,用户体验佳。
图2是根据一示例性实施例示出的一种语音互动装置的结构示意图。请参考图2,本实施例的语音互动装置包括存储器210与处理器220,存储器210存储有至少一条程序指令,处理器220通过加载并执行至少一条程序指令以实现的步骤包括:
接收用户的语音信息;
根据语音信息确定待播放内容及当前的互动场景;
根据互动场景对应的预设语音包播放待播放内容。
在一实施方式中,处理器220执行根据语音信息确定待播放内容及当前的互动场景的步骤,包括:
分别对语音信息进行声纹识别与语音识别;
根据声纹识别的结果确定用户特征,用户特征包括年龄、性别中的至少一种;
根据用户特征确定当前的互动场景;
根据语音识别得到的语音内容确定与语音信息对应的待播放内容。
其中,声纹(voiceprint),是用电声学仪器显示的携带言语信息的声波频谱,声纹具有特定性及相对稳定性的特点,利用声纹特征可以进行性别分析或年龄分析,从而确认当前用户的性别、年龄等用户特征,不同的性别、年龄可能决定用户对声音的偏好,例如儿童更喜欢欢快的声音、女性更喜欢轻柔的声音等,因而不同用户特征对应不同的互动场景,例如儿童对话场景、女性对话场景、男性对话场景等。
进行语音识别时,分帧提取语音信息的语音特征信息,根据语音信息生成识别结果,也即语音信息的语音内容,接着,根据语音信息的内容进行语义解析,从识别结果的语句中抽取有效的知识,根据句子的句法结构和句中词的词义等信息,推导语音信息的意义,从而获得语义解析结果,根据语义解析结果可获取对应的待播放内容,对于较为简单的语音信息,则可在识别出语音信息的内容后,直接提取内容的关键字进行待播放内容的匹配。
在一实施方式中,处理器220执行根据语音信息确定待播放内容及当前的互动场景的步骤,包括:
对语音信息进行语音识别;
根据语音识别得到的语音内容确定待播放内容;
根据语音内容或待播放内容的主题类型确定当前的互动场景。
其中,在识别出语音信息的内容后,可根据语音内容的关键字确定当前的互动场景,互动场景不限于包括“天气播报”、“导游”、“财经类新闻”、“科技类新闻”等,例如语音信息“播放天气预报”、“介绍附近景点”、“播放财经新闻”的关键字分别为“天气预报”、“景点”、“财经新闻”,对应的互动场景可以分别为“天气播报”、“导游”、“财经类新闻”。作为另一种实施方式,还可以根据待播放内容的主题类型确定当前的互动场景,例如获取的待播放内容为景点导游词、天气预报内容、一段财经新闻,则待播放内容的主题类型分别可确定为天气预报、景点介绍、财经新闻,进而可以确定对应的互动场景可以分别为“天气播报”、“导游”、“财经类新闻”。
在一实施方式中,处理器220执行接收用户的语音信息的步骤之前,还执行以下步骤:
当接收到语音包设置指令时,展示各互动场景的可选语音包,可选语音包包括性别关联语音包、年龄关联语音包、语速关联语音包、偏好关联语音包中的至少一种;
将用户选择的语音包设置为对应互动场景的预设语音包。
在一实施方式中,处理器220执行将用户选择的语音包设置为对应互动场景的预设语音包的步骤之后,还执行以下步骤:
当接收到服务器发送的语音包更新消息时,向服务器获取已更新的语音包;
利用已更新的语音包替换对应的预设语音包或可选语音包。
其中,已有的语音包,包括预设语音包或可选语音包,均可以在线进行自动更新和升级,实际实现时,服务器在语音包有更新时,向车辆发送的语音包更新消息,若用户设置自动更新或选择进行更新,则车辆向服务器获取已更新的语音包,并利用已更新的语音包替换对应的预设语音包或可选语音包,使得利用语音包进行语音播放的内容更加丰富、声音更加真实。
在一实施方式中,处理器220还用于执行以下步骤:
对历史使用的预设语音包的声音类型进行深度学习以获取用户在不同互动场景下的声音偏好;
根据声音偏好向用户推荐语音包,或,根据声音偏好更新各互动场景的可选语音包。
其中,在用户每次设置好语音包后,记录用户在不同互动场景下使用的预设语音包的声音类型,例如年龄、性别、语速、语调,通过历史使用的预设语音包的声音类型进行深度学习,即可得到用户在不同互动场景下的声音偏好,在得到用户的声音偏好后,根据声音偏好向用户推荐在不同互动场景下适用的语音包,或者,根据声音偏好更新各互动场景的可选语音包,使得用户在设置语音包时有更多符合偏好的选择。
本实施例的语音互动装置中处理器220的具体工作过程及步骤请参考图1所示实施例的描述,在此不再赘述。
本申请还提供一种车辆,所述车辆包括如上所述的语音互动装置。
本申请的语音互动装置及车辆,在接收用户的语音信息后,根据语音信息确定待播放内容及当前的互动场景,再根据互动场景对应的预设语音包播放待播放内容。通过这种方式,本申请能够根据不同的互动场景采用不同的声音与用户进行互动,用户体验佳。
以上所述,仅是本申请的较佳实施例而已,并非对本申请作任何形式上的限制,虽然本申请已以较佳实施例揭露如上,然而并非用以限定本申请,任何熟悉本专业的技术人员,在不脱离本申请技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本申请技术方案内容,依据本申请的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本申请技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!