基于CBAM和动态卷积分解的歌唱语音转换方法
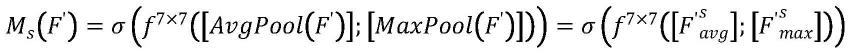
基于cbam和动态卷积分解的歌唱语音转换方法
技术领域
1.本发明属于语音转换技术领域,具体地说,是一种基于cbam和动态卷积分解的歌唱语音转换方法。
背景技术:
2.语音转换(voice conversion,vc)技术的定义是将源说话人(source speaker)的身份特征改变为目标说话人(target speaker)的身份特征,同时保持源说话人的内容特征不变,语音转换技术的关键在于保证语音质量的同时有效地改变说话人的音色。
3.歌唱语音转换是语音转换中的一个新的研究方向,它将源歌手的声音转换为目标歌手的声音,同时保留歌唱内容。通过歌唱语音转换,可以让每个人都像专业人士一样唱歌,克服专业上的限制,自由地控制声音的音调,并以不同的方式表达情感。歌唱语音的分析更关注持续音符、和声/节奏结构和相对音高,而在普通语音中,这些音乐价值是不存在的。进一步,歌唱语音更强调非周期方面,如辅音话语和快速移动的频谱包络,需要处理更广泛的频率变化,以及在歌唱语音中音量和音调更尖锐的变化。
4.歌唱语音转换领域涌现了很多种方法,如2015年kazuhiro kobayashi等人提出的基于全局方差的直接波形修正的统计歌唱语音转换,与基于频谱差分的直接波形修正歌唱语音转换;或者2016年fernando villavicencio等人提出的级联声乐合成等方法。它们通常都需要并行数据来训练转换模型。
5.为了克服歌唱语音转换依赖并行训练数据的局限性,2019年,facebookai提出了一种利用非并行数据的无监督方法,该方法采用了一种由类wavenet编码器、wavenet自回归译码器和可学习的歌手嵌入向量表组成的自动编解码器体系结构。通过切换不同歌手的嵌入向量,可以实现歌唱语音的转换。
6.虽然上述方法可以产生与目标歌手在感知上相似的歌唱语音,但由于语音和音高联合表示的学习存在困难,所产生的歌唱质量往往会受到影响。2020年,tencentai lab中的deng等人提出了一种新的无监督歌唱语音转换方法pitchnet,该方法利用音高回归网络将音高相关信息从编码器的潜在空间中分离出来,生成音高不变表示,实现了灵活的音高处理。
7.近些年来,基于gan的方法在语音转换和歌唱语音转换中得到了广泛的应用,它可以通过一个小的参数模型快速生成高质量的音频,这有助于端到端的训练。然而,直接使用gan进行歌唱语音转换会导致一些问题,如基音抖动和高音误差,这些将主要体现在和声成分中,而和声成分在歌唱语音中非常重要,会直接影响生成的歌唱语音的质量,从而降低对整首歌曲的听觉体验。
8.得益于语音转换领域的蓬勃发展,上述提到的方法在一定程度上提升了转换歌唱语音的质量和个性相似度,但是还缺少对歌唱语音细节的关注,对音高,基频和宽泛频率的变化处理程度不够好,目前这方面行之有效的方法还比较少。另一方面,在提升转换歌唱语音质量的同时,保持尽可能低的联合优化难度和训练成本,也成为了一个亟需解决的问题。
技术实现要素:
9.为了解决上述问题,本发明提出一种基于cbam和动态卷积分解的歌唱语音转换方法,该方法可以通过对空间和通道施加注意力,提升网络对歌唱语音细节的处理能力,进而提升转换歌唱语音的质量;另一方面从矩阵分解的角度重新审视动态卷积,通过动态通道融合,降低了潜在空间的维数,大幅度减少模型的参数量和计算量,显著降低动态注意和静态卷积核的联合优化的难度,提升了模型的运行效率。
10.本发明采用的具体技术方案如下:
11.一种基于cbam和动态卷积分解的歌唱语音转换方法,包括训练阶段和转换阶段,其中,训练阶段包括以下步骤:
12.(1.1)获取训练语料,训练语料由多名歌手的歌唱语音组成;
13.(1.2)使用world语音分析/合成模型提取出源歌唱语音频谱特征xs、基频特征f
0s
和非周期性特征;
14.(1.3)通过风格编码器s提取目标歌唱语音风格特征s
t
。生成器g包括编码网络和解码网络,通过编码网络生成源歌唱语音内容特征xc,然后通过解码网络将源歌唱语音内容特征xc和目标歌唱语音风格特征s
t
进行重构,恢复出歌唱语音;
15.(1.4)不断调整转换网络的超参数,使得损失函数最小化,直至理想的迭代次数,从而得到训练好的转换网络;
16.(1.5)构建从源歌唱语音基频特征f
0s
到目标歌唱语音基频特征f
0t
的基频转换函数;
17.转换阶段包括以下步骤:
18.(2.1)使用world语音分析/合成模型提取出待转换语料中源歌唱语音频谱特征xs′
、基频特征f
0s
′
和非周期性特征;
19.(2.2)通过风格编码器s提取目标歌唱语音风格特征s
t
′
,将上述源歌唱语音频谱特征xs′
和目标歌唱语音风格特征s
t
′
输入到步骤(1.4)中训练好的转换网络中,重构出目标歌唱语音频谱特征x
st
′
;
20.(2.3)通过步骤(1.5)中的基频转换函数,将步骤(2.1)提取出的源歌唱语音的基频特征f
0s
′
转换为目标歌唱语音基频特征f
0t
′
;
21.(2.4)使用world语音分析/合成模型将步骤(2.1)中提出的非周期性特征、步骤(2.2)中得到的重构目标歌唱语音频谱特征x
st
′
和步骤(2.3)中得到的目标歌唱语音基频特征f
0t
′
进行合成,得到转换后的歌唱语音。
22.本发明的进一步改进,上述风格编码器s由5层一维模块组成,包括一维卷积模块和一维池化模块,其中每层卷积模块由卷积层和relu激活函数组成,每层池化模块由平均池化构成,输出层由全连接层构成。
23.本发明的进一步改进,上述(1.3)的训练过程包括以下步骤:
24.步骤1、将源歌唱语音频谱特征xs输入生成器g的编码网络中,得到身份无关的内容特征g(xs);
25.步骤2、通过风格编码器s提取目标歌唱语音风格特征s
t
。
26.步骤3、将上述生成的内容特征g(xs)和目标歌唱语音风格特征s
t
输入到生成器g的解码网络进行训练,在训练的过程中,最小化生成器g的损失函数,从而得到转换目标歌唱
语音频谱特征x
st
;
27.步骤4、将源歌唱语音频谱特征xs输入风格编码器s,得到源歌唱语音风格特征ss;
28.步骤5、将上述生成的转换目标歌唱语音的频谱特征x
st
再次输入生成器g的编码网络,得到身份无关的内容特征g(x
st
);
29.步骤6、将上述生成的内容特征g(x
st
)与源歌唱语音风格特征ss,输入生成器g的解码网络进行训练,在训练的过程中最小化生成器g的损失函数,得到重构的源歌唱语音频谱特征
30.步骤7、将步骤3中生成的转换目标歌唱语音频谱特征x
st
输入鉴别器d中进行训练,最小化鉴别器d的损失函数;
31.步骤8、将步骤3中生成的转换目标歌唱语音频谱特征x
st
,输入风格编码器s进行训练,最小化风格编码器s的风格损失函数;
32.步骤9、返回步骤1重复上述步骤,直到达到理想的迭代次数,从而得到训练好的转换网络。
33.本发明所提出的基于cbam和动态卷积分解的歌唱语音转换方法,所述动态卷积的核的生成函数表示为:
[0034][0035]
其中,wk为静态卷积核,k为静态卷积核的数目,πk(x)为注意力得分,并且
[0036][0037]
本发明所提出的基于cbam和动态卷积分解的歌唱语音转换方法,所述动态卷积分解的核的生成函数表示为:
[0038]
w(x)=λ(x)w0+pφ(x)q
t
[0039][0040]
其中λ(x)是一个c
×
c的对角矩阵,通过这种方式在w0上实现了动态通道注意;p矩阵的维度为c
×
l,q
t
为l
×
c,并且l<<c,pφ(x)q
t
代表了稀疏动态残差,为一个对角矩阵;φ(x)为一个全动态矩阵,用于实现动态通道融合;w0为k个静态卷积核的加权平均值。
[0041]
本发明所提出的基于cbam和动态卷积分解的歌唱语音转换方法,所述动态卷积分解使用一个轻量级动态分支来生成动态通道融合φ(x)的系数和动态通道注意λ(x)。动态分支首先将平均池化应用于输入向量x,然后使向量x依次经过两个全连接层和一个激活层,最终加权生成卷积核w(x)。与静态卷积类似,动态卷积分解层还包括批量归一化层和激活层。
[0042]
本发明所提出的基于cbam和动态卷积分解的歌唱语音转换方法,所述cbam注意力模块包括两个子模块,首先是通道注意力模块,输入特征图f,具体函数为:
[0043]
[0044][0045]
mc(f)代表生成的通道注意力,σ代表激活函数sigmoid,mlp代表多层感知机,avgpool代表全局平均池化,maxpool代表全局最大池化,w0和w1代表mlp的权重矩阵。和分别代表全局平均池化特征图和全局最大池化特征图。
[0046][0047]f′
代表通道注意力模块输出的特征图,由输入特征图f和生成的通道注意力mc(f)相乘得到。
[0048]
本发明所提出的基于cbam和动态卷积分解的歌唱语音转换方法,所述cbam注意力模块将通道注意力模块输出的特征图f
′
作为空间注意力模块的输入特征图,具体函数为:
[0049][0050]ms
(f
′
)代表生成的空间注意力,σ代表激活函数sigmoid,f7×7代表7
×
7的卷积操作,和分别代表全局平均池化特征图和全局最大池化特征图。
[0051][0052]f″
代表最终特征图,由输入特征图f
′
和生成的空间注意力ms(f
′
)相乘得到。
[0053]
本发明有益效果:与现有技术相比,本发明首先在生成器中引入动态卷积分解,通过动态通道融合代替对通道组的动态关注,解决生成器中动态卷积会导致卷积权重的数量增加k倍的问题,减轻了联合优化的难度,使得模型在不牺牲精度的情况下,需要的参数更少。并且能够在不降低歌唱语音质量的前提下减少训练时间,提升整个模型的运行效率;本发明进一步针对歌唱语音更广泛的频率变化,引入cbam注意力模块,输入特征图将依次通过通道注意力模块和空间注意力模块,通过共享神经元网络对特征图的池化等操作,增加对频谱中细节的关注,识别不太显著的特征,有效提高网络的表征能力,从而提升歌唱语音的质量。同时由于该模型能够适应广泛的频率变化,因此可以针对目标的非歌唱语音进行转换,即将普通人的说话语音转换成高质量的歌唱语音。因此,本发明是具有高合成语音质量和个性相似度的歌唱语音转换方法。
附图说明
[0054]
图1是本发明的模型的原理示意图。
[0055]
图2是本发明实施例所述的模型中生成器的网络结构图。
[0056]
图3是本发明实施例所述的模型中动态卷积分解的网络结构图。
[0057]
图4是本发明实施例所述的模型中cbam注意力模块的原理示意图。
[0058]
图5是本发明实施例所述的模型中通道注意力模块的原理示意图。
[0059]
图6是本发明实施例所述的模型中空间注意力模块的原理示意图。
具体实施方式
[0060]
为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描
述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
[0061]
实施例:如图1所示,一种基于cbam和动态卷积分解的歌唱语音转换方法,包括训练阶段和转换阶段,训练阶段用于得到歌唱语音转换所需的参数和转换函数,而转换阶段用于实现源歌唱语音转换为目标歌唱语音。
[0062]
进一步说明,训练阶段包括以下步骤:
[0063]
步骤1、获取非平行文本的训练语料,训练语料由多名歌手的歌唱语料组成。实验选取新加坡国立大学声音与音乐计算实验室开发的歌唱和口语语料库nus-48e中的非平行语料库数据集,该语料库是一个169分钟的集合,有12名歌手的48首英语歌词的歌唱和朗读录音,以及一套完整的转录和持续时间注释,每名歌手对应一个文件夹,每个文件夹包括4个歌唱和朗读的wav格式文件。
[0064]
此次实验选取该语料库中8名歌手所对应的所有歌唱录音,重新命名为sf3、sf4、sm3、sm4、tf1、tf2、tm1、tm2,其中s代表源歌手,t代表目标歌手,f代表女性歌手,m代表男性歌手。并且将每名歌手的歌唱录音进行切分处理,每名歌手处理之后得到80句录音,每句录音时长在3~4秒,采样率设置为24khz。其中65句用于训练任务,15句录音用于测试任务,在转换阶段,上述8名歌手将构成16组源-目标转换情形,分别为sf3-tfl、sf3-tf2、sf3-tm1、sf3-tm2、sf4-tf1、sf4-tf2、sf4-tm1、sf4-tm2、sm3-tf1、sm3-tf2、sm3-tm1、sm3-tm2、sm4-tf1、sm4-tf2、sm4-tm1、sm4-tm2。
[0065]
步骤2、使用world语音分析/合成模型从训练语料中提取出源歌唱语音频谱特征xs、基频特征f
0s
和非周期性特征。快速傅里叶变换参数设置为1024,时间帧长度设置为256,梅尔倒谱维度设置为36。因此,提取的梅尔倒谱维度为(36,256),基频特征维度为(1,256),非周期性特征维度为(1,256),一次训练时的批次设置为8。
[0066]
步骤3、本实施例中的基于cbam和动态卷积分解的歌唱语音转换方法由三部分组成:一个产生真实频谱的生成器g,一个判断输入频谱是真实频谱特征还是生成频谱特征的鉴别器d,以及一个用于提取目标风格特征的风格编码器s。
[0067]
网络的目标函数l为:
[0068]
l=lg+ld+ls[0069]
其中,lg、ld和ls分别是生成器g、鉴别器d和风格编码器s的损失函数。
[0070]
生成器的损失函数lg表示为:
[0071][0072]
其中,λ
cyc
和λ
sty
是一组正则化超参数,分别表示循环一致性损失和风格重构损失的权重,和分别表示生成器的对抗损失、循环一致性损失、风格编码器的风格重构损失;
[0073]
鉴别器的损失函数ld为:
[0074][0075]
其中,是鉴别器的对抗损失。
[0076]
步骤4、使用world语音分析/合成模型从训练语料中提取出目标歌唱语音频谱特征x
t
,并将其输入风格编码器s中,得到目标歌唱语音风格特征s
t
;风格编码器由5层一维卷
积模块和5层一维池化模块构成,其中,每层一维卷积模块包括卷积和relu激活函数,每层一维池化模块由平均池化构成,输出层由全连接层构成。
[0077]
步骤5、将提取的源歌唱语音频谱特征xs与步骤4中得到的目标歌唱语音风格特征s
t
一起输入生成器进行训练,使生成器的损失函数lg尽量小,得到转换目标歌唱语音频谱特征x
st
。
[0078]
如图2所示,生成器采用二维卷积网络,激活函数使用mish函数,生成器由编码网络和解码网络组成。编码网络由7层模块组成,其中,前3层为二维卷积模块,每层二维卷积模块包括二维卷积、实例归一化和mish函数,后4层为动态卷积分解整合cbam注意力模块,每层包括动态卷积分解、实例归一化、mish函数和通道注意力模块以及空间注意力模块。解码网络由6层模块组成,其中,前4层为动态卷积分解整合cbam注意力模块,每层包括动态卷积分解、实例归一化、mish函数和通道注意力模块以及空间注意力模块,后2层为二维转置卷积模块,每层二维转置卷积模块包括转置动态卷积、自适应实例归一化和mish函数。具体动态卷积分解的网络结构图如图3所示,cbam注意力模块的原理图如图4所示,图5和图6分别是上述通道注意力模块以及空间注意力模块。
[0079]
步骤6、将目标歌唱语音频谱特征x
t
和步骤5得到的转换目标歌唱语音频谱特征x
st
输入鉴别器,训练鉴别器,使鉴别器的对抗损失函数尽可能小。鉴别器由5层二维卷积模块和输出层构成。其中,每层二维卷积模块包括二维卷积和leakyrelu函数,鉴别器的输出层卷积通道数设置为1。
[0080]
鉴别器的损失函数为:
[0081][0082]
其中,是鉴别器的对抗损失。
[0083][0084]
其中,d(xs)表示鉴别器d判别真实频谱特征,s
t
表示风格编码器s生成的目标歌唱语音风格特征,即s(x
t
)=s
t
,g(xs,s
t
)表示生成器g生成的转换目标歌唱语音频谱特征,d(g(xs,s
t
))表示鉴别器判别生成的频谱特征,表示生成器g生成的概率分布的期望,表示真实概率分布的期望。
[0085]
优化目标为:
[0086][0087]
步骤7、将步骤5得到的转换目标歌唱语音频谱特征x
st
,再次输入到生成器g的编码网络,得到与身份无关的内容特征g(x
st
),将源歌唱语音频谱特征xs输入到风格编码器s,得到源歌唱语音风格特征ss,将得到的内容特征g(x
st
)和源歌唱语音风格特征ss一起输入到生成器g的解码网络进行训练,在训练过程中最小化生成器g的损失函数,得到重构的源歌唱语音频谱特征
[0088]
在训练过程中最小化生成器的损失函数,包括生成器的对抗损失、循环一致性损失、风格编码器的风格重构损失。其中,训练循环一致损失是为了使源歌唱语音频谱特征xs在经过生成器g后,所重构的源歌唱语音频谱特征可以和xs尽可能保持一致,训练风格重
构损失是为了约束风格编码器生成更加符合目标歌唱语音的风格特征s
t
。
[0089]
生成器的损失函数为:
[0090][0091]
优化目标为:
[0092][0093]
其中,λ
cyc
和λ
sty
是一组正则化超参数,分别表示循环一致性损失和风格重构损失的权重。
[0094]
表示生成器g的对抗损失:
[0095][0096]
其中,表示生成器生成的概率分布的期望,s
t
表示风格编码器生成的目标歌唱语音风格特征,即s(x
t
)=s
t
,g(xs,s
t
)表示生成器生成的转换目标歌唱语音频谱特征,d(g(xs,s
t
))表示鉴别器判别真实目标频谱特征,用来判别输入鉴别器的频谱是真实频谱还是生成频谱。在训练过程中尽可能小,生成器不断优化,直至生成能够以假乱真的频谱特征g(xs,ss),使得鉴别器难以判别真假。
[0097]
为生成器g中的循环一致损失:
[0098][0099]
其中,ss表示源歌唱语音风格特征,即s(xs)=ss,g(g(xs,s
t
),ss)为生成器生成的重构的源歌唱语音频谱特征,为重构源歌唱语音频谱和真实源歌唱语音频谱的损失期望,||
·
||1表示1-范数。在训练生成器的损失中,尽可能小,使生成的目标歌唱语音频谱特征g(xs,s
t
)和源歌唱语音风格特征ss再次输入到生成器后,得到的重构源歌唱语音频谱特征尽可能和xs相似。通过训练可以有效保证歌唱语音的内容特征在经过生成器的编码以后不被损失。
[0100]
为风格编码器s的风格重构损失,用来优化风格特征s
t
:
[0101][0102]
其中,s
t
表示风格编码器s生成的目标歌唱语音风格特征,即s(x
t
)=s
t
,g(xs,s
t
)表示生成器生成的转换目标歌唱语音频谱特征,||
·
||1表示1-范数,s(g(xs,s
t
))表示风格编码器s生成的转换目标歌唱语音风格特征。
[0103]
将转换目标歌唱语音频谱特征g(xs,s
t
)输入到风格编码器s中得到重构的风格特征s(g(xs,s
t
)),与风格编码器生成的目标歌唱语音风格特征s
t
求绝对值,在训练过程中,尽可能小,使得风格编码器s生成的目标歌唱语音风格特征s
t
能够充分表达。
[0104]
步骤8、不断重复步骤4至步骤7,达到理想的迭代次数,从而得到训练好的网络。由于神经网络具体设置不同以及实验设备性能不同,设置的迭代次数也各不相同。本实验中设置迭代次数为250000次。
[0105]
步骤9、构建从源歌唱语音基频特征f
0s
到目标歌唱语音基频特征f
0t
的基频转换函
数,针对均值和均方差建立转换关系。
[0106]
进一步说明,基频转换函数为:
[0107][0108]
其中,μs和σs分别为源歌唱语音基频特征在对数域的均值和均方差,μ
t
和σ
t
分别为目标歌唱语音基频特征在对数域的均值和均方差,log f
0s
为源歌唱语音的对数域基频特征,log f
0t
为转换的目标歌唱语音对数域基频特征。
[0109]
在本实施例中,转换阶段包括以下步骤:
[0110]
步骤1、通过world语音分析/合成模型提取待转换语料中源歌唱语音频谱特征xs′
、基频特征f
0s
′
和非周期性特征;
[0111]
步骤2、通过风格编码器s提取目标歌唱语音风格特征s
t
′
,将上述待转换语料中源歌唱语音频谱特征xs′
和目标歌唱语音风格特征s
t
′
输入到训练阶段步骤8训练好的网络中,重构出目标歌唱语音频谱特征x
st
′
;
[0112]
步骤3、通过训练阶段步骤9中的基频转换函数,将步骤1提取出的源歌唱语音的基频特征f
0s
′
转换为目标歌唱语音基频特征f
0t
′
;
[0113]
步骤4、使用world语音分析/合成模型,将步骤1中提取的非周期性特征、步骤2中得到的重构目标歌唱语音频谱特征x
st
′
和步骤3中得到的目标歌唱语音基频特征f
0t
′
等进行合成,得到最终转换后的歌唱语音。
[0114]
本实施例披露的一种基于动态卷积分解和cbam注意力机制的歌唱语音转换方法可通过计算机程序进行运行,该计算机程序可以安装在计算机上抑或封装在移动存储介质里。
[0115]
以上所述为本发明的示例性实施例,并非因此限制本发明专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1