一种快速编码广播用数字音频的方法与流程
本发明涉及数字音频编解码技术领域,尤其是涉及一种可以并行处理的快速编码广播用数字音频的方法。
背景技术:
广播用音频数据文件需要进行编解码操作,当音频文件较大时,例如24小时音频,则编解码过程耗时较长,处理器利用率不高。
技术实现要素:
本发明主要是解决现有技术所存在的音频文件编码耗时较长、效率较低的技术问题,提供一种可以充分利用多核cpu或gpu、具有较高处理器利用率的快速编码广播用数字音频的方法。
本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种快速编码广播用数字音频的方法,包括以下步骤:
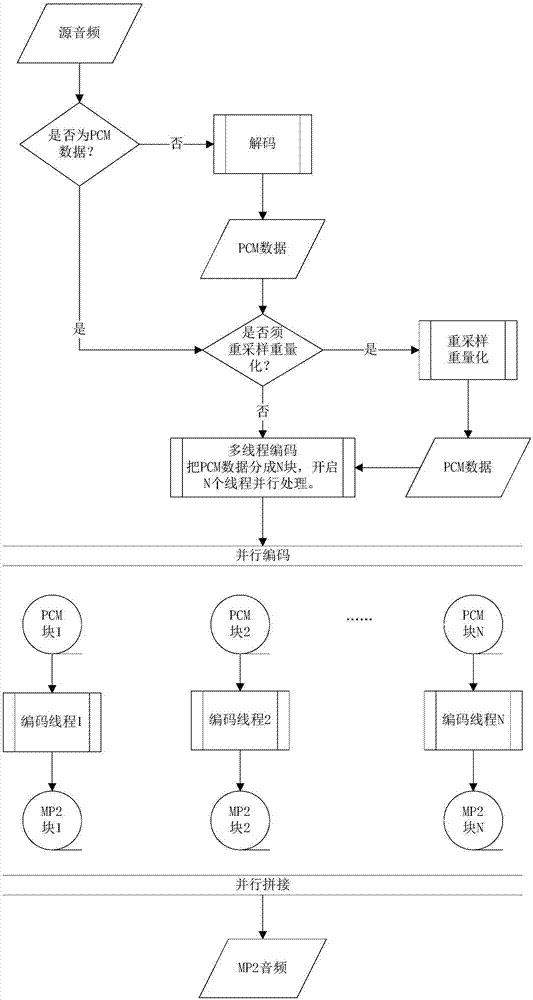
s1、把源音频文件转换为pcm数据;
s2、将pcm数据切分成若干块,并给每块数据按先后顺序打上标签;
s3、将切分后的数据送入cpu或gpu进行并行编码运算;
s4、将编码完成的音频数据按标签顺序进行合并,生成最终的数字音频文件。
本方案将数据切分以后送入处理器并行处理,在当前处理器基本为多核处理器的情况下,可以每个核心处理一块数据,多线程并发,有效提高处理速度。
作为优选,所述步骤s1具体为:
s101、判断源音频是否为pcm数据,如果是,则跳转到步骤s103,否则进入步骤s102:
s102、对源音频数据解码生成pcm数据,然后进入步骤s103;
s103、判断pcm数据与目标音频mp2的采样率、位深度和声道数量是否一致,如果其中任一参数不一致则进入步骤s104,如果所有参数均一致则进入步骤s2;目标音频mp2的采样率、位深度、声道数量,是编码前人为或程序默认输入的参数;
s104、对源数据进行重采样和重量化,然后进入步骤s2。重采样和重量化后的数据即为pcm数据,不需要解码操作。
作为优选,步骤s1中,源音频为可以用ffmpeg或libav开源库完成通用解码,生成pcm数据的音频数据。
作为优选,每块数据的大小schunk由以下公式组确定:
式中,p为帧填充的最小周期值,cf为单位帧所含样本信息的数量,nbitdepth为位深,nchannel为声道数量,ceil(float)为向上取整函数,spcm为pcm数据总大小,sframe为单位帧数据大小。cf:对于mp1每帧固定为384个样点信息,对于mp2每帧固定为1152个样点信息。nbitdepth:位深为编码前人为或程序默认输入的参数,一般默认为16bit。nchannel:声道数为编码前认为或程序默认输入的参数,一般为立体声,即2个声道。
作为优选,帧填充的最小周期值p由以下公式组确定:
式中,rb为位率,ss为单位槽所占字节数,fs为采样率,gcd(number1,number2)为求number1,number2的最大公约数函数。rb:位率,可在编码前人为或程序输入的参数,也可通过单位帧样点数、采样率、声道数等参数计算得出,一般作为输入项。ss:对于mp1一个槽占4个字节,对于mp2一个槽占1个字节。fs:采样率为编码前人为或程序输入的参数。
作为优选,帧填充的最小周期值p由以下公式组确定:
式中,rb为位率,ss为单位槽所占字节数,fs为采样率,lcm(number1,number2)为求number1,number2的最小公倍数函数。
本发明带来的实质性效果是,可以缩短编解码过程,提高处理器利用率。
附图说明
图1是本发明的一种流程图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:本实施例的一种快速编码广播用数字音频的方法,包括以下步骤:
【步骤一】解码成pcm数据:把源音频文件解码成pcm数据后,进行步骤二。
【步骤二】把pcm数据切分成n块:按照“公式组1”或“公式组2”计算帧填充的最小周期值p。再按照“公式组3”把pcm数据切分成n块(对应n个线程),每块大小为schunk(最后一个分块大小不恒等于schunk),并按先后顺序打标签后,进行步骤三。
算法公式:
①公式组1:
②公式组2:
③公式组3
公式中符号:
p:帧填充的最小周期值。
lcm(number1,number2):数学函数,求number1,number2的最小公倍数。
gcd(number1,number2):数学函数,求number1,number2的最大公约数。
fs:采样率,单位是hz;一般有32khz、44.1khz、48khz等。
cf:单位帧所含样本信息的数量。
ss:单位槽所占字节数,1byte=8bit。
rb:位率,单位是bit/s。
spcm:pcm数据总大小,即总字节数,单位是byte。
nbitdepth:位深,例如:8(bit)、16(bit)、24(bit)、32(bit)。
nchannel:声道数量,例如:单声道为1,立体声/双声道为2。
ceil(float):数学函数,向上取整。
sframe:单位帧数据大小,单位是字节。
schunk:pcm分块数据大小,单位是字节。
n:并行处理开启的线程数,线程数∈[1*处理器核数,1.5*处理核数]在这个范围内即可,只要cpu利用率达到100%即可。
*:乘法运算符。
%:取模运算符。
【步骤三】送入cpu或gpu进行并行编码运算,将编码完成的音频数据按标签顺序进行合并(可多线程合并),生成最终的数字音频文件。
图1是本实施例的流程图。
实例如下:
用pcm原始音频数据做测试,转码成mp2:
(1)系统环境:
操作系统:windowsserver2008r2x64sp1
处理器:inter(r)core(tm)i5-4590cpu@3.30ghz
内存(ram):12g
(2)源音频:
pcm,48000hz,16bit,2声道,时长1:00:00,691,200,000字节。
(3)目标音频:
mp2,48000hz,256000bit/s,2声道,时长1:00:00,115,200,000字节。
测试结果:
(1)因测试过程中,测试pc同时运行开发工具等其他耗资源程序,该结果仅供说明多线程编码较单线程有明显增速。
(2)另,不同音频编解码库对帧的封装有所不同,以ffmpeg为例,当对各分块(首块除外)pcm数据编码时,编码首帧须“重编码”或“多取1帧数据并遗弃该帧数据”。
(3)gpu编码:以nvidiageforcegtx1080ti显卡为例,其核心数量为3584个,加速频率为1582mhz。可同时开启3584个线程并行处理。那么理论上gpu的增速幅度会更明显。
相关术语
pcm脉冲编码调制:脉冲编码调制(pulse-codemodulation,pcm)是一种模拟信号的数字化方法。
位流bitstream:在gb/t17191中,位流是音频信号的编码表示。
编码encoding:编码是信息从一种形式或格式转换为另一种形式的过程。在gb/t17191中没有规定的一种处理,读取输入的音频样值流,以产生一个符合gb/t17191中定义的有效的位流。
解码decoding:解码,是编码的逆过程。在gb/t17191中定义的处理,即读入编码的位流并产生解码音频采样值。
声道soundchannel:是指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号,所以声道数也就是声音录制时的音源数量或回放时相应的扬声器数量。
采样率samplerate:采样率,也称为采样速度、采样频率,定义了每秒从连续信号中提取并组成离散信号的采样个数,单位赫兹(hz)。常用的表示符号是fs。
位率bitrate:位率,即位速率,也称比特率、码率,是单位时间内传输送或处理的比特的数量。使用“比特每秒”(bit/s或bps)为单位。可用符号rb表示。
位深bitdepth:在使用pcm数字音频中,位深度是每个样本中信息的位数,它直接对应于每个样本的分辨率。位深度的示例包括每个样本使16bits的光盘数字音频,以及每个样本可以支持多达24bits的dvd音频和蓝光光盘。也有称量化精度、量化位数、采样精度、采样位数等,含义基本一致。比特深度仅对pcm数字信号有意义。非pcm格式(例如有损压缩格式)没有相关的位深度。
层layer:在gb/t17191中,层是音频系统编码层次的一个层次。
音频存取单元audioaccessunit:在gb/t17191中,对层ⅰ和ⅱ,音频存取单元定义为可由自身进行解码的编码位流的最小部分。其中解码是指“完全重构的声音”。
帧frame:在gb/t17191中,与从音频存取单元的音频pcm样值相对应的部分音频信号。一帧含有样点信息的数量可用符号cf表示。
槽slot:在gb/t17191中,槽是位流的一个基本部分。在层ⅰ中,一个槽为4个字节;在层ⅱ中,一个槽为1个字节。一个槽字节数可用符号ss表示。
填充padding:在gb/t17191中,通过有条件地在音频帧中加入一槽来调整音频帧的平均时间长度,使其与对应的pcm数据采样值的持续期相适应。
最小公倍数lcm:lowestcommonmultiple的简写。lcm(number1,number2,...,numbern),求number1,number2,...,numbern的最小公倍数。
最大公约数gcd:greatestcommondivisor的简写,也称最大公因数(gch)。gcd(number1,number2,...,numbern),求number1,number2,...,numbern的最大公约数。
本方案对源音频没有严格的格式要求,只要是常用的音频格式,可以用ffmpeg/libav等开源库完成通用解码,生成pcm数据即可。
解码后的pcm数据是否需要重采样重量化的判断依据是:pcm数据与目标音频mp2的采样率、位深度、声道数量等参数是否一致,如果一致则不需要,任一参数不一致则需要。
并行编码:开启n个线程并行处理,把pcm数据分成n块,每块大小为schunk(最后一个分块大小不恒等于schunk)。mp2编码过程为通用编码,可使用ffmpeg/libav等开源库完成。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了pcm、块、帧等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 还没有人留言评论。精彩留言会获得点赞!