一种增量语义处理方法与流程
本申请涉及自然语言处理技术领域,尤其涉及一种增量语义处理方法。
背景技术:
目前所有的人机语音交互都是把人机交互分为语音识别和语义处理和应用程序三个部分。首先语音识别部分根据语音断点检测判断用户说话结束,然后把所有的文字送给语义处理引擎去处理,然后应用程序模块根据语义处理结果执行后续的动作。这三个环节都是串行执行的,每个环节都造成一定的时延,这给用户的使用带来了不好的体验。以当今主流几款汽车产品体验,如图4所示,现在通常语音检测环节约500ms,语义处理环节约200ms,应用程序模块处理环节约500-1000ms。三个环节加起来要有1-3s左右延迟。
技术实现要素:
有鉴于此,本申请提供一种增量语义处理方法,能够减少人机语言交互时的延迟时间,快速理解用户的语音信号内容,并给出反馈,提高用户的语音交互体验。
为解决上述技术问题,本申请采用以下技术方案:
第一方面,本申请提供一种增量语义处理方法,应用于电子装置,所述电子装置包括语音检测模块、语音识别模块和语义处理模块,所述方法包括:
当所述语音检测模块检测到语音信号时,通知所述语音识别模块处理所述语音信号;
所述语音识别模块按照时间顺序将接收的所述语音信号实时转换成分段文本信息;
所述语音识别模块按照时间顺序将每一段语音信号的文本信息依次发送给所述语义处理模块,所述语义处理模块实时接收每一段所述语音信号的文本信息,其中,当所述语义处理模块每接收到一段语音信号的文本信息时,并提取该段语音信号的文本信息的语义特征值,以实现与所述语音识别模块并行处理所述语音信号。
作为本申请的第一方面的一个实施例,方法还包括:
所述语义处理模块按照时间顺序依次累加每一段文本信息对应的语义特征值,并对第一次得到的语义特征值,或基于第一次得到的语义特征值累加后的语义特征值进行评分,当所述语义特征值或累加后的语义特征值的评分大于阈值时,所述语义处理模块将该语义特征值或累加后的语义特征值发送给应用程序模块;
所述应用程序模块实时接收每一段语音信号对应的语义特征值,并根据每次接收后的语义特征值调整输出的内容。
作为本申请的第一方面的一个实施例,所述应用程序模块实时接收每一段语音信号对应的语义特征值,并根据每次接收后的语义特征值调整输出的内容,包括:
所述应用程序模块在接收到所述语义特征值后,根据语义特征值匹配得到所述语义特征值对应的命令,并切换到待执行所述命令的应用界面,以通过所述应用界面输出与语义特征值对应的界面内容。
作为本申请的第一方面的一个实施例,当所述语音检测模块检测到所述语音信号结束时,所述应用程序模块执行与完整的一段语音信号的语义特征值对应的命令,所述完整的一段语音信号为所述检测模块从检测到所述语音信号开始计时,到所述语音信号结束时的一段时间内的语音信号。
作为本申请的第一方面的一个实施例,所述语义特征值包括唯一的主键值,所述主键值用于标识所述语音信号的第一意图。
作为本申请的第一方面的一个实施例,所述语义特征值还可以包括n个副键值(n≥0),所述副键值用于进一步限定所述主键值的所述第一意图的范围。
作为本申请的第一方面的一个实施例,所述语音信息值的主键值和副键值根据所述语音信号实时更新。
作为本申请的第一方面的一个实施例,所述文本信息的最细粒度信息是单个汉字或单个单词。
作为本申请的第一方面的一个实施例,所述语义特征值的存储类型是json数据类型。
作为本申请的第一方面的一个实施例,所述语义处理模块103采用lstm,cnn或者transformer中任一种模型。
本申请的上述技术方案至少具有如下有益效果之一:
根据本申请实施例的增量语义处理方法,能够缩短语音信号的处理时间,快速理解用户的语音信号内容,并给出反馈,减少了语音交互过程中的延时,提高了用户的语音交互体验。
附图说明
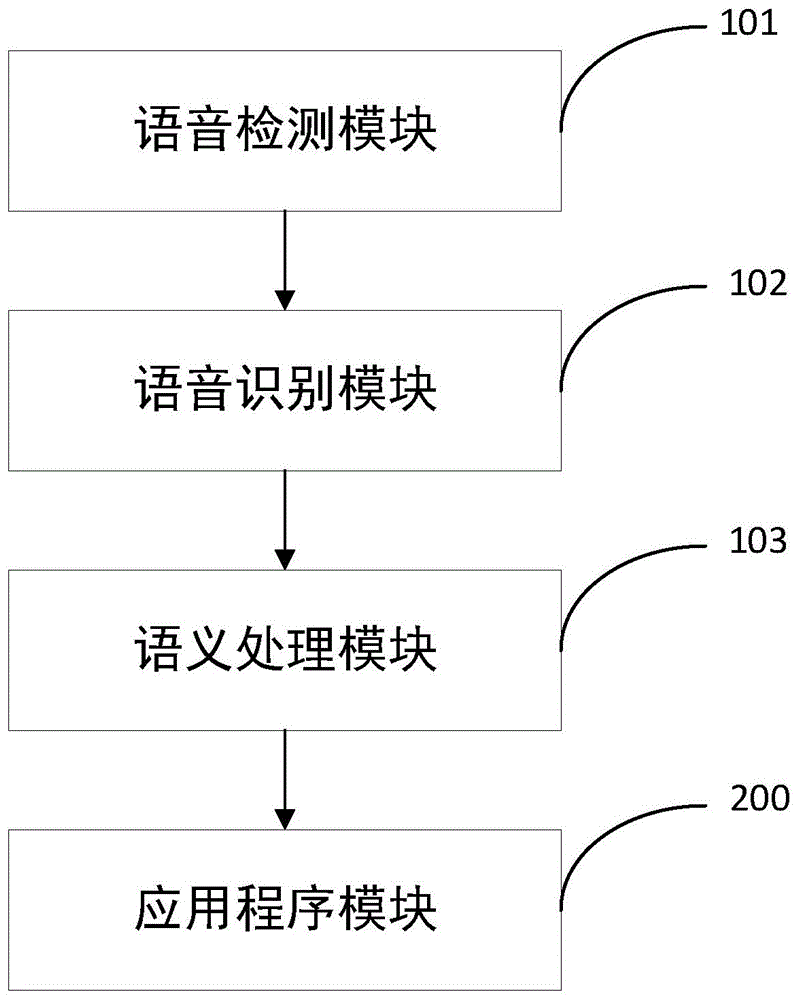
图1为本申请实施例的增量语义处理方法的模块图;
图2为本申请实施例的增量语义处理方法的流程图;
图3为本申请实施例各个模块的运行时间示意图;
图4为现有技术各个模块的运行时间示意图;
图5为本申请实施例的增量语义处理方法的系统流程图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
下面结合具体的实施例对本申请实施例进行说明。
本申请实施例主要应用在汽车、家居等所有人机语音交互场景中,如图1所示,电子装置包括语音检测模块101、语音识别模块102、语义处理模块103和应用程序模块200,这些模块并行运行,可以有效的减少人机交户过程的处理时间。例如,用户想要听歌,对电子装置说:“我要听刘德华的忘情水”,当语音检测模块101识别到用户的语音信号时,语音识别模块102实时处理该语音信号,比如用户说了“我要听刘德华的忘情水”,实时处理结果可能是“我要”“听”“刘德华”“的”“忘情水”这样的分段文本信息,进一步地,语音识别模块102按照时间顺序将每一段文本信息依次发送给语义处理模块103,语义处理模块103依次收到上述双引号中的内容,并提取分段文本信息里的语义特征值,在本申请实施例的实际应用中,可以通过创建json对象,命名intent,用来存储语义特征值,例如,当语义处理模块103收到“我要听”的文本信息时,可以判断语义特征值intent很可能是播放音乐,标识为{“intent”:“paly_music”},进一步地,语义处理模块103会对该特征值进行评分,当评分大于阈值时,则把该语义特征值发送给应用程序模块200,例如{“intent”:“paly_music”}发送给应用程序模块200,应用程序模块200展示音乐播放界面。也就是说,如图3所示,从人说话开始,语音识别模块102、语义处理模块103和应用程序模块200并行处理语音信号,通常,人说话的时间至少要1秒,而语义处理模块103和应用程序模块200的运行时间大都在几十毫秒到几百毫秒之间,当语音检测模块101检测到语音信号结束时,花费了时间t1,语音识别模块识别语音信号并实时把语音信号转换的文本信息发送给并行的语义处理模块103,语义处理模块102工作结束,延时t2,语义处理模块103实时传输结果给应用程序模块200,应用程序模块200工作结束,延时t3,在实际应用中,用户从说话结束到应用程序模块200执行命令结束,一共延迟td=t1+t2+t3,而用户说话的时间1秒是足够语义处理模块103和应用程序模块200运行结束的,这里的t2和t3仅仅是语音识别模块、语义处理模块103以及应用程序模块200之间通讯的时间,约几十毫秒,由此,整体延迟时间td远小于图4所示现有技术中t1+t2+t3的延时,这样,该方法在人机语音交互场景中,能够缩短语音信号的处理时间,快速理解用户的语音信号内容,并给出反馈,减少了语音交互过程中的延时,提高了用户的语音交互体验。
下面结合附图对本申请的一种增量语义处理方法进行描述,图2示出了一种增量语义处理方法的流程图,该方法应用于电子装置,电子装置包括语音检测模块、语音识别模块和语义处理模块,如图2所示,该方法包括:
步骤s210,当语音检测模块检测到语音信号时,通知语音识别模块处理语音信号。也就是说,语音检测模块先检测语音信号,当判断用户在说话时,立即通知语音识别模块处理该语音信号。
步骤s220,语音识别模块按照时间顺序将接收的语音信号实时转换成分段文本信息。也就是说,语音处理模块首先按照时间顺序处理该语音信号,把该语音信号实时转换成文本信息,其中,语音处理模块一般是把该语音信号转换成分段文本信息,例如,用户说:“我要听刘德华的忘情水”,语音处理模块实时处理结果可能是“我要”“听”“刘德华”“的”“忘情水”,在本申请的一些实施例中,语音处理模块转换的文本信息最细粒度的结果是“我”“要”“听”“刘”“德”“华”“的”“忘”“情”“水”。
步骤s230,语音识别模块按照时间顺序将每一段语音信号的文本信息依次发送给语义处理模块,语义处理模块实时接收每一段语音信号的文本信息,其中,当语义处理模块每接收到一段语音信号的文本信息时,并提取该段语音信号的文本信息的语义特征值,以实现与语音识别模块并行处理语音信号。也就是说,通过上一步骤s220,得到分段文本信息,语音识别模块按照时间顺序将每一段文本信息发送给语义处理模块,语义处理模块提取文本信息的语义特征值,例如,语义处理模块实时接收到“我要听”时,可以提取语义特征值play_music,在本申请实施例的实际应用中,通过创建json对象,命名intent,用来存储语义特征值,语义用{“intent”:“paly_music”}标识。
在本申请的一些实施例中,方法还包括:
步骤s240,语义处理模块按照时间顺序依次累加每一段文本信息对应的语义特征值,并对第一次得到的语义特征值,或基于第一次得到的语义特征值累加后的语义特征值进行评分,当语义特征值或累加后的语义特征值的评分大于阈值时,语义处理模块将该语义特征值或累加后的语义特征值发送给应用程序模块。也就是说,进一步地,语义处理模块继续接收到“刘德华”文本信息时,可以提取语义特征值“singer”=“刘德华”,累加到上述的语义中,用{“intent”:“play_music”,“singer”:“刘德华”}标识,进一步地,语义处理模块继续接收到“忘情水”文本信息时,可以提取语义特征值“song”=“忘情水”,累加到上述语义中,用{“intent”:“play_music”,“singer”:“刘德华”,“song”:“忘情水”}标识。
如图4所示,语义处理模块每次提取到语义特征值时,可以对该语义特征值评分,例如,当语义处理模块接收文本信息是“我想听”,语义处理模块提取的语义特征值是{“intent”:“paly_music”},但是这个语义不太完整,所以该语义特征值评分不会超过阈值,因此不会把这个语义送给应用程序模块。当语义处理模块接收到“刘德华”文本信息时,语义处理模块提取出“singer”=“刘德华”,这时,语义处理模块对{“intent”:“play_music”,“singer”:“刘德华”}的语义打分会大于阈值,此时,语义处理模块把{“intent”:“play_music”,“singer”:“刘德华”}送给应用程序模块。
应用程序模块实时接收每一段语音信号对应的语义特征值,并根据每次接收后的语义特征值调整输出的内容。也就是说,当应用程序模块接收到该语义特征值{“intent”:“play_music”,“singer”:“刘德华”},会在应用程序界面展示准备播放刘德华的歌的界面。
在本申请的一些实施例中,应用程序模块实时接收每一段语音信号对应的语义特征值,并根据每次接收后的语义特征值调整输出的内容,包括:
应用程序模块在接收到语义特征值后,根据语义特征值匹配得到语义特征值对应的命令,并切换到待执行命令的应用界面,以通过应用界面输出与语义特征值对应的界面内容。其中,当应用程序模块接收的语义特征值是{“intent”:“play_music”,“singer”:“刘德华”}时,应用程序模块根据这个语义,会在应用程序界面展示准备播放刘德华的歌的界面,但是由于没有歌名,所以很可能等待播放的歌曲是刘德华唱的其他歌,需要指出的是,应用程序模块的界面展示的时间点距离用户说完“我要听刘德华”这几个字的时间点很近,用户的体验效果会很好。当语义处理模块继续提取语义特征值“song”=“忘情水”,得到{“intent”:“play_music”,“singer”:“刘德华”,“song”:“忘情水”},这个语义的评分超过阈值,发送给应用程序模块时,应用程序模块把播放音乐的界面从播放刘德华的任意歌改成播放刘德华的忘情水。
步骤s250,当语音检测模块检测到语音信号结束时,应用程序模块执行与完整的一段语音信号的语义特征值对应的命令,完整的一段语音信号为检测模块从检测到语音信号开始计时,到语音信号结束时的一段时间内的语音信号。也就是说,当语音检测模块检测到语音信号结束时,应用程序模块即开始执行命令,例如,上一步骤s250中,应用程序模块的界面已经在刘德华的忘情水的播放界面,当用户停止说话时,语音检测模块检测到语音信号结束时,应用程序模块开始播放歌曲刘德华的忘情水。
在本申请的一些实施例中,语义特征值包括唯一的主键值,主键值用于标识语音信号的第一意图。例如在上述实施例中,“intent”=“paly_music”是语义特征值的主键值,由此,可以知道用户想要听音乐。
在本申请的一些实施例中,语义特征值还可以包括n个副键值(n≥0),副键值用于进一步限定主键值的第一意图的范围。例如在上述实施例中,“singer”=“刘德华”,“song”=“忘情水”是语义特征值的副键值,由此,可以知道用户具体想要听刘德华的歌曲忘情水。
在本申请的一些实施例中,语义处理模块采用lstm,cnn或者transformer中任一种模型,其中,lstm,cnn或transformer模型都是成熟的神经模型,容易训练,语义处理模块通过lstm,cnn或transformer模型可以快速准确提取语义特征值。
由此,本申请实施例的增量语义处理方法,能够并行语音识别模块、语义处理模块和应用程序模块,缩短语音信号的处理时间,快速理解用户的语音信号内容,并给出反馈,减少了语音交互过程中的延时,提高了用户的语音交互体验。
需要说明的是,在本专利的示例和说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个”限定的要素,并不排除在包括所述要素的过程、方法、物品或者方法中还存在另外的相同要素。
以上所述是本申请的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!