智能家居系统控制实现方式的制作方法
本发明智能家居技术领域,具体讲就是涉及一种将智能语音面板与智能家居系统相结合的智能家居系统控制实现方式。
背景技术:
目前市面上智能家居设备的控制方式分为两类:直接接触控制和人间接接触控制。直接接触控制可分为:按键控制和触摸控制;间接接触控制可分为:传感器控制和通信控制。其中传感器控制又分为:人体红外传感器、人脸识别和语音识别等。
随着智能家居行业的发展,在语音控制领域,市面上智能音响正是行业发展的产物。但是对于用户来说,音响可能并不是家居必备的产品,而且价格普遍较高,单个产品并不能支撑整个家庭的使用,而且还占用空间。二传统家居设备控制面板(开关、插座、网口等),在行业发展的变革中,趋于安装在墙内。在ai人工智能大爆炸的社会环境下,语音识别技术快速发展,其中声纹、语义的识别是实现人机交互尤为重要的条件。现有的面板类产品一般都是通过按键或者通过无线连接手机进行控制,存在输入方式单一化,必须手动操作,体验感差的特点。同时传统的面板也不支持身份识别权限管理的功能。
因此,将智能面板增加语音识别功能后与现有智能家居系统进行融合在一整套系统中成为亟待解决的技术难题。
技术实现要素:
本发明的目的就是针对上述现有的单独的智能面板和智能家居系统互相独立工作不融合的技术缺陷,提供一种智能家居系统控制实现方式,将智能语音面板与智能家居系统相结合,实现通过语音输入的方式控制家居产品,解放了双手。同时支持声纹识别,通过声纹特征值得提取与比对,实现身份识别,可根据身份匹配不同的操作权限,分配不同的场景。通过简单唤醒词以及语音指令即可与家居交流,并可以通过大数据分析不同的用户习惯,给用户推荐专属的场景,让用户获得专属的体验。
技术方案
为了实现上述技术目的,本发明提供的智能家居系统控制实现方式,其特征在于,它包括以下几个步骤:
(1)智能语音面板根据不同用户声音音色和音域等声音特点提取特征值并保存命名为不同的用户,将用户的语音操作按照相应的格式和协议内容转化后发送给家庭中控;
(2)家庭中控主机中预先设定不同用户的操作权限,家庭中控主机接收到智能语音面板上传来的指令后首先会检验该指令格式以及校验码是否正确,如果错误则会要求智能语音面板重发;
如果正确则会解析该指令判断该用户是否有权限执行对应的智能家居设备,如果没有权限,家庭中控主机则通过指令回复智能语音面板该用户没有权限执行对应的智能家居设备;如果有权限,家庭中控主机则通过指令回复给智能语音面板相应的智能家居设备即将执行指令,同时将指令下发给智能家居设备,智能语音面板接收到家庭中控主机反馈的指令后,则回复给用户智能家居设备s30已按照你的要求执行。
(3)智能家居设备接收到家庭中控主机下发的指令执行后会将执行结果或者数据反馈给家庭中控主机,家庭中控主机会根据预先的设置将用户关心的数据反馈给智能语音面板,智能语音面板通过语音合成播报相应的信息给用户。
进一步,所述智能语音面板在步骤(1)中根据不同用户声音音色和音域等声音特点提取特征值并保存命名为不同的用户的过程包括智能语音面板内部逻辑实现,智能语音面板声纹录入命名和智能语音面板声纹语音应用;
其中,
所述智能语音面板内部逻辑的实现方式包括以下几个步骤:
(1)线性麦克风阵列前端采集用户的声音信息;
(2)音频ad电路a将步骤(1)采集到的音频模拟信号转为音频pcm信号;
(3)处理器平台读取音频ad电路a输送的数字音频pcm信号并处理;
所述处理器平台对音频信号的处理包括;唤醒词声纹特征值的提取以及比对,语音的解析,语义的理解;
(4)功放电路将处理平台输出的音频信号进行放大并输送给扬声器*2模块,进而语音播报,实现与用户语音交互功能;
(5)音频ad电路b将功放电路的输出的音频模拟信号转化为数字信号pcm,处理器平台采集处理音频ad电路b的音频pcm信号,实现音频信号的回采,处理器平台通过对比处理音频a电路a的音频信号与音频ad电路b的信号,实现回声消除的功能,实现更好的用户体验;
所述智能语音面板声纹录入命名的实现方式包括以下几个步骤:
(1)声音采集模块采集用户特定预定好的唤醒词的语音信息;
(2)声音处理模块对步骤(1)采集的声音信息进行处理,所述声音模块功能包括声源定位和噪声消除;
(3)声纹特征值提取模块提取由声音处理模块处理后的用户声音的特征值,所述声纹特征值包括音色、音域、模糊特征;
(4)声纹命名保存模块将声纹特征值提出模块提取的用户声纹特征命名并保存,用于后续的用户声纹识别。
所述能语音面板声纹语音应用的实现方式包括以下几个步骤:
(1)声音采集模块采集用户特定预定好的唤醒词的语音信息;
(2)声音处理模块对声音信息进行处理;所述声音模块功能包括但不限于声源定位和噪声消除。
(3)声纹特征值提取模块提取由声音处理模块处理后的用户声音的特征值,所述声纹特征值包括但不限于音色、音域和模糊特征。
(4)声纹特征值对比模块将声纹特征值提取模块获得的声音特征值与声纹命名保存模块保存的声纹内容对比,进而匹配得到用户的身份。
(5)声纹唤醒模块用于唤醒语音处理模块,所述声纹唤醒模块在声纹特征值对比模块对比成功后才会唤醒语音处理模块。
(6)语音处理模块用于将由声音处理模块处理后的音频转换为文本格式,所述语音处理模块在声纹唤醒模块触发条件下才会进入工作状态。
(7)语义处理模块用于将声音处理模块处理后音频文件进行语义理解,所述语义处理模块可通过大数据分析,对比,锻炼,学习方法解析语义。
(8)数据上传模块将语义处理模块解析的语义以及声纹特征值对比模块获得的用户身份按照相应的协议上传给上一级的处理单元;
(9)上一级的处理单元执行数据上传模块上传的指令以及反馈信息;
上一级的处理单元通过数据上传模块上传的用户身份按照预定的权限发放权限;
上一级的处理单元可通过数据上传模块上传的用户身份统计当前用户的生活习惯,给用户派生推荐场景,提供人性化需求。
本发明提供一种智能家居系统控制实现方式,将智能语音面板与智能家居系统相结合,实现通过语音输入的方式控制家居产品,解放了双手。同时支持声纹识别,通过声纹特征值得提取与比对,实现身份识别,可根据身份匹配不同的操作权限,分配不同的场景。通过简单唤醒词以及语音指令即可与家居交流,并可以通过大数据分析不同的用户习惯,给用户推荐专属的场景,让用户获得专属的体验。
附图说明
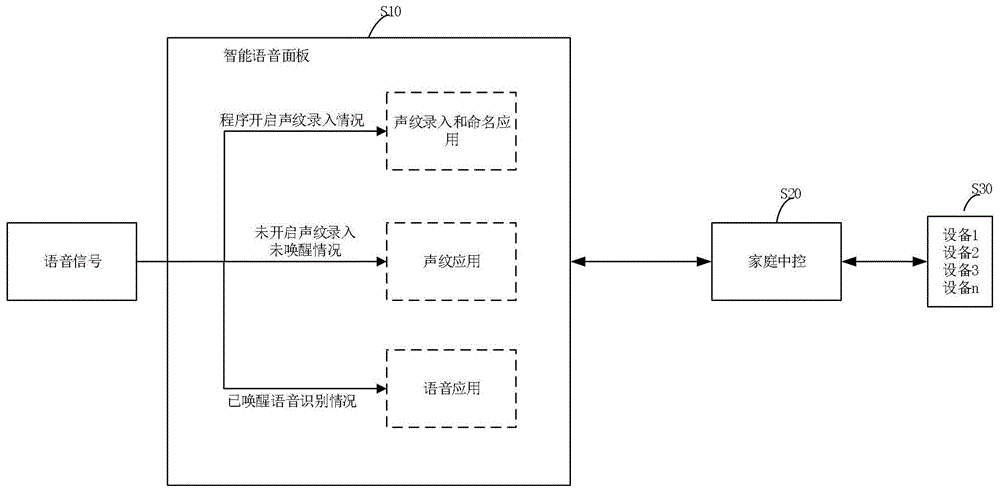
附图1是本发明实施例的系统连接图。
附图2是本发明实施例中智能语音面板内部逻辑流程图。
附图3是本发明实施例中智能语音面板声纹录入命名的流程图。
附图4是本发明实施例中智能语音面板声纹语音应用的的流程图。
具体实施方式
下面结合附图和实施例,对本发明做详细说明。
实施例
如附图1所示,智能家居系统控制实现方式,它包括以下几个步骤:
(1)智能语音面板s10根据不同用户声音音色和音域等声音特点提取特征值并保存命名为不同的用户,将用户的语音操作按照相应的格式和协议内容转化后发送给家庭中控主机s20;
(2)家庭中控主机s20中预先设定不同用户的操作权限,家庭中控主机s20接收到智能语音面板s10上传来的指令后首先会检验该指令格式以及校验码是否正确,如果错误则会要求智能语音面板s10重发;
如果正确则会解析该指令判断该用户是否有权限执行对应的智能家居设备s30,如果没有权限,家庭中控主机s20则通过指令回复智能语音面板s10该用户没有权限执行对应的智能家居设备s30;如果有权限,家庭中控主机s20则通过指令回复给智能语音面板s10相应的智能家居设备s30即将执行指令,同时将指令下发给智能家居设备s30,智能语音面板s10接收到家庭中控主机s20反馈的指令后,则回复给用户智能家居设备s30已按照你的要求执行。
(3)智能家居设备s30接收到家庭中控主机s20下发的指令执行后会将执行结果或者数据反馈给家庭中控主机s20,家庭中控主机s20会根据预先的设置将用户关心的数据反馈给智能语音面板s10,智能语音面板s10通过语音合成播报相应的信息给用户。
所述智能语音面板s10在步骤(1)中根据不同用户声音音色和音域等声音特点提取特征值并保存命名为不同的用户的过程包括智能语音面板内部逻辑实现,智能语音面板声纹录入命名和智能语音面板声纹语音应用;
其中,
如附图2所示,所述智能语音面板内部逻辑的实现方式包括以下几个步骤:
(1)线性麦克风阵列s101前端采集用户的声音信息;
(2)音频ad电路as102将步骤(1)采集到的音频模拟信号转为音频pcm信号;
(3)处理器平台s105读取音频ad电路as102输送的数字音频pcm信号并处理;
所述处理器平台s105对音频信号的处理包括;唤醒词声纹特征值的提取以及比对,语音的解析,语义的理解;
(4)功放电路s106将处理平台s105输出的音频信号进行放大并输送给扬声器*2s107模块,进而语音播报,实现与用户语音交互功能;
(5)音频ad电路bs108将功放电路s106的输出的音频模拟信号转化为数字信号pcm,处理器平台s105采集处理音频ad电路bs108的音频pcm信号,实现音频信号的回采,处理器平台s105通过对比处理音频a电路as102的音频信号与音频ad电路bs108的信号,实现回声消除的功能,实现更好的用户体验;
整个智能家居系统中wifi模块s104电路将语音面板处理器平台s105与中控s20无线的连接;
按键电路s103用于开关机,组网,音量加,音量减,静音的操作;
usb调试接口s120用于功能调试,提高产品的研发的效率以及解决后续生产和维护过程中问题;
调试工作指示灯s109用于工作状态指示,便于直观了解设备软硬件的工作状态。
如附图3所示,所述智能语音面板声纹录入命名的实现方式包括以下几个步骤:
(1)声音采集模块1采集用户特定预定好的唤醒词的语音信息;
(2)声音处理模块2对步骤(1)采集的声音信息进行处理,所述声音模块2功能包括声源定位和噪声消除;
(3)声纹特征值提取模块3提取由声音处理模块2处理后的用户声音的特征值,所述声纹特征值包括音色、音域、模糊特征;
(4)声纹命名保存模块4将声纹特征值提出模块3提取的用户声纹特征命名并保存,用于后续的用户声纹识别。
如附图4所示,所述能语音面板声纹语音应用的实现方式包括以下几个步骤:
(1)声音采集模块11采集用户特定预定好的唤醒词的语音信息;
(2)声音处理模块12对声音信息进行处理;所述声音模块12功能包括但不限于声源定位和噪声消除。
(3)声纹特征值提取模块13提取由声音处理模块12处理后的用户声音的特征值,所述声纹特征值包括但不限于音色、音域和模糊特征。
(4)声纹特征值对比模块14将声纹特征值提取模块13获得的声音特征值与声纹命名保存模块4保存的声纹内容对比,进而匹配得到用户的身份。
(5)声纹唤醒模块15用于唤醒语音处理模块16,所述声纹唤醒模块15在声纹特征值对比模块14对比成功后才会唤醒语音处理模块16。
(6)语音处理模块16用于将由声音处理模块12处理后的音频转换为文本格式,所述语音处理模块16在声纹唤醒模块15触发条件下才会进入工作状态。
(7)语义处理模块17用于将声音处理模块12处理后音频文件进行语义理解,所述语义处理模块17可通过大数据分析,对比,锻炼,学习方法解析语义。
(8)数据上传模块18将语义处理模块17解析的语义以及声纹特征值对比模块14获得的用户身份按照相应的协议上传给上一级的处理单元;
(9)上一级的处理单元执行数据上传模块18上传的指令以及反馈信息;
上一级的处理单元通过数据上传模块18上传的用户身份按照预定的权限发放权限;
上一级的处理单元可通过数据上传模块18上传的用户身份统计当前用户的生活习惯,给用户派生推荐场景,提供人性化需求。
根据上述说明书的揭示和教导,本发明所属领域的技术人员还能够对上述实施方式进行变更和修改。因此,本发明并不局限于上述的具体实施方式,凡是本领域技术人员在本发明的基础上所作出的任何显而易见的改进、替换或变型均属于本发明的保护范围。
此外,尽管本说明书中使用了一些特定的术语,但这些术语只是为了方便说明,并不对本专利构成任何限制。
- 还没有人留言评论。精彩留言会获得点赞!