家电设备的多模态交互方法及系统与流程
本发明涉及家用电器语音识别技术,特别涉及家电设备的多模态交互方法及系统的技术。
背景技术:
在智能设备交互过程中,目前较常用的交互方式是语音交互,通过获取的语音参数控制家电设备的运转或者搜索服务。但是单一的语音参数存在误识别,特别是当周围环境噪音大、距离较远时,更加大误识别的概率。同时,目前的语音交互是先需要激活词唤醒设备的强交互模式,操作不便,交互方式不友好。综上,现有的家电设备交互方法和系统存在着误识别、依赖激活词和交互不友好的问题。
技术实现要素:
本发明的目的是提供一种家电设备的多模态交互方法及系统,解决传统单一的语音交互存方式在的误识别、依赖激活词和交互不友好的问题。
本发明解决其技术问题,采用的技术方案是:家电设备的多模态交互方法,包括以下步骤:
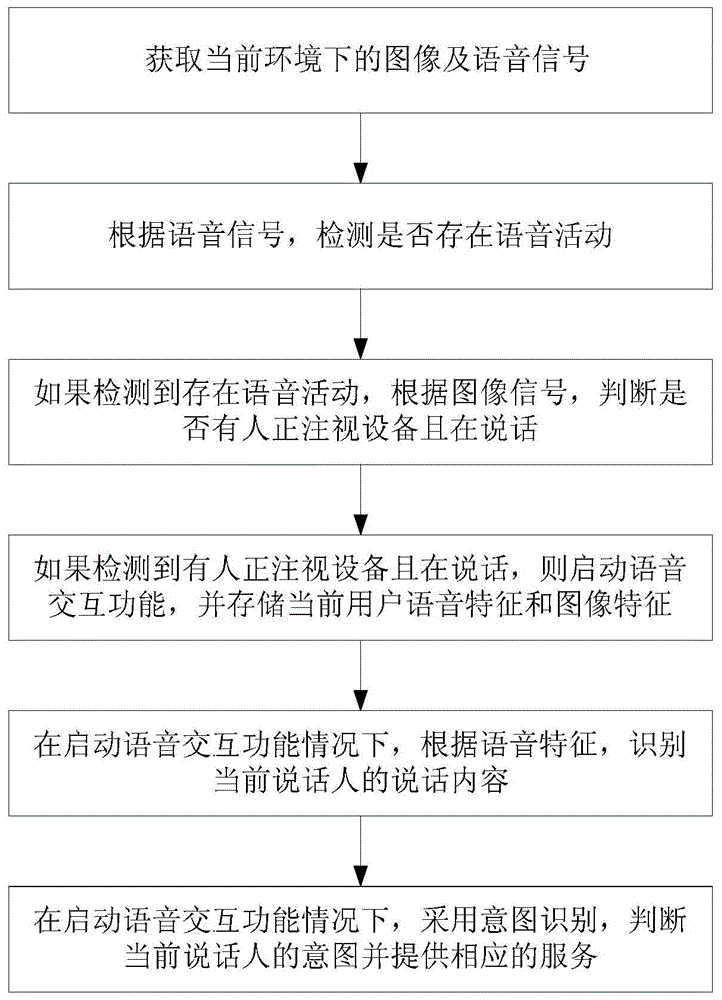
s1.获取当前环境下的图像及语音信号;
s2.根据语音信号,检测是否存在语音活动;
s3.如果检测到存在语音活动,根据图像信号,判断是否有人正注视设备且在说话;
s4.如果检测到有人正注视设备且在说话,则启动语音交互功能,并存储当前用户语音特征和图像特征;
s5.在启动语音交互功能情况下,根据语音特征,识别当前说话人的说话内容;
s6.在启动语音交互功能情况下,采用意图识别,判断当前说话人的意图并提供相应的服务。
具体的是,步骤s1中,通过家电设备内置的语音接收器装置,获取当前环境下的语音信号;通过家电设备内置的摄像头装置,获取当前环境下的图像信号。
进一步的是,步骤s2具体包括以下步骤:
s201.提取语音信号传统特征或深度特征;
s202.基于门限、统计模型及机器学习对特征进行判决,检测是否存在语音活动。
具体的是,步骤s3具体包括以下步骤:
s301.根据所述图像信号,用计算机视觉技术计算当前说话人的人脸朝向,判断当前环境中是否有人在正注视设备;
s302.如果有人在正注视设备,根据图像信号,利用计算机视觉技术计算判断注视设备的人是否在说话。
进一步的是,步骤s4中,所述语音特征包括说话人的年龄、性别及身份;所述图像特征包括说话人的人脸、位置、性别、年龄及身份。
具体的是,步骤s5中,通过提取语音特征中的语音参数,识别当前说话人的说话内容。
进一步的是,步骤s6具体包括以下步骤:
s601.采用意图识别,分析说话内容,提取当前说话人的意图;
s602.家电设备内置命令词数据库;
s603.将当前说话人的意图与数据库匹配,确认用户想输入的命令;
s604.提供当前说话人所需的服务。
家电设备的多模态交互系统,应用于所述的家电设备的多模态交互方法包括信号获取模块、说话人检测模块、语音交互模块、特征存储模块、语音识别模块及意图识别模块,信号获取模块与说话人检测模块相连,说话人检测模块与语音交互模块相连,语音交互模块与特征存储模块相连,特征存储模块与语音识别模块相连,语音识别模块和意图识别模块相连;
所述信号获取模块,用于获取语音及图像信号;
所述说话人检测模块,用于判断是否有人正在对家电设备说话;
所述语音交互模块,用于根据所述图像、语音信号,判断是否启动语音交互功能;
所述特征存储模块,用于存储当前说话人的语音特征及图像特征;
所述语音识别模块,用于识别用户说话内容;
所述意图识别模块,用于理解用户意图,推荐服务内容。
本发明的有益效果是,通过上述家电设备的多模态交互方法及系统,能够通过图像、语音信号的输入,采用计算机视觉技术和语音识别技术,自动判断是否需要启动语音交互,无需激活词,让交互更精准、更高效,提升了家电设备的智能化水平,并通过语音识别技术和意图识别技术确认用户搜索意图,帮助用户进行服务选择,提升了交互准确率和效率,带来更加良好的交互体验。
附图说明
图1为本发明家电设备的多模态交互方法的流程图。
具体实施方式
下面结合实施例及附图,详细描述本发明的技术方案。
本发明所述家电设备的多模态交互方法,其流程图参见图1,其中,该方法包括以下步骤:
s1.获取当前环境下的图像及语音信号。
其中,为了节约投入成本且采集语音信号更方便,优选通过家电设备内置的语音接收器装置,获取当前环境下的语音信号;为了能够精准获取图像信号,优选通过家电设备内置的摄像头装置,获取当前环境下的图像信号。
s2.根据语音信号,检测是否存在语音活动。
其中,步骤s2具体包括以下步骤:
s201.提取语音信号传统特征或深度特征;
s202.基于门限、统计模型及机器学习对特征进行判决,检测是否存在语音活动。
s3.如果检测到存在语音活动,根据图像信号,判断是否有人正注视设备且在说话。
其中,步骤s3具体包括以下步骤:
s301.根据所述图像信号,用计算机视觉技术计算当前说话人的人脸朝向,判断当前环境中是否有人在正注视设备;
s302.如果有人在正注视设备,根据图像信号,利用计算机视觉技术计算判断注视设备的人是否在说话。
s4.如果检测到有人正注视设备且在说话,则启动语音交互功能,并存储当前用户语音特征和图像特征。
其中,所述语音特征包括说话人的年龄、性别及身份等;所述图像特征包括说话人的人脸、位置、性别、年龄及身份等。
s5.在启动语音交互功能情况下,根据语音特征,识别当前说话人的说话内容。
其中,一般工况下,可以通过提取语音特征中的语音参数,识别当前说话人的说话内容。
s6.在启动语音交互功能情况下,采用意图识别,判断当前说话人的意图并提供相应的服务。
其中,步骤s6具体包括以下步骤:
s601.采用意图识别,分析说话内容,提取当前说话人的意图;
s602.家电设备内置命令词数据库;
s603.将当前说话人的意图与数据库匹配,确认用户想输入的命令;
s604.提供当前说话人所需的服务。
家电设备的多模态交互系统,应用于所述的家电设备的多模态交互方法包括信号获取模块、说话人检测模块、语音交互模块、特征存储模块、语音识别模块及意图识别模块,信号获取模块与说话人检测模块相连,说话人检测模块与语音交互模块相连,语音交互模块与特征存储模块相连,特征存储模块与语音识别模块相连,语音识别模块和意图识别模块相连;
所述信号获取模块,用于获取语音及图像信号;
所述说话人检测模块,用于判断是否有人正在对家电设备说话;
所述语音交互模块,用于根据所述图像、语音信号,判断是否启动语音交互功能;
所述特征存储模块,用于存储当前说话人的语音特征及图像特征;
所述语音识别模块,用于识别用户说话内容;
所述意图识别模块,用于理解用户意图,推荐服务内容。
实施例1
本实施例提供了一种家电设备的多模态交互方法,包括以下步骤:
s1.获取当前环境下的图像及语音信号。其中,通过家电设备内置语音接收器装置,如遥控器或远场麦克风阵列获取当前环境下的语音信号;通过家电设备内置摄像头装置,若rgb摄像头或红外摄像头,获取当前环境下的图像信号。
s2.根据语音信号,检测是否存在语音活动。其中,首先,提取语音信号传统特征或深度特征,在本实施例中,可计算每个时刻语音的能量作为特征;然后,设定门限阈值k,若能量大于k记为1,即语音,否则记为0,即非语音,并判断语音持续的间隔,若大于设定阈值t,则检测到存在语音活动。
s3.如果检测到存在语音活动,根据图像信号,判断是否有人正注视设备且在说话。其中,首先,根据图像信号,对获取的图像信号进行人脸检测和关键点定位,判断设备前是否有人,同时对定位的人通过关键点进行头部姿态估计得到人脸朝向,判断其相对设备的偏转角度,若其小于阈值r,则判定为正对设备;然后,如果有人在正注视设备,根据图像信号,对正对人连续几帧的关键点进行判断,看其上下唇间距离动态变化范围是否大于阈值d,若大于则判定其在说话,即有人正注视设备且在说话。
s4.如果检测到有人正注视设备且在说话,则启动语音交互功能,并存储当前用户语音特征和图像特征。其中,首先,存储说话人的语音特征,包括年龄“25”、性别“男”、身份“用户1”等;其次,存储说话人的图像特征,包括人脸图像及坐标、位置“设备左30度”、性别“男”、年龄“25”、身份用户1”等。
s5.在启动语音交互功能情况下,根据语音特征,识别当前说话人的说话内容。其中,通过提取语音特征中的语音参数,识别用户说话内容,如用于电视交互的指令“我想看西游记”、“声音大一点”,用于空调交互的指令“温度高一点”、“风小一点”等。
s6.在启动语音交互功能情况下,采用意图识别,判断当前说话人的意图并提供相应的服务。其中,首先,采用意图识别,分析说话内容,提取用户意图,如电视交互指令“我想看西游记”,分析出“西游记”;空调交互指令“风小一点”分析出“风”、“小”;其次,家电设备内置命令词数据库,如“西游记”、“风”、“小”;然后,将用户意图与数据库匹配,确认用户想输入的命令;最后,提供当前说话人所需的服务,如搜索西游记片源供用户选择、调低空调风速。
实施例2
本实施例提供一种家电设备的多模态交互系统,在该系统中具体包括:信号获取模块、说话人检测模块、语音交互模块、特征存储模块、语音识别模块及意图识别模块,信号获取模块与说话人检测模块相连,说话人检测模块与语音交互模块相连,语音交互模块与特征存储模块相连,特征存储模块与语音识别模块相连,语音识别模块和意图识别模块相连。
信号获取模块通过传感器获取当前场景下的图像及语音信号,其中,图像获取设备如rgb摄像头,语音设备接收器如遥控器或远场麦克风阵列。
说话人检测模块主要用于判断是否有人正在对家电设备说话,若非正对家电说话或正对家电没说话,则不连接语音交互模块。判断方法如下:
a.提取语音信号传统特征或深度特征,在本实施例中,可计算每个时刻语音的能量作为特征;
b.设定门限阈值k,若能量大于k记为1,即语音,否则记为0,即非语音,并判断语音持续的间隔,若大于设定阈值t,则检测到存在语音活动;
c.若检测到语音活动,根据图像参数,对获取的图像信号进行人脸检测和关键点定位,判断设备前是否有人,同时对定位的人通过关键点进行头部姿态估计得到人脸朝向,判断其相对设备的偏转角度,若其小于阈值r,则判定为正对设备;
d.如果有人在正注视设备,根据图像信号,对正对人连续几帧的关键点进行判断,看其上下唇间距离动态变化范围是否大于阈值d,若大于则判定其在说话,即有人正注视设备且在说话。
语音交互模块根据所述图像、语音信号,判断是否启动语音交互功能:
若未检测到语音活动,不启动语音交互功能;若检测到语音活动,未检测到有人正注视设备说话,不启动语音交互功能;若检测到语音活动,且检测到有人正注视设备说话,启动语音交互功能。
特征存储模块用于存储当前说话人的语音特征及图像特征,包括语音特征和图像特征:存储说话人的语音特征,包括年龄“25”、性别“男”、身份“用户1”等;存储说话人的图像特征,包括人脸图像及坐标、位置“设备左30度”、性别“男”、年龄“25”、身份用户1”等。
语音识别模块识别说话人的说话内容,如用于电视交互的指令“我想看西游记”、“声音大一点”,用于空调交互的指令“温度高一点”、“风小一点”等。
意图识别模块,在识别说话人的说话内容之后,对当前说话人进行意图识别,理解用户意图,如“西游记”、“风”、“小”。家电设备提供当前说话人所需的服务,如搜索西游记片源供用户选择、调低空调风速。
实施例1和实施例2也可扩展用于其它家电设备的语音交互,如冰箱的温度、灯的开关等。从而可无需激活词启动语音交互功能,并进行多模态识别,提高了交互效率,为用户提供更智能化的服务。
- 还没有人留言评论。精彩留言会获得点赞!