一种音频合成方法、装置、设备和存储介质与流程
本技术涉及计算机领域,具体涉及一种音频合成方法、装置、设备和存储介质。
背景技术:
1、人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
2、其中,语音技术(speech technology)的关键技术有自动语音识别技术 (asr)和语音合成技术(tts)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一。
3、然而,现阶段的语音合成技术,无法通过文本合成得到同语种下不同口音或不同音色的音频,从而在实际应用层面上造成一些问题。例如,通常银行 atm机的操作提示语或引导语由普通话语音来播报,对于非普通话使用人群 (尤其长期生活在方言语言环境下的老年人)来讲,可能不太适应甚至无法理解提示语或引导语的具体含义。
技术实现思路
1、本技术实施例提供一种音频合成方法、装置、设备和存储介质,可以通过能够呈现同语种下的不同口音和音色的合成音频,改善现有的部分人群无法适应或理解普通话提示语音或引导语音的问题。
2、本技术实施例提供一种音频合成方法,包括:
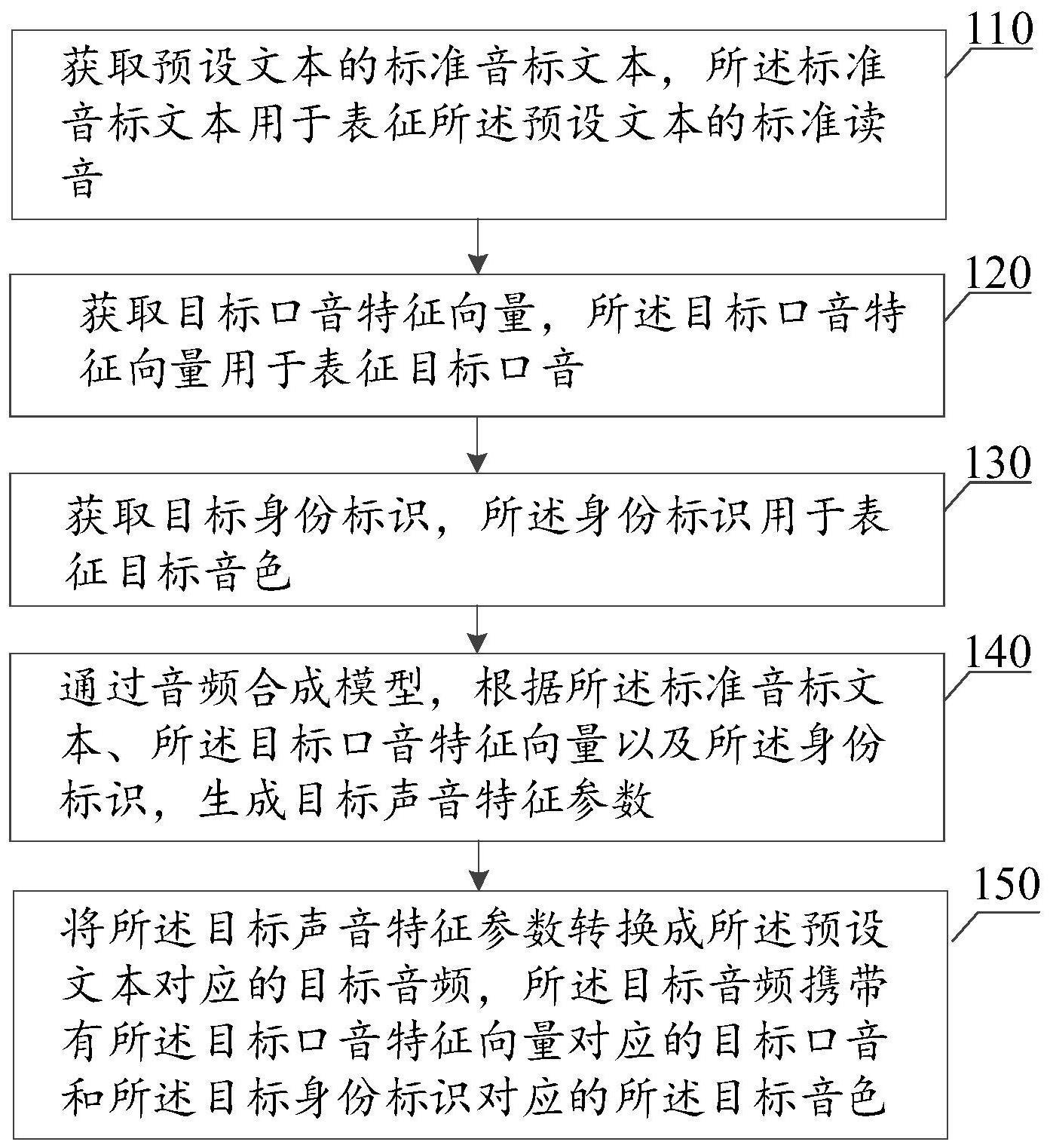
3、获取预设文本的标准音标文本,所述标准音标文本用于表征所述预设文本的标准读音;
4、获取目标口音特征向量,所述目标口音特征向量用于表征目标口音;
5、获取目标身份标识,所述目标身份标识用于表征目标音色;
6、通过音频合成模型,根据所述标准音标文本、所述目标口音特征向量以及所述身份标识,生成目标声音特征参数;
7、将所述目标声音特征参数转换成所述预设文本对应的目标音频,所述目标音频携带有所述目标口音特征向量对应的目标口音和所述目标身份标识对应的所述目标音色。
8、在上述的实施方式中,所述获取目标口音特征向量,包括:
9、接收目标用户的用户音频;
10、提取所述用户音频对应的用户声音特征参数;
11、通过音频合成模型中的第一口音特征提取网络,根据所述用户声音特征参数生成所述目标口音特征向量。
12、可选地,所述获取目标口音特征向量,包括:
13、获取口音音标文本,所述口音音标文本用于表征所述预设文本的所述目标口音的读音;
14、通过音频合成模型中的第二口音特征提取网络,根据所述口音音标文本生成所述目标口音特征向量。
15、可选地,所述音频合成模型包括编码器、嵌入网络以及解码器;
16、所述通过音频合成模型,根据所述标准音标文本、所述目标口音特征向量以及所述身份标识,生成目标声音特征参数,包括:
17、通过所述编码器,根据所述标准音标文本生成输出向量;
18、通过所述嵌入网络,根据所述目标身份标识生成身份标识向量;
19、计算所述目标口音特征向量、所述输出向量以及所述身份标识向量的加和,获取加和结果;
20、通过所述解码器,根据所述加和结果生成所述目标声音特征参数。
21、可选地,在所述获取预设文本的标准音标文本之前,所述方法还包括:
22、获取训练口音音标文本集,所述训练口音音标文本集包括第一数量个训练口音音标文本,所述第一数量个训练口音音标文本由至少两个训练用户共同产生,每个所述训练口音音标文本用于表征其所属的训练用户的带口音读音;
23、获取训练标准音标文本集,所述训练标准音标文本集包括所述第一数量个训练标准音标文本,所述训练标准音标文本与所述训练口音音标文本一一对应,且每个所述训练标准音标文本用于表征所述带口音读音对应的标准读音;
24、获取所述至少两个训练用户中每个训练用户对应的身份标识;
25、获取所述第一数量个训练口音音标文本对应的训练音频,并基于所述训练音频获取训练声音特征参数;
26、根据所述训练口音音标文本集、所述训练标准音标文本集、至少两个所述身份标识以及所述训练声音特征参数对初始音频合成模型进行训练,得到音频合成模型。
27、在上述的实施方式中,所述初始音频合成模型包括初始第一口音特征提取网络、初始第二口音特征提取网络、初始嵌入网络、初始编码器以及初始解码器;
28、所述根据所述训练口音音标文本集、所述训练标准音标文本集、至少两个所述身份标识以及所述训练声音特征参数对初始音频合成模型进行训练,得到音频合成模型,包括:
29、获取所述第一训练口音音标文本对应的所述训练声音特征参数。
30、通过所述初始第一口音特征提取网络,根据所述训练声音特征参数生成训练第一口音特征向量;
31、通过所述初始第二口音特征提取网络,根据第一训练口音音标文本生成训练第二口音特征向量,所述第一训练口音音标文本为所述第一数量个训练口音音标文本中的任一个;
32、通过所述初始嵌入网络,根据所述第一训练口音音标文本对应的所述身份标识生成训练身份标识向量;
33、通过所述初始编码器,根据所述第一训练口音音标文本对应的训练标准音标文本生成训练输出向量;
34、基于所述训练第二口音特征向量、所述训练身份标识向量与所述训练输出向量,获取训练输出声音特征参数;
35、根据所述训练声音特征参数与所述训练输出声音特征参数计算第一损失;
36、根据所述训练第一口音特征向量与所述训练第二口音特征向量计算第二损失;
37、根据所述第一损失和第二损失之和调整所述初始音频合成模型的参数,当所述第一损失和第二损失之和达到预设条件时,将包含调整后的参数的初始音频合成模型确定为音频合成模型。
38、在上述的实施方式中,所述基于所述训练第二口音特征向量、所述训练身份标识向量与所述训练输出向量,获取训练输出声音特征参数,包括:
39、计算所述训练第二口音特征向量、所述训练身份标识向量与所述训练输出向量的训练向量加和;
40、通过所述初始解码器,根据所述训练向量加和生成训练输出声音特征参数。
41、本技术实施例还提供一种音频合成装置,包括:
42、标准音标文本模块,用于获取预设文本的标准音标文本,所述标准音标文本用于表征所述预设文本的标准读音;
43、目标口音特征向量模块,用于获取目标口音特征向量,所述目标口音特征向量用于表征目标口音;
44、目标身份标识模块,用于获取目标身份标识,所述目标身份标识用于表征目标音色;
45、合成模块,用于通过音频合成模型,根据所述标准音标文本、所述目标口音特征向量以及所述目标身份标识,生成目标声音特征参数;
46、转换模块,用于将所述目标声音特征参数转换成所述预设文本对应的目标音频,所述目标音频携带有所述目标口音特征向量对应的目标口音和所述目标身份标识对应的所述目标音色。
47、本技术实施例还提供一种设备,包括处理器和存储器,所述存储器存储有多条指令;所述处理器从所述存储器中加载指令,以执行所述的一种音频合成方法中的步骤。
48、本技术实施例还提供一种存储介质,其特征在于,所述存储介质存储有多条指令,所述指令适于处理器进行加载,以执行所述的一种音频合成方法中的步骤。
49、本技术实施例可以根据用户的需求生成合成音频,通过合成音频向用户播报操作提示语或引导语,便于用户理解提示语或引导语。本技术实施例可以针对不同语种采用不同的读音标注方式,不仅仅适用中文,具有普遍适用性。
- 还没有人留言评论。精彩留言会获得点赞!