基于神经网络的语音合成方法、系统、设备及存储介质与流程
1.本发明涉及语音合成领域,具体地说,涉及基于神经网络的语音合成方法、系统、设备及存储介质。
背景技术:
2.在线旅行服务公司每天需要给非常多的商家与客人打电话,通过语音合成技术,再利用语音识别、对话管理、自然语言理解以及自然语言生成等模块,使用外呼机器人呼叫酒店以及客户,可以大量节省人力资源,由于旅游业务不仅局限在国内,大量的海外业务或海外客人也需要联系,因此在与酒店、景区沟通时,有很多中英文混合的内容需要播报。中英文混合的语音合成主要思想是用一个人的声音合成出中英文混合文本的音频,但是由于中英文发音流利且音色较好的人不多,录制此种音频的成本巨大。想找能够说中英文混合文本的客服难度很高,因此大量开展电话服务的成本很高,也降低了需要增加新的混合文本的及时性和灵活性。但是只包含中文的音频文本和只包含英文的音频文本显然就容易获取。
3.此外,在企业内部服务上线以及发布过程中可能会出现bug,通过邮件以及电话的方式可以及时提醒发布者,及时修正bug;因为各种服务有很多英文专业术语,因此在电话播报的时候需要播报大量的中英文混合的文本话术。
4.因此,本发明提供了一种基于神经网络的语音合成方法、系统、设备及存储介质。
技术实现要素:
5.针对现有技术中的问题,本发明的目的在于提供基于神经网络的语音合成方法、系统、设备及存储介质,克服了现有技术的困难,能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
6.本发明的实施例提供一种基于神经网络的语音合成方法,包括以下步骤:
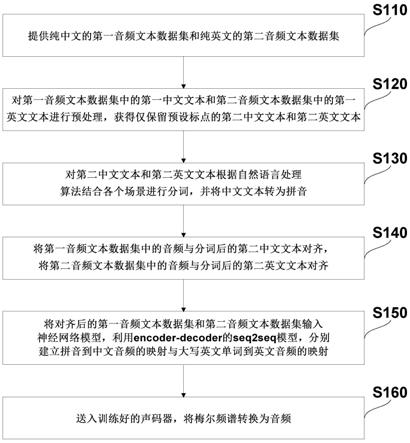
7.s110、提供纯中文的第一音频文本数据集和纯英文的第二音频文本数据集;
8.s120、对第一音频文本数据集中的第一中文文本和第二音频文本数据集中的第一英文文本进行预处理,获得仅保留预设标点的第二中文文本和第二英文文本;
9.s130、对第二中文文本和第二英文文本根据自然语言处理算法结合各个场景进行分词,并将中文文本转为拼音;
10.s140、将第一音频文本数据集中的音频与分词后的第二中文文本对齐,将第二音频文本数据集中的音频与分词后的第二英文文本对齐;
11.s150、将对齐后的第一音频文本数据集和第二音频文本数据集输入神经网络模型,利用encoder
‑
decoder的seq2seq模型,分别建立拼音到中文音频的映射与大写英文单词到英文音频的映射;
12.s160、送入训练好的声码器,将梅尔频谱转换为音频。
13.优选地,所述步骤s120中,所述预设标点包括所述第一中文文本中英文字母状态
下的逗号、句号和问号,以及所述第一英文文本中英文字母状态下的逗号、单引号、句号和问号。
14.优选地,所述步骤s130中,将英文算法中的阿拉伯数字转换为英文单词。
15.优选地,所述步骤s140中,在每一条文本中加入语言标签,将转换的拼音文本中各音素转换为对应的字典索引,进而得到向量供神经网络模型使用。
16.优选地,所述步骤s150中,使用双向ltsm、多层cnn以及全连接层神经网络结构建立encoder
‑
decoder的端到端的神经网络模型,通过注意力机制学习音素向量和对应梅尔谱特征的对齐关系;在得到对齐好的声学模型后,将文本转为梅尔频谱。
17.优选地,所述神经网络模型采用中文编码器、英文编码器两个编码器,在训练阶段,模型训练时encoder的输入文本分别送入两个编码器,最后根据输入语言的标签,得到最后的编码器。
18.优选地,在decoder解码过程中,通过将模型的音频送入判别器,并且将判别器输出的信息送入解码过程的每一步,建立判别器输出信息与说话人音色之间的映射关系,在decoder后面又连接一个全连接层用于生成指定维度的梅尔谱特征。
19.本发明的实施例还提供一种基于神经网络的语音合成系统,用于实现上述的基于神经网络的语音合成方法,所述基于神经网络的语音合成系统包括:
20.数据集模块,提供纯中文的第一音频文本数据集和纯英文的第二音频文本数据集;
21.预处理模块,对第一音频文本数据集中的第一中文文本和第二音频文本数据集中的第一英文文本进行预处理,获得仅保留预设标点的第二中文文本和第二英文文本;
22.文本分词模块,对第二中文文本和第二英文文本根据自然语言处理算法结合各个场景进行分词,并将中文文本转为拼音;
23.文本对齐模块,将第一音频文本数据集中的音频与分词后的第二中文文本对齐,将第二音频文本数据集中的音频与分词后的第二英文文本对齐;
24.音频映射模块,将对齐后的第一音频文本数据集和第二音频文本数据集输入神经网络模型,利用encoder
‑
decoder的seq2seq模型,分别建立拼音到中文音频的映射与大写英文单词到英文音频的映射;
25.音频生成模块,送入训练好的声码器,将梅尔频谱转换为音频。
26.本发明的实施例还提供一种基于神经网络的语音合成设备,包括:
27.处理器;
28.存储器,其中存储有所述处理器的可执行指令;
29.其中,所述处理器配置为经由执行所述可执行指令来执行上述基于神经网络的语音合成方法的步骤。
30.本发明的实施例还提供一种计算机可读存储介质,用于存储程序,所述程序被执行时实现上述基于神经网络的语音合成方法的步骤。
31.本发明的目的在于提供基于神经网络的语音合成方法、系统、设备及存储介质,能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
附图说明
32.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显。
33.图1是本发明的基于神经网络的语音合成方法的流程图。
34.图2是本发明的基于神经网络的语音合成系统的模块示意图。
35.图3是本发明的基于神经网络的语音合成设备的结构示意图。
36.图4是本发明一实施例的计算机可读存储介质的结构示意图。
具体实施方式
37.现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的实施方式。相反,提供这些实施方式使得本发明将全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。在图中相同的附图标记表示相同或类似的结构,因而将省略对它们的重复描述。
38.图1是本发明的基于神经网络的语音合成方法的流程图。如图1所示,本发明的实施例提供一种基于神经网络的语音合成方法,包括以下步骤:
39.s110、提供纯中文的第一音频文本数据集和纯英文的第二音频文本数据集。
40.s120、对第一音频文本数据集中的第一中文文本和第二音频文本数据集中的第一英文文本进行预处理,获得仅保留预设标点的第二中文文本和第二英文文本。
41.s130、对第二中文文本和第二英文文本根据自然语言处理算法结合各个场景进行分词,并将中文文本转为拼音。
42.s140、将第一音频文本数据集中的音频与分词后的第二中文文本对齐,将第二音频文本数据集中的音频与分词后的第二英文文本对齐。
43.s150、将对齐后的第一音频文本数据集和第二音频文本数据集输入神经网络模型,利用encoder
‑
decoder的seq2seq模型,分别建立拼音到中文音频的映射与大写英文单词到英文音频的映射。其中,encoder
‑
decoder(编码
‑
解码)是深度学习中非常常见的一个模型框架,比如无监督算法的auto
‑
encoding就是用编码
‑
解码的结构设计并训练的。比如这两年比较热的image caption的应用,就是cnn
‑
rnn的编码
‑
解码框架。再比如神经网络机器翻译nmt模型,往往就是lstm
‑
lstm的编码
‑
解码框架。seq2seq属于encoder
‑
decoder结构的一种,这里看看常见的encoder
‑
decoder结构,基本思想就是利用两个rnn,一个rnn作为encoder,另一个rnn作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量c。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
44.s160、送入训练好的声码器,将梅尔频谱转换为音频。
45.本发明通过找一位英语母语的说话人录制英文音频,再找一位中文母语的说话人录制中文音频,通过神经网络模型,最终可以得到一个说话人既说中文又说英文,通过该方法可以进行国外订单的相关信息的播报,从而减少人力成本。
46.在一个优选实施例中,步骤s120中,预设标点包括第一中文文本中英文字母状态下的逗号、句号和问号,以及第一英文文本中英文字母状态下的逗号、单引号、句号和问号。
47.在一个优选实施例中,步骤s130中,将英文算法中的阿拉伯数字转换为英文单词。
48.在一个优选实施例中,步骤s140中,在每一条文本中加入语言标签,将转换的拼音文本中各音素转换为对应的字典索引,进而得到向量供神经网络模型使用。
49.在一个优选实施例中,步骤s150中,使用双向ltsm、多层cnn以及全连接层神经网络结构建立encoder
‑
decoder的端到端的神经网络模型,通过注意力机制学习音素向量和对应梅尔谱特征的对齐关系。在得到对齐好的声学模型后,将文本转为梅尔频谱。其中,长短期记忆网络(lstm,long short
‑
term memory)是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。卷积神经网络(convolutional neural networks,cnn)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforward neural networks),是深度学习(deep learning)的代表算法之一。
50.在一个优选实施例中,神经网络模型采用中文编码器、英文编码器两个编码器,在训练阶段,模型训练时encoder的输入文本分别送入两个编码器,最后根据输入语言的标签,得到最后的编码器。
51.在一个优选实施例中,在decoder解码过程中,通过将模型的音频送入判别器,并且将判别器输出的信息送入解码过程的每一步,建立判别器输出信息与说话人音色之间的映射关系,在decoder后面又连接一个全连接层用于生成指定维度的梅尔谱特征。
52.想找能够说中英文混合文本的客服难度很高,因此大量开展电话服务的成本很高,通过找一位英语母语的说话人录制英文音频,再找一位中文母语的说话人录制中文音频,通过神经网络模型,最终可以得到一个说话人既说中文又说英文,通过该方法可以进行国外订单的相关信息的播报,从而减少人力成本。本发明要解决的问题:研发一种不用找中英文都流利的录音者进行录音,而是找一位英语母语的说话人录制英文音频,再找一位中文母语的说话人录制中文音频,通过神经网络模型学习中文拼音到中文音频以及英文大写字母到英文音频的映射,可以根据输入文本合成对应的音频信息,能够让语音外呼机器人代替真人,并且能够速度满足业务需求。
53.本发明公开了一种基于神经网络的中英文混合文本的语音合成技术,使用深度学习技术,构建深度学习网络结构,利用某说话人的纯中文音频和某说话人的纯英文音频进行深度学习模型的训练,能够合成中英文混合文本的音频,将文本信息转换为语音信息,进行相关场景的语音播报。
54.本发明提出了一种基于神经网络的中英文混合的语音合成方法,将待合成的中英文混合的文本送入模型,模型就能够合成出对应的音频。该发明主要有以下几个步骤:1)首先将纯中文的音频文本数据集和纯英文的音频文本数据集,对中文文本进行预处理,得到仅包含部分标点和中英文的文本随后根据nlp的分词算法,结合不同场景进行分词,随后将中文转为拼音,例子为“携程旅行网是中国最大的在线旅行服务公司”转为“xie2cheng2 lv3 xing2 wang3 shi4 zhong1 guo2 zui4 da4 de5 zai4 xian4 lv3xing2 fu2 wu4 gong1 si1”;而英文数据集需要将阿拉伯数字等转换为英文单词,例子为“32dollars”转为“thirty
‑
two dollars”;2)通过程序进行录音数据的预处理,通过强制对齐方法将音频和文本进行强制对齐,在预处理后的数据中加上语音标签,供后续模型使用。3)将数据送入神经网络模型,利用encoder
‑
decoder的seq2seq模型,分别建立拼音到中文音频的映射与大
写英文单词到英文音频的映射,在解码过程中,将模型的音频送入判别器,期望与真实语言标签一样,并且将判别器输出的信息送入解码过程的每一步,建立判别器输出信息与语音言间的映射关系。4)随后送入训练好的声码器,将mel
‑
spectrogram(梅尔频谱)转换为音频。
55.在一个实施例中,本发明提出一种基于神经网络的中英文混合语音合成模型,包括文本正则化阶段、数据后处理阶段、声学建模和声码器。该技术包括以下步骤:
56.文本正则化阶段:
57.首先将确认文本和音频一一对应,对中文文本进行正则化处理,删掉除逗号、句号、问号之外的标点符号,并将各标点符号变成英文状态下的标点符号。
58.将中文文本的阿拉伯数字按照实际场景的读法转为中文。例如“订单尾号6158”应转为“订单尾号六幺五八”,“现在是22:20”应转为“现在是二十二点二十分”。
59.经过上述处理后,将中文转为拼音格式,例如:“语音合成”转为“yu3yin1 he2 cheng2”。
60.将英文文本除逗号、句号、单引号、问号之外的标点符号删掉,将各标点符号变成英文状态下的标点符号。
61.将英文文本中的阿拉伯数字转为英文单词。例如“10dollars”转为“ten dollars”,最后同一将英文单词中的所有字母转为大写字母。
62.数据后处理阶段:
63.首先将经过正则化得到的文本进行简单处理,通过montreal forced al igner工具将文本与音频进行强制对齐,将结果再进一步处理,得到模型能用的文本,在每一条文本中加入语言标签,供后续声学模型建模使用。将转换的拼音文本中各音素转换为对应的字典索引,进而得到向量供后续模型使用。
64.声学建模:
65.使用双向ltsm、多层cnn以及全连接层等神经网络结构建立整个模型,其框架为seq2seq的encoder
‑
decoder模型。除此之外,为了能够更好的学到输入文本与音频之间的对齐关系,模型加入了注意力机制。由于中文发音和英文发音有很大差别,模型采用两个编码器,即中文编码器和英文编码器,在训练阶段,文本被同时送入两个编码器,这样可以减少编码器对于另一种语言编码的误差,最后根据输入语言的标签,得到最后的编码器。
66.声码器:
67.声码器部分使用melgan的生成对抗网络模型将mel
‑
spectrogram转为音频。
68.在本发明的具体实施中,主要分为以下六部分:数据集准备、文本正则化模块、数据后处理模块、声学模型、声码器、模型训练。具体实施步骤如下:
69.步骤1:数据集准备
70.数据集中的中文话术是从酒店客服与商家的通话记录中提取并标注,英文话术是海外订单中提取并标注,由两位专门的人工客服经过培训后去录音棚录制,总共录制了10000条48khz的中文音频和10000条48khz的英文音频,音频总时长约为21小时,并且每条音频均由专门的员工进行标注核对。
71.步骤2:文本正则化模块
72.首先核对文本和音频是否匹配,待数据无误后,对中文文本进行正则化处理,删掉
除逗号、句号、问号之外的标点符号,并将各标点符号变成英文状态下的标点符号。将中文文本的阿拉伯数字按照实际场景的读法转为中文。例如“订单尾号3364”应转为“订单尾号三三六四”,“今天23:20”应转为“今天二十三点二十分”。经过上述处理后,将中文转为拼音格式,例如:“语音合成”转为“yu3 yin1 he2 cheng2”;将英文文本除逗号、句号、单引号、问号之外的标点符号删掉,将各标点符号变成英文状态下的标点符号。将英文文本中的阿拉伯数字转为英文单词。例如“give me 5books”转为“give me five books”,最后同一将英文单词中的所有字母转为大写字母。
73.步骤3:数据后处理阶段
74.首先将所有的标点符号去掉,只保留大写英文单词和拼音字符,通过montreal forced aligner(mfa,强制对齐用法)对齐工具将文本和音频进行强制对齐,通过汉字的字级别的对齐以及英文的词级别的对齐,使得音频和文本内容匹配,便于后续模型能够更好的学习对齐关系,在每一条文本中加入语言标签,供后续声学模型建模使用。随后将拼音里的每个字符,经过一个embedding层,将输入的文本转为模型能够利用的向量。
75.步骤4:声学模型建模
76.声学模型是使用双向ltsm、多层cnn以及全连接层等网络结构建立了神经网络,其主体结构是encoder
‑
decoder的端到端模型,为了能够更好的学习到字符和音频之间的对齐关系,使用注意力机制加快模型的收敛;由于中文和英文的发音特点及习惯差距很大,因此采用两个encoder编码器,分别命名为encoder_cn和encoder_en,模型训练时encoder的输入分别送入两个编码器,后面根据输入语言的标签将不同语言的编码器隐藏掉,最终的encoder输出为相同语言标签的编码器的结果;在decoder解码过程中,通过将模型的音频送入判别器,期望与真实语言标签一样,并且将判别器输出的信息送入解码过程的每一步,建立判别器输出信息与说话人音色之间的映射关系,在decoder后面又接了一个全连接层用于生成指定维度的梅尔谱特征。
77.步骤5:声码器
78.声码器部分使用了melgan,通过训练melgan模型,可将梅尔谱特征合成音频。
79.步骤6:模型训练
80.声学模型和声码器均单独训练。
81.首先通过montreal forced aligner对齐工具将文本和音频进行强制对齐,将文本信息转为可供模型使用的向量,将该数据送入声学模型中训练,由于数据量较大,且为了使模型能够更稳定,因此训练了40万次,loss基本收敛了,文本音素和梅尔谱已经对齐。声码器的训练利用melgan的生成对抗网络模型训练,将梅尔频谱转换为真实的音频。
82.本发明题出的一种基于神经网络的中英文混合的语音合成方法,该技术方法主要分为以下四个模块,首先将文本进行正则化,将中文文本正则化后变为拼音文本,中文文本只包含英文字母状态下的逗号、句号和问号,英文文本正则化后只包含大写字母的单词,英文文本只包含英文字母状态下的逗号、单引号、句号和问号。随后将文本的每一个音素转为向量,然后送入encoder
‑
decoder模型中,通过gpu训练神经网络模型,利用注意力机制学习音素向量和对应梅尔谱特征的对齐关系;在得到对齐好的声学模型后,将文本转为mel
‑
spectrogram,利用melgan模型将mel
‑
spectrogram转为音频。该方法能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音
效果自然逼真。
83.图2是本发明的基于神经网络的语音合成系统的模块示意图。如图2所示,本发明的基于神经网络的语音合成系统5包括:
84.数据集模块51,提供纯中文的第一音频文本数据集和纯英文的第二音频文本数据集。
85.预处理模块52,对第一音频文本数据集中的第一中文文本和第二音频文本数据集中的第一英文文本进行预处理,获得仅保留预设标点的第二中文文本和第二英文文本。
86.分词模块53,对第二中文文本和第二英文文本根据自然语言处理算法结合各个场景进行分词,并将中文文本转为拼音。
87.文本对齐模块54,将第一音频文本数据集中的音频与分词后的第二中文文本对齐,将第二音频文本数据集中的音频与分词后的第二英文文本对齐。
88.音频映射模块55,将对齐后的第一音频文本数据集和第二音频文本数据集输入神经网络模型,利用encoder
‑
decoder的seq2seq模型,分别建立拼音到中文音频的映射与大写英文单词到英文音频的映射。
89.音频生成模块56,送入训练好的声码器,将梅尔频谱转换为音频。
90.本发明的基于神经网络的语音合成系统能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
91.本发明实施例还提供一种基于神经网络的语音合成设备,包括处理器。存储器,其中存储有处理器的可执行指令。其中,处理器配置为经由执行可执行指令来执行的基于神经网络的语音合成方法的步骤。
92.如上所示,该实施例本发明的基于神经网络的语音合成系统能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
93.所属技术领域的技术人员能够理解,本发明的各个方面可以实现为系统、方法或程序产品。因此,本发明的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“平台”。
94.图3是本发明的基于神经网络的语音合成设备的结构示意图。下面参照图3来描述根据本发明的这种实施方式的电子设备600。图3显示的电子设备600仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
95.如图3所示,电子设备600以通用计算设备的形式表现。电子设备600的组件可以包括但不限于:至少一个处理单元610、至少一个存储单元620、连接不同平台组件(包括存储单元620和处理单元610)的总线630、显示单元640等。
96.其中,存储单元存储有程序代码,程序代码可以被处理单元610执行,使得处理单元610执行本说明书上述电子处方流转处理方法部分中描述的根据本发明各种示例性实施方式的步骤。例如,处理单元610可以执行如图1中所示的步骤。
97.存储单元620可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(ram)6201和/或高速缓存存储单元6202,还可以进一步包括只读存储单元(rom)6203。
98.存储单元620还可以包括具有一组(至少一个)程序模块6205的程序/实用工具
6204,这样的程序模块6205包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
99.总线630可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
100.电子设备600也可以与一个或多个外部设备700(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该电子设备600交互的设备通信,和/或与使得该电子设备600能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口650进行。并且,电子设备600还可以通过网络适配器660与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。网络适配器660可以通过总线630与电子设备600的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备600使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储平台等。
101.本发明实施例还提供一种计算机可读存储介质,用于存储程序,程序被执行时实现的基于神经网络的语音合成方法的步骤。在一些可能的实施方式中,本发明的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在终端设备上运行时,程序代码用于使终端设备执行本说明书上述电子处方流转处理方法部分中描述的根据本发明各种示例性实施方式的步骤。
102.如上所示,该实施例本发明的基于神经网络的语音合成系统能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
103.图4是本发明的计算机可读存储介质的结构示意图。参考图4所示,描述了根据本发明的实施方式的用于实现上述方法的程序产品800,其可以采用便携式紧凑盘只读存储器(cd
‑
rom)并包括程序代码,并可以在终端设备,例如个人电脑上运行。然而,本发明的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
104.程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
105.计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读存储介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、rf等等,或者上述的任意合适的组合。
106.可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如java、c++等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
107.综上,本发明的目的在于提供基于神经网络的语音合成方法、系统、设备及存储介质,本发明的基于神经网络的语音合成系统能够合成出流利的中英文混合文本的音频,且不需要花费大价钱找中英文流利的录音员进行录音,合成的语音效果自然逼真。
108.以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1