一种基于时变多段式频谱的音色拟合系统的制作方法
本发明涉及一种乐器领域,具体的说,是一种基于时变多段式频谱的音色拟合系统。
背景技术:
弦乐器的发声方式是通过弦振动发声,而反应振动现象最基本的物理量就是频率,简单周期振动只有一个频率。而复杂运动不能用一个频率描写它的运动情况,频谱是频率的分布曲线,是将振动幅值按频率大小排列的图形,因此通常采用频谱来描写一个复杂的振动情况。音色是声音的听觉感知特性,是不同的声音的频率表现在波形方面的特性。不同的物体振动都有不同的特点,因此音色也各不相同。任何一个普通的音色都是由若干谐音组成,即由若干谐波构成,是一种复杂振动,因此,可以通过分析不同乐器发出的音符中谐波的频谱来区分不同乐器的音色。
现有的弦乐器设备通常都只具有一种单一的音色,而在实际演出或使用中,往往需要用到多种不同音色的弦乐器设备,这就需要携带多种不同音色的弦乐器设备外出,且在演奏的间隙频繁的更换以匹配演奏所需的音色,既花费时间实际操作起来又相当不方便。因此,现有技术中已出现一些可模拟多种弦乐器设备音色的装置,从而在实际应用中不用频繁更换弦乐器设备。
如美国专利文献us10115381b2中公开了一种模拟弦乐器音色的装置,该专利中通过获取由源乐器的弦的振动产生的输入电信号;通过将目标乐器的声音特征与所述源乐器的声音特征相关联来获得传递函数,所述声音特征分别包括在所述目标乐器上播放的一系列音符的平均频谱和在所述源乐器上播放的相应音符范围的平均频谱;对由所述源乐器产生的所述电信号进行滤波,将所述传递函数应用于所述电信号,从而能够通过修改源乐器的声音音色直到它与目标乐器的音色完全相同。但是上述专利仍存在不足之处,因为每个音符从音头到音尾的频谱都是变化的,而且其变化规律也是不一样的,因此,将声音特征设置为一段音符的平均频谱,不能准确反应该段音符的声音特征,因此模拟出来的结果仍不够精确。
技术实现要素:
为解决现有技术中的缺点,本发明提供了一种基于时变多段式频谱的音色拟合系统,其根据振幅值大小将音符进行分段,使声音特征包括多个分别处于各振幅段内的音符的频谱,从而更接近实际频谱变化的规律,因而使模拟出的同一类型的另一种弦乐器的音色更相似。
本发明采用的技术方案为:一种基于时变多段式频谱的音色拟合系统,包括用于获取乐器音频信号的输入装置和分段式多模型补偿模块,所述分段式多模型补偿模块分别学习源乐器和目标乐器的音色,建立源乐器声音特征的多段式模型和目标乐器声音特征的多段式模型,所述声音特征设置为以在目标乐器和源乐器上演奏相同序列的音频信号的振幅最大值为基准,将该段序列音频信号按照振幅大小分成多段,所述声音特征包括多个分别处于各振幅段内的音符的频谱,所述分段式多模型补偿模块基于源乐器声音特征和目标乐器声音特征的差异建立含时变增益的多模型结构,通过所述多模型结构使源乐器声音特征和目标乐器声音特征的差异最小化,所述音色拟合系统适用于弦乐器音色的模拟。
所述多模型结构的时变增益值是根据音频信号的振幅值大小来选择的,其中根据振幅值大小,所述时变增益值设置为稳定段和过渡段,相邻两振幅段的时变增益值的交点为相邻两过渡段时变增益曲线的中点,相邻两振幅段的相邻两过渡段的时变增益值之和为1。
所述相邻两振幅段的界限点设置为在相邻两振幅段的时变增益值交点所对应的振幅值上下浮动一定值。
本发明在模拟弦乐器的音色时,首先由输入装置从源乐器和目标乐器弹奏的音符中获得模拟电信号,由输入装置获取的电信号随后被发送到模数转换器,该模数转换器将具有连续级数的模拟电信号(特别是电压)转换为具有一系列离散值的数字信号。在模数转换之后,处理装置(通常由处理器或cpu组成)处理数字信号,从而定义对应于电信号来源的源乐器和目标乐器的声音特征,声音特征分别包括源乐器和目标乐器的多个分别处于各振幅段内的音符的频谱,该频谱识别即对应于源乐器和目标乐器的声音音色。含分段式多模型补偿模块的处理器基于源乐器和目标乐器声音特征的差异,建立含时变增益的多模型结构,并将模型参数存储于存储器中。在实际运行时,对由源乐器产生的电信号进行滤波,将含时变增益值的多模型结构应用于由源乐器的弦的振动产生的输入电信号,从而能够通过修改源乐器的声音音色直到它与目标乐器的音色差异最小化。
采用本发明的技术方案,其有益效果为:根据振幅值大小将音符进行分段,使声音特征包括多个分别处于各振幅段内的音符的频谱,与采用整段音符的平均频谱相比,本发明的设置更接近实际频谱变化的规律,因而在模拟同一类型的另一种弦乐器的音色时,其音色会更相似。
附图说明
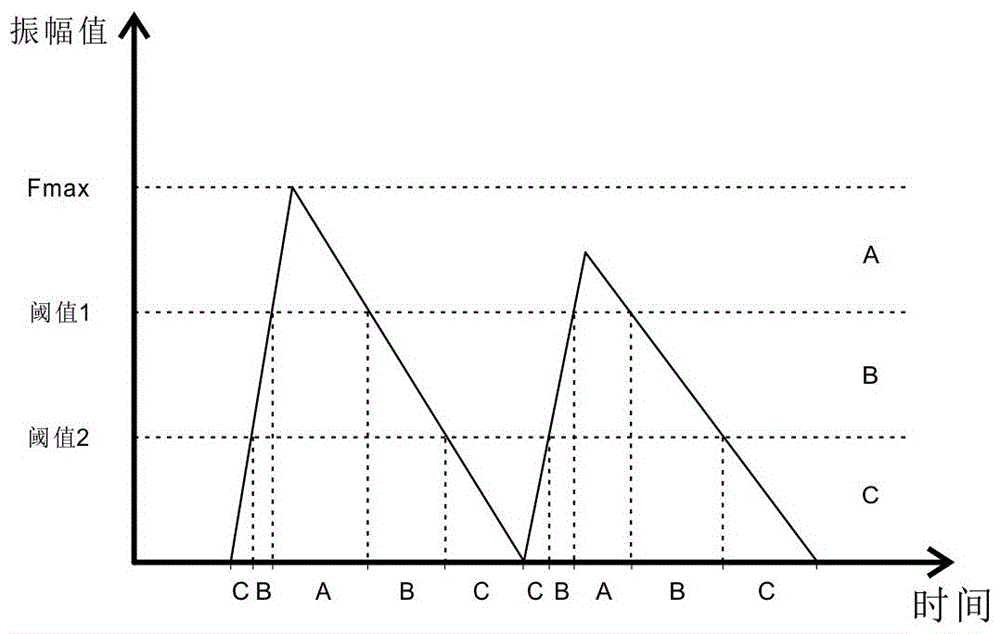
图1是本发明实施例的频谱与振幅分段的关系。
图2是本发明实施例的时变增益值随振幅变化的关系。
图3是本发明实施例的源乐器拟合为目标乐器的运行图。
具体实施方式
下面结合附图和具体实施方式对本发明的技术方案作进一步的详细说明。
一种基于时变多段式频谱的音色拟合系统,其适用于弦乐器音色的模拟,包括用于获取乐器音频信号的输入装置和分段式多模型补偿模块,所述分段式多模型补偿模块分别学习源乐器和目标乐器的音色,建立源乐器声音特征的多段式模型和目标乐器声音特征的多段式模型,如图1所示,在源乐器和目标乐器上演奏相同序列的音符,以该段音符的振幅最大值fmax为基准,将该段序列音符按照振幅大小均分成三段,形成a、b、c三个振幅段后,声音特征分别包括源乐器和目标乐器的多个分别处于a、b、c三个振幅段内的音符的频谱,分段式多模型补偿模块基于源乐器声音特征和目标乐器声音特征的差异建立含时变增益(a,b,c)的多模型结构(fir(a)-fir(b)-fir(c)),通过所述多模型结构(fir(a)-fir(b)-fir(c))使源乐器声音特征和目标乐器声音特征的差异最小化。其中音符的分段形式,即是否均分、分成几段,可根据实际情况自行调整。
多模型结构(fir(a)-fir(b)-fir(c))的时变增益值(a,b,c)是根据音频信号的振幅值大小来选择的,如图2所示,其中根据振幅值大小,所述时变增益值(a,b,c)设置为稳定段和过渡段,在稳定段时,各时变增益值(a,b,c)的取值为1,在过渡段时,各时变增益值(a,b,c)的取值由1-0过渡或者由0-1过渡,相邻两振幅段的时变增益值的交点为相邻两过渡段时变增益曲线的中点,如c1c2段与b1b3段交点m1为c1c2段与b1b3段的中点,a1a2段与b2b4段交点m2为a1a2段与b2b4段的中点,相邻两振幅段的相邻两过渡段的时变增益值之和为1,如c1c2段与b1b3段的时变增益值c与b之和为1,a1a2段与b2b4段的时变增益值a与b之和为1。
相邻两振幅段的界限点设置为在相邻两振幅段的时变增益值交点所对应的振幅值上下浮动一定值,如b1、c1设置在m1所对应的振幅值上下浮动一定值,a1、b2设置在m2所对应的振幅值上下浮动一定值,从而保证相邻两振幅段的时变增益值的交点为相邻两过渡段时变增益曲线的中点。
本发明的基于时变多段式频谱的音色拟合系统,包括用于获取源乐器和目标乐器电信号的输入装置、模数转换器、处理装置(含分段式多模型补偿模块)、存储器、数模转换器。在模拟弦乐器的音色时,首先,输入装置从源乐器和目标乐器弹奏的音符中获得模拟电信号,由输入装置获取的电信号随后被发送到模数转换器,该模数转换器将具有连续级数的模拟电信号(特别是电压)转换为具有一系列离散值的数字信号。在模数转换之后,处理装置(通常由处理器或cpu组成)处理数字信号,从而定义对应于电信号来源的源乐器和目标乐器的声音特征,声音特征分别包括源乐器和目标乐器的多个分别处于各振幅段内的音符的频谱,该频谱识别即对应于源乐器和目标乐器的声音音色。处理器基于源乐器和目标乐器声音特征的差异,建立含时变增益的多模型结构,并将模型参数存储于存储器中。如图3所示,在实际运行时,对由源乐器产生的电信号进行滤波,将含时变增益值的多模型结构应用于由源乐器的弦的振动产生的输入电信号,从而能够通过修改源乐器的声音音色直到它与目标乐器的音色差异最小化,并通过数模转换器输出新的电信号,发送给放大器或扬声器,这种新电信号具有与目标乐器差异最小的声音音色。
上述实施例仅为本发明的优选方案,并非作为对本发明的进一步限定,不能以此来限制本发明的保护范围,凡是根据本发明精神实质所作的等效变化或修饰,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!